ByteBuf
Nio ByteBuffer 和 Netty ByteBuf 对比
主要有两个方面:指针、扩容两个方面的差别和优化
1 指针:
ByteBuffer
例如下面使用buffer的例子:
public class Test2 {
public static void main(String[] args) {
String content = "abcdefg";
ByteBuffer byteBuffer = ByteBuffer.allocate(256);
byteBuffer.put(content.getBytes());
byteBuffer.flip();
byte[] bufferValue = new byte[byteBuffer.remaining()];
byteBuffer.get(bufferValue);
System.out.println(new String(bufferValue));
}
}
ByteBuffer中会有三个下标,初始位置0,当前位置positon,limit位置,初始时,position为0,limit为Buffer数组末尾
调用buffer.put(value.getBytes())后:
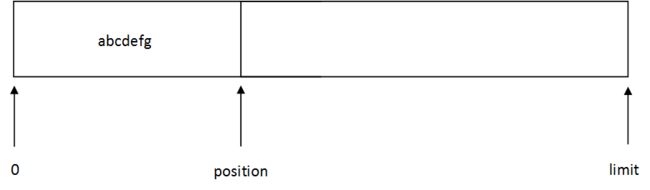
不调用flip:
从缓冲区读取的是position — limit位置的数据,明显不是我们要的
调用flip:
会将limit设置为position,position设置为0,,此时读取的数据 :
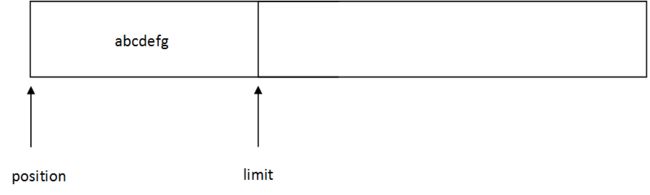
比较关键的代码 byteBuffer.flip();它会把limit设置为position的位置。否则读取到的将会是错误的内容。
ByteBuf:
ByteBuf中使用两个指针,readerIndex,writerIndex来指示位置,初始时readrIndex = writerIndex = 0,当写入数据后:
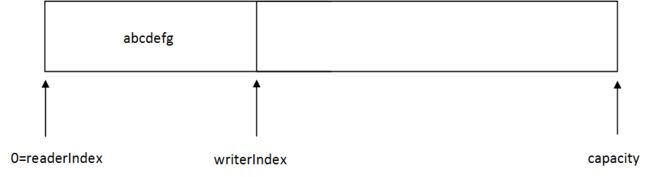
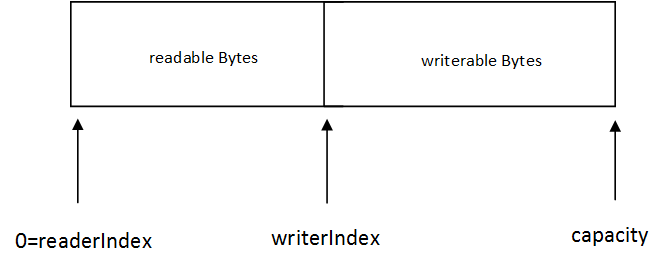
writerIndex — capacity:可写容量
readerIndex — writerIndex:可读部分
当读取了M个字节后:
调用discardReadBytes,会释放掉discardReadBytes的空间,并把readableBytes复制到从0开始的位置,因此这里会发生内存复制,频繁调用会影响性能
2 扩容
nio--ByteBuffer
ByteBuffer缓冲区的长度固定,分多了会浪费内存,分少了存放大的数据时会索引越界,所以使用ByteBuffer时,为了解决这个问题,我们一般每次put操作时,都会对可用空间进行校检,如果剩余空间不足,需要重新创建一个新的ByteBuffer,然后将旧的ByteBuffer复制到新的ByteBuffer中去。最后释放老的ByteBuffer。
netty--ByteBuf
而ByteBuf则对其进行了改进,它会自动扩展,具体的做法是,写入数据时,会调用ensureWritable方法,传入我们需要写的字节长度,判断是否需要扩容:
源码可以查看类AbstractByteBuf中对ByteBuf的实现中查看,方法writeBytes方法:
@Override
public ByteBuf writeBytes(ByteBuf src, int srcIndex, int length) {
ensureAccessible();
ensureWritable(length);
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}
@Override
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format(
"minWritableBytes: %d (expected: >= 0)", minWritableBytes));
}
ensureWritable0(minWritableBytes);
return this;
}
private void ensureWritable0(int minWritableBytes) {
if (minWritableBytes <= writableBytes()) {
return;
}
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
// Normalize the current capacity to the power of 2. 扩容
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
// Adjust to the new capacity.
capacity(newCapacity);
}
可以看到,具体新容量的计算在AbstractByteBufAllocator类中的calculateNewCapacity方法中;
ByteBuf还有一个最大容量限制maxCapacity,若没有指定值,则它的默认值是Integer.MAX_VALUE即最允许的int类型值,设置该值的原因就是因为writerIndex是int类型的。还有一个初始化的容量值initialCapacity,该值用于控制初始化的byte数组的长度,会创建一个长度为该值的字节数组。
@Override
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
if (minNewCapacity < 0) {
throw new IllegalArgumentException("minNewCapacity: " + minNewCapacity + " (expectd: 0+)");
}
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
final int threshold = CALCULATE_THRESHOLD; // 4 MiB page
if (minNewCapacity == threshold) { //如果4MB恰好,则返回4MB
return threshold;
}
// If over threshold, do not double but just increase by threshold.
if (minNewCapacity > threshold) { // 如果不够,每次增长4MB,直到足够或者到达最大容量限制
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// Not over threshold. Double up to 4 MiB, starting from 64.
int newCapacity = 64;
while (newCapacity < minNewCapacity) { //如果小于阀值,则以64为计数倍增,直到倍增的结果>=需要的容量值,
// 即则从64B开始,每次乘以2,直到大于minNewCapacity
int newCapacity = 64;
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}
如何进行计算?
参数writerIndex+minWriableBytes,即满足要求的最小容量。
设置阀门值是4MB,如果新增的内存空间大于这个值,不采用倍增,而采用每次步进4MB的方式,每次增加后和maxCapacity比较,选择其小者。
如果扩容之后的新容量小于阀值,则以64进行倍增。
这样做的原因无非是综合2点因素:不希望一次增加容量太小,导致需要频繁的扩容,不希望一次增加太多,造成空间上的浪费。
因此,在内存比较小的时候(<4MB)的时候,倍增64->128->256字节,这种方式大多数应用可以接收
当内存达到阀值时,再倍增就会带来额外的内存浪费,例如10MB->20MB,因此使用步增的方式进行扩张。
discardReadBytes()
容量扩增的具体实现与ByteBuf的底层实现紧密相关,最终实现的容量扩增方法capacity(newCapacity)由底层实现。
接着分析丢弃已读字节方法discardReadBytes():
//AbstractByteBuf
@Override
public ByteBuf discardReadBytes() {
ensureAccessible();
if (readerIndex == 0) {
return this;
}
if (readerIndex != writerIndex) {
setBytes(0, this, readerIndex, writerIndex - readerIndex);
writerIndex -= readerIndex;
adjustMarkers(readerIndex);
readerIndex = 0;
} else {
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
}
return this;
}
只需注意其中的setBytes(),从一个源数据ByteBuf中复制数据到ByteBuf中,在本例中数据源ByteBuf就是它本身,所以是将readerIndex之后的数据移动到索引0开始,也就是丢弃readerIndex之前的数据。adjustMarkers()重新调节标记索引,方法实现简单,不再进行细节分析。
需要注意的是:读写索引不同时,频繁调用discardReadBytes()将导致数据的频繁前移,使性能损失。由此,提供了另一个方法discardSomeReadBytes(),当读索引超过容量的一半时,才会进行数据前移,核心实现如下:
@Override
public ByteBuf discardSomeReadBytes() {
ensureAccessible();
if (readerIndex == 0) {
return this;
}
if (readerIndex == writerIndex) {
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
return this;
}
if (readerIndex >= capacity() >>> 1) { //当读索引超过容量的一半时,才会进行数据前移
setBytes(0, this, readerIndex, writerIndex - readerIndex);
writerIndex -= readerIndex;
adjustMarkers(readerIndex);
readerIndex = 0;
}
return this;
}
Netty VS JavaNIO
1.跨平台性和通用型
NIO某些底层的操作依赖于操作系统,因此,你写的NIO程序有可能在windows上运行良好,但到了Linux可能会出现问题。 Java6和Java7对NIO提供了不同的解决方案,两个API是不通用的。
2.拓展了ByteBuffer
Netty提供了对ByteBuffer的封装类ByteBuf,拓展了JDK中ByteBuffer的功能,增强了易用性。
- 数据拆分和聚集
很多时候我们想把数据分割成独立的Bytebuffer来处理,比如Http协议Header放到一个buffer中,而Body放到另一个buffer中。很不幸,对于这种处理方式直到Java7才出现,而且如果处理不当,会极易造成OutOfMemoryError。
Scattering And Gathering:
4.解决了著名的epoll bug
为了提升性能,netty在很多地方都进行了无锁设计。比如在IO线程内部进行串行操作,避免多线程竞争造成的性能问题。表面上似乎串行化设计似乎CPU利用率不高,但是通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁串行线程设计性能更优。