【目标检测】YOLOv5算法实现(五):预测结果后处理
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。
本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模块即可实现其他版本的YOLO算法。
文章地址:
YOLOv5算法实现(一):算法框架概述
YOLOv5算法实现(二):模型加载
YOLOv5算法实现(三):数据集加载
YOLOv5算法实现(四):损失计算
YOLOv5算法实现(五):预测结果后处理
YOLOv5算法实现(六):评价指标及实现
YOLOv5算法实现(七):模型训练
YOLOv5算法实现(八):模型验证
YOLOv5算法实现(九):模型预测(编辑中…)
本文目录
- 1 引言
- 2 非极大抑值
- 3 预测结果处理
1 引言
本篇文章实现预测中预测结果的处理(reprocess.py)。在非训练状态下,模型在每一个feature_map、每一个Anchor以及每一个预测单元上均有预测结果,需要对其做进一步的处理,筛选预测结果。预测结果后处理的流程如图1所示。NMS实现对同一类别重合度较大的预测结果的剔除。
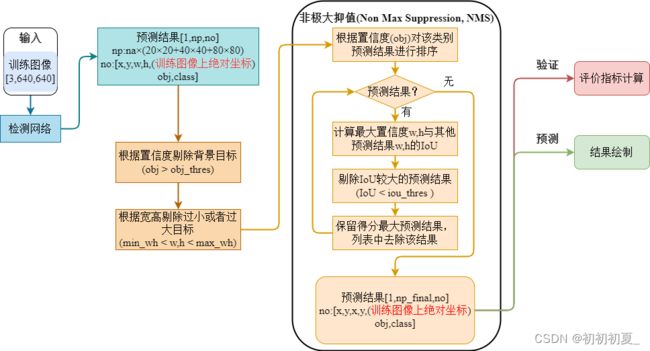
2 非极大抑值
def box_iou(box1, box2):
'''
计算IoU,输入坐标为(xmin,xmax,ymin,ymax)形式
:param box1: (Tensor[N, 4])
:param box2: (Tensor[M, 4])
:return: iou (Tensor[N, M]) box1和box2两两之间的IoU
'''
def box_area(box):
# 计算框面积
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.t())
area2 = box_area(box2.t())
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
def nms(boxes, scores, iou_threshold):
'''
non-maximum suppression (NMS)
在同类别的重合度较大的预测结果中保留置信度最高的结果
:param boxes: Tensor[N, 4])
:param scores: 每个框的目标得分
:param iou_threshold: 判断两个框的重合程度阈值
:return: 保留结果的索引
'''
keep = [] # 最终保存的结果, 在boxes中对应的索引
idxs = scores.argsort() # 得分值从小到大的索引
while idxs.numel() > 0: # 循环直到null
# 得分最大框对应的索引
max_score_index = idxs[-1]
# 得分最大框坐标信息
max_score_box = boxes[max_score_index][None, :] # [1, 4]
keep.append(max_score_index) # 保留该结果
if idxs.size(0) == 1: # 只剩一个框了
break
idxs = idxs[:-1] # 将得分最大的框从索引中删除
other_boxes = boxes[idxs] # [?, 4],其余框
ious = box_iou(max_score_box, other_boxes) # 计算得分最大的框与其他框的IoU [1, ?]
idxs = idxs[ious[0] <= iou_threshold] # 去掉与得分最高的框的重合度较高的框
keep = idxs.new(keep)
return keep
3 预测结果处理
def predict_result_reprocess(prediction, conf_thres=0.3, iou_thres=0.6,
multi_label=True, classes=None, max_num=100):
'''
预测结果后处理
:param prediction: 预测信息
:param conf_thres: 目标置信度阈值(用于剔除背景目标)
:param iou_thres: IoU阈值(用于剔除重合度较大的框)
:param multi_label:若为True,在目标含有多种类别时,一个框可能预测多个类别
:param classes: 非None时仅保留特定类别的预测结果
:param max_num: 保留的预测结果最大数
:return:
'''
# Settings
min_wh, max_wh = 2, 4096 # 最小和最大w,h(剔除过小或过大目标)
nc = prediction[0].shape[1] - 5 # 类别数
multi_label &= nc > 1 # multiple labels per box
output = [None] * prediction.shape[0] # 保留最终输出结果
for xi, x in enumerate(prediction): # image index, image inference 遍历每张图片
x = x[x[:, 4] > conf_thres] # 根据obj虑除背景目标
x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)] # 虑除过小或者过大目标
# 若没有保留的预测结果,则跳过当前图片
if not x.shape[0]:
continue
# 计算目标类别置信度(作为类别得分)
x[..., 5:] *= x[..., 4:5] # conf = obj_conf * cls_conf
# 将(x,y,w,h)预测结果转换为(x,y,x,y)原图上绝对坐标
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label: # 多类别时,保留满足条件的类别预测结果(每个框可能预测了多个满足条件的类别结果)
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t() # i:预测结果序号; j:类别独热编码中最大值的序号
# 将类别独热编码转换为目标的类别(x,y,x,y,conf,cls)
x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)
else: # 每个框仅保留置信度最大的类别预测结果
conf, j = x[:, 5:].max(1) # conf:预测结果最大值; j:类别独热编码中最大值的序号
# (x,y,x,y,conf,cls)
x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]
# 仅保留特定类别的预测结果
if classes:
x = x[(j.view(-1, 1) == torch.tensor(classes, device=j.device)).any(1)]
n = x.shape[0] # 预测结果数量
if not n:
continue
# NMS
c = x[:, 5] # 目标类别
# 根据目标类别给位置增加偏置,保证不同类别的预测框不会重合
boxes, scores = x[:, :4].clone() + c.view(-1, 1) * max_wh, x[:, 4]
i = nms(boxes, scores, iou_thres)
i = i[:max_num] # 最多只保留前max_num个目标信息
output[xi] = x[i]
return output