【目标检测】YOLOv5算法实现(八):模型验证
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。
本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模块即可实现其他版本的YOLO算法。
文章地址:
YOLOv5算法实现(一):算法框架概述
YOLOv5算法实现(二):模型加载
YOLOv5算法实现(三):数据集加载
YOLOv5算法实现(四):损失计算
YOLOv5算法实现(五):预测结果后处理
YOLOv5算法实现(六):评价指标及实现
YOLOv5算法实现(七):模型训练
YOLOv5算法实现(八):模型验证
YOLOv5算法实现(九):模型预测(编辑中…)
本文目录
- 1 引言
- 2 模型验证(validation.py)
1 引言
本篇文章综合之前文章中的功能,实现模型的验证。模型验证的逻辑如图1所示。
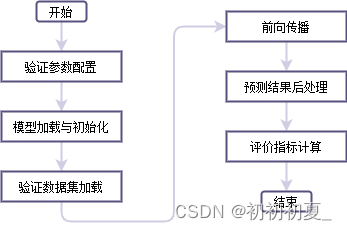
2 模型验证(validation.py)
def validation(parser_data):
device = torch.device(parser_data.device if torch.cuda.is_available() else "cpu")
print("Using {} device validation.".format(device.type))
# read class_indict
label_json_path = './data/object.json'
assert os.path.exists(label_json_path), "json file {} dose not exist.".format(label_json_path)
with open(label_json_path, 'r') as f:
class_dict = json.load(f)
category_index = {v: k for k, v in class_dict.items()}
data_dict = parse_data_cfg(parser_data.data)
test_path = data_dict["valid"]
# 注意这里的collate_fn是自定义的,因为读取的数据包括image和targets,不能直接使用默认的方法合成batch
batch_size = parser_data.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using %g dataloader workers' % nw)
# load validation data set
val_dataset = LoadImagesAndLabels(test_path, parser_data.img_size, batch_size,
hyp=parser_data.hyp,
rect=False) # 将每个batch的图像调整到合适大小,可减少运算量(并不是512x512标准尺寸)
val_dataset_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=nw,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
# create model
model = Model(parser_data.cfg, ch=3, nc=parser_data.nc)
weights_dict = torch.load(parser_data.weights, map_location='cpu')
weights_dict = weights_dict["model"] if "model" in weights_dict else weights_dict
model.load_state_dict(weights_dict, strict=False)
model.to(device)
# evaluate on the test dataset
# 计算PR曲线和AP
stats = []
iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for [email protected]:0.95
niou = iouv.numel()
# 混淆矩阵
confusion_matrix = ConfusionMatrix(nc=3, conf=0.6)
model.eval()
with torch.no_grad():
for imgs, targets, paths, shapes, img_index in tqdm(val_dataset_loader, desc="validation..."):
imgs = imgs.to(device).float() / 255.0 # uint8 to float32, 0 - 255 to 0.0 - 1.0
nb, _, height, width = imgs.shape # batch size, channels, height, width
targets = targets.to(device)
preds = model(imgs)[0] # only get inference result
preds = non_max_suppression(preds, conf_thres=0.3, iou_thres=0.6, multi_label=False)
targets[:, 2:] *= torch.tensor((width, height, width, height), device=device)
outputs = []
for si, pred in enumerate(preds):
'''
labels: [clas, x, y, w, h] (训练图像上绝对坐标)
pred: [x,y,x,y,obj,cls] (训练图像上绝对坐标)
predn: [x,y,x,y,obj,cls] (输入图像上绝对坐标)
labels: [x,y,x,y,class] (输入图像上绝对坐标)
shapes[si][0]: 输入图像大小
shapes[si][1]
'''
labels = targets[targets[:, 0] == si, 1:] # 当前图片的标签信息
nl = labels.shape[0] # number of labels # 当前图片标签数量
if pred is None:
npr = 0
else:
npr = pred.shape[0] # 预测结果数量
correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # 判断在不同IoU下预测是否预测正确
path, shape = Path(paths[si]), shapes[si][0] # 当前图片shape(原图大小)
if npr == 0: # 若没有预测结果
if nl: # 没有预测结果但有实际目标
# 不同IoU阈值下预测准确率,目标类别置信度,预测类别,实际类别
stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
# 混淆矩阵计算(类别信息)
confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
continue
predn = pred.clone()
scale_boxes(imgs[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
if nl: # 有预测结果且有实际目标
tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
scale_boxes(imgs[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
correct = process_batch(predn, labelsn, iouv)
confusion_matrix.process_batch(predn, labelsn)
stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # 预测结果在不同IoU是否预测正确, 预测置信度, 预测类别, 实际类别
confusion_matrix.plot(save_dir=parser_data.save_path, names=["normal", 'defect', 'leakage'])
# 图片:预测结果在不同IoU下预测结果,预测置信度,预测类别,实际类别
stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, names=["normal", 'defect', 'leakage'])
ap50, ap = ap[:, 0], ap.mean(1) # [email protected], [email protected]:0.95
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
print(map50)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description=__doc__)
# 使用设备类型
parser.add_argument('--device', default='cuda', help='device')
# 检测目标类别数
parser.add_argument('--nc', type=int, default=3, help='number of classes')
file = 'yolov5s'
cfg = f'cfg/models/{file}.yaml'
parser.add_argument('--cfg', type=str, default=cfg, help="*.cfg path")
parser.add_argument('--data', type=str, default='data/my_data.data', help='*.data path')
parser.add_argument('--hyp', type=str, default='cfg/hyps/hyp.scratch-med.yaml', help='hyperparameters path')
parser.add_argument('--img-size', type=int, default=640, help='test size')
# 训练好的权重文件
weight_1 = f'./weights/{file}/{file}' + '-best_map.pt'
weight_2 = f'./weights/{file}/{file}' + '.pt'
weight = weight_1 if os.path.exists(weight_1) else weight_2
parser.add_argument('--weights', default=weight, type=str, help='training weights')
parser.add_argument('--save_path', default=f'results/{file}', type=str, help='result save path')
# batch size
parser.add_argument('--batch_size', default=2, type=int, metavar='N',
help='batch size when validation.')
args = parser.parse_args()
validation(args)