Mysql 行列变换《你想要的都有》
目录
-
-
- 介绍
- 1.准备测试数据
- 2.根据分隔符一行变多行
- 3.一列变多列,简单分列
- 4.一列变多列,数据透视
- 5.多列变一列
-
介绍
在面试和实际问题中,常常会遇到各种行列转换,例如数据根据分隔符一行变多行、数据一列变多列和多列变一列,下面来给大家介绍在Mysql中如何处理这些场景。
1.准备测试数据
create table dwd.fact_suject_data
(
student_id int null comment '编号',
subject_level varchar(255) null comment '科目等级',
subject_level_json varchar(255) null comment '科目等级json数据'
);
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (12,'China E,English D,Math E','{"China": "E","English": "D","Math": "E"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (2,'China B,English B','{"China": "B","English": "B"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (3,'English A,Math C','{"English": "A","Math": "C"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (4,'China C,Math A','{"China": "C","Math": "A"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (5,'China D,English A,Math C','{"China": "D","English": "A","Math": "C"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (6,'China C,English A,Math D','{"China": "C","English": "A","Math": "D"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (7,'China A,English E,Math B','{"China": "A","English": "E","Math": "B"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (8,'China D,English E,Math E','{"China": "D","English": "E","Math": "E"}');
insert into dwd.fact_suject_data(student_id, subject_level,subject_level_json) values (9,'China C,English E,Math C','{"China": "C","English": "E","Math": "C"}');
2.根据分隔符一行变多行
需求:我想要学生编号和科目等级两列,科目等级只展示单个科目等级。
方法一:使用mysql自带的表,用于切分字符串,注意help_topic_id是从0开始的
select t1.student_id,
-- 根据 help_topic_id 对 subject_level 进行切分字符串
substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1) subject_level
from dwd.fact_suject_data t1
left join mysql.help_topic t2
on t2.help_topic_id <= length(t1.subject_level) - length(replace(t1.subject_level, ',', ''))
;
方法二:使用递归自己构造出自增id列(从1开始也可从0开始),用于切分字符串
with recursive cte(n) as
(select 1
union all
select n + 1
from cte
where n < 100) -- 递归出需要的自增id表
select t1.student_id,
-- 根据 n 对 subject_level 进行切分字符串
substring_index(substring_index(t1.subject_level, ',', t2.n), ',', -1) subject_level
from dwd.fact_suject_data t1
left join cte t2
on t2.n <= (length(t1.subject_level) - length(replace(t1.subject_level, ',', '')) + 1)
;

两个方法的脚本,都是根据分隔符的总数量,依次构造出递增到总数量的数字,用于做substring_index()参数进行切割,除了以上两种方法,如果有其他表有这样递增且唯一的id,也可以进行借用。
3.一列变多列,简单分列
需求:我想要学生编号、科目和等级三列;
根据步骤2的结果,简单使用substring_index()切分就可以了;
select t1.student_id,
-- 根据 help_topic_id 对 subject_level 进行切分字符串
substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1) subject_level,
substring_index(substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1),' ',1) subject,
substring_index(substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1),' ',-1) level
from dwd.fact_suject_data t1
left join mysql.help_topic t2
on t2.help_topic_id <= length(t1.subject_level) - length(replace(t1.subject_level, ',', ''))
;

需求:我想要学生编号和每科对应的数据,需要使用subject_level_json字段;

subject_level_json是常见的json数据类型,那么我们可以使用有关json的函数,下面介绍常用的几个,如果想要了解更多可点击Mysql官网查看和扩展;
select json_object('key1', 1, 'key2','abc') json_data,
json_extract('{"key1": 1, "key2": "abc"}','$.key1') key1,
json_extract('{"key1": 1, "key2": "abc"}','$.key2') key2;

接下来直接引用,遇到数据类型不对的可以cast()转换,值多双引号的可replace()替换;
select student_id,
subject_level_json,
replace(cast(json_extract(cast(subject_level_json as json),'$.China') as char),'"','') china,
replace(cast(json_extract(cast(subject_level_json as json),'$.English') as char),'"','') english,
replace(cast(json_extract(cast(subject_level_json as json),'$.Math') as char),'"','') math
from fact_suject_dat;

4.一列变多列,数据透视
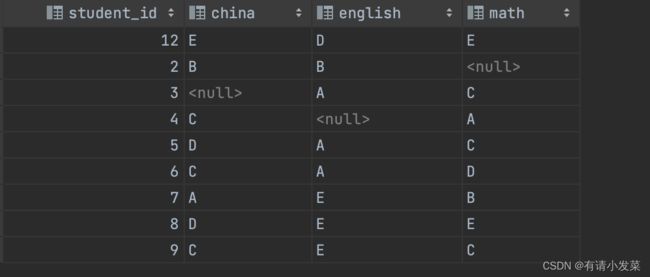
需求:我想要学生编号和每科对应的数据,不能使用使用subject_level_json字段;
根据步骤2分列后,进一步使用case when 就可直接转换了
select student_id,
max(case when subject = 'China' then level else null end) china,
max(case when subject = 'English' then level else null end) english,
max(case when subject = 'Math' then level else null end) math
from (select t1.student_id,
-- 根据 help_topic_id 对 subject_level 进行切分字符串
substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1) subject_level,
substring_index(substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1),' ',1) subject,
substring_index(substring_index(substring_index(t1.subject_level, ',', t2.help_topic_id + 1), ',', - 1),' ',-1) level
from dwd.fact_suject_data t1
left join mysql.help_topic t2
on t2.help_topic_id <= length(t1.subject_level) - length(replace(t1.subject_level, ',', ''))) t
group by student_id
;
也可以subject_level字段,结合mid()或者substring()和case when进一步转换,如果对字符串函数不了解,点这里;
select student_id,
max(case when subject_level like '%China%'
then mid(subject_level ,(instr(subject_level,'China')+length('China')+1), 1) else null end) china,
max(case when subject_level like '%English%'
then mid(subject_level,(instr(subject_level,'English')+length('English')+1), 1) else null end) english,
max(case when subject_level like '%Math%'
then mid(subject_level ,(instr(subject_level,'Math')+length('Math')+1), 1) else null end) math
from fact_suject_data
group by student_i;
5.多列变一列
需求:我想要根据步骤4的结果,生成学生编号、科目和等级三列数据;

使用union all进行拼接就可以,如果是oracle的话可以用PIOVT功能。
select student_id,
concat('China ',china) subject_level
from
(select student_id,
max(case when subject_level like '%China%'
then mid(subject_level ,(instr(subject_level,'China')+length('China')+1), 1) else null end) china,
max(case when subject_level like '%English%'
then mid(subject_level,(instr(subject_level,'English')+length('English')+1), 1) else null end) english,
max(case when subject_level like '%Math%'
then mid(subject_level ,(instr(subject_level,'Math')+length('Math')+1), 1) else null end) math
from fact_suject_data
group by student_id) t
where china is not null
union all
select student_id,
concat('English ',english) subject_level
from
(select student_id,
max(case when subject_level like '%China%'
then mid(subject_level ,(instr(subject_level,'China')+length('China')+1), 1) else null end) china,
max(case when subject_level like '%English%'
then mid(subject_level,(instr(subject_level,'English')+length('English')+1), 1) else null end) english,
max(case when subject_level like '%Math%'
then mid(subject_level ,(instr(subject_level,'Math')+length('Math')+1), 1) else null end) math
from fact_suject_data
group by student_id) t
where english is not null
union all
select student_id,
concat('Math ',math) subject_level
from
(select student_id,
max(case when subject_level like '%China%'
then mid(subject_level ,(instr(subject_level,'China')+length('China')+1), 1) else null end) china,
max(case when subject_level like '%English%'
then mid(subject_level,(instr(subject_level,'English')+length('English')+1), 1) else null end) english,
max(case when subject_level like '%Math%'
then mid(subject_level ,(instr(subject_level,'Math')+length('Math')+1), 1) else null end) math
from fact_suject_data
group by student_id) t
where math is not null;
需要:我想要……
