【面试】数据库优化、索引
目录
数据库调优的目标
索引覆盖是什么?
最左缀原则是什么?
哪些因素可能会造成Mysql性能问题?
如果sql语句需要使用联表查询我们如何进行优化呢?
Mysql常见优化手段
你从哪些方面去优化你的数据库?
一个页面响应很慢,你按照什么顺序去排查?
你怎么去找到系统中查询慢的SQL
什么是索引?
如何查看某个sql有没有命中索引?
InnoDB主键索引和辅助索引
Mysql执行流程
SQL如何进行调优?
Mysql中的索引有哪些类型?
聚集索引(主键索引)VS非聚集索引(非主键索引)
什么是聚集索引?
聚集索引:
Mysql索引方式有哪些
B+树索引和Hash索引的区别?
Mysql为什么使用B+树?
Mysql的存储引擎有哪些?
InnoDB和MyISAM的区别?
使用场景
InnoDB和MyIsam的索引结构 区别、谁快?【重要又拓展知识】
InnoDB和MyIsam如何进行选择?
Mysql主从复制优化策略?【加分项】
索引是建的越多越好吗?
哪些情况不适合创建索引?
哪些情况适合创建索引?
什么时候创建组合(联合)索引?
组合(联合)索引的匹配原则
索引的代价
哪些因素会造成索引失效(未命中索引)?
InnoDB辅助索引的叶子节点也存数据吗
Like一定会让索引失效吗
============多机优化=============
Mysql的集群有哪些模式?
单机优化到极致了,可以怎么优化?
多机优化有哪些方式?
什么是CAP理论哪些是AP,哪些是CP?讲几个案例
什么是垂直分库分表什么是水平分库分表
多少数据量适合分表
分表的规则有哪些,你们是按照什么规则分表的,具体算法是什么
分库分表后会出现哪些问题?怎么解决
你们公司使用的是什么技术来水平分表?还可以有什么技术?有什么区别?
什么是Mysql主从复制
主从复制解决什么问题,不能解决什么问题?
Mysql主从复制的原理是什么?
Mysql主从复制优化策略?【加分项】
你们在表设计的时候出现设计上的结构的问题?你们如何解决?
数据库调优的目标
数据库调优的目的就是要让数据库运行得更快,响应的时间更快,吞吐量更大。
索引覆盖是什么?
索引覆盖就是将需要查询的数据作为索引建立普通索引,从而可以利用索引快速查询,所以sql语句就会直接通过索引进行查询就不用进行回表(数据库),所需要的字段都在索引的叶子节点上,直接返回结果即可,不用进行回表。
最左缀原则是什么?
最左前缀原则:顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上。
当创建(a,b,c)复合索引时,想要索引生效的话,只能使用 a和ab,ac和abc(顺序无影响)四种组合!
当一个sql想要使用索引时,就一定要提供该索引所对应的字段最左边的字段,也就是排在最前面的字段,针对a,b,c三个字段建立了一个联合索引,那么写一个sql语句就一定要提供a字段的条件(不管顺序,只要提供了就可以),这样就可以使用联合索引了。这是因为在建立abc三个字段的联合索引时,底层B+树也是按照abc的顺序进行大小排序的,所以想要使用B+树进行快速查询也必须复合这个规则。
mysql>SELECT `a`,`b`,`c` FROM A WHERE `a`='a1' ; //索引生效
mysql>SELECT `a`,`b`,`c` FROM A WHERE `b`='b2' AND `c`='c2'; //索引失效
mysql>SELECT `a`,`b`,`c` FROM A WHERE `a`='a3' AND `c`='c3'; //索引生效,实际上值使用了索引a
哪些因素可能会造成Mysql性能问题?
1表数据量过大
2sql查询太复杂使用了大量的select*和join
3sql查询没有走索引
4数据库服务器性能过低等
如果sql语句需要使用联表查询我们如何进行优化呢?
首先查询的时候不要使用select *,尽量采用 select 字段 进行查询。我们还可以在数据表中设计冗余字段,将多表查询变单表查询,从而提高查询效率。
如果非要使用联表!
还有就是给查询的字段的加上索引,或者对数据库经常查询的字段加上索引,如果加上索引的话就要避免索引失效的问题。
还有就是我们如果不考虑事务,主要是查询的话,我们可以采用MyIsAM存储引擎。最后的方式就是数据量实在是太庞大了,就建议使用分库分表的方法。
Mysql常见优化手段
归纳看这就够了:
1首先我们需要定位慢sql,(通过MySQL的慢查询日志查看慢SQL【show variables like '%slow_query_log%'; 】)
2通过explain关键字加在需要查询的sql语句前面,通过执行结果查看是否使用了索引,
2.1如果没有使用索引,就1查看是否是索引失效【索引失效又包含了很多】,2然后查看是否是查询了不需要查询的字段,3如果只是查询,可以使用Myisam存储引擎,4将JOIN联表查询变成单表查询使用Union All(不去重不排序,Union去重且排序) 结合起来或者设计冗余字段,5还有就是给需要查询的字段加索引,
2.2如果使用了索引还是很慢,查看是否是数据量太大了,就可以考虑分表分库了。
=================================================================
-
给查询字段增加索引
-
不需要的字段就不要查询出来
-
小结果集驱动大结果集,将能过滤更多数据的小表的条件写到前面【先精准查询再模糊查询】
-
in和not in尽量不要用,会导致索引失效(未命中索引)
-
避免在where中使用or连接条件,这会导致索引失效(未命中索引)
-
考虑如果不需要事务,并且主要是查询的话(查少写多的场景),可以考虑使用MyISAM存储引擎
你从哪些方面去优化你的数据库?
如果是并发高,可以考虑将数据存储到缓存中,如果是数据量大可以考虑分库分表,具体如下:
首先应该考虑垂直分库,不同的业务使用不同的数据库
然后进行垂直分表,按照使用频率把字段多的表拆分成若干个表
1对经常查询的列建立索引,提高查询效率
2设计冗余字段,减少join表的次数
3SQL优化,比如尽量使用索引查询
4对热点数据应该考虑做缓存,比如首页展示汇总数据
5如果查询并发高,可以对mySQL做主从集群,如果写并发高,采用双主数据库。
从海量数据中查询数据应该考虑用全文检索
如果数据量实在太大了,可以考虑水平分表,
水平分表后,表数量还是太多了,可以考虑水平分库
一个页面响应很慢,你按照什么顺序去排查?
1首先看一下硬件和网络层面,有没有什么异常
然后2分析代码有没有什么问题,3算法有没有什么缺陷,4比如多层嵌套循环
最后我们再5定位到慢SQL,比如
-
通过druid连接池的内置监控来定位慢SQL
-
Springboot整合druid连接池,开启sql监控,慢SQL检测 (附git源码)_全栈小定的博客-CSDN博客_druid慢sql监控
-
通过MySQL的慢查询日志查看慢SQL【show variables like '%slow_query_log%'; 】
-
通过show processlist,可以用来查看当前数据库SQL正在执行的情况,定位SQL的状态
定位到慢SQL再考虑6优化该SQL,比如说
-
不需要的字段就不要查询出来
-
尽量不要使用select * ,建议使用字段列表
-
多表联查尽量不要使用Join,使用单表查询采用UNION ALL(替换UNION-去重且排序)
-
使用索引和组合索引
-
小结果集驱动大结果集,将能过滤更多数据的条件写到前面【先精准查询再模糊查询】
-
in和not in尽量不要用,会导致索引失效(未命中索引)
-
避免在where中使用or连接条件,这会导致索引失效(未命中索引)
-
考虑如果不需要事务,并且主要是查询的话,可以考虑使用MyISAM存储引擎
如果优化SQL后还是很慢,可以考虑给7查询字段建索引来提升效率
如果建立索引了还是慢,看一下是不是数据量太庞大了,应该8考虑分表了
你怎么去找到系统中查询慢的SQL
通过druid连接池的内置监控来定位慢SQL
通过MySQL的慢查询日志 来定位慢SQL【show variables like '%slow_query_log%'; 】
通过show processlist,查看当前数据库SQL执行情况来定位慢SQL
什么是索引?
索引就是用来帮助Mysql高效获取去数据的数据结构。
通过索引查询数据时不用读完数据库中的所有信息,而只是查询索引列。否则,就需要读取每条数据进行匹配,非常影响效率。
因此,使用索引可以很大程度上提高数据库的查询速度,还有效的提高了数据库系统的性能。
如何查看某个sql有没有命中索引?
MySQL如何查看SQL查询是否用到了索引?_Kant101的博客-CSDN博客_mysql查看sql是否使用索引
通过索引验证字段Explain,就是在SQL语句前加上explain,type只要不是All(全表扫描)都是走了索引的,查询结果中的key就表示mysql实际使用的索引。如果没有选择索引,则为null。
key:表示MySQL实际使用的(索引)键。如果没有选择索引,键是NULL。查询中如果使用覆盖索引,则该索引和查询的select字段重叠(表示创建的索引的字段刚好是需要查询的字段)。


InnoDB主键索引和辅助索引
对于主键默认会创建主键索引,其他列创建的索引就叫辅助索引,也叫二级索引,辅助索引的叶子节点存储的是主键索引的键值,这就意味着辅助索引需要查询两个B+Tree.

所以出现了回表和覆盖索引的概念:
-
回表:辅助索引扫描完B+树之后(因为辅助索引叶子节点存储的数据是主键索引的键值),还要扫描主键索引(主键索引叶子节点存储的是数据),这叫回表。
-
覆盖索引:覆盖索引就是将需要查询的数据作为索引建立普通索引(就是需要select查询name字段,刚好有一个普通索引就是以name创建的),从而可以利用索引快速查询,所以sql语句就会直接通过索引进行查询就不用进行回表(数据库),所需要的字段都在索引的叶子节点上,直接返回结果即可,不用进行回表。
-
例如,在sakila的inventory表中,有一个组合索引(store_id,film_id),对于只需要访问这两列的查 询,MySQL就可以使用索引,如下:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory


操作
-
创建表时指定存储引擎
create table 表名(字段列表) engine 存储引擎名称【默认INNODB】;
CREATE TABLE t_temp(id BIGINT PRIMARY key,name VARCHAR(20)) ENGINE myisam;注意:如果不指定则使用默认的存储引擎,这个默认实在my.ini配置
My.ini增加配置: default-storage-engine=INNODB【默认是InnoDB】
修改存储引擎:alter table table_name engine=innodb;
Mysql执行流程

1客户端发起SQL查询,首先通过连接器,它会检查用户的身份,包括校验账户密码,权限
2然后会查询缓存,如果缓存命中直接返回,如果没有命中再执行后续操作,但是MySQL8.0之后已经删除了缓存功能
3接下来到达分析器,主要检查语法词法,比如SQL有没有写错,总共有多少关键字,要查询哪些东西
4然后到达优化器,他会以它的方式优化我们的SQL
5最后到达执行器,调用存储引擎(innodb或myisam)的接口并执行SQL语句将执行结果进行返回。
SQL如何进行调优?
数据库调优一般指的就是sql调优。
sql调优可以解决我们的大部分问题。然后sql调优的主要着手点就在执行器执行之前的分析器,优化器阶段。
首先sql优化的步骤:
1先检查一般将开发涉及到业务的sql在本地环境进行跑一边,1通过explain关键字加载sql语句前面,查看执行的结果,查看是否使用了索引,其中的key就表示这条sql语句使用的那个索引,extra下面如果是Using index就表示使用了索引进行查询。然后去线上环境跑一遍看看执行时间。
如何查看sql执行时间
show profiles;

Mysql中如何查看Sql语句的执行时间(建议多准备点初始数据效果更佳)_程序员小王java的博客-CSDN博客_mysql查询sql执行时间
2还有要2注意Mysql8.0之前我们数据库都是带缓存的,因为存在缓存,sql永远都会执行很快,所以在查询的时候应该加上 SQL NoCache去跑sql。
再开启缓存的情况下我们对sql语句做一些改动
Select sql_no_cache count(*) from users; 不使用缓存
Select sql_cache count(*) from users; 缓存(也可以不加,默认缓存已经开启了)
这样就可以查询出真正的运行时间了。
为什么缓存会失效,而且会经常失效。
如果我们Mysql版本号支持缓存我们并且开启了缓存,每次请求都会去缓存中进行查询,没有才会去数据库进行查询,只要我们对表中的一条数据进行修改就会删除缓存中的数据。所以说后面Mysql8.0后就没有缓存了。
SQL调优简单总结_ss.zhang的博客-CSDN博客_sql调优
2统一sql语句的规范
如,对于以下两句SQL语句,很多人认为是相同的,但是,数据库查询优化器认为是不同的。
select * from student
select * From student3少用*(尽量不要用*),用具体的字段列表来代替*,不要查询不需要的字段。
4对sql语句进行优化(就是避免索引失效,走全文索引)
1)应考虑在 where 及 order by 涉及的列上建立索引。
2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如
select id from t where score is null
可以在score上设置默认值0,确保表中score列没有null值,然后这样查询:
select id from t where score=0
3)应尽量避免在 where 子句中使用!=或<>操作符,否则将导致引擎放弃使用索引而进行全表扫描
4)应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
// union all不去重不排序 union去重且排序(效率低)
5)慎用in 和 not in,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6)合理使用like模糊查询
有时候需要进行一些模糊查询,如:
select * from contact where username like ‘%yue%’
关键词 %yue%,由于yue前面用到了“%”,因此该查询必然走全表扫描,除非必要,否则不要在关键词前加%
7)应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8)应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
如:查询name以abc开头的id
select id from t where substring(name,1,3)='abc'
应改为:
select id from t where name like 'abc%'
5、用 exists 代替 in
很多时候用 exists 代替 in 是一个好的选择,Exists只检查存在性,性能比in强很多。例:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
6、不要把SQL语句写得太长,太过冗余、要简洁;能用一句千万不要用两句
7、将where后面的查询条件设置成组合索引(保证最左匹配原则即可)
Mysql中的索引有哪些类型?
普通索引【NORMAL】:允许重复的值出现,可以在任何字段上面添加
唯一索引【UNIQUE】:除了不能有重复的值外,其它和普通索引一样,可以在值是唯一的字段添加(用户名、手机号码、身份证、email,QQ)
主键索引:数据库自动为我们的主键创建索引,如果我们没有指定主键,它会根据没有null的唯一索引创建主键索引,否则会默认根据一个隐藏的rowId作为主键索引
全文索引【FULL TEXT】,用来对文本域进行索引,比如text,varchar,只针对MyISAM有效,InnoDB不支持全文索引
创建普通索引的方式
create index 索引名 on 表 (列1,列名2,...);
修改表添加索引
alter table 表名 add index 索引名(列1,列名2,..);
案例
create table aaa(id int unsigned,name varchar(32)); // 创建表aaa
create index Iname on aaa(name); // 给表名aaa的name字段创建索引名为Iname
alter table aaa add index index1(name);创建组合索引
CREATE INDEX PersonIndex
ON Person (LastName, FirstName);
详情请看下列链接。
Sql Server sql语句创建索引_执着的涛的博客-CSDN博客_创建索引的sql语句
聚集索引(主键索引)VS非聚集索引(非主键索引)
什么是聚集索引?
在Mysql当中,B+树索引 按照存储方式的不同 就可以分为聚集索引和非聚集索引。
聚集索引:
以InnoDB作为存储引擎的表,表中的数据都会有一个主键,即使不创建主键,系统也会给你创建一个隐式的主键。
这是因为InnoDB把数据存储在B+树上,而B+树的键值就是主键,在B+树的叶子节点上,存储了表中所有的数据。
这种以主键作为B+树的索引而构建的B+树索引,我们称之为聚集索引。
非聚集索引:
以主键之外的列值作为B+树的索引而构建的B+树索引,称之为非聚集索引。
非聚集索引和聚集索引的主要区别在于非聚集索引(辅助索引)的叶子节点不存储表中的数据,而是存储的是该列的主键,想要查询数据还需要根据主键再次进行聚集索引种进行查找。这种再根据聚集索引查找数据的过程,我们称之为回表。
Mysql索引方式有哪些
B+树和hash
Myisam和innodb都不支持hash,Memory支持hash。【皆为Mysql存储引擎】
B+树索引和Hash索引的区别?
-
如果是等值查询,那么hash索引具有绝对优势【只需要进行一次hash计算出数据的地址值就可以找到数据,而B+树还需要从根节点查询到字节点,才能获取到数据。】
-
B+树可以对数据进行范围查询,而Hash不能,因为hash索引存储是无序的,采用hash算法进行存储数据。
-
hash索引容易出现hash冲突,效率会降低。
-
hash索引不支持最左匹配原则。
总结
B+树索引的使用面更广,如果是查询单条数据,建议使用hash,如果是大量数据,建议使用B+树。
Mysql为什么使用B+树?
因为B+树属于多叉树【Balance Tree】,B+树的所有数据都存储在叶子节点,非叶子节点只存储索引【key】,从而每个节点可以存储更多的索引(key--key为表中数据的主键)。树的深度就会更低,查询效率就会更高。叶子节点中的数据使用双向链表的方式进行关联。还可以进行范围查找。

Mysql的存储引擎有哪些?
InnoDB和MyISAM的区别?
存储引擎:InnoDB,MyISAM,Memory。
innodb支持事务(所以mysql默认使用的是InnoDB),速度相对较慢,支持外键,不支持全文索引
myisam 不支持事务,速度相对较快,不支持外键,支持全文索引
memory不支持事务,速度快,基于内存读写,支持全文索引
使用场景
如果对事务要求不高,而且是查询为主,考虑用myisam
如果对事务要求高,保存的都是重要的数据,建议使用Innodb,它也是默认的存储引擎
如果数据频繁变化的,不需要持久化,可以使用memory
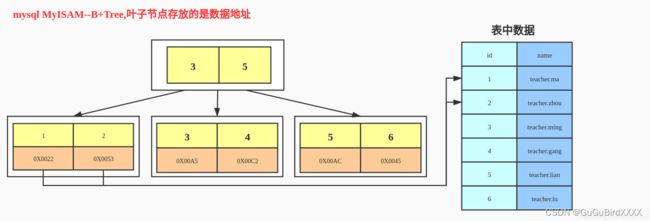
InnoDB和MyIsam的索引结构 区别、谁快?【重要又拓展知识】
他们都是底层用的B+树,不同的是
-
innodb的叶子节点存放的是真实数据,myisam的叶子节点存放的是数据的地址
-
innodb中辅助索引的叶子节点存放的是主键索引的键值【需要进行回表】,myisam中辅助索引的叶子节点存放的也是数据的地址(不用进行回表)
-
innodb的索引和数据都存放到一个文件中,myisam的索引和数据分别存放到不同的文件中
=========================拓展知识====================
首先要知道谁快?主要还是看不同的条件
1查询的字段是主键索引。【InnoDB存储引擎胜出】
如果索引主键的话,InnoDB查询效率是比MyISAM存储引擎快的(因为通过主键索引进行查询查询的时候,直接不会进行回表再进行查询一次,而MyISAM存储的是数据的地址值,还需要拿着地址值再去查询一次)
2查询的字段不是主键索引【MyISAM存储引擎胜出】
如果索引不是主键,查询的时候InnoDB会先通过辅助索引进行查询到叶子节点(叶子节点存储的是主键索引的值),查询到了过后还需要进行回表查询。
而MyISAM是通过索引查询到数据的地址值然后通过地址值,拿着地址表进行查询。
InnoDB和MyIsam如何进行选择?
如果绝大多数据都是进行读取的话,可以使用MyISAM(因为没有事务,效率会更高。)
如果既有读又有写的话,建议使用InnoDB.(因为有事务,要保证数据的一致性。)
Mysql主从复制优化策略?【加分项】
Mysql数据库主从复制的时候,因为主数据库大多数用来写数据,从数据库只用来读数据。所以可以采用主数据库采用InnoBD的存储引擎(保证事务,保证数据的一致性),从数据库采用MyISAm的存储引擎(没有事务,读取效率就会更高。)
但是,一般不建议这么做。

索引是建的越多越好吗?
明显不是,有以下几点:
- 数据量小的表不需要建立索引,建立会增加额外的索引开销
- 不经常引用的列不要建立索引,因为不常用,即使建立了索引也没有多大意义。对经常用于查询的字段应该创建索引。
- 经常频繁更新的列不要建立索引,因为肯定会影响插入或更新的效率
- 数据重复且分布平均的字段,因此他建立索引就没有太大的效果(例如性别字段,是否上架等等,不适合建立索引)
- 数据变更需要维护索引,意味着索引越多维护成本越高。当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
- 更多的索引也需要更多的存储空间,一个表中很够创建多个索引,这些索引度会被存放到一个索引文件中(专门存放索引的地方)。
哪些情况不适合创建索引?
数据量小的表最好不要使用索引,建立会增加额外的索引开销
不经常查询的列不适合创建索引
不出现在where(条件)中的字段不适合创建索引,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的。
数据大量重复且分布平均的字段,比如性别
select * from emp where sex = '男’
更新非常频繁的字段不适合创建索引,因为肯定会影响插入或更新的效率
select * from emp where empno = 1
哪些情况适合创建索引?
经常查询的列可以创建索引
出现在where(条件)中的字段适合创建索引,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的。
什么时候创建组合(联合)索引?
当我们的where条件存在多个条件查询的时候,我们需要对查询的列创建组合(联合)索引。
组合(联合)索引的匹配原则
组合查询的匹配原则是最左匹配原则,假设我们需要对(a,b,c)这样的一个组合索引,那么相当于对a列进行排序,也就是我们创建组合索引,以最左边的为准,只要查询条件中带有最左边的列,那么查询就会使用到索引。
比如
SELECT a, b, cFROM test where a = 1 ;
SELECT a, b, cFROM test where a = 1 and b =1 ;
SELECT a, b, cFROM test where a = 1 and c =1 ;
索引的代价
-
占用磁盘空间。
-
对DML操作有影响,因为要维护索引,变慢。
通过DML实现表中数据的操作
插入数据:insert
查询数据:select
更新数据:update
删除数据:delete
哪些因素会造成索引失效(未命中索引)?
-
模糊查询时,通配符放到左边的时候,会导致索引失效 比如 like ''%keyword%'' like “keyword%”可以
expain select * from dept where dname=’111’;
-
列是字符串类型,无论是不是字符串数字一定要用 “ ‘ ”引号 把它包括起来,否则索引失效
expain select * from dept where dname=’111’;
-
注意:not in 、not exist、!=、< >、like "%_",以及in(select子句) 会导致索引失效
-
查询的条件列进行过运算或处理,不会走索引,因为不确定计算后的值是什么
如: where DATE_FORMART(start_time,’%y-%m-%d’) = “21-2-23” 不会走索引
-
查询null值如: where name is null 不会走索引,可以去null设定为 0 来代替。
-
or会导致索引失效
select * from dept where dname=’xxx’ or loc=’xx’; //不能使用索引,它没办法从两个索引树种去检索
-
如果mysql认为使用全表扫描要比使用索引快,则不使用索引,比如表里面只有一条记录
InnoDB辅助索引的叶子节点也存数据吗
对于主键默认会创建主键索引,其他列创建的索引就叫辅助索引
InnoDB辅助索引的叶子节点存放的是 主键索引的键值【表中记录的主键】
因此辅助索引扫描完还会扫描主键索引,也叫回表。
如果select name查询的列刚好是辅助索引创建的列(name),就不用进行回表了。直接通过索引进行查询所需要的数据就行了,这就叫覆盖索引。
======================================
覆盖索引就是将需要查询的数据(列)作为索引建立普通索引(就是需要查询name字段,刚好有一个普通索引就是以name创建的),从而可以利用索引快速查询,所以sql语句就会直接通过索引进行查询就不用进行回表(数据库),所需要的字段都在索引的叶子节点上,直接返回结果即可,不用进行回表。
例如,在sakila的inventory表中,有一个组合索引(store_id,film_id),对于只需要访问这两列的查 询,MySQL就可以使用索引,如下:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory
Like一定会让索引失效吗
不一定,比如:like "值%" 一样可以使用索引,向左匹配,通配符不能在最左边(索引未命中,索引失效),所以 like "%值"或 "_值"就不能命中索引。
============多机优化=============
Mysql的集群有哪些模式?
集群:多个服务器一起对外提供一个服务。多个服务器部署相同的代码处理相同的业务。
一主一从;一主多从;双主;环形多主;级联同步

Mysql集群有N种方式,我们这里选择主从模式,因为根据2/8原则(80%用来读取,20%用来写入),数据库的性能瓶颈往往都在80%的读操作上,我们需要减轻读的压力【将经常读取的数据存储在Redis当中】 。
单机优化到极致了,可以怎么优化?
可以考虑做集群,比如一主多从模式,然后对应用做读写分离(主可读可写,从全部用来读取。)。
多机优化有哪些方式?
分表,分库,主从同步(主数据库和从数据库进行数据同步,主数据库主要用作写入操作,从服务器进行读取操作。)
什么是CAP理论哪些是AP,哪些是CP?讲几个案例
实现分布式锁的三种方式+CAP理论+Base理论_GuGuBirdXXXX的博客-CSDN博客
什么是垂直分库分表什么是水平分库分表
数据库的水平分表和垂直分表到底是什么?_GuGuBirdXXXX的博客-CSDN博客_数据库垂直分表和水平分表
多少数据量适合分表
为了保证数据库的查询效率,当数据达成一定量时建议进行分表操作
1、oracle
当oracle单表的数据量大于2000万行时,建议进行水平分表。
2、mysql
当mysql单表的数据量大于1000万行时,建议进行水平分表。
具体情况根据数据库服务器的配置和架构有关,仅供参考。
分表的规则有哪些,你们是按照什么规则分表的,具体算法是什么
范围法,hash算法,雪花算法。
数据库的水平分表和垂直分表到底是什么?_GuGuBirdXXXX的博客-CSDN博客_数据库垂直分表和水平分表
分库分表后会出现哪些问题?怎么解决
会产生分布式事务,以前本地事务就能结局的问题现在要用上Seata分布式事务
垂直分库后跨库查询会导致一个查询结果来源于两个库,可能要用到多线程调用多个库查询
水平分库后一个分页查询的某一页可能来自两个库,可以将两个库的数据合并之后再执行SQL
水平分表后不同的表出现主键重复,可以通过雪花算法来解决
两个库都用到同一个表,那这个公共表的维护可能要用到MySQL主从同步
你们公司使用的是什么技术来水平分表?还可以有什么技术?有什么区别?
使用的是sharding-jdbc来实现的,它是由java开发的关系型数据库中间件,读写分离,分库分表操作简单
TDDL,淘宝业务框架,复杂而且分库分表的部分还没有开源
Mycat,要安装额外的环境,不稳定用起来复杂
MySQL官方提供的中间件,不支持大数据量的分不分表,性能较差
shardingjdbc如何实现读写分离
1首先导入相关的依赖
2然后在配置文件中配置datasource,包括主从数据库的名字,主从数据库的连接信息,配置负载均衡
4项目中就可以正常使用datasource了,自动做读写分离
shardingjdbc如何实现读分库分表
首先,要改造数据库,比如水平分表,水平分库
在配置文件中,需要做如下配置
-
datasource名字,多个数据源就配多个datasource
-
分库策略,比如按照哪一列分库,分库规则
-
分表策略,比如哪些库下面的哪些表,按照那一列分表,分表规则
-
配置公共的表
然后项目中就可以正常使用了
什么是Mysql主从复制

一个主(Master)数据库多个从(Slave)数据库,主数据库主要负责写操作,从数据库负责读操作,主数据库的数据同步到从数据库进行存储(读取直接从从数据库进行读取),这样的集群模式就主从同步 。
主从同步的优点是减轻读的压力,如果主库的写并发比较高或者为了解决主数据库单点故障,可用做成多个主库,多个主库相互复制,这样即提高了主库写的并发能力,也解决了单节点故障问题(主从--主服务器挂掉,还有其他服务器能够进行读操作,主主--一个主服务器挂掉,其他主服务器还是可以进行写操作)。
主从复制解决什么问题,不能解决什么问题?
主从复制解决了数据的读取的压力,但是不能解决写的压力和主库的单点故障。【从数据库只能用来进行读取。可以采用多主(数据库)的方式解决写的压力】
Mysql主从复制的原理是什么?

Mysql主从复制就是通过binary log(二进制日志)实现主数据库的异步复制到从数据库的。当主数据库执行了一条sql命令,那么从数据库就会从Binary log中进行读取并同样的执行一遍,从而达到主从复制的效果。
binary log(二进制日志)中存储的内容称之为事件,每一个数据库更新操作(Insert、Update、Delete,不包括Select)等都对应一个事件。
主从复制步骤:
首先需要开启3个线程,masterI/O,Slave开启I/O,SQL线程。
-
Master将Binary-log日志文件打开,该日志文件用来记录主数据库的增删改。
-
Slave会通过IO线程请求Master,Master会返回给Slave一个Binary Log的名字以及当前数据更新的位置等信息。
-
Slave会将binary log日志内存写入relay log(中继日志)当中。
-
当数据库进行增删改操作时,会按照binary log格式,会将这条sql命令存储到binary log日志文件当中。
-
Master会生成一个binary log dump 线程,用来通知slave进行读取Binary log日志文件到relaylog(中继日志)当中。
-
从库slave的sql线程,会实时监控relay log文件中的日志是否更新,然后解析日志文件中的sql语句,在slave数据库中进行执行,从而达到主从复制。
Mysql主从复制优化策略?【加分项】
Mysql数据库主从复制的时候,因为主数据库大多数用来写数据,从数据库只用来读数据。所以可以采用主数据库采用InnoBD的存储引擎(保证事务,保证数据的一致性),从数据库采用MyISAm的存储引擎(没有事务,读取效率就会更高。)
但是,一般不建议这么做。
你们在表设计的时候出现设计上的结构的问题?你们如何解决?
如果我们在项目开发过程中发现我们的表结构有问题,比如说设计的字段不够,这时候需要添加一个字段。
方法一,直接添加字段(在数据量比较小的情况下操作,可能会造成表死锁)
ALTER TABLE 表名 ADD 字段名 字段属性 DEFAULT '有默认值或者允许为null' COMMENT '字段解释' ;
方法适合十几万的数据量,可以直接进行加字段操作,但是,线上的一张表如果数据量很大,执行加字段操作就会锁表,这个过程可能需要很长时间甚至导致服务崩溃(俗称表锁),那么这样操作就有风险。如果服务崩溃时,可通过show PROCESSLIST找到对应info列(之前执行的SQL语句)以及state列为locked的id值,然后kill id对应的值就可以了
方法2.创建一张临时的新表
3. ① 创建一个临时的新表,首先复制旧表的结构(包含索引);
create table 临时表 like 旧表;
② 给新表加上新增的字段
alter table student_log1 add zyp int(11) null DEFAULT 0
注:新增字段要么有为空,要么有默认,否则后续复制表报错
③ 复制旧表数据到新表,注意此时新表是空表,加字段很快;【 from 旧表】
INSERT INTO student_log1 ( id, NAME, sno, ip, url, operation, excute_time ) SELECT
id,
NAME,
sno,
ip,
url,
operation,
excute_time
FROM
student_log
注:复制表数据最好在业务低峰期操作,避免数据丢失
④ 删除旧表(可以先把旧表重命名,不建议立即删除,方便后续的数据恢复,如果确保复制表数据成功,可以删除旧表),重命名新表的名字为旧表的名字
alter table student_log1 rename to student_log;