数据治理 | 还在人工识别表格呢?Python 调用百度 OCR API 又快又准
文章目录
- @[toc] Part1 前言
- Part2 注册百度 AI 平台,申请 API
- Part3 识别表格 PDF
-
- 1、安装 Python 包
- 2、PDF 文档转为图片
- 3、调用 API,将图片识别为 Excel 表
- 4、批量识别并合并为一张表
- Part4总结
-
- 题外话
Part1 前言
文章目录
- @[toc] Part1 前言
- Part2 注册百度 AI 平台,申请 API
- Part3 识别表格 PDF
-
- 1、安装 Python 包
- 2、PDF 文档转为图片
- 3、调用 API,将图片识别为 Excel 表
- 4、批量识别并合并为一张表
- Part4总结
-
- 题外话
文档类型的转换(PDF,Excel等)对广大社科学者来说一直是一个不大不小,但又令人十分头疼的问题。往期的实用技能分享中我们介绍过如何OCR识别图片中的文本,也介绍过如何使用 Python 读取(可以复制内容的)PDF 中的表格,将其转为 Excel 表。此时细心的小伙伴会发现一个盲区:我们怎么把不可复制内容的PDF(或扫描件)表格转成 Excel 表呢?
本文正是为了解决这个问题而写。我们知道,面对扫描文件一般会使用 OCR 技术来识别其中的文本。使用软件的话会面临收费,不符合白嫖精神;自己训练模型费时费力还不一定有效果。如果你也有这样的问题,请往下看,我们教你免费使用百度公司的 OCR 产品。
Part2 注册百度 AI 平台,申请 API
出于识别准确度和使用门槛的考虑,我们选择使用 百度 AI 平台提供的 OCR 服务,使用服务需要注册百度智能云账号,并申请 OCR 服务。这一步并不难,这里有一份非常详细的官方教程:https://ai.baidu.com/forum/topic/show/867951。
申请成功页面如下图所示:
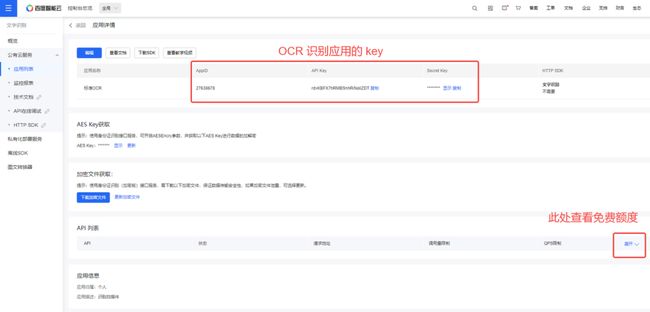
接下来我们使用 Python 调用我们前面申请到的 API 来识别 PDF 文档。
Part3 识别表格 PDF
我们以一份 PDF 文档(共 3 页)为例进行演示,其内容不可复制,所以不能使用 Python 直接读取其中的内容,只能依靠 OCR 识别。
下图是 PDF 第一页中部分表格内容:

1、安装 Python 包
使用 Python 调用百度 OCR API 需要安装 baidu-aip 库,在命令提示符中输入以下命令安装:
pip install baidu-aip
2、PDF 文档转为图片
OCR 工具可以将图片识别为指定内容,而我们需要转换的文档是 PDF,所以需要先将 PDF 的每一页分别转为图片。PDF 转图片的代码如下:
import fitz
# 下面是待转换 PDF 的路径
pdf = './TEST/2019-2020 年全国碳排放权交易前2-4页.pdf'
doc = fitz.open(pdf)
for pg in range(doc.pageCount):
page = doc[pg] # 选择一页
rotate = 0
# 设置参数调整图片的质量
X_, Y_ = 4, 4
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
pix.save(f"./TEST/Pic/Page_{pg}.png")
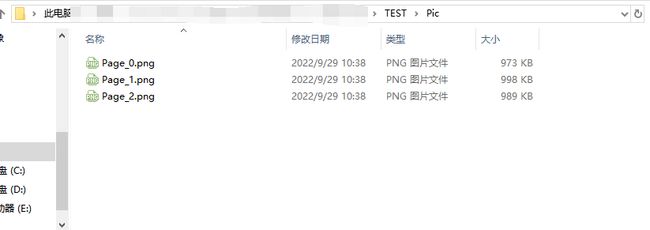
如上图所示,代码运行后,在指定位置生成 3 张图片,分别对应 PDF 中的 3 页。
3、调用 API,将图片识别为 Excel 表
首先,我们根据前面申请的 API key,生成一个 API 客户端,这是固定的代码写法,代码如下:
from aip import AipOcr # 导入第一步安装的库
APP_ID = '根据实际填写'
API_KEY = '根据实际填写'
SECRET_KEY = '根据实际填写'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY) # 根据 API key 生成客户端
第二步,将图片传入 API 客户端,等待服务器完成 OCR 识别。代码如下:
img = open("./TEST/Pic/Page_0.png",'rb').read() # 以二进制方式打开图片
table = client.tableRecognitionAsync(img) # 调用 API 表格服务
print(table) # 查看 API 返回结果
![]()
此时,服务器只返回给我们两个 id,接下来我们根据其中的 request_id 来获取识别的状态和识别的结果,代码如下:
ID = table['result'][0]['request_id'] # 取出 request_id
result = client.getTableRecognitionResult(ID) # 根据 id 尝试获取识别结果
result # 查看请求结果

如上图所示,我们只需关注请求结果中的识别状态(因为 OCR 识别需要一定时间,当识别已完成时才能获取结果)和识别结果(url),百度 API 会将识别的结果存放在云端,我们需要根据请求结果中的 url 来获取识别结果。
最后一步,获取识别结果,并写入 Excel 表中(识别结果为二进制数据,只有写入 Excel 才能使用)。代码如下:
import requests # 使用 requests 库抓取数据
dataurl = result['result']['result_data'] # 请求结果的 url
data = requests.get(dataurl) # 根据 url 获取数据
# 在我们希望的文件夹下新建一个 Excel 表,将识别的结果写入其中
with open("./TEST/识别结果/table_Page_0.xlsx", 'wb') as excel: # .表示Python当前工作目录
excel.write(data.content) # 将识别结果写入 Excel
excel.close()
运行代码后,会在我们指定的位置(在上面的倒数第三行代码中,如果没有这个文件夹,我们需要主动创建)生成一个 Excel 表,如下图所示:


对比 PDF ,发现识别效果非常可观。实际上,只要是人眼能够分辨的文字,此 API 几乎都能准确识别。
4、批量识别并合并为一张表
绝大多数情况下,一份 PDF 含有多页,以上三小节介绍了 Python 调用百度 API 识别表格的完整过程,下面我们再演示一下如何批量识别多页。前面的步骤中,我们将一份 PDF(3 页)转换为 3 张图片,下面我们就来 OCR 识别这三张图片,并将这三张图片的识别结果合并为一张表,代码如下:
import time, requests, glob
from aip import AipOcr
import pandas as pd
APP_ID = '根据实际填写'
API_KEY = '根据实际填写'
SECRET_KEY = '根据实际填写'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
path_list = glob.glob('./TEST/Pic/*.png') # 获取 Pic 目录下所有 png 图片的路径
for pic_path in path_list:
# 遍历所有图片的路径列表
img = open(pic_path,'rb').read() # 加载图片
table = client.tableRecognitionAsync(img) # 调用表格识别 API 进行识别
request_id = table['result'][0]['request_id'] # API 返回的请求 ID
# 下面每隔两秒查看识别状态,直到识别完成,即可抓取识别结果
result = client.getTableRecognitionResult(request_id)
while result['result']['ret_msg'] != '已完成':
# 通过 ID 获取识别结果,直至识别完成
time.sleep(2)
result = client.getTableRecognitionResult(request_id)
dataurl = result['result']['result_data'] # 识别完成后结果存储的 url
# 将结果写入 Excel 表,与图片同名
imgname = pic_path.split('\\')[-1].split('.')[0]
with open(f'./TEST/excel/{imgname}.xlsx', 'wb') as excel:
excel.write(requests.get(dataurl).content)
# 以上代码运行后,会在事先创建的 excel 文件夹下中生成三份 excel 表
# 接下来我们使用 Pandas 将他们合并为一张表(前提是这三张表结构一致,即字段名一样)。
excel_paths = glob.glob('./TEST/excel/*.xlsx')
DATA = pd.DataFrame()
for path in excel_paths:
Page_df = pd.read_excel(path)
DATA = pd.concat([DATA, Page_df])
# 将合并的表保存为 Excel 表
DATA.to_excel('./TEST/excel/2019-2020 年全国碳排放权交易前2-4页.xlsx', index=False)
运行代码后,在我们指定的文件夹下就会生成三份单页的 Excel 表,以及一个合并的 Excel 表。

以上就是调用百度 API 批量识别表格的步骤了。

提示:
任何 OCR 产品都无法保证 100% 的识别准确率,如果你的数据非常非常重要,请谨慎使用 OCR 功能,或者使用后进行人工核对。
Part4总结
本期文章为大家介绍了如何使用百度 API 识别 PDF 表格或图片中的表格。如果你有这方面的需求,又恰好会一点 Python,那么就可以好好琢磨琢磨,把这个技能掌握住。最后,希望本期的技术分享能够给各位读者带来一点点帮助。
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上脚本呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


七、简历模板