谷歌最新医学领域LLM大模型:AMIE
2024年1月11日Google 研究院发布最新医疗大模型AMIE:用于诊断医学推理和对话的研究人工智能系统。
文章链接:Articulate Medical Intelligence Explorer (AMIE)
giuthub:目前代码未开源
关于大模型之前有过一篇总结:大语言模型(LLM)发展历程及模型相关信息汇总欢迎大家阅读
下面是关于AMIE的解读:
医患对话是医学的基石,熟练且有意的沟通可以推动诊断、管理、同理心和信任。能够进行此类诊断对话的人工智能系统可以通过成为临床医生和患者等有用的对话伙伴来提高护理的可用性、可及性、质量和一致性。但接近临床医生丰富的专业知识是一项重大挑战。
医学领域之外的大型语言模型 (LLM) 的最新进展表明,它们可以计划、推理并使用相关上下文来进行丰富的对话。然而,良好的诊断对话有许多方面是医学领域独有的。一位高效的临床医生会获取完整的“临床病史”,并提出有助于得出鉴别诊断的明智问题。他们运用相当多的技能来建立有效的关系,清楚地提供信息,与患者共同做出明智的决定,对他们的情绪做出同理心的反应,并在下一步的护理中支持他们。虽然法学硕士可以准确地执行医学总结或回答医学问题等任务,但很少有专门针对开发此类对话诊断能力的工作。
受这一挑战的启发,我们开发了 Articulate Medical Intelligence Explorer (AMIE),这是一个基于法学硕士并针对诊断推理和对话进行优化的研究人工智能系统。我们从临床医生和患者的角度从反映现实世界临床咨询质量的多个维度对 AMIE 进行了培训和评估。为了将 AMIE 扩展到多种疾病状况、专业和场景,我们开发了一种新颖的基于自我游戏的模拟诊断对话环境,具有自动反馈机制,以丰富和加速其学习过程。我们还引入了推理时间链推理策略,以提高 AMIE 的诊断准确性和对话质量。最后,我们通过模拟与训练有素的演员的协商,在多轮对话的真实例子中前瞻性地测试了 AMIE。
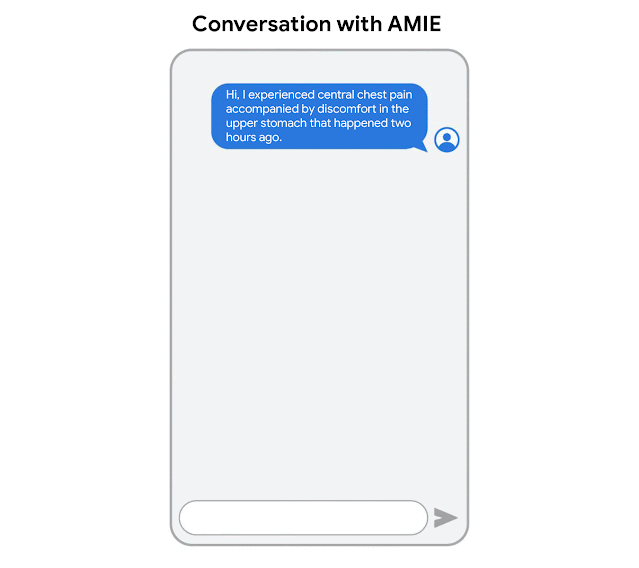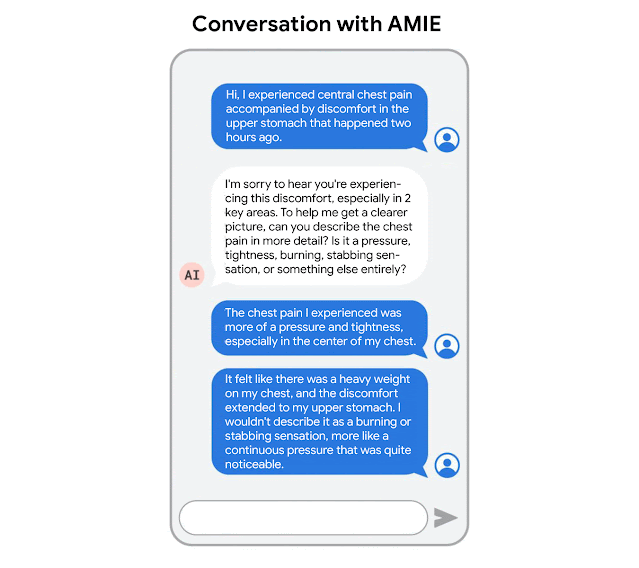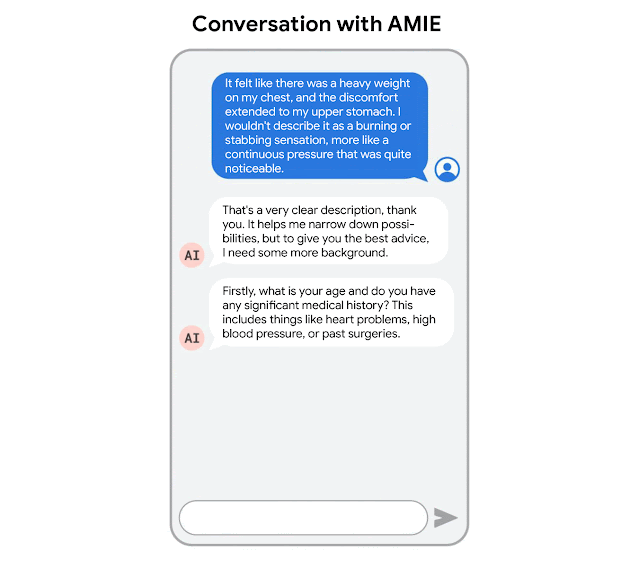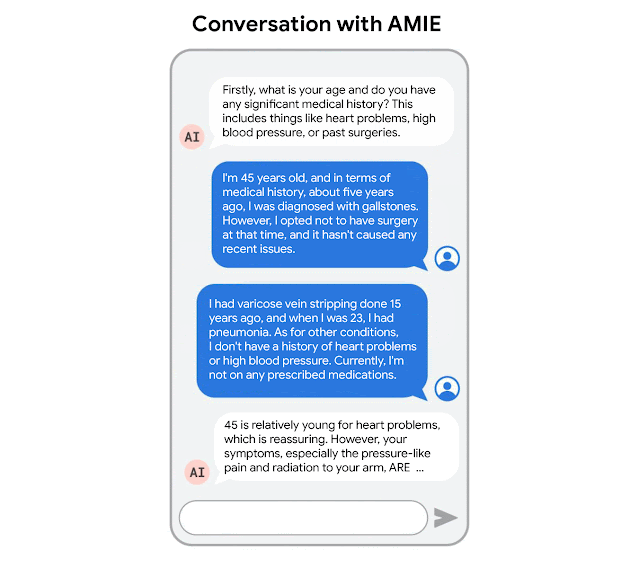
AMIE 针对诊断对话进行了优化,提出有助于减少不确定性并提高诊断准确性的问题,同时还与有效临床沟通的其他要求(例如同理心、培养关系和清晰地提供信息)进行平衡。
对话式诊断人工智能的评估
除了开发和优化人工智能系统本身用于诊断对话之外,如何评估此类系统也是一个悬而未决的问题。受到用于衡量现实环境中咨询质量和临床沟通技巧的公认工具的启发,我们构建了一个试点评估标准,以评估与病史采集、诊断准确性、临床管理、临床沟通技巧、关系培养和共情。
然后,我们设计了一项基于文本的咨询的随机、双盲交叉研究,其中经过验证的患者参与者与经过委员会认证的初级保健医生 (PCP) 或针对诊断对话进行优化的人工智能系统进行交互。我们以客观结构化临床检查 (OSCE) 的方式进行咨询,这是现实世界中常用的一种实用评估,用于检查临床医生的技能和能力。以标准化和客观的方式评估能力。在典型的 OSCE 中,临床医生可能会在多个工作站之间轮换,每个工作站都模拟现实生活中的临床场景,在这些场景中,他们执行诸如与标准化患者演员(经过仔细培训以模拟患有特定病症的患者)进行咨询等任务。咨询是使用同步文本聊天工具进行的,模仿了当今大多数使用法学硕士的消费者所熟悉的界面。
AMIE 是一个基于LLM的研究人工智能系统,用于诊断推理和对话。
AMIE:基于LLM的对话式诊断研究人工智能系统
我们在真实世界的数据集上对 AMIE 进行了训练,其中包括医学推理、医学总结和真实世界的临床对话。
使用通过被动收集和转录现场临床就诊而开发的真实对话来培训法学硕士是可行的,但是,两个重大挑战限制了它们在培训法学硕士进行医学对话方面的有效性。首先,现有的现实世界数据往往无法捕捉广泛的医疗状况和场景,阻碍了可扩展性和全面性。其次,来自现实世界对话记录的数据往往很嘈杂,包含模棱两可的语言(包括俚语、行话、幽默和讽刺)、中断、不合语法的话语和隐含的引用。
为了解决这些限制,我们设计了一个基于自我游戏的模拟学习环境,具有自动反馈机制,可在虚拟护理环境中进行诊断医疗对话,使我们能够在许多医疗条件和环境中扩展 AMIE 的知识和能力。除了所描述的真实世界数据的静态语料库之外,我们还使用此环境通过一组不断发展的模拟对话来迭代微调 AMIE。
这个过程由两个自我对弈循环组成:(1)一个“内部”自我对弈循环,其中 AMIE 利用上下文中的评论家反馈来改进其在与人工智能患者模拟器的模拟对话中的行为;(2)“外部”自我播放循环,其中一组经过改进的模拟对话被纳入后续的微调迭代中。由此产生的新版本的 AMIE 可以再次参与内部循环,从而创建一个良性的持续学习循环。
此外,我们还采用了推理时间链策略,使 AMIE 能够根据当前对话逐步完善其响应,以得出知情且有依据的答复。
AMIE 使用一种新颖的基于自我游戏的模拟对话学习环境来提高多种疾病状况、专业和患者背景下的诊断对话的质量。
我们测试了与模拟患者(由训练有素的演员扮演)会诊的表现,并与使用上述随机方法的 20 名真实 PCP 进行的会诊进行比较。在一项随机、盲法交叉研究中,从专科主治医生和模拟患者的角度对 AMIE 和 PCP 进行了评估,该研究包括来自加拿大、英国和印度的 OSCE 提供者的 149 个案例场景,涉及不同的专业和疾病。
值得注意的是,我们的研究并不是为了模仿传统的面对面 OSCE 评估或临床医生通常使用文本、电子邮件、聊天或远程医疗的方式。相反,我们的实验反映了当今消费者与法学硕士互动的最常见方式,这是人工智能系统参与远程诊断对话的一种潜在可扩展且熟悉的机制。
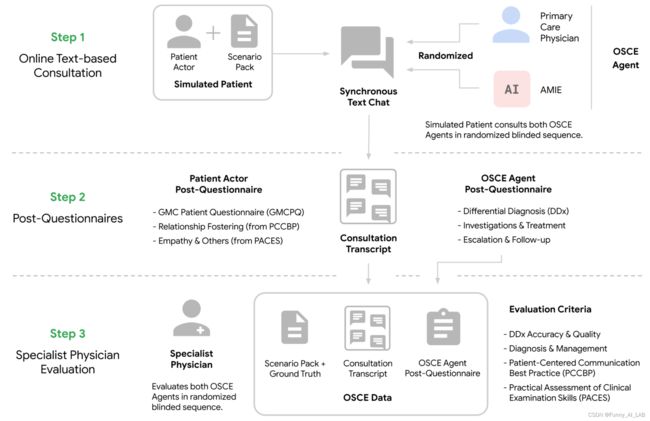
通过在线多轮同步文本聊天与模拟患者进行虚拟远程 OSCE 的随机研究设计概述。
AMIE 性能
在这种情况下,我们观察到,当沿着多个具有临床意义的咨询质量轴进行评估时,AMIE 执行模拟诊断对话的效果至少与 PCP 一样好。从专科医生的角度来看,AMIE 在 32 个轴中的 28 个轴上具有更高的诊断准确性和卓越的性能,从患者参与者的角度来看,在 26 个轴中的 24 个轴上,AMIE 具有更高的诊断准确性和卓越的性能。
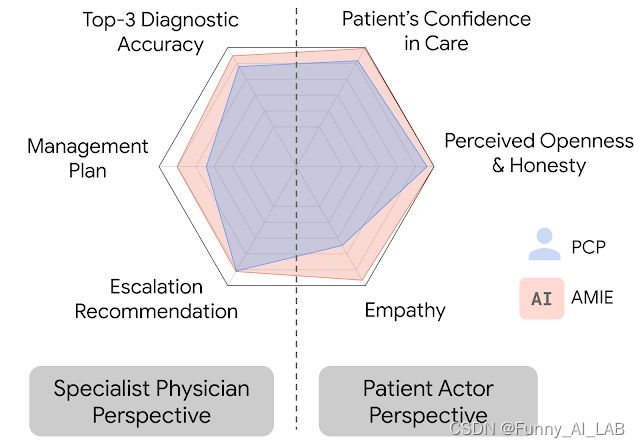
在我们的评估中,AMIE 在诊断对话的多个评估轴上均优于 PCP。
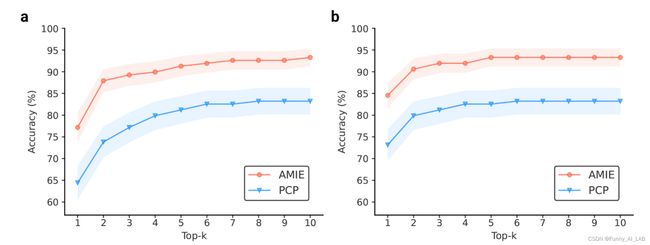
专家评级的 top-k 诊断准确性。AMIE 和 PCP 的 top-k 鉴别诊断 (DDx) 准确性在 149 个场景中与地面真实诊断 (a) 和可接受的鉴别诊断中列出的所有诊断 (b) 进行比较。Bootstrapping (n=10,000) 确认 AMIE 和 PCP DDx 准确度之间的所有前 k 个差异均显着,在 错误发现率 (FDR) 校正后,p <0.05。
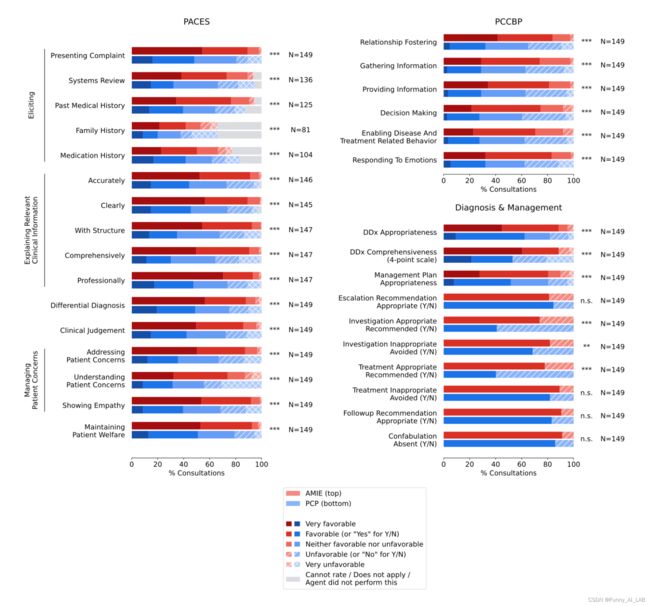
由专科医生评估的诊断性对话和推理质量。在 32 个轴中的 28 个轴上,AMIE 的性能优于 PCP,而其他轴的性能相当。
AMIE的局限性
我们的研究有一些局限性,应谨慎解释。首先,我们的评估技术可能低估了人类对话的现实价值,因为我们研究中的临床医生仅限于不熟悉的文本聊天界面,该界面允许大规模的法学硕士与患者互动,但不能代表通常的临床实践。其次,任何此类研究都必须被视为漫长旅程中探索性的第一步。从我们在本研究中评估的法学硕士研究原型过渡到可供人们和为其提供护理的人使用的安全而强大的工具,将需要大量的额外研究。有许多重要的限制需要解决,包括现实世界约束下的实验性能,以及对健康公平、隐私、鲁棒性等重要主题的专门探索,以确保技术的安全性和可靠性。
AMIE 对临床医生的帮助
在最近发布的预印本中,我们评估了 AMIE 系统早期迭代单独生成 DDx 或作为临床医生辅助的能力。二十 (20) 名全科临床医生评估了 303 个具有挑战性的真实医疗案例,这些案例来自* 新英格兰医学杂志 * (NEJM) [ 临床病理学会议 ](https:/ /www.nejm.org/case-challenges) (CPC)。每份病例报告均由两名随机接受两种辅助条件之一的临床医生阅读:搜索引擎和标准医疗资源的帮助,或除这些工具外的 AMIE 帮助。所有临床医生在使用相应的辅助工具之前都提供了基线、无协助的 DDx。
协助随机读者研究设置,调查 AMIE 对临床医生解决新英格兰医学杂志复杂诊断病例挑战的辅助效果
AMIE 表现出的独立性能超过了无人协助的临床医生(前 10 名准确率分别为 59.1% 和 33.6%,p= 0.04)。比较两个辅助研究组,与没有 AMIE 协助的临床医生 (24.6%,p<0.01) 和有搜索的临床医生 (5.45%,p=0.02) 相比,受 AMIE 协助的临床医生的前 10 名准确率更高。此外,与没有 AMIE 协助的临床医生相比,得到 AMIE 协助的临床医生得出了更全面的鉴别列表。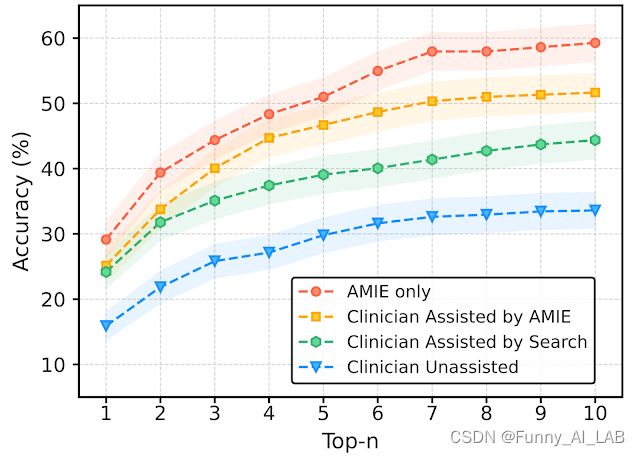
除了强大的独立性能之外,使用 AMIE 系统还可以为临床医生解决这些复杂的病例挑战带来显着的辅助效果和诊断准确性的提高。
值得注意的是,NEJM CPC 并不代表日常临床实践。它们是仅针对数百人的不寻常病例报告,因此为探讨公平或公平等重要问题提供了有限的范围。
医疗保健领域大胆而负责任的研究
在世界各地,获得临床专业知识的机会仍然稀缺。虽然人工智能在特定的临床应用中显示出了巨大的前景,但参与临床实践的动态、对话式诊断过程需要人工智能系统尚未展示的许多功能。医生不仅拥有知识和技能,还致力于遵守无数原则,包括安全和质量、沟通、伙伴关系和团队合作、信任和专业精神。在人工智能系统中实现这些属性是一项鼓舞人心的挑战,应该负责任地、谨慎地对待。AMIE 是我们对“可能性的艺术”的探索,这是一个仅供研究的系统,用于安全地探索未来的愿景,其中人工智能系统可能会更好地与委托我们护理的熟练临床医生的属性保持一致。它只是早期的实验工作,而不是产品,并且有一些局限性,我们认为值得进行严格和广泛的进一步科学研究,以设想一个对话式、同理心和诊断式人工智能系统可能变得安全、有用和易于使用的未来。
参考:
AMIE: A research AI system for diagnostic medical reasoning and conversations