周赛377
文章目录
- 周赛377
-
- [2974. 最小数字游戏](https://leetcode.cn/problems/minimum-number-game/)
-
- 模拟
- [2975. 移除栅栏得到的正方形田地的最大面积](https://leetcode.cn/problems/maximum-square-area-by-removing-fences-from-a-field/)
-
- 贪心
- [2976. 转换字符串的最小成本 I](https://leetcode.cn/problems/minimum-cost-to-convert-string-i/)
-
- Floyd算法
- [2977. 转换字符串的最小成本 II](https://leetcode.cn/problems/minimum-cost-to-convert-string-ii/)
-
- Floyd算法 + DP
周赛377
2974. 最小数字游戏
简单
你有一个下标从 0 开始、长度为 偶数 的整数数组 nums ,同时还有一个空数组 arr 。Alice 和 Bob 决定玩一个游戏,游戏中每一轮 Alice 和 Bob 都会各自执行一次操作。游戏规则如下:
- 每一轮,Alice 先从
nums中移除一个 最小 元素,然后 Bob 执行同样的操作。 - 接着,Bob 会将移除的元素添加到数组
arr中,然后 Alice 也执行同样的操作。 - 游戏持续进行,直到
nums变为空。
返回结果数组 arr 。
示例 1:
输入:nums = [5,4,2,3]
输出:[3,2,5,4]
解释:第一轮,Alice 先移除 2 ,然后 Bob 移除 3 。然后 Bob 先将 3 添加到 arr 中,接着 Alice 再将 2 添加到 arr 中。于是 arr = [3,2] 。
第二轮开始时,nums = [5,4] 。Alice 先移除 4 ,然后 Bob 移除 5 。接着他们都将元素添加到 arr 中,arr 变为 [3,2,5,4] 。
示例 2:
输入:nums = [2,5]
输出:[5,2]
解释:第一轮,Alice 先移除 2 ,然后 Bob 移除 5 。然后 Bob 先将 5 添加到 arr 中,接着 Alice 再将 2 添加到 arr 中。于是 arr = [5,2] 。
提示:
1 <= nums.length <= 1001 <= nums[i] <= 100nums.length % 2 == 0
模拟
class Solution {
public int[] numberGame(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
int[] res = new int[n];
for(int i = 0; i < n; i += 2){
res[i] = nums[i+1];
res[i+1] = nums[i];
}
return res;
}
}
2975. 移除栅栏得到的正方形田地的最大面积
中等
有一个大型的 (m - 1) x (n - 1) 矩形田地,其两个对角分别是 (1, 1) 和 (m, n) ,田地内部有一些水平栅栏和垂直栅栏,分别由数组 hFences 和 vFences 给出。
水平栅栏为坐标 (hFences[i], 1) 到 (hFences[i], n),垂直栅栏为坐标 (1, vFences[i]) 到 (m, vFences[i]) 。
返回通过 移除 一些栅栏(可能不移除)所能形成的最大面积的 正方形 田地的面积,或者如果无法形成正方形田地则返回 -1。
由于答案可能很大,所以请返回结果对 109 + 7 取余 后的值。
**注意:**田地外围两个水平栅栏(坐标 (1, 1) 到 (1, n) 和坐标 (m, 1) 到 (m, n) )以及两个垂直栅栏(坐标 (1, 1) 到 (m, 1) 和坐标 (1, n) 到 (m, n) )所包围。这些栅栏 不能 被移除。
示例 1:
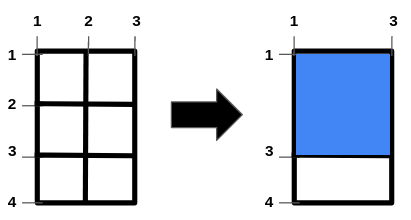
输入:m = 4, n = 3, hFences = [2,3], vFences = [2]
输出:4
解释:移除位于 2 的水平栅栏和位于 2 的垂直栅栏将得到一个面积为 4 的正方形田地。
示例 2:

输入:m = 6, n = 7, hFences = [2], vFences = [4]
输出:-1
解释:可以证明无法通过移除栅栏形成正方形田地。
提示:
3 <= m, n <= 1091 <= hFences.length, vFences.length <= 6001 < hFences[i] < m1 < vFences[i] < nhFences和vFences中的元素是唯一的。
贪心
class Solution {
/**
水平栅栏和垂直栅栏分开计算。
对于水平栅栏,计算出任意两个栅栏之间的距离,存到一个哈希表 h 中
对于垂直栅栏,计算出任意两个栅栏之间的距离,存到一个哈希表 v 中
答案就是 h 和 v 中的最大值(相等的)的平方
*/
public int maximizeSquareArea(int m, int n, int[] hFences, int[] vFences) {
List<Integer> hlist = new ArrayList<>();
for(int x : hFences) hlist.add(x);
hlist.add(1);
hlist.add(m);
List<Integer> vlist = new ArrayList<>();
for(int x : vFences) vlist.add(x);
vlist.add(1);
vlist.add(n);
Collections.sort(hlist);
Collections.sort(vlist);
Map<Integer, Integer> h = new HashMap<>();
Map<Integer, Integer> v = new HashMap<>();
for(int i = 0; i < hlist.size(); i++)
for(int j = i+1; j < hlist.size(); j++)
h.merge(hlist.get(j) - hlist.get(i), 1, Integer::sum);
int res = 0;
for(int i = 0; i < vlist.size(); i++){
for(int j = i+1; j < vlist.size(); j++){
int len = vlist.get(j) - vlist.get(i);
if(res < len && h.containsKey(len)) res = len;
}
}
return res == 0 ? -1 : (int)(((long) res * res) % (int)(1e9+7));
}
}
2976. 转换字符串的最小成本 I
中等
给你两个下标从 0 开始的字符串 source 和 target ,它们的长度均为 n 并且由 小写 英文字母组成。
另给你两个下标从 0 开始的字符数组 original 和 changed ,以及一个整数数组 cost ,其中 cost[i] 代表将字符 original[i] 更改为字符 changed[i] 的成本。
你从字符串 source 开始。在一次操作中,如果 存在 任意 下标 j 满足 cost[j] == z 、original[j] == x 以及 changed[j] == y 。你就可以选择字符串中的一个字符 x 并以 z 的成本将其更改为字符 y 。
返回将字符串 source 转换为字符串 target 所需的 最小 成本。如果不可能完成转换,则返回 -1 。
注意,可能存在下标 i 、j 使得 original[j] == original[i] 且 changed[j] == changed[i] 。
示例 1:
输入:source = "abcd", target = "acbe", original = ["a","b","c","c","e","d"], changed = ["b","c","b","e","b","e"], cost = [2,5,5,1,2,20]
输出:28
解释:将字符串 "abcd" 转换为字符串 "acbe" :
- 更改下标 1 处的值 'b' 为 'c' ,成本为 5 。
- 更改下标 2 处的值 'c' 为 'e' ,成本为 1 。
- 更改下标 2 处的值 'e' 为 'b' ,成本为 2 。
- 更改下标 3 处的值 'd' 为 'e' ,成本为 20 。
产生的总成本是 5 + 1 + 2 + 20 = 28 。
可以证明这是可能的最小成本。
示例 2:
输入:source = "aaaa", target = "bbbb", original = ["a","c"], changed = ["c","b"], cost = [1,2]
输出:12
解释:要将字符 'a' 更改为 'b':
- 将字符 'a' 更改为 'c',成本为 1
- 将字符 'c' 更改为 'b',成本为 2
产生的总成本是 1 + 2 = 3。
将所有 'a' 更改为 'b',产生的总成本是 3 * 4 = 12 。
示例 3:
输入:source = "abcd", target = "abce", original = ["a"], changed = ["e"], cost = [10000]
输出:-1
解释:无法将 source 字符串转换为 target 字符串,因为下标 3 处的值无法从 'd' 更改为 'e' 。
提示:
1 <= source.length == target.length <= 105source、target均由小写英文字母组成1 <= cost.length== original.length == changed.length <= 2000original[i]、changed[i]是小写英文字母1 <= cost[i] <= 106original[i] != changed[i]
Floyd算法
class Solution {
private static final int INF = Integer.MAX_VALUE / 2;
public long minimumCost(String source, String target, char[] original, char[] changed, int[] cost) {
int n = original.length;
int[][] g = new int[26][26];
// 初始化邻接表
for(int i = 0; i < 26; i++){
Arrays.fill(g[i], INF);
g[i][i] = 0;
}
for(int i = 0; i < original.length; i++){
int x = original[i] - 'a', y = changed[i] - 'a', cs = cost[i];
g[x][y] = Math.min(g[x][y], cs);
}
// Floyd算法
for(int k = 0; k < 26; k++){
for(int i = 0; i < 26; i++){
for(int j = 0; j < 26; j++){
g[i][j] = Math.min(g[i][j], g[i][k] + g[k][j]);
}
}
}
long res = 0;
for(int i = 0; i < source.length(); i++){
int x = source.charAt(i) - 'a', y = target.charAt(i) - 'a';
if(x == y) continue;
if(g[x][y] == INF) return -1;
res += g[x][y];
}
return res;
}
}
2977. 转换字符串的最小成本 II
困难
给你两个下标从 0 开始的字符串 source 和 target ,它们的长度均为 n 并且由 小写 英文字母组成。
另给你两个下标从 0 开始的字符串数组 original 和 changed ,以及一个整数数组 cost ,其中 cost[i] 代表将字符串 original[i] 更改为字符串 changed[i] 的成本。
你从字符串 source 开始。在一次操作中,如果 存在 任意 下标 j 满足 cost[j] == z 、original[j] == x 以及 changed[j] == y ,你就可以选择字符串中的 子串 x 并以 z 的成本将其更改为 y 。 你可以执行 任意数量 的操作,但是任两次操作必须满足 以下两个 条件 之一 :
- 在两次操作中选择的子串分别是
source[a..b]和source[c..d],满足b < c或d < a。换句话说,两次操作中选择的下标 不相交 。 - 在两次操作中选择的子串分别是
source[a..b]和source[c..d],满足a == c且b == d。换句话说,两次操作中选择的下标 相同 。
返回将字符串 source 转换为字符串 target 所需的 最小 成本。如果不可能完成转换,则返回 -1 。
注意,可能存在下标 i 、j 使得 original[j] == original[i] 且 changed[j] == changed[i] 。
示例 1:
输入:source = "abcd", target = "acbe", original = ["a","b","c","c","e","d"], changed = ["b","c","b","e","b","e"], cost = [2,5,5,1,2,20]
输出:28
解释:将 "abcd" 转换为 "acbe",执行以下操作:
- 将子串 source[1..1] 从 "b" 改为 "c" ,成本为 5 。
- 将子串 source[2..2] 从 "c" 改为 "e" ,成本为 1 。
- 将子串 source[2..2] 从 "e" 改为 "b" ,成本为 2 。
- 将子串 source[3..3] 从 "d" 改为 "e" ,成本为 20 。
产生的总成本是 5 + 1 + 2 + 20 = 28 。
可以证明这是可能的最小成本。
示例 2:
输入:source = "abcdefgh", target = "acdeeghh", original = ["bcd","fgh","thh"], changed = ["cde","thh","ghh"], cost = [1,3,5]
输出:9
解释:将 "abcdefgh" 转换为 "acdeeghh",执行以下操作:
- 将子串 source[1..3] 从 "bcd" 改为 "cde" ,成本为 1 。
- 将子串 source[5..7] 从 "fgh" 改为 "thh" ,成本为 3 。可以执行此操作,因为下标 [5,7] 与第一次操作选中的下标不相交。
- 将子串 source[5..7] 从 "thh" 改为 "ghh" ,成本为 5 。可以执行此操作,因为下标 [5,7] 与第一次操作选中的下标不相交,且与第二次操作选中的下标相同。
产生的总成本是 1 + 3 + 5 = 9 。
可以证明这是可能的最小成本。
示例 3:
输入:source = "abcdefgh", target = "addddddd", original = ["bcd","defgh"], changed = ["ddd","ddddd"], cost = [100,1578]
输出:-1
解释:无法将 "abcdefgh" 转换为 "addddddd" 。
如果选择子串 source[1..3] 执行第一次操作,以将 "abcdefgh" 改为 "adddefgh" ,你无法选择子串 source[3..7] 执行第二次操作,因为两次操作有一个共用下标 3 。
如果选择子串 source[3..7] 执行第一次操作,以将 "abcdefgh" 改为 "abcddddd" ,你无法选择子串 source[1..3] 执行第二次操作,因为两次操作有一个共用下标 3 。
提示:
1 <= source.length == target.length <= 1000source、target均由小写英文字母组成1 <= cost.length == original.length == changed.length <= 1001 <= original[i].length == changed[i].length <= source.lengthoriginal[i]、changed[i]均由小写英文字母组成original[i] != changed[i]1 <= cost[i] <= 106
Floyd算法 + DP
https://leetcode.cn/problems/minimum-cost-to-convert-string-ii/solutions/2577877/zi-dian-shu-floyddp-by-endlesscheng-oi2r/
class Solution {
/**
changed.length <= 100,可以把每个字符串变成一个整数编号(整体),这一步可以通过字典树完成
建图,从 o[i] 到 c[i] 连边,边权 cost[i]
用Floyd算法求图中任意两点最短路,即 dis[i][j] 表示编号为i的字串变成编号为j的字串的最小成本
定义 dfs(i) 表示从 source[i] 开始向后修改的最小成本
转移 若s[i] == t[i],可以不修改 dfs(i) = dfs(i+1)
也可以从s[i]开始向后修改,枚举所有字串编号
利用字典树快速判断s和t的下标从i到j的字串是否在original和changed中
如果在就用 dis[x][y] + dfs(j+1) 更新dfs(i)的最小值
递归边界 dfs(n) = 0
递归入口 dfs(0)
*/
private int[][] dis;
private char[] s, t;
private long[] memo;
public long minimumCost(String source, String target, String[] original, String[] changed, int[] cost) {
int m = cost.length;
dis = new int[m*2][m*2];
for(int i = 0; i < dis.length; i++){
Arrays.fill(dis[i], Integer.MAX_VALUE / 2);
dis[i][i] = 0;
}
for(int i = 0; i < cost.length; i++){
int x = insert(original[i]);
int y = insert(changed[i]);
dis[x][y] = Math.min(dis[x][y], cost[i]);
}
// floyd统计任意两点最短路
for(int k = 0; k < sid; k++){
for(int i = 0; i < sid; i++){
if(dis[i][k] == Integer.MAX_VALUE / 2)
continue;
for(int j = 0; j < sid; j++){
dis[i][j] = Math.min(dis[i][j], dis[i][k] + dis[k][j]);
}
}
}
// DP求修改成本,枚举以第i位为字符串起点的字串换还是不换
s = source.toCharArray();
t = target.toCharArray();
memo = new long[s.length];
Arrays.fill(memo, -1);
long ans = dfs(0);
return ans < Long.MAX_VALUE / 2 ? ans : -1;
}
public long dfs(int i){
if(i >= s.length){
return 0;
}
if(memo[i] != -1) return memo[i];
long res = Long.MAX_VALUE / 2;
// 当 s[i] = t[i],此时可以不修改
if(s[i] == t[i]){
res = dfs(i+1);
}
// 以 s[i] 为字符串第一个字符,枚举转移
TrieNode p = root, q = root;
for(int j = i; j < s.length; j++){
p = p.child[s[j] - 'a'];
q = q.child[t[j] - 'a'];
if(p == null || q == null)
break;
if(p.sid < 0 || q.sid < 0){
continue;
}
// 修改从 i 到 j 的这一段
int d = dis[p.sid][q.sid];
if(d < Integer.MAX_VALUE / 2){
res = Math.min(res, d + dfs(j + 1));
}
}
return memo[i] = res;
}
int sid = 0; // 编号总数
class TrieNode{//字典树的结点数据结构
boolean end;//是否是单词末尾的标识
int pass; // 经过这个结点的次数(根据需要设置这个变量)
TrieNode[] child; //26个小写字母的拖尾
int sid; // 字符串编号
public TrieNode(){
end = false;
pass = 0;
sid = -1;
child = new TrieNode[26];
}
}
TrieNode root = new TrieNode();
public int insert(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
//若当前结点下没有找到要的字母,则新开结点继续插入
if (p.child[u] == null) p.child[u] = new TrieNode();
p = p.child[u];
p.pass++;
}
p.end = true;
if(p.sid < 0)
p.sid = sid++;
return p.sid;
}
}