PyTorch常用操作
0. 先决条件
安装驱动、CUDA、cuDNN,请参考:https://blog.csdn.net/liugan528/article/details/128974129
import torch
print(torch.__version__)
#查看gpu是否可用
print(torch.cuda.is_available())
#查看设备gpu个数
print(torch.cuda.device_count())
#查看torch对应CUDA版本号
print(torch.backends.cudnn.version())
print(torch.version.cuda)
1. PyTorch安装
https://pytorch.org/get-started/locally/
根据自己的配置选择相应的标签得到提示的安装指令进行安装:
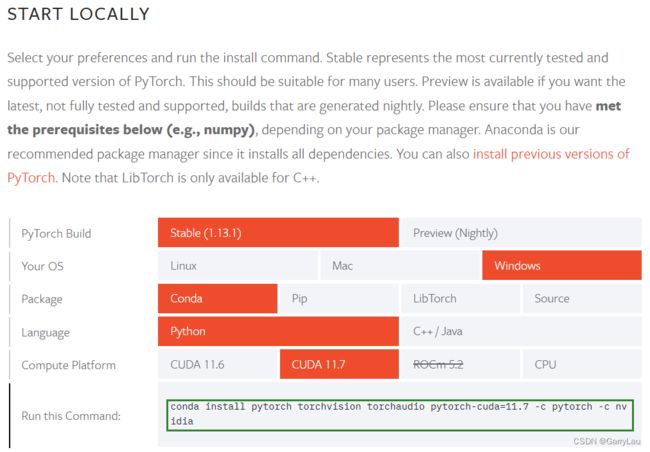
- 安装完毕之后测试是否安装成功
import torch
x = torch.rand(5, 3)
print(x)
输出结果:
tensor([[0.6336, 0.6199, 0.3328, 0.9812],
[0.5288, 0.5243, 0.9603, 0.1340],
[0.9176, 0.2647, 0.5914, 0.9771],
[0.5646, 0.4666, 0.6248, 0.0663],
[0.5966, 0.4487, 0.8861, 0.4725]])
- 查看GPU驱动和CUDA是否可被pytorch启用
import torch
torch.cuda.is_available()
如果能正常启用则输出:True
2. 基本操作
2.1 Tensor与numpy的互转
函数名后面带下划线_的函数会修改Tensor本身,例如x.add_(1)会改变x,但x.add(1)会返回一个新的Tensor而x不变。
Tensor和numpy的数组可以相互转换,它们之间共享内存,如果其中一个变了另外一个也会随之改变。
Tensor转numpy
import torch
import numpy as np
a = torch.ones(3,2)
b = a.numpy()
print('a = ', a)
print('b = ', b)
print('-------------------------------------')
a.add_(1)
print('a = ', a)
print('b = ', b)
输出:
a = tensor([[1., 1.],
[1., 1.],
[1., 1.]])
b = [[1. 1.]
[1. 1.]
[1. 1.]]
-------------------------------------
a = tensor([[2., 2.],
[2., 2.],
[2., 2.]])
b = [[2. 2.]
[2. 2.]
[2. 2.]]
numpy转Tensor
import torch
import numpy as np
a = np.ones([3,2])
b = torch.from_numpy(a)
print('a = ', a)
print('b = ', b)
print('-------------------------------------')
b.add_(1)
print('a = ', a)
print('b = ', b)
输出:
a = [[1. 1.]
[1. 1.]
[1. 1.]]
b = tensor([[1., 1.],
[1., 1.],
[1., 1.]], dtype=torch.float64)
-------------------------------------
a = [[2. 2.]
[2. 2.]
[2. 2.]]
b = tensor([[2., 2.],
[2., 2.],
[2., 2.]], dtype=torch.float64)
2.2 Tensor的.cuda方法可以将Tensor转换为GPU的Tensor从而享受GPU带来的加速运算
未使用CUDA加速
import torch
x = torch.ones(5)
y = torch.zeros(5)
print(x + y)
输出:
tensor([1., 1., 1., 1., 1.])
使用CUDA加速
import torch
x = torch.ones(5)
y = torch.zeros(5)
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
print(x + y)
输出:
tensor([1., 1., 1., 1., 1.], device='cuda:0')
2.3 自动求导
import torch
from torch import autograd
x = torch.tensor(1.)
a = torch.tensor(1., requires_grad=True)
b = torch.tensor(2., requires_grad=True)
c = torch.tensor(3., requires_grad=True)
y = a ** 2 * x + b * x + c
print(a.grad, b.grad, c.grad) # 输出 None None None
grads = autograd.grad(y, [a, b, c])
# 输出 tensor(2., dtype=torch.float64) tensor(1., dtype=torch.float64) tensor(1., dtype=torch.float64)
print(grads[0], grads[1], grads[2])