基于pytorch的循环神经网络情感分析系统
任务目标
基于给定数据集,进行数据预处理,搭建以LSTM为基本单元的模型,以Adam优化器对模型进行训练,使用训练后的模型进行预测并计算预测分类的准确率。
数据简介
IMDB数据集是一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。
已知数据集中数据格式如下
1、读取数据
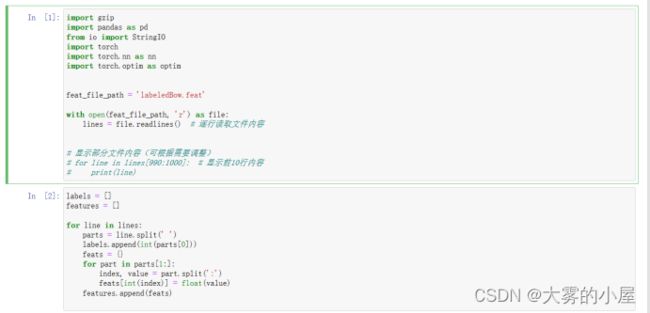
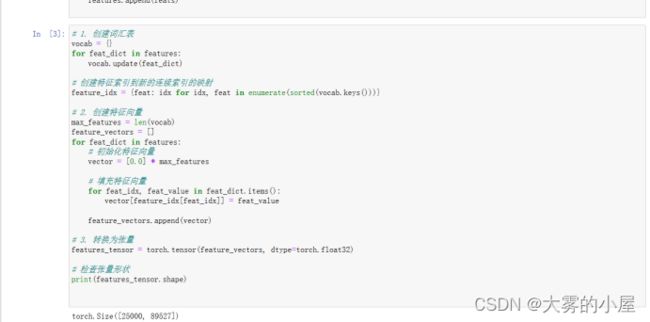
2、数据预处理
首先,对于创建词汇表,记录每一个单词出现的频率,并由此将特征数据集转为特征向量。最后转化为tensor格式
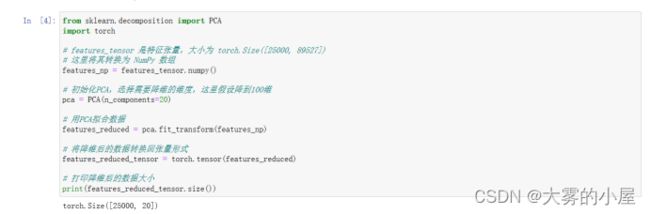
由于数据量庞大,这里先用PCA将数据降维,这里选择降到20个维度
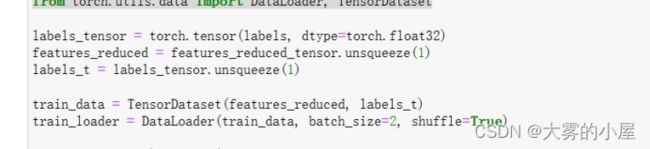
将特征数据集和标签进行匹配,并每两个数据作为一个批次,全部数据进行随机的打乱
模型构建
这里采用pytorch中的LSTM来得到LSTM层的状态

LSTM层总共设置4层,传入初始隐藏状态的细胞内容和输入内容。最后取得最后的时间步的输出
模型训练
损失函数选择均方误差函数,优化器选择了Adam优化,总共训练4个epoch
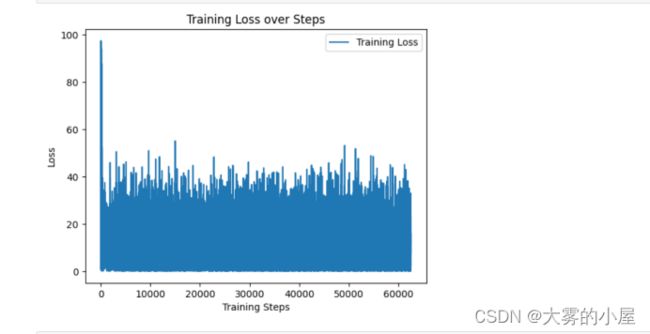
损失值变化图像
绘制出损失值的变化图像
模型评估
将测试集的内容导入并做和训练集一样的预处理,然后将测试集放入模型中,将均方误差作为评价标准,计算平均误差。
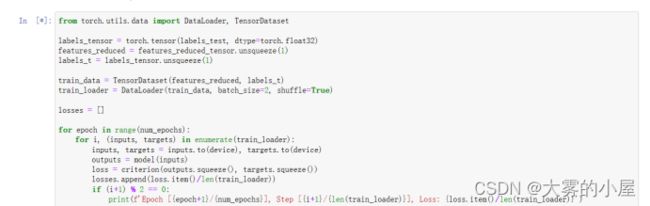
并绘制出误差图像
误差都在0.003到0.005之间,说明模型能够正确预测情感。
完整代码
import gzip
import pandas as pd
from io import StringIO
import torch
import torch.nn as nn
import torch.optim as optim
feat_file_path = 'labeledBow.feat'
with open(feat_file_path, 'r') as file:
lines = file.readlines() # 逐行读取文件内容
# 显示部分文件内容(可根据需要调整)
# for line in lines[990:1000]: # 显示前10行内容
# print(line)
# In[2]:
labels = []
features = []
for line in lines:
parts = line.split(' ')
labels.append(int(parts[0]))
feats = {}
for part in parts[1:]:
index, value = part.split(':')
feats[int(index)] = float(value)
features.append(feats)
# In[3]:
# 1. 创建词汇表
vocab = {}
for feat_dict in features:
vocab.update(feat_dict)
# 创建特征索引到新的连续索引的映射
feature_idx = {feat: idx for idx, feat in enumerate(sorted(vocab.keys()))}
# 2. 创建特征向量
max_features = len(vocab)
feature_vectors = []
for feat_dict in features:
# 初始化特征向量
vector = [0.0] * max_features
# 填充特征向量
for feat_idx, feat_value in feat_dict.items():
vector[feature_idx[feat_idx]] = feat_value
feature_vectors.append(vector)
# 3. 转换为张量
features_tensor = torch.tensor(feature_vectors, dtype=torch.float32)
# 检查张量形状
print(features_tensor.shape)
# In[4]:
from sklearn.decomposition import PCA
import torch
# features_tensor 是特征张量,大小为 torch.Size([25000, 89527])
# 这里将其转换为 NumPy 数组
features_np = features_tensor.numpy()
# 初始化PCA,选择需要降维的维度,这里假设降到100维
pca = PCA(n_components=20)
# 用PCA拟合数据
features_reduced = pca.fit_transform(features_np)
# 将降维后的数据转换回张量形式
features_reduced_tensor = torch.tensor(features_reduced)
# 打印降维后的数据大小
print(features_reduced_tensor.size())
# In[5]:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
labels_tensor = torch.tensor(labels, dtype=torch.float32)
features_reduced = features_reduced_tensor.unsqueeze(1)
labels_t = labels_tensor.unsqueeze(1)
train_data = TensorDataset(features_reduced, labels_t)
train_loader = DataLoader(train_data, batch_size=2, shuffle=True)
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=4):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出
return out
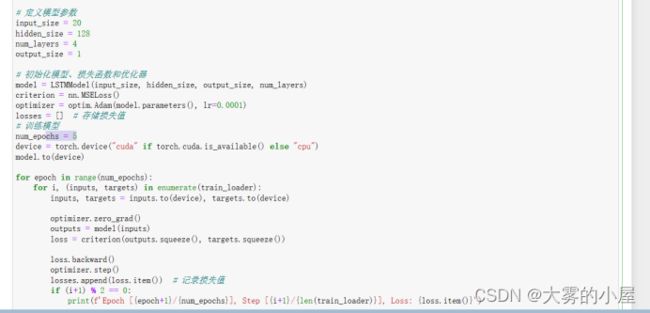
# 定义模型参数
input_size = 20
hidden_size = 128
num_layers = 4
output_size = 1
# 初始化模型、损失函数和优化器
model = LSTMModel(input_size, hidden_size, output_size, num_layers)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
losses = [] # 存储损失值
# 训练模型
num_epochs = 5
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
for i, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs.squeeze(), targets.squeeze())
loss.backward()
optimizer.step()
losses.append(loss.item()) # 记录损失值
if (i+1) % 2 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()}')
# In[6]:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
# 绘制损失值变化图
plt.plot(losses, label='Training Loss')
plt.xlabel('Training Steps')
plt.ylabel('Loss')
plt.title('Training Loss over Steps')
plt.legend()
plt.show()
# In[7]:
feat_file_path = 'labeledBow_test.feat'
with open(feat_file_path, 'r') as file:
lines = file.readlines() # 逐行读取文件内容
labels_test = []
features_test = []
for line in lines:
parts = line.split(' ')
labels_test.append(int(parts[0]))
feats = {}
for part in parts[1:]:
index, value = part.split(':')
feats[int(index)] = float(value)
features_test.append(feats)
# In[8]:
# 1. 创建词汇表
vocab = {}
for feat_dict in features_test:
vocab.update(feat_dict)
# 创建特征索引到新的连续索引的映射
feature_idx = {feat: idx for idx, feat in enumerate(sorted(vocab.keys()))}
# 2. 创建特征向量
max_features = len(vocab)
feature_vectors = []
for feat_dict in features_test:
# 初始化特征向量
vector = [0.0] * max_features
# 填充特征向量
for feat_idx, feat_value in feat_dict.items():
vector[feature_idx[feat_idx]] = feat_value
feature_vectors.append(vector)
# 3. 转换为张量
features_tensor = torch.tensor(feature_vectors, dtype=torch.float32)
# 检查张量形状
print(features_tensor.shape)
# In[9]:
from sklearn.decomposition import PCA
import torch
# features_tensor 是特征张量,大小为 torch.Size([25000, 89527])
# 这里将其转换为 NumPy 数组
features_np = features_tensor.numpy()
# 初始化PCA,选择需要降维的维度,这里假设降到100维
pca = PCA(n_components=20)
# 用PCA拟合数据
features_reduced = pca.fit_transform(features_np)
# 将降维后的数据转换回张量形式
features_reduced_tensor = torch.tensor(features_reduced)
# 打印降维后的数据大小
print(features_reduced_tensor.size())
# In[14]:
from torch.utils.data import DataLoader, TensorDataset
labels_tensor = torch.tensor(labels_test, dtype=torch.float32)
features_reduced = features_reduced_tensor.unsqueeze(1)
labels_t = labels_tensor.unsqueeze(1)
train_data = TensorDataset(features_reduced, labels_t)
train_loader = DataLoader(train_data, batch_size=2, shuffle=True)
losses = []
for epoch in range(num_epochs):
for i, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs.squeeze(), targets.squeeze())
losses.append(loss.item()/len(train_loader))
if (i+1) % 2 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()/len(train_loader)}')
# In[15]:
plt.plot(losses, label='Training Loss')
plt.xlabel('Training Steps')
plt.ylabel('Loss')
plt.title('Training Loss over Steps')
plt.legend()
plt.show()