[论文精读]BrainGB: A Benchmark for Brain Network Analysis With Graph Neural Networks
论文网址:BrainGB: A Benchmark for Brain Network Analysis With Graph Neural Networks | IEEE Journals & Magazine | IEEE Xplore
论文代码:GitHub - HennyJie/BrainGB: Officially Accepted to IEEE Transactions on Medical Imaging (TMI, IF: 11.037) - Special Issue on Geometric Deep Learning in Medical Imaging.
BrainGB网站:https://braingb.us
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
1. 省流版
1.1. 心得
1.2. 论文总结图
2. 论文逐段精读
2.1. Abstract
①At present, there is still a lack of systematic research on brain network analysis(啥是脑网络分析的系统研究?)
②They proposed Brain Graph Neural Network Benchmark (BrainGB) to construct pipelines and modularize its implementation
2.2. Introduction
①The interactions between brain regions are decisive factors of analysing neurology and diseases
②Their contributions are: a) establishing a unified framework and evaluation criteria, b) summarizing the reprocessing and building pipeline of fMRI and sMRI, c) setting baselines as node features, message passing mechanisms, attention mechanisms, and pooling strategies
③Overall framework:
![[论文精读]BrainGB: A Benchmark for Brain Network Analysis With Graph Neural Networks_第1张图片](http://img.e-com-net.com/image/info8/2ffeda171bf64a1eb5fb6b9dbfa0f0c7.jpg)
motif n.(文学作品或音乐的)主题;装饰图案;动机;主旨
2.3. Preliminaries
2.3.1. Brain Network Analysis
①Brain network dataset is ![]() with
with  subjects, where
subjects, where ![]() ,
, 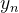 is the true label,
is the true label, ![]() denotes
denotes  nodes (ROIs),
nodes (ROIs), ![]() denotes edges. The output of model is prediction
denotes edges. The output of model is prediction ![]()
②Graph kernels and tensor factorization are too shallow to analyse the complicate brain structure
aberration n.异常行为;反常现象;脱离常规
2.3.2. Graph Neural Networks
①There are 3 differences between brain network and other graph: a) brain network is lack of node features, b) weights of connection can be positive or negative, c) ROI is fixed
2.4. Brain Network Dataset Construction
2.4.1. Background: Diverse Modalities of Brain Imaging
There is a lot of scanning technology: Magnetic-Resonance Imaging (MRI), Electroencephalography (EEG) and Magnetoencephalography (MEG), Positron Emission Tomography (PET), Single-Photon Emission Computed Tomography (SPECT), and X-ray Computed Tomography (CT) etc.
(1)MRI Data
①Functional MRI (fMRI) indicates changes in blood oxygen and blood flow and reveals the functional activities
②Diffusion-weighted MRI (dMRI) fits brain structure through molecular (usually water) motion trajectories
trajectory n.轨迹;(射体在空中的)轨道;弹道
(2)Challenges in MRI Preprocessings
①There are preprocessing tools like SPM, AFNI and FSL. However, it really takes time to learn them or use them
②None of a tool contains all the preprocessing functions of dMRI
③The publicity of datasets is also a big problem
④For different modalities, they need different methods of preprocessing
2.4.2. Brain Network Construction From Raw Data
(1)Functional Brain Network Construction
①Some preprocessing functions in different tools:
![[论文精读]BrainGB: A Benchmark for Brain Network Analysis With Graph Neural Networks_第2张图片](http://img.e-com-net.com/image/info8/128c7d8be64b4c1f9a38ea9ae13e4cc7.jpg)
②There are partial correlations, mutual information, coherence, Granger causality etc. as the pairwise correlations between ROIs
(2)Structural Brain Network Construction
①Some preprocessing functions in different tools:
![[论文精读]BrainGB: A Benchmark for Brain Network Analysis With Graph Neural Networks_第3张图片](http://img.e-com-net.com/image/info8/8637783ad27946ba98271485651f1e6d.jpg)
2.4.3. Discussions
The combination of sMRI and fMRI might be more effective than single modality
metabolic adj.代谢的;新陈代谢的
2.5. GNN Baselines for Brain Network Analysis
2.5.1. Node Feature Construction
①Identity: give one hot feature vector for each node
②Eigen: similar to PCA...
③Degree: a one dimension vector that records the degree of one node
④Degree profile:
![]()
⑤Connection profile: each row of one node is the original node feature
2.5.2. Message Passing Mechanisms
①The node feature ![]() in layer
in layer  firstly get message from neighbors through sum operation:
firstly get message from neighbors through sum operation:
![]()
where ![]() represents all the neighbors of node
represents all the neighbors of node  ,
, 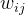 denotes the edge weights between node and
denotes the edge weights between node and  ,
, ![]() denotes the message function
denotes the message function
②They secondly update with:
![]()
where ![]() can be any differentiable function
can be any differentiable function
③They ![]() might be influenced on:
might be influenced on:
| egde wights | Aggregation as in GCN, 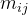 is related to the edge weight value is related to the edge weight value |
| bin concat | Set  buckets, trying it in [5, 10, 15, 20]. Each bucket possesses its own expression buckets in ascending order. Then, followed by an MLP: buckets, trying it in [5, 10, 15, 20]. Each bucket possesses its own expression buckets in ascending order. Then, followed by an MLP: |
| edge weight concat |  is the dimension of node feature. Such scaling extends the impact of edge feature is the dimension of node feature. Such scaling extends the impact of edge feature |
| node edge concat | |
| node concat |
2.5.3. Attention-Enhanced Message Passing
2.5.4. Pooling Strategies
2.6. Experimental Analysis and Insights
2.6.1. Experimental Settings
(1)Datasets
(2)Baselines
(3)Implementation Details
2.6.2. Performance Report
(1)Node Feature
(2)Message Passing
(3)Attention Enhanced Message Passing
(4)Pooling Strategies
(5)Other Baselines
(6)Insights on Density Levels
2.7. Open Source Benchmark Platform
2.8. Discussion and Extensions
3. BrainGB库/代码
参见另一篇文章
4. Reference List
Cui H. et al. (2023) 'BrainGB: A Benchmark for Brain Network Analysis With Graph Neural Networks', IEEE Transactions on Medical Imaging, 42 (2), pp. 493-506. doi" 10.1109/TMI.2022.3218745