【论文阅读】Progressive Prompts: Continual Learning for Language Models
论文信息
论文标题
Progressive Prompts: Continual Learning for Language Models
发表刊物
ICLR2023
作者团队
多大、Meta AI
关键词
Continual Learing、LLMs
文章结构
引言
研究动机
Progressive Prompts allows forward transfer and resists catastrophic forgetting, without relying on data replay or a large number of task-specific parameters.
任务背景
Intro-P1:
- Learning a long sequence of tasks while gaining experience and avoiding forgetting remains a key feature of human-level intelligence.
- Although pretrained language models have largely succeeded in learning on a single task, their performance degrades in scenarios where multiple tasks are encountered sequentially, also known as continual learning (CL).
- avoiding catastrophic forgetting, i.e., loss of the knowledge acquired from previous tasks after learning new ones
- allowing forward transfer, i.e., leveraging the knowledge from past tasks for efficient learning of new tasks.
背景的第一段包括三句话。第一句话说明了在human-level层面的智能要求模型能够学习解决一长串儿的任务而不忘记过去任务的能力。第二句话用了转折关系,提出尽管预训练语言模型在解决单一任务上很强,但是在多个任务连续出现时,性能还是会下降,这种学习模型被称为持续学习。第三句话,概括了持续学习的两大挑战:一是避免灾难性遗忘,即模型在学习新的任务后不能忘记如何解决旧任务;二是允许前向转移,即利用过去任务的知识能够快速学习新知识。
第一段之所以这么写,是为了交代研究背景和研究对象,让读者了解我们关心的问题所在,即CF和FT,为第二段介绍传统方法及其优缺点打下基础。
Intro-P2:
- Typical CL approaches for language models train a model on all tasks, which ensures forward transfer but also leads to forgetting. These methods use data replay or add regularization constraints, but they still suffer from forgetting due to inevitable changes in parameters shared between tasks.
- Other approaches, such as progressive networks, can alleviate catastrophic forgetting completely while supporting forward transfer, but are computationally expensive because they add a new copy of the model for each task. This can be especially intractable for large-scale language models with billions of parameters, which have become a standard in the NLP field.
背景的第二段可分为两部分。第一部分介绍了传统持续学习方法的解决思想。通过在所有任务上都进行训练,传统方法能够做到前向迁移学习能力,但是无法避免灾难性遗忘。这是由于传统方法通过数据复习或者添加正则化限制的方式来减少遗忘,但在不同任务中的模型共享的参数会发生改变,这就难以避免“顾此失彼”的情况发生。第二部分将话题引入到了本文章采用的方法领域,progressive networks 进步网络,一种能够在支持前向迁移能力的前提下还能彻底避免灾难性遗忘的网络。但由于给每个任务复制了一份模型参数,导致开销巨大。所以这种方法也是不可行的,尤其是在数亿参数的大语言模型已经成为NLP领域的基准模型的情况下。
第二段之所以这么写,是为了突出本文工作的重要性。将以前的工作分为A和B两个方向,介绍A的优势和缺点,再介绍B的优势和缺点,与第一段提出CL领域关心的两个问题对应,同时也为下文提出我们自己的方法做铺垫。
Intro-P3:
- In this paper, we introduce Progressive Prompts – a novel CL approach for language models that supports forward transfer without forgetting.
- Our method is inspired by progressive networks, but is significantly more memory-efficient because it only learns a fixed number of tokens, or prompt, for each new task.
- Learning a prompt to adapt language models on a single downstream task was introduced in prompt tuning , and was shown to match the performance of full model finetuning while training <0.01% of the parameters.
- In Progressive Prompts, we learn a separate prompt for each incoming task and sequentially concatenate it with previously learned prompts. Importantly, we share input tokens across all tasks and progressively prepend new prompts while keeping previous prompts frozen (see Figure 1).
- Our method can: 1) alleviate catastrophic forgetting by preserving the knowledge acquired in previous prompts, and 2) transfer knowledge to future tasks by sequentially learning new prompts given previous ones. We also introduce a new technique for prompt embedding reparameterization. We show that by passing the prompt embeddings through a residual MLP we can stabilize prompt tuning and improve its performance.
凌晓峰教授在《学术研究,你的成功之道》一书中说过,写作是introduction是abstract的扩充版本。摘要里只说一句 “Progressive Prompts learns a new soft prompt for each task and sequentially concatenates it with the previously learned prompts, while keeping the base model frozen.”而在此段中,想表达同样的意思却用了5句话。第一句总说,介绍了我们提出的方法Progressive Prompts及其优势(FT+wCF),与前面提到的CL两个核心问题相照应。第二句话强调了工作的创新性,也就是说虽然进步网络不是我原创工作,但是我们对其进行了改进,只学习固定数量的tokens或叫prompt,而不是针对每个任务,这对内存开销是个重大的优化。第三句说明了prompt tuning 是较为流行的方法,以加强我们提出的这种方法的可行性。第四句话则是详细地说明了我们提出的网络是如何实现的,对每个即将来到的任务都用一个prompt与之对应,然后将不同的prompt先后拼接在一起。还强调了,在逐步拼接的过程中保持先前的tokens保持不变。这个思想也很直接,就是用不同的token表示解决不同任务的能力,新任务来了就学习解决新任务的能力,而将以前的token固定住就是想让模型不改变模型解决过去任务的能力,以缓解灾难性遗忘。此外,作者还利用了残差MLP来提高prompt tuning 的稳定性和表现。值得一提的是,作者在论文中将模型主图放在了第一段的这个位置,通过对比传统的进步网络和基于prompts的进步网络来让读者进一步理解本文的方法。与对比自己的工作是将主图放在正文的第三部分即Method部分,这两种放置图片的位置会对读者理解的效果带来哪些不同,大家可以自己思考体会一下。
Intro-P4:
- We run extensive experiments on standard CL benchmarks for text classification, and show that Progressive Prompts outperforms state-of-the-art approaches on both BERT and T5 architectures. We show over 20% improvement over the current SOTA for T5 model.
- Furthermore, we run experiments on a more challenging CL setup with longer task sequences, and show that our method outperforms prior approaches for T5 and BERT architectures.
- Our main contributions in this paper are as follows:
- We propose a novel CL approach, Progressive Prompts, that alleviates catastrophic forgetting and supports knowledge transfer to future tasks – all while learning < 0.1% of the total parameters.
- Progressive Prompts is suitable for any transformer-based architecture. We show that it significantly outperforms prior SOTA methods on standard CL benchmarks for both BERT and T5 models.
- We propose a more challenging CL setup encompassing 15 text classification tasks and show that our method significantly outperforms prior methods.
在实验环节,本文的实验环节还是非常sound的。数据集上分为(1)传统CL benchmark,包括5个文本分类任务,还根据不同模型(Bert、T5)设置了不同的任务出现的顺序;(2)大量任务。传统CL任务往往是3-5个任务以不同顺序进行,任务数量太少,相比于真实的CL环境差距较大。因此,本文构建了一个15个文本分类任务的benchmark。(3)迁移学习实验。将实验分为几组,每组的任务都用相似的数据集例如A和B,测试模型在A上学习了以后对在B上性能有没有提升。
技术背景
FineTuning
不具体介绍,可查阅资料。
Prompt Tuning
不具体介绍,可查阅资料。
Continual Learning
这里需要重点讨论一点,就是关于持续学习的setup。本文在2.3节中介绍setup时认为在一连串的任务之间是有边界的,也就是说每条文本数据和对应的分类标签来自于哪个数据集这个信息是提供给模型的。但在实际场景中,这个信息往往不会提供给模型。也就是说,模型在预测阶段不知道当前文本数据来自哪个数据集,只是给你一个文本让你去判断,这样难度便大大增加。正是这一点,reviewers一致认为这是本文的硬伤,几乎拒稿。最后PC考虑到本文在LLMs做持续学习的先行性最后放了一马。但这一点在未来工作中是不可忽视的。
创新方法
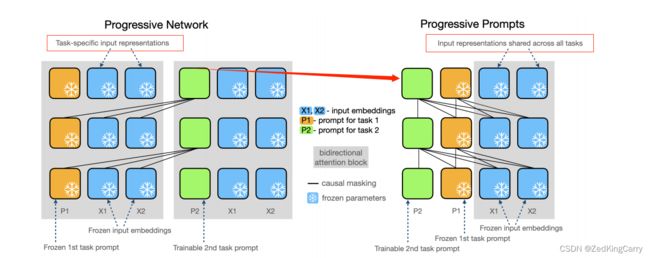
下面,我们主要根据模型结构图来具体理解本文的方法。左侧是传统方法,右侧是文本改进的方法。比较明显的区别有两个。一是传统方法对每个任务都新增一个灰色的bidirection attention block,而新方法只有一个,新增的是tokens。二是传统方法不同任务之间有不同的task-specific input representations 而新方法是共享参数(input representations shared across all tasks)。特别地,这里作者提到 “prompts learned on previous tasks allow information re-use for future tasks. A similar phenomenon has been shown by Vu et al. (2021) – prompts learned on informative source tasks served as a good initialization for other downstream tasks.” 从初始化的角度解释了不同任务对应的prompt tokens之间的关系。此外,还使用了Embedding reparameterization (残差)技术来提高prompt tuning 稳定性。
实验环节
实验设置
数据集
见intro第四段;
baselines
- Finetune: train all model parameters on a sequence of tasks (without adding any regularization constraints or replaying samples from the previous tasks).
- EWC: finetune the whole model with a regularization loss that prevents updating parameters that could interfere with previously learned tasks.
- A-GEM: save examples from the past tasks and restrict the gradients used to update the model on new tasks based on the retrieved examples.
- Experience replay: finetune the whole model with a memory buffer, and replay samples from old tasks when learning new tasks to avoid forgetting.
- MBPA++: augment BERT with an episodic memory that saves all seen examples. Perform replay during training, and local adaptation during test time.
- IDBR: BERT-specific approach which continuously trains the whole model using data replay and a regularization loss, which applies sentence representation disentanglement into task-specific and task-generic spaces. Current SOTA on CL benchmark with BERT.
- Per-task prompts: train a separate soft prompt for each task, while keeping the original model frozen. This setup will eliminate catastrophic forgetting, since per-task parameters do not change when new tasks are learned, but will not result in forward transfer.
- PromptTuning: train a shared soft prompt sequentially on all tasks, while keeping the original model parameters frozen.
- LFPT5: continuously train a soft prompt that simultaneously learns to solve the tasks and generate training samples, which are subsequently used in experience replay. Current
SOTA on CL benchmark with T5.
实现细节
Progressive Prompts与模型无关,可以用在任意的transformer-based任务上。
- encoder-only: BERT
- text-to-text: T5 (脚注里解释了虽然有人说T5 v1.1版本比T5效果更好,但是前者在prompt tuning过程中不如T5稳定,因此本文还是采用了T5。这里是预判review提问,提前解释。)
- Prompt length:每个任务对应的prompt tokens的数量
附录里详细介绍了实验细节。
实验结果
For all CL experiments we evaluate methods after training on all tasks and report averaged test set scores across all tasks. 全部训完了再测试。
实验一:CL benchmark

上表基于T5-large。3runs的平均值。few-shot。*表示只train了soft prompt,没标*的动了整个模型参数。DR ->(data replay)。其他符号表示结果是引用其他paper的,不是自己复现的。
正文关于表1的解释:
- SOTA是52.7,新方法是75.1具有较大提升,这印证了新方法做到了克服CF同时保证FT(论证本文中心论点);
- 作者用了2个长句子解释了Adapter-Fusion方法是比LFPT5更强的baseline,但这里为什么没对比是因为本文关注的都是prompt tuning的,adapter tuning的就不考虑了。(这里也是预判review提问,提前解释。)
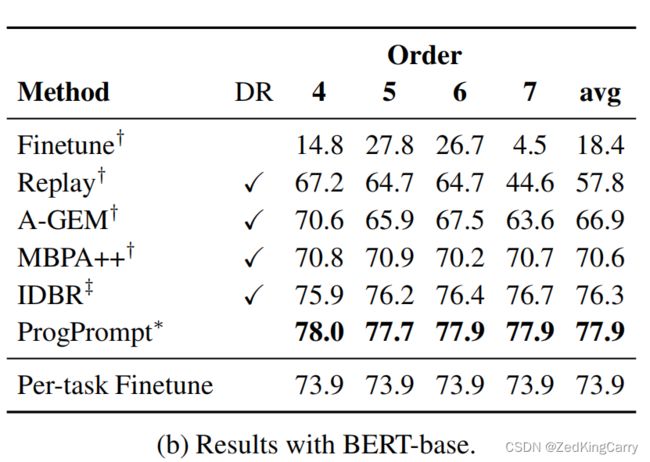
上表基于Bert-base。3runs的平均值。full datasets。其他符号同上。
正文关于表2的解释:
- SOTA是76.3,新方法是77.9,有提升。
- IDBR是Bert专属方法,而本文方法是通用的。
- 新方法不需要DR。
- 用了残差重参数技巧帮助训练稳定,具体分析放在附录;
实验二:长序列任务
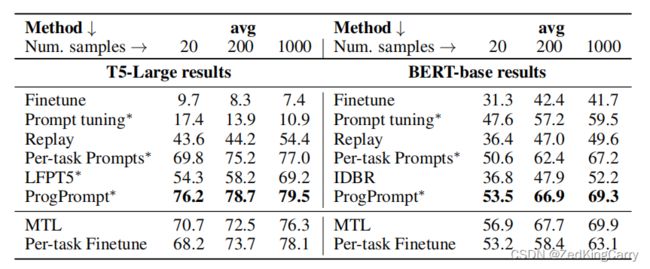
样本数量20,200,1000;MTL: multi-task learning;
正文关于表3的解释:
- 比SOTA高了21.9%和33.3%,确实是明显的提高;
- 除了avg acc,还用了forward transfer 和 backward transfer两个指标,放在了附录B;
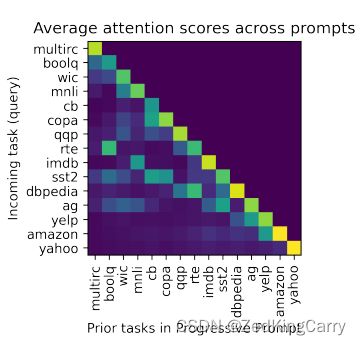
Attention between prompts
作者在长序列实验中贴了一张average attention scores的图片,用prompt之间的attention验证prompt对于学习的影响。例如,图中yelp和amazon相似度高 (黄色),sst2和imdb相似度高。
作者这里用T5 encoder编码了所有任务文本,取最后一层的attention matrices平均值发现了相似规律。这里任务相似可以得到prompt tokens的attention matrices相似。进一步思考:之前学习的任务如何帮助后面相似的任务进一步学习呢?在lora微调过程如何对应prompt token这种情况呢?
实验三:前向迁移实验

prompt tuning直接用100个tokens在target task上训练;progressive prompt先用50个训task1,再用50个训task2(task1的token固定)。
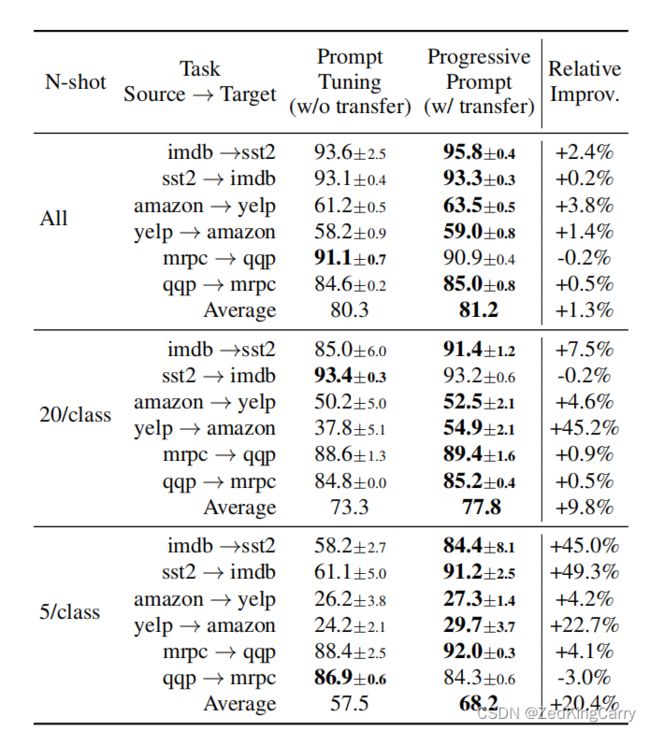
all datasets and few-shot; prompt tuning没有迁移能力,progressive prompt有迁移能力;误差区间,相对提升,整体平均;另外这个relative improv是怎么算出来的,直接两个相减好像不对;
该实验的目的是想证明,在A任务上先训练过再到B任务上训练后,模型在B上的测试表现比直接在B上训练的测试表现要高,从而证明模型是有迁移学习的能力;

随着每类中样本数量增加,两个模型的平均表现(6个任务)增加,但Prog Prompt比Prompt Tuning表现更好。
GLEU->SuperGLEU transfer
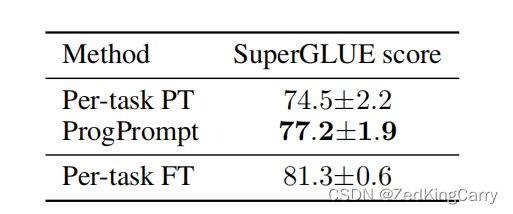
传统prompt tuning: P T P_T PT is a trainable matrix of 100 × e \times e ×e dimension->cat input-> [ P T ; x ] [P_T; x] [PT;x] 直接在SuperGLEU上训练和测试;
Progressive Prompt: [ P T P r o g ; P G L U E ; x ] [P_{T_{Prog}};P_{GLUE};x] [PTProg;PGLUE;x],其中 P T P r o g P_{T_{Prog}} PTProg 40 × e \times e ×e, P G L E U P_{GLEU} PGLEU 60 × e \times e ×e 先在GLEU上训练(60% prompt tokens)再在SuperGLUE(40%prompt tokens)上训练和测试;
相关工作
持续学习
经典三分类:replay, regularization, architecture,介绍了做法和优缺点
Parameter-efficient Learning
PEFT+CL: Adapter CL, LFPT5 但在CF和FT之间存在trade-off.
文献引用
CL
- A-GEM、MBPA++、EWC、LwF、GEM
- Continual learning for text classification with information disentanglement based regularization.
- Continual learning in task-oriented dialogue systems.
- Catastrophic interference in connectionist networks: The sequential learning problem.
- Adapter-fusion: Non-destructive task composition for transfer learning.
- Lfpt5: A unified framework for lifelong few-shot language learning based on prompt tuning of t5.
- Continual unsupervised representation learning.
- Connectionist models of recognition memory: constraints imposed by learning and forgetting functions.
- Experience replay for continual learning.
- Lamol: Language modeling for lifelong language learning.
- Efficient meta lifelong learning with limited memory.
Model & FineTuning
- Bert、T5、adapter、Adam、Prefix-tuning、 P-tuning v2、Pytorch、Glue、Superglue、 Huggingface’s transformers
- Compacter: Efficient low-rank hypercomplex adapter layers.
- The power of scale for parameter-efficient prompt tuning.
- Improving language models fine-tuning with representation consistency targets.
- Progressive neural networks.
- Spot: Better frozen model adaptation through soft prompt transfer.
- Revisiting few-sample bert fine-tuning.
- Character-level convolutional networks for text classification.
etc
- Pretrained transformers improve out-of-distribution robustness.
- Learning word vectors for sentiment analysis.
阅读思考
- 实验部分
为什么是T5-large 和 bert-base,其他model没有尝试吗
为什么t5和bert做实验的时候对比的baseline不完全一样