ELK日志分析系统之(Filebeat 收集Nginx日志并写入 Kafka 缓存发送至Elasticsearch)
场景:与redis作为缓存服务器相比,虽然利用redis 可以实现elasticsearch 缓存功能,减轻elasticsearch的压力,但不支持的redis集群,存在单点问题,故利用kafka代替redis,且支持kafka集群,消除单点故障隐患,同时利用 kafka 缓存日志数据,解决应用解耦,异步消息,流量削锋等问题

大致流程:将nginx 服务器(web-filebeat)的日志通过filebeat收集之后,存储到缓存服务器kafka,之后logstash到kafka服务器上取出相应日志,经过处理后写入到elasticsearch服务器并在kibala上展示。
官方文档:
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-redis.html
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-redis.html
部署Nginx服务配置Json格式的访问日志
#包安装
[root@elk-web1 ~]#apt update && apt -y install nginx
#修改nginx访问日志为Json格式
[root@elk-web1 ~]#vim /etc/nginx/nginx.conf
.......................
log_format access_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /var/log/nginx/access_json.log access_json ;
error_log /var/log/nginx/error.log;
.........................
#默认开启nginx的错误日志,但如果是ubuntu,还需要修改下面行才能记录错误日志
[root@elk-web1 ~]#vim /etc/nginx/sites-available/default
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
#try_files $uri $uri/ =404; #将此行注释
[root@elk-web1 ~]#systemctl restart nginx
部署kafka
这里我采用脚本一键部署方式,脚本如下
[root@ubuntu2204 ~]#hostnamectl set-hostname kafka-node1
[root@ubuntu2204 ~]#hostnamectl set-hostname kafka-node2
[root@ubuntu2204 ~]#hostnamectl set-hostname kafka-node3
[root@kafka-node1 ~]#cat install_kafka.sh
#!/bin/bash
#
KAFKA_VERSION=3.3.2
SCALA_VERSION=2.13
KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz"
ZK_VERSOIN=3.7.1
ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/apache-zookeeper-${ZK_VERSOIN}-bin.tar.gz"
ZK_INSTALL_DIR=/usr/local/zookeeper
KAFKA_INSTALL_DIR=/usr/local/kafka
NODE1=10.0.0.231
NODE2=10.0.0.232
NODE3=10.0.0.233
HOST=`hostname -I|awk '{print $1}'`
. /etc/os-release
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo-n"$1" && $MOVE_TO_COL
echo-n"["
if [ $2="success"-o$2="0" ] ;then
${SETCOLOR_SUCCESS}
echo-n$" OK "
elif [ $2="failure"-o$2="1" ] ;then
${SETCOLOR_FAILURE}
echo-n$"FAILED"
else
${SETCOLOR_WARNING}
echo-n$"WARNING"
fi
${SETCOLOR_NORMAL}
echo-n"]"
echo
}
install_jdk() {
if [ $ID='centos'-o $ID='rocky' ];then
yum -y install java-1.8.0-openjdk-devel || { color "安装JDK失败!"1; exit1; }
else
apt update
apt install openjdk-8-jdk -y || { color "安装JDK失败!"1; exit1; }
fi
java -version
}
zk_myid () {
read -p"请输入node编号(默认为 1): " MYID
if [ -z"$MYID" ] ;then
MYID=1
elif [[ ! "$MYID"=~ ^[0-9]+$ ]];then
color "请输入正确的node编号!"1
exit
else
true
fi
}
install_zookeeper() {
wget-P /usr/local/src/ $ZK_URL || { color "下载失败!"1 ;exit ; }
tar xf /usr/local/src/${ZK_URL##*/}-C`dirname ${ZK_INSTALL_DIR}`
ln-s /usr/local/apache-zookeeper-*-bin/ ${ZK_INSTALL_DIR}
echo'PATH=${ZK_INSTALL_DIR}/bin:$PATH' > /etc/profile.d/zookeeper.sh
. /etc/profile.d/zookeeper.sh
mkdir-p${ZK_INSTALL_DIR}/data
echo$MYID > ${ZK_INSTALL_DIR}/data/myid
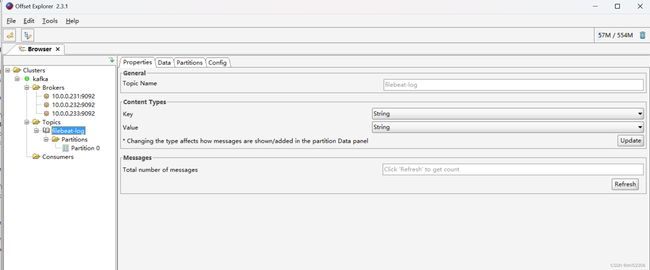
cat > ${ZK_INSTALL_DIR}/conf/zoo.cfg < tickTime=2000 initLimit=10 syncLimit=5 dataDir=${ZK_INSTALL_DIR}/data clientPort=2181 maxClientCnxns=128 autopurge.snapRetainCount=3 autopurge.purgeInterval=24 server.1=${NODE1}:2888:3888 server.2=${NODE2}:2888:3888 server.3=${NODE3}:2888:3888 EOF cat > /lib/systemd/system/zookeeper.service < [Unit] Description=zookeeper.service After=network.target [Service] Type=forking #Environment=${ZK_INSTALL_DIR} ExecStart=${ZK_INSTALL_DIR}/bin/zkServer.sh start ExecStop=${ZK_INSTALL_DIR}/bin/zkServer.sh stop ExecReload=${ZK_INSTALL_DIR}/bin/zkServer.sh restart [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable --now zookeeper.service systemctl is-active zookeeper.service if [ $?-eq0 ] ;then color "zookeeper 安装成功!"0 else color "zookeeper 安装失败!"1 exit1 fi } install_kafka(){ if [ ! -f kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz ];then wget-P /usr/local/src $KAFKA_URL || { color "下载失败!"1 ;exit ; } else cp kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz /usr/local/src/ fi tar xf /usr/local/src/${KAFKA_URL##*/} -C /usr/local/ ln-s${KAFKA_INSTALL_DIR}_*/ ${KAFKA_INSTALL_DIR} echoPATH=${KAFKA_INSTALL_DIR}/bin:'$PATH' > /etc/profile.d/kafka.sh . /etc/profile.d/kafka.sh cat > ${KAFKA_INSTALL_DIR}/config/server.properties < broker.id=$MYID listeners=PLAINTEXT://${HOST}:9092 log.dirs=${KAFKA_INSTALL_DIR}/data num.partitions=1 log.retention.hours=168 zookeeper.connect=${NODE1}:2181,${NODE2}:2181,${NODE3}:2181 zookeeper.connection.timeout.ms=6000 EOF mkdir${KAFKA_INSTALL_DIR}/data cat > /lib/systemd/system/kafka.service < [Unit] Description=Apache kafka After=network.target [Service] Type=simple #Environment=JAVA_HOME=/data/server/java #PIDFile=${KAFKA_INSTALL_DIR}/kafka.pid ExecStart=${KAFKA_INSTALL_DIR}/bin/kafka-server-start.sh ${KAFKA_INSTALL_DIR}/config/server.properties ExecStop=/bin/kill -TERM \${MAINPID} Restart=always RestartSec=20 [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable --now kafka.service #kafka-server-start.sh -daemon ${KAFKA_INSTALL_DIR}/config/server.properties systemctl is-active kafka.service if [ $?-eq0 ] ;then color "kafka 安装成功!"0 else color "kafka 安装失败!"1 exit1 fi } zk_myid install_jdk install_zookeeper install_kafka [root@kafka-node1 ~]#bash install_kafka.sh 请输入node编号(默认为 1): 1 .................................... .................................... Created symlink /etc/systemd/system/multi-user.target.wants/zookeeper.service → /lib/systemd/system/zookeeper.service. active zookeeper 安装成功! [ OK ] Created symlink /etc/systemd/system/multi-user.target.wants/kafka.service → /lib/systemd/system/kafka.service. active kafka 安装成功! [ OK ] [root@kafka-node2 ~]#bash install_kafka.sh 请输入node编号(默认为 1): 2 .................................... .................................... Created symlink /etc/systemd/system/multi-user.target.wants/zookeeper.service → /lib/systemd/system/zookeeper.service. active zookeeper 安装成功! [ OK ] Created symlink /etc/systemd/system/multi-user.target.wants/kafka.service → /lib/systemd/system/kafka.service. active kafka 安装成功! [ OK ] [root@kafka-node3 ~]#bash install_kafka.sh 请输入node编号(默认为 1): 3 .................................... .................................... Created symlink /etc/systemd/system/multi-user.target.wants/zookeeper.service → /lib/systemd/system/zookeeper.service. active zookeeper 安装成功! [ OK ] Created symlink /etc/systemd/system/multi-user.target.wants/kafka.service → /lib/systemd/system/kafka.service. active kafka 安装成功! [ OK ] 查看端口 #9092为kafka开启端口, #2181为客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求 #2888,zookeeper集群Leader和Follower的数据同步端口,只有leader才会打开 #3888为zookeeper集群Leader和Follower选举端口,Leader和Follower [root@kafka-node1 ~]#ss -tln State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 128 0.0.0.0:22 0.0.0.0:* LISTEN 0 128 127.0.0.1:6010 0.0.0.0:* LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* LISTEN 0 128 [::]:22 [root@kafka-node1 ~]#/usr/local/zookeeper/bin/zkServer.sh status /bin/java ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower [root@kafka-node1 ~]#ss -tln State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 50 [::ffff:10.0.0.231]:9092 *:* LISTEN 0 50 *:2181 *:* LISTEN 0 50 [::ffff:10.0.0.231]:3888 *:* LISTEN 0 50 *:8080 *:* LISTEN 0 50 *:35857 *:* LISTEN 0 50 *:41109 *:* [root@kafka-node2 ~]#/usr/local/zookeeper/bin/zkServer.sh status /bin/java ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower [root@kafka-node2 ~]#ss -tln State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 50 [::ffff:10.0.0.232]:9092 *:* LISTEN 0 50 *:2181 *:* LISTEN 0 50 *:32973 *:* LISTEN 0 50 [::ffff:10.0.0.232]:3888 *:* LISTEN 0 50 *:8080 *:* [root@kafka-node3 ~]#/usr/local/zookeeper/bin/zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: leader [root@kafka-node3 ~]#ss -tln State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 50 [::ffff:10.0.0.233]:9092 *:* LISTEN 0 50 *:2181 *:* LISTEN 0 50 [::ffff:10.0.0.233]:2888 *:* LISTEN 0 50 [::ffff:10.0.0.233]:3888 *:* LISTEN 0 50 *:8080 *:* LISTEN 0 50 *:40659 *:* LISTEN 0 50 *:44407 [::]:* LISTEN 0 128 [::1]:6010 [::]:* LISTEN 0 50 [::ffff:10.0.0.231]:9092 *:* LISTEN 0 50 *:2181 *:* LISTEN 0 50 [::ffff:10.0.0.231]:3888 *:* LISTEN 0 50 *:8080 *:* LISTEN 0 50 *:35857 *:* LISTEN 0 50 *:41109 *:* 使用exploer连接测试kafka集群是否正常 安装Filebeat #web服务器安装Filebeat [root@elk-web1 ~]#wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/8.x/apt/pool/main/f/filebeat/filebeat-8.6.1-amd64.deb [root@elk-web1 ~]#dpkg -i filebeat-8.6.1-amd64.deb 修改配置 [root@elk-web1 ~]#cp /etc/filebeat/filebeat.yml{,.bak} [root@elk-web1 ~]#vim /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access_json.log json.keys_under_root: true #默认False会将json数据存储至message,改为true则会独立message外存储 json.overwrite_keys: true #设为true,覆盖默认的message字段,使用json格式日志中>自定义的key tags: ["nginx-access"] #指定tag,用于分类 - type: log enabled: true paths: - /var/log/nginx/error.log tags: ["nginx-error"] - type: log enabled: true paths: - /var/log/syslog tags: ["syslog"] output.kafka: hosts: ["10.0.0.231:9092", "10.0.0.232:9092", "10.0.0.233:9092"] topic: filebeat-log #指定kafka的topic partition.round_robin: reachable_only: true #true表示只发布到可用的分区,false时表示所有分区,如果一个节点down会导致阻塞 required_acks: 1 #如果为0,表示不确认,错误消息可能会丢失,1等待写入主分区(默认),-1等待写入副本分区 compression: gzip max_message_bytes: 1000000 启动filebeat服务 [root@elk-web1 ~]#systemctl status filebeat.service [root@elk-web1 ~]#systemctl enable --now filebeat.service 导入日志数据通过exploer验证kafka是否可接收数据 [root@elk-web1 ~]#cat access_json.log-20220304 >> /var/log/nginx/access_json.log 修改content type可查看具体数据内容 包安装 #8.X 要求JDK11或17 [root@logstash ~]#apt update && apt -y install openjdk-11-jdk [root@logstash ~]#wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/8.x/apt/pool/main/l/logstash/logstash-8.6.1-amd64.deb [root@logstash ~]#dpkg -i logstash-8.6.1-amd64.deb 正在选中未选择的软件包 logstash。 (正在读取数据库 ... 系统当前共安装有 166976 个文件和目录。) 准备解压 logstash-8.6.1-amd64.deb ... 正在解压 logstash (1:8.6.1-1) ... 正在设置 logstash (1:8.6.1-1) ... [root@logstash ~]#systemctl enable --now logstash.service #采用包安装方式,默认会生成logstash,以此用户启动服务,如需抓取syslog等系统日志存在权限问题 [root@logstash ~]#id logstash 用户id=999(logstash) 组id=999(logstash) 组=999(logstash) [root@logstash ~]#ll /var/log/syslog -rw-r-----1 syslog adm 190160 2月 2021:00 /var/log/syslog #other用户无权限读 准备日志收集文件 [root@logstash ~]#cat /etc/logstash/conf.d/kafka-to-es.conf input { kafka { bootstrap_servers => "10.0.0.231:9092,10.0.0.232:9092,10.0.0.233:9092" topics => "filebeat-log" #与kafka指定的topic要一致 codec => "json" #group_id => "logstash" #消费者组的名称 #consumer_threads => "3" #建议设置为和kafka的分区相同的值为线程数 #topics_pattern => "nginx-.*" #通过正则表达式匹配topic,而非用上面topics=>指定固定值 } } filter { if"nginx-access"in [tags] { geoip { source=> "clientip" #日志必须是json格式,且有一个clientip的key target => "geoip" #database => "/etc/logstash/conf.d/GeoLite2-City.mmdb" #指定数据库文件,可选 add_field => ["[geoip][coordinates]","%{[geoip][geo][location][lon]}"] #8.X添加经纬度字段包括经度 add_field => ["[geoip][coordinates]","%{[geoip][geo][location][lat]}"] #8.X添加经纬度字段包括纬度 #add_field => ["[geoip][coordinates]", "%{[geoip][longitude]}"] #7,X添加经纬度字段包括经度 #add_field => ["[geoip][coordinates]", "%{[geoip][latitude]}"] #7,X添加经纬度字段包括纬度 } #转换经纬度为浮点数,注意:8X必须做,7.X 可不做此步 mutate { convert => [ "[geoip][coordinates]", "float"] } } } output { stdout { codec => "rubydebug" #调试代码,用户手动启动服务监测日志处理情况,生产后可删除 } if"syslog"in [tags] { elasticsearch { hosts => ["10.0.0.206:9200","10.0.0.207:9200","10.0.0.208:9200"] index => "logstash-syslog-%{+YYYY.MM.dd}" } } if"nginx-access"in [tags] { elasticsearch { hosts => ["10.0.0.206:9200","10.0.0.207:9200","10.0.0.208:9200"] index => "logstash-nginx-accesslog-%{+YYYY.MM.dd}" template_overwrite => true } } if"nginx-error"in [tags] { elasticsearch { hosts => ["10.0.0.206:9200","10.0.0.207:9200","10.0.0.208:9200"] index => "logstash-nginx-errorlog-%{+YYYY.MM.dd}" template_overwrite => true } } } #语法检测 [root@logstash ~]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/kafka-to-es.conf -t ..................... [INFO ] 2023-02-2222:31:20.055 [LogStash::Runner] javapipeline - Pipeline `main` is configured with `pipeline.ecs_compatibility: v8` setting. All plugins in this pipeline will default to `ecs_compatibility => v8` unless explicitly configured otherwise. Configuration OK [INFO ] 2023-02-2222:31:20.056 [LogStash::Runner] runner - Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash #启动服务 [root@logstash ~]#systemctl enable --now logstash.service Created symlink /etc/systemd/system/multi-user.target.wants/logstash.service → /lib/systemd/system/logstash.service. [root@logstash ~]#systemctl status logstash.service ● logstash.service - logstash Loaded: loaded (/lib/systemd/system/logstash.service; enabled; vendor prese> Active: active (running) since Mon 2023-02-2022:32:27 CST; 2s ago Main PID: 5204 (java) Tasks: 20 (limit: 2196) Memory: 167.2M CPU: 3.548s CGroup: /system.slice/logstash.service └─5204 /usr/share/logstash/jdk/bin/java -Xms1g-Xmx1g-Djava.awt.he> 2月 2022:32:27 logstash systemd[1]: Started logstash. 2月 2022:32:27 logstash logstash[5204]: Using bundled JDK: /usr/share/logstash/> lines 1-12/12 (END) 导入历史数据模版,方便后续kibana展示 [root@elk-web1 ~]#cat access_json.log-20220304 >> /var/log/nginx/access_json.log 通过kafka工具查看kafka已缓存日志数据 查看视图 选择需要展示的视图

利用 Filebeat 收集日志到 Redis



安装logstash收集kafka数据发送至Elasticsearch
导入数据

通过插件查看索引


通过Kibana创建索引视图