AAAI 2021最佳论文《Informer》作者:Transformer 最新进展
作者:周号益,彭杰奇
单位:北京航空航天大学
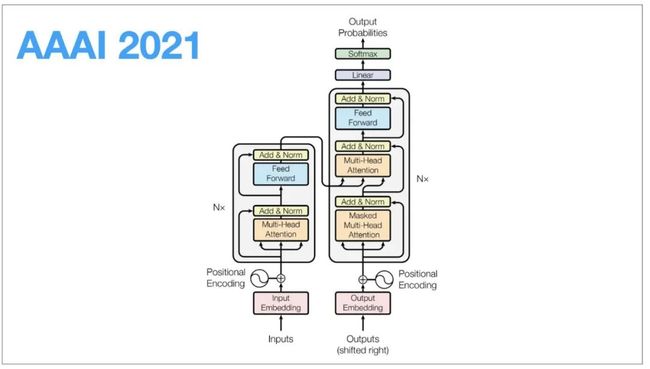
自2017年,Ashish Vaswani等人在《Attention Is All You Need》这篇文章种提出了Transformer模型后,BERT等工作极大地扩展了该模型在NLP等任务上的影响力。随之, 有关Transformer模型的改进和应用逐渐成为人工智能研究的一大热门。
回顾Transformer模型的起源,其最初作为有效顺序语言建模的新方法提出,虽然只使用自注意力机制(Self-attention Mechanism)进行网络结构建模,但它拥有更强的捕捉序列数据依赖的能力。此后得益于预训练模型的发展和普及,Transformer类模型极大地推动了自然语言处理的下游任务的发展。
虽然获得了广泛的应用,Transformer模型本身存在的内存开销和计算效率的瓶颈,也催生了大量改进Transformer以减小开销并提升效果的研究。
与此同时,Transformer模型也不再仅限于自然语言处理领域的应用,很多研究者将Transformer引入到推荐系统、时间序列预测、计算机视觉、图神经网络以及多模态等领域,在多个领域呈现热点研究的趋势。
在2月4日召开的AAAI 2021上同样涌现了大量和Transformer相关的研究,本文约覆盖40余篇论文,将从Self-Attention变体、更高效的模型架构、更深入的分析和更多样的应用几个方面对本次大会中的Transformer最新进展进行介绍。
01
自注意力机制的变体
自注意力机制是一种特殊的attention模型,简单概括是一种自己学习自己的表征过程。特别地,自注意力的计算/内存开销是随输入/输出的序列长度呈二次相关的,这导致大规模的Transformer模型必须使用大量计算资源,昂贵的训练和部署成本阻碍了模型的应用;同时这也会限制Transformer模型对于长序列数据的处理能力。因此研究自注意力机制的变体,实现高效Transformer成为了一个重要的研究方向。
Informer[1]基于自注意力机制中存在的查询稀疏性(attention的长尾分布),选择top-u进行query-key对的部分计算,提出了ProbSparse Self-Attention替代标准的Self-Attention,将自注意力机制的内存和计算开销从 减小到 。
Nyströmformer[2]将Nyström方法应用于自注意力机制的近似,利用landmark(作者称之为Nyström) point来重构Self-Attention中的Softmax注意力矩阵,从而避免 的矩阵计算,得到了在内存和时间开销上复杂度为 的近似。
02
更高效的自注意力模型架构
除了对自注意力机制本身进行改变,主动压缩模型结构并取得与原始网络结构相近的效果,这也是一种获得高效的Transformer的重要手段。
[3]基于Transformer decoder的数学推导,证明了在适当条件下压缩Transformer的基本子层来简化模型结构并获得更高的并行度是可行的,并提出了子层数量为1的Decoder的来压缩Transformer,在提高推理速度的同时不降低性能。
Informer[1]除了提出在时序问题下使用自注意力蒸馏机制,每层Encdoer都将输入序列的长度减小一半,从而大大减小了Encoder内存开销和计算时间;同时提出在Decoder结构中使用生成式结构,能够一次生成全部预测序列,极大减小了预测解码耗时。
CP Transformer[4]通过类比在动态图上形成hyperedge的方式,整合token的embedding来实现序列的压缩,在音乐建模中使用更短的训练和推理时间生成了与Transformer-XL质量相当的完整钢琴曲。
Faster Depth-Adaptive Transformer[5]提出了基于互信息和重建损失的两种估计方法,提前估计所需深度,得到了一个相比原始Transformer速度快7倍,且效率与鲁棒性相对其他深度自适应方法均有提高的深度自适应网络。
此外,GPKD[6]是一种基于组排列的知识蒸馏方法,能够将深度Transformer模型压缩为浅层模型,且性能牺牲较小,其性能大大优于SKD方法。
LRC-BERT[7]提出了一种基于对比学习的知识蒸馏方法,从角度距离的角度来拟合中间输出,并在训练阶段引入了基于梯度扰动的训练体系以提高模型鲁棒性。
03
对Transformer架构更深入的分析
伴随Transformer的广泛应用,对于其内部工作机理的研究以及对模型的攻击和防护也更加关键。
[8]提出了一种自注意力归因方法,给出了Transformer内部的信息交互的一种诠释,利用归因得分推导出交互树,进一步合理可视化自注意力机制;该方法能识别出重要的注意头,形成了一种注意头修剪方法;并且还可以用来构造对抗触发器来实现非目标攻击。
Ashim Gupta等人[9]则研究了BERT家族中的大模型对于不连贯输入的响应,定义了简单的启发式方法来构造例子,使目前的模型都无法有效区分这些无效文本;同时这些输入可以被显式地加入训练,模型可以在不降低性能的情况下对此类攻击具有鲁棒性。
Madhura Pande等人[14]的研究提出了一个统一方法来分析Multi-head Self-Attention中各注意头,通过筛选偏倚得分来获得分头功能作用,假设检验确保了统计显著性;作为一种新视角,作者同时还研究了任务微调对注意力角色的影响及关联问题。
04
将Transformer拓展到更多样的应用
值得关注的是,Transformer模型相关的应用已经不局限于自然语言处理领域[18-25],在时序预测、图网络、计算机视觉以及多模态等领域,类Transformer模型也展现出了不俗的效果。
Informer[1]的研究表明Transformer在时间序列(长序列预测)中拥有更加出色的建模能力。CNMT[10]利用OCR系统和多模态Transformer进行TextCaps任务。
而针对图像字幕生成任务,GET[11]设计了一种全局增强的Transformer来提取更全面的表示,其包括一个全局增强编码器来捕捉全局特征和一个全局自适应解码器来指导字幕的生成,从而得到高质量的字幕。
DLCT[12]同样是研究图像字幕生成,这是一种双层协同Transformer模型;其设计了综合关系注意(CRA)和双向自我注意(DWSA)的层次内融合,合并了区域和网格的外观和几何特征;通过一种应用局部约束交叉注意(LCCA)的几何对齐图实现特征增强,解决了两种特征直接融合引起的语义噪声问题。
针对视听场景感知对话问题,STSGR[13]提出了一种新的层次图表示学习和基于Transformer的推理框架,模型能够产生对象、框架和视频级别的表示,并被系统集成来产生视觉记忆;这些记忆则以输入问题为条件,使用一个Shuffled Transformer,顺序地融合到其他知识(如对话历史等)的编码中。
图注意力转换编码器GATE[15]提出利用Self-Attention机制,明确地融合结构信息来学习不同句法距离的单词之间的依赖关系,对细粒度句法结构信息进行建模,来生成结构化的上下文表示;从而解决GCNs很难对具有长期依赖关系的单词建模,让依赖树中没有直接连接的元素得到了更健壮的表示。
RpBERT[16]针对推文中与文本无关的图像在多模态学习中的视觉注意力问题进行了研究,提出了一种基于“文本-图像”关系推理及传播的多模态模型;模型通过文本图像关系分类和下游NER的多重任务进行训练,并在MNER数据集上实现了最先进的性能。
ActionBert[17]将Bert应用到UI任务中,探索跟踪用户动作来构建通用特征表示,以促进用户界面的理解;模型利用用户交互追踪中的视觉、语言和领域特定的特征来预先训练UI及其组件的一般特征表示,得到一个预先训练的用户界面嵌入模型,并应用到多个用户界面理解任务中。
## 参考文献
[1] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
[2] Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
[3] An Efficient Transformer Decoder with Compressed Sub-layers
[4] Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
[5] Faster Depth-Adaptive Transformers
[6] Learning Light-Weight Translation Models from Deep Transformer
[7] LRC-BERT: Latent-representation Contrastive Knowledge Distillation for Natural Language Understanding
[8] Self-Attention Attribution: Interpreting Information Interactions Inside Transformer
[9] BERT & Family Eat Word Salad: Experiments with Text Understanding
[10] Confidence-aware Non-repetitive Multimodal Transformers for TextCaps
[11] Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network
[12] Dual-Level Collaborative Transformer for Image Captioning
[13] Dynamic Graph Representation Learning for Video Dialog via Multi-Modal Shuffled Transformers
[14] The heads hypothesis: A unifying statistical approach towards understanding multi-headed attention in BERT
[15] GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction
[16] RpBERT: A Text-image Relation Propagation-based BERT Model for Multimodal NER
[17] ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces
[18] Contrastive Triple Extraction with Generative Transformer
[19] LightXML: Transformer with Dynamic Negative Sampling for High-Performance Extreme Multi-label Text Classification
[20] Future-Guided Incremental Transformer for Simultaneous Translation
[21] Segatron: Segment-Aware Transformer for Language Modeling and Understanding
[22] Paragraph-level Commonsense Transformers with Recurrent Memory
[23] Context-Guided BERT for Targeted Aspect-Based Sentiment Analysis
[24] IsoBN: Fine-Tuning BERT with Isotropic Batch Normalization
[25] DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances
推荐阅读:

AAAI 2021 | 图神经网络·最新进展解读

AAAI 2021 | 机器翻译·最新进展解读

AAAI 2021 | 情感分析·最新进展解读
【关于智源社区】
智源社区隶属于北京智源人工智能研究院,我们致力于创建一个AI领域内行人的交流平台。
在这里你有机会参与全年线上线下百场专题论坛,与顶尖学者零距离接触;也可以与同行探讨领域前沿,碰撞思想火花。如果你更想进入微信群与更多同行人发起实时讨论,或者加入「青源会」结识更多研究伙伴,或者成为智源社区编辑参与更多文字工作,欢迎填写以下表单(扫描二维码)进行申请。
