【操作系统】在阅读论文:OrcFS: Orchestrated file system for flash storage时需要补充的基础知
在阅读论文:OrcFS: Orchestrated file system for flash storage是需要补充的基础知识
这篇论文是为了解决软件层次之间的信息冗余问题
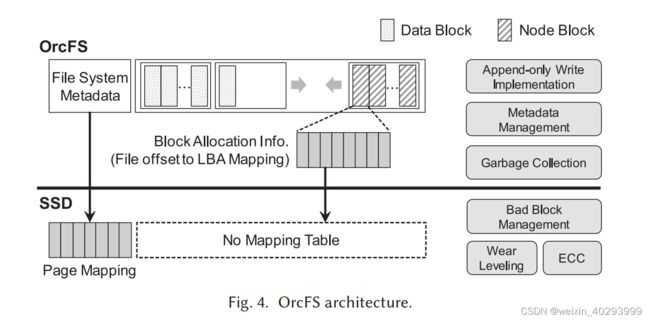
To minimize the disk traffic, the file system buffers the updates and then flushes them to the disk as a single unit, a segment (e.g.,2Mbyte), either when the buffer is full or when fsync() is called.
 The metadata area consists of the file system super block (FS-SB), checkpoint, segment information table (SIT), and node address table (NAT). The SIT manages the block
The metadata area consists of the file system super block (FS-SB), checkpoint, segment information table (SIT), and node address table (NAT). The SIT manages the block
bitmap of each segment in the data area. The NAT manages the block address corresponding to
each node ID.

fsync
一、缓冲#
传统的UNIX实现的内核中都设置有缓冲区或者页面高速缓存,大多数磁盘IO都是通过缓冲写的。
当你想将数据write进文件时,内核通常会将该数据复制到其中一个缓冲区中,如果该缓冲没被写满的话,内核就不会把它放入到输出队列中。
当这个缓冲区被写满或者内核想重用这个缓冲区时,才会将其排到输出队列中。等它到达等待队列首部时才会进行实际的IO操作。

这里的输出方式就是大家耳熟能详的: 延迟写
这个缓冲区就是大家耳熟能详的:OS Cache
二、延迟写的优缺点#
很明显、延迟写降低了磁盘读写的次数,但同时也降低了文件的更新速度。
这样当OS Crash时由于这种延迟写的机制可能会造成文件更新内容的丢失。而为了保证磁盘上的实际文件和缓冲区中的内容保持一致,UNIX系统提供了三个系统调用:sync、fsync、fdatasyn
三、sync、fsync、fdatasync
#includesync系统调用:将所有修改过的缓冲区排入写队列,然后就返回了,它并不等实际的写磁盘的操作结束。所以它的返回并不能保证数据的安全性。通常会有一个update系统守护进程每隔30s调用一次sync。
fsync系统调用:需要你在入参的位置上传递给他一个fd,然后系统调用就会对这个fd指向的文件起作用。fsync会确保一直到写磁盘操作结束才会返回。所以fsync适合数据库这种程序。
fdatasync系统调用:和fsync类似但是它只会影响文件的一部分,因为除了文件中的数据之外,fsync还会同步文件的属性。
缓存的意义:
系统调用是一件成本很高的事情,如果没有缓冲区,写一个数据就要传输一下,时间成本很高。缓冲区可以根据一定的策略进行数据的一次性传输,所以意义就是可以节省调用者的时间。
OrcFS的架构
基础知识补充
1.磁盘
磁盘是计算机上唯一一个机械设备,磁盘和我们现在电脑上的固态硬盘(SSD)不一样,固态硬盘是电子的,比起磁盘要快的多,但是价格比磁盘贵。磁盘现在只有一些公司存储大量数据的时候会用,因为成本低。
机械磁盘中主要的部件有:马达、磁盘、磁头等,磁盘有一摞,数据就记录在磁盘上面,一个磁盘有两面,就会有两个磁头,一个磁头负责一面的数据读写。磁头负责读写磁盘上的数据,马达负责转动磁盘。磁头和磁盘是不接触的,但是距离非常近,如果磁头接触了磁盘,就有可能把磁盘上的数据抹掉,造成数据丢失。所以磁盘是不能碰撞的,一旦磕碰就有可能会发生数据丢失,这也是被淘汰的原因
计算机是只能识别0和1的,那么在磁盘上怎么区分0和1呢?不同的设备区分0和1的方法不同,在磁盘上就是以南极北极区分0和1,磁盘的盘片上有无数的基本单元,每一个基本单元就是一个磁铁,磁铁就有南极和北极。所以写入数据的过程就是把N编程S,删除数据的本质就是S编程N。所以磁头读取数据就是读取南北极,写入数据就是更改南北极。

2.具体存储:
数据在盘面上存储的,而盘面是一个同心圆,那么根据什么规则来找到数据所在的区域呢?
把盘面分为多个扇面,每个扇面都有磁道划分扇区,数据就是存储在无数个扇区里面,每个扇区大小不同,但是存储的bit位是相同的,都是512字节,那么怎么找到对应的扇区呢? 一个磁盘有多个盘面,一个盘面对应一个磁头,所以可以给磁头定一个编号,根据磁头能找到盘面,而盘面相对位置都是一样的,所以就会有一个柱面,这个柱面就是磁道,然后根据扇面的编号就可以确定一个扇区。磁头(head)、柱面(cylinder)、扇区(sector)这种就是一种CHS定位法。根据这种方法可以定位任意一个扇区,把文件写入磁盘的本质就是给一个或者多个扇区写入二进制,或者读取多个扇区的二进制。
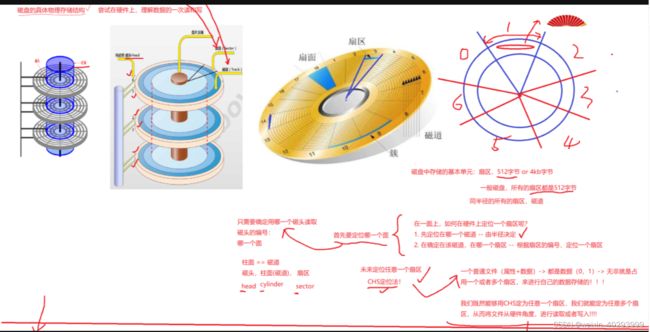
对磁盘物理结构的逻辑抽象
一个磁盘通过CHS地址能够访问到任何一个扇区,那么OS内不能是不是通过CHS地址访问磁盘中的数据呢?并不是。一旦磁盘物理结构发生改变,OS就不能访问数据了,这样是为了OS和磁盘之间解耦。
一个扇区也就是512字节,但是OS读取数据的时候基本单位是4kb,哪怕OS只修改一个bit位OS也会把这一个bit位所在4kb全部读取,然后修改完成后再把4kb整体放回到原来的地方。所以操作系统需要有一套新的地址进行IO操作。
那么操作系统想要一次读取4kb(也就是8个扇区),怎么读取的呢?
把一个盘面抽象成一个数组。LBA方式读取数据
磁盘的数据存储再盘面上,而盘面是一个同心圆,从最外圈到最内圈有无数个磁道,一圈磁道有许多扇区,如果把磁道拉伸成一个线性的,就像磁带一样,最开始读取数据是在最外圈,最后读取的数据是在最内圈。一个磁道拉伸出来就像一个长条,然后这个长条内有无数个扇区就像数组的空间,这样一圈磁道就被拉伸成了一个数组,内侧磁道拉伸成数组头部跟在外侧磁道尾部的后面,这样就可以把一个同心圆抽象成一个数组。
计算机要读取一个内置类型或者自定义类型时,通常是起始地址+偏移量(数据类型)。OS读取4kb也就是8个扇区就是读取8个扇区空间的首地址。这4kb大小的类型,被称为块。把这个数据块看做一种数据类型。块的地址就是一个下标。这种读取数据的方式被称为LBA。
LBA转换成CHS方法,简单的转换,实际的转换方法一定要复杂得多。
//假设一个盘面有10圈磁道,一圈有500个扇区,一个盘面有5000个扇区。读取6500号数组下标
C:1500/500 = 3
H:6500/5000 = 1
S: 1500%500 = 0
到现在操作系统对磁盘的管理就变成了对数组的管理。
文件系统
OS对磁盘抽象为数组管理,每个数组空间为4kb,但是磁盘有着很大的空间,是以GB甚至是TB为单位的。用一个简单数组直接管理难度太大。所以会对磁盘进行分区,类似分C盘D盘,而每个区还是很大,所以每个区会分组(group)管理。
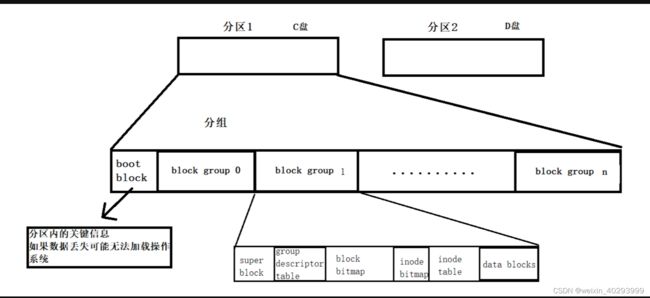
每个组内又分了各种区域存储不同的信息,把一个组管理模式可以复刻到每一个分组,这样就能管理好整个分区。
super block
这个分区内存放的是:
1.文件系统的类型
2.整个分组的情况
super block在每个分组里都存在,而且都存了文件系统的类型,是同时更新的同样的数据。主要是为了做多个备份,如果super block这个区域的数据没有备份而且损坏,直接导致整个分区的数据不能被使用。
Group Descriptor Table
简称GDT:组描述符,主要是记录组内详细统计等信息。例如每个区域的大小等等
inode table
linux系统中,内容和属性是分开存储的,一个文件的所有属性集合就是一个inode(128kb)节点,一个分组内也有大量的文件也就有大量的inode节点,这些inode节点都存储在inode
table表中,每一个inode节点都有自己的indoe编号,也属于对应文件的属性id。Linux中查看inode编号ls -il
Date block
主要存储文件的内容数据,所有的文件的内容都被存储在Date block这个区域内。Linux查找一个文件必须先找到这个文件对应的inode节点的编号,通过indoe节点映射关系找到文件的内容。
inode bitmap
这个区域内的一个bit位表示一个inode的使用情况,0表示空可以使用,1表示被占用。
Linux系统只认识inode编号,并不存在文件名,文件名是给用户看的。
ref: https://blog.csdn.net/weixin_48344647/article/details/129925872