【RT-DETR改进涨点】为什么YOLO版本的RT-DETR训练模型不收敛的问题
前言
大家好,我是Snu77,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
其中提到的多个版本ResNet18、ResNet34、ResNet50、ResNet101为本人根据RT-DETR官方版本1:1移植过来的,参数量基本保持一致(误差很小很小),不同于ultralytics仓库版本的ResNet官方版本,同时ultralytics仓库的一些参数是和RT-DETR相冲的所以我也是会教大家调好一些参数,真正意义上的跑ultralytics的和RT-DETR官方版本的无区别,给后期发论文的时候省区许多麻烦。
欢迎大家订阅本专栏,一起学习RT-DETR!
本文介绍
本文的内容同样为本专栏的前期预热文章,文章主要解释一下为什么有的人跑ultralytics仓库的RT-DETR精度很差,模型不收敛,mAP异常的情况。
为了验证这一情况我也是跑了多个实验,从多个数据集出发,100-500的数据集我跑了5个数据集,1000的跑了二个,2000的我跑了一个,4000的了一个,同时其中一些版本我也用了不同的batch_size来出发验证精度异常的情况。从这些角度来论证为什么你的数据集在RT-DETR上不能够收敛,同时本文的验证内容均为在修改了我的ResNet18上进行出发和修改了我的超参数和代码调节后的模型上。
最开始我先放一下不同数据集的mAP精度汇总图,让大家心里有一个认识,同时明白自己属于那种情况。
图片说明:在数据集为100张的时候如果小batch_size对于模型来说是可以适当收敛的,当bathc_size过大的时候其就会造成模型无法收敛的情况。
(为什么会有这种情况,这是因为模型过于复杂,但是数据较少你一个batch的图片太少模型任何东西都学不到,所以造成无法收敛的情况,当然这都是在我的调参和更改模型中部分代码和我复现过的ResNet的基础上的实验,其它的版本我没有验证)
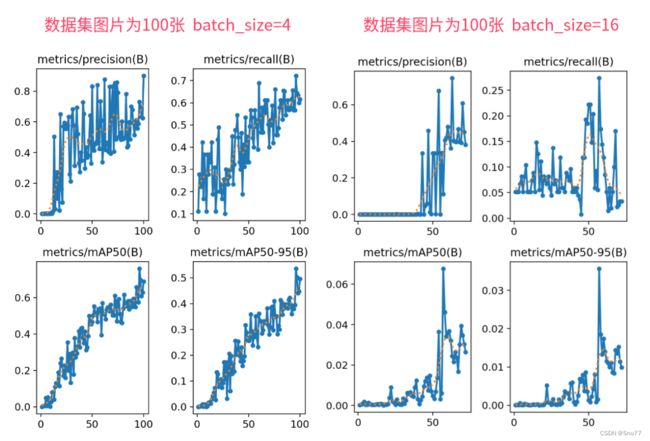
图片说明:数据集为300-500张的时候可以看到在相同的batch_size的情况下图片更多的在更小的epochs下面收敛了当然其中的波动还是因为数据集质量不好,图片较少导致的。

图片说明:当数据的数量来到了1000-2000张的时候,首先是1000张的数据集虽然有着较小的batch_size但是其波动性也比较大和多,但是图片来到了2000张我们此时的波东西就变小了一些同时收敛的速度也变得更快。

图片说明:下面的图片为同一个数据集的不同batch_size结果可以看到模型结果基本一致,但是其中batch_size更小的曲线更平滑,这是因为batch=74对于4000张的图片来说过于大了,有部分的上面的情况,所以我们可以知道数据集过大的时候小batch是可以拟合的,过大的也可以 的。

上面我们已经分析了,为什么会出现模型不拟合的情况,和模型精度波动性较大的情况,当然了这些都是在我的结构当中进行实验中的结果,同时可以看到我的模型参数和官方的R18参数基本保持一致均为2KW,计算量GFLOPs仅有误差1.4。
![]()
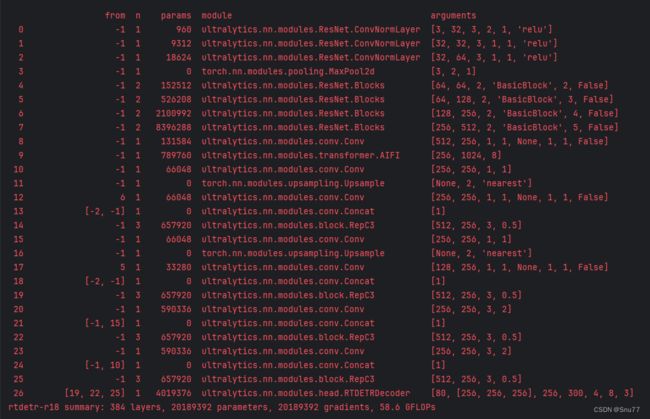
下面这个文件是RT-DETR官方的版本的ResNet大家可以在下面的链接中找到,其中实现的代码是Paddle实现的,我所有的代码都来源与这个文件的总结,所以可以号称是1:1移植。
代码地址:RT-DETR官方下载地址
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from numbers import Integral
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from ppdet.core.workspace import register, serializable
from paddle.regularizer import L2Decay
from paddle.nn.initializer import Uniform
from paddle import ParamAttr
from paddle.nn.initializer import Constant
from paddle.vision.ops import DeformConv2D
from .name_adapter import NameAdapter
from ..shape_spec import ShapeSpec
__all__ = ['ResNet', 'Res5Head', 'Blocks', 'BasicBlock', 'BottleNeck']
ResNet_cfg = {
18: [2, 2, 2, 2],
34: [3, 4, 6, 3],
50: [3, 4, 6, 3],
101: [3, 4, 23, 3],
152: [3, 8, 36, 3],
}
class ConvNormLayer(nn.Layer):
def __init__(self,
ch_in,
ch_out,
filter_size,
stride,
groups=1,
act=None,
norm_type='bn',
norm_decay=0.,
freeze_norm=True,
lr=1.0,
dcn_v2=False):
super(ConvNormLayer, self).__init__()
assert norm_type in ['bn', 'sync_bn']
self.norm_type = norm_type
self.act = act
self.dcn_v2 = dcn_v2
if not self.dcn_v2:
self.conv = nn.Conv2D(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
weight_attr=ParamAttr(learning_rate=lr),
bias_attr=False)
else:
self.offset_channel = 2 * filter_size**2
self.mask_channel = filter_size**2
self.conv_offset = nn.Conv2D(
in_channels=ch_in,
out_channels=3 * filter_size**2,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
weight_attr=ParamAttr(initializer=Constant(0.)),
bias_attr=ParamAttr(initializer=Constant(0.)))
self.conv = DeformConv2D(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
dilation=1,
groups=groups,
weight_attr=ParamAttr(learning_rate=lr),
bias_attr=False)
norm_lr = 0. if freeze_norm else lr
param_attr = ParamAttr(
learning_rate=norm_lr,
regularizer=L2Decay(norm_decay),
trainable=False if freeze_norm else True)
bias_attr = ParamAttr(
learning_rate=norm_lr,
regularizer=L2Decay(norm_decay),
trainable=False if freeze_norm else True)
global_stats = True if freeze_norm else None
if norm_type in ['sync_bn', 'bn']:
self.norm = nn.BatchNorm2D(
ch_out,
weight_attr=param_attr,
bias_attr=bias_attr,
use_global_stats=global_stats)
norm_params = self.norm.parameters()
if freeze_norm:
for param in norm_params:
param.stop_gradient = True
def forward(self, inputs):
if not self.dcn_v2:
out = self.conv(inputs)
else:
offset_mask = self.conv_offset(inputs)
offset, mask = paddle.split(
offset_mask,
num_or_sections=[self.offset_channel, self.mask_channel],
axis=1)
mask = F.sigmoid(mask)
out = self.conv(inputs, offset, mask=mask)
if self.norm_type in ['bn', 'sync_bn']:
out = self.norm(out)
if self.act:
out = getattr(F, self.act)(out)
return out
class SELayer(nn.Layer):
def __init__(self, ch, reduction_ratio=16):
super(SELayer, self).__init__()
self.pool = nn.AdaptiveAvgPool2D(1)
stdv = 1.0 / math.sqrt(ch)
c_ = ch // reduction_ratio
self.squeeze = nn.Linear(
ch,
c_,
weight_attr=paddle.ParamAttr(initializer=Uniform(-stdv, stdv)),
bias_attr=True)
stdv = 1.0 / math.sqrt(c_)
self.extract = nn.Linear(
c_,
ch,
weight_attr=paddle.ParamAttr(initializer=Uniform(-stdv, stdv)),
bias_attr=True)
def forward(self, inputs):
out = self.pool(inputs)
out = paddle.squeeze(out, axis=[2, 3])
out = self.squeeze(out)
out = F.relu(out)
out = self.extract(out)
out = F.sigmoid(out)
out = paddle.unsqueeze(out, axis=[2, 3])
scale = out * inputs
return scale
class BasicBlock(nn.Layer):
expansion = 1
def __init__(self,
ch_in,
ch_out,
stride,
shortcut,
variant='b',
groups=1,
base_width=64,
lr=1.0,
norm_type='bn',
norm_decay=0.,
freeze_norm=True,
dcn_v2=False,
std_senet=False):
super(BasicBlock, self).__init__()
assert groups == 1 and base_width == 64, 'BasicBlock only supports groups=1 and base_width=64'
self.shortcut = shortcut
if not shortcut:
if variant == 'd' and stride == 2:
self.short = nn.Sequential()
self.short.add_sublayer(
'pool',
nn.AvgPool2D(
kernel_size=2, stride=2, padding=0, ceil_mode=True))
self.short.add_sublayer(
'conv',
ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=1,
stride=1,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr))
else:
self.short = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=1,
stride=stride,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr)
self.branch2a = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=3,
stride=stride,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr)
self.branch2b = ConvNormLayer(
ch_in=ch_out,
ch_out=ch_out,
filter_size=3,
stride=1,
act=None,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
dcn_v2=dcn_v2)
self.std_senet = std_senet
if self.std_senet:
self.se = SELayer(ch_out)
def forward(self, inputs):
out = self.branch2a(inputs)
out = self.branch2b(out)
if self.std_senet:
out = self.se(out)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
out = paddle.add(x=out, y=short)
out = F.relu(out)
return out
class BottleNeck(nn.Layer):
expansion = 4
def __init__(self,
ch_in,
ch_out,
stride,
shortcut,
variant='b',
groups=1,
base_width=4,
lr=1.0,
norm_type='bn',
norm_decay=0.,
freeze_norm=True,
dcn_v2=False,
std_senet=False):
super(BottleNeck, self).__init__()
if variant == 'a':
stride1, stride2 = stride, 1
else:
stride1, stride2 = 1, stride
# ResNeXt
width = int(ch_out * (base_width / 64.)) * groups
self.branch2a = ConvNormLayer(
ch_in=ch_in,
ch_out=width,
filter_size=1,
stride=stride1,
groups=1,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr)
self.branch2b = ConvNormLayer(
ch_in=width,
ch_out=width,
filter_size=3,
stride=stride2,
groups=groups,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
dcn_v2=dcn_v2)
self.branch2c = ConvNormLayer(
ch_in=width,
ch_out=ch_out * self.expansion,
filter_size=1,
stride=1,
groups=1,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr)
self.shortcut = shortcut
if not shortcut:
if variant == 'd' and stride == 2:
self.short = nn.Sequential()
self.short.add_sublayer(
'pool',
nn.AvgPool2D(
kernel_size=2, stride=2, padding=0, ceil_mode=True))
self.short.add_sublayer(
'conv',
ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out * self.expansion,
filter_size=1,
stride=1,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr))
else:
self.short = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out * self.expansion,
filter_size=1,
stride=stride,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr)
self.std_senet = std_senet
if self.std_senet:
self.se = SELayer(ch_out * self.expansion)
def forward(self, inputs):
out = self.branch2a(inputs)
out = self.branch2b(out)
out = self.branch2c(out)
if self.std_senet:
out = self.se(out)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
out = paddle.add(x=out, y=short)
out = F.relu(out)
return out
class Blocks(nn.Layer):
def __init__(self,
block,
ch_in,
ch_out,
count,
name_adapter,
stage_num,
variant='b',
groups=1,
base_width=64,
lr=1.0,
norm_type='bn',
norm_decay=0.,
freeze_norm=True,
dcn_v2=False,
std_senet=False):
super(Blocks, self).__init__()
self.blocks = []
for i in range(count):
conv_name = name_adapter.fix_layer_warp_name(stage_num, count, i)
layer = self.add_sublayer(
conv_name,
block(
ch_in=ch_in,
ch_out=ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
variant=variant,
groups=groups,
base_width=base_width,
lr=lr,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
dcn_v2=dcn_v2,
std_senet=std_senet))
self.blocks.append(layer)
if i == 0:
ch_in = ch_out * block.expansion
def forward(self, inputs):
block_out = inputs
for block in self.blocks:
block_out = block(block_out)
return block_out
@register
@serializable
class ResNet(nn.Layer):
__shared__ = ['norm_type']
def __init__(self,
depth=50,
ch_in=64,
variant='b',
lr_mult_list=[1.0, 1.0, 1.0, 1.0],
groups=1,
base_width=64,
norm_type='bn',
norm_decay=0,
freeze_norm=True,
freeze_at=0,
return_idx=[0, 1, 2, 3],
dcn_v2_stages=[-1],
num_stages=4,
std_senet=False,
freeze_stem_only=False):
"""
Residual Network, see https://arxiv.org/abs/1512.03385
Args:
depth (int): ResNet depth, should be 18, 34, 50, 101, 152.
ch_in (int): output channel of first stage, default 64
variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently
lr_mult_list (list): learning rate ratio of different resnet stages(2,3,4,5),
lower learning rate ratio is need for pretrained model
got using distillation(default as [1.0, 1.0, 1.0, 1.0]).
groups (int): group convolution cardinality
base_width (int): base width of each group convolution
norm_type (str): normalization type, 'bn', 'sync_bn' or 'affine_channel'
norm_decay (float): weight decay for normalization layer weights
freeze_norm (bool): freeze normalization layers
freeze_at (int): freeze the backbone at which stage
return_idx (list): index of the stages whose feature maps are returned
dcn_v2_stages (list): index of stages who select deformable conv v2
num_stages (int): total num of stages
std_senet (bool): whether use senet, default False.
"""
super(ResNet, self).__init__()
self._model_type = 'ResNet' if groups == 1 else 'ResNeXt'
assert num_stages >= 1 and num_stages <= 4
self.depth = depth
self.variant = variant
self.groups = groups
self.base_width = base_width
self.norm_type = norm_type
self.norm_decay = norm_decay
self.freeze_norm = freeze_norm
self.freeze_at = freeze_at
if isinstance(return_idx, Integral):
return_idx = [return_idx]
assert max(return_idx) < num_stages, \
'the maximum return index must smaller than num_stages, ' \
'but received maximum return index is {} and num_stages ' \
'is {}'.format(max(return_idx), num_stages)
self.return_idx = return_idx
self.num_stages = num_stages
assert len(lr_mult_list) == 4, \
"lr_mult_list length must be 4 but got {}".format(len(lr_mult_list))
if isinstance(dcn_v2_stages, Integral):
dcn_v2_stages = [dcn_v2_stages]
assert max(dcn_v2_stages) < num_stages
if isinstance(dcn_v2_stages, Integral):
dcn_v2_stages = [dcn_v2_stages]
assert max(dcn_v2_stages) < num_stages
self.dcn_v2_stages = dcn_v2_stages
block_nums = ResNet_cfg[depth]
na = NameAdapter(self)
conv1_name = na.fix_c1_stage_name()
if variant in ['c', 'd']:
conv_def = [
[3, ch_in // 2, 3, 2, "conv1_1"],
[ch_in // 2, ch_in // 2, 3, 1, "conv1_2"],
[ch_in // 2, ch_in, 3, 1, "conv1_3"],
]
else:
conv_def = [[3, ch_in, 7, 2, conv1_name]]
self.conv1 = nn.Sequential()
for (c_in, c_out, k, s, _name) in conv_def:
self.conv1.add_sublayer(
_name,
ConvNormLayer(
ch_in=c_in,
ch_out=c_out,
filter_size=k,
stride=s,
groups=1,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=1.0))
self.ch_in = ch_in
ch_out_list = [64, 128, 256, 512]
block = BottleNeck if depth >= 50 else BasicBlock
self._out_channels = [block.expansion * v for v in ch_out_list]
self._out_strides = [4, 8, 16, 32]
self.res_layers = []
for i in range(num_stages):
lr_mult = lr_mult_list[i]
stage_num = i + 2
res_name = "res{}".format(stage_num)
res_layer = self.add_sublayer(
res_name,
Blocks(
block,
self.ch_in,
ch_out_list[i],
count=block_nums[i],
name_adapter=na,
stage_num=stage_num,
variant=variant,
groups=groups,
base_width=base_width,
lr=lr_mult,
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
dcn_v2=(i in self.dcn_v2_stages),
std_senet=std_senet))
self.res_layers.append(res_layer)
self.ch_in = self._out_channels[i]
if freeze_at >= 0:
self._freeze_parameters(self.conv1)
if not freeze_stem_only:
for i in range(min(freeze_at + 1, num_stages)):
self._freeze_parameters(self.res_layers[i])
def _freeze_parameters(self, m):
for p in m.parameters():
p.stop_gradient = True
@property
def out_shape(self):
return [
ShapeSpec(
channels=self._out_channels[i], stride=self._out_strides[i])
for i in self.return_idx
]
def forward(self, inputs):
x = inputs['image']
conv1 = self.conv1(x)
x = F.max_pool2d(conv1, kernel_size=3, stride=2, padding=1)
outs = []
for idx, stage in enumerate(self.res_layers):
x = stage(x)
if idx in self.return_idx:
outs.append(x)
return outs
@register
class Res5Head(nn.Layer):
def __init__(self, depth=50):
super(Res5Head, self).__init__()
feat_in, feat_out = [1024, 512]
if depth < 50:
feat_in = 256
na = NameAdapter(self)
block = BottleNeck if depth >= 50 else BasicBlock
self.res5 = Blocks(
block, feat_in, feat_out, count=3, name_adapter=na, stage_num=5)
self.feat_out = feat_out if depth < 50 else feat_out * 4
@property
def out_shape(self):
return [ShapeSpec(
channels=self.feat_out,
stride=16, )]
def forward(self, roi_feat, stage=0):
y = self.res5(roi_feat)
return y
本文总结
从今天开始正式开始更新RT-DETR剑指论文专栏,本专栏的内容会迅速铺开,在短期呢大量更新,价格也会乘阶梯性上涨,所以想要和我一起学习RT-DETR改进,可以在前期直接关注,本文专栏旨在打造全网最好的RT-DETR专栏为想要发论文的家进行服务。
官方链接:RT-DETR剑指论文专栏,持续复现各种顶会内容——论文收割机RT-DETR
