【大数据】深入浅出 Apache Flink:架构、案例和优势
深入浅出 Apache Flink:架构、案例和优势
- 1.现代大数据架构
-
- 1.1 什么是批处理?
- 1.2 什么是流处理?
- 2.Apache Flink 项目
-
- 2.1 处理无界和有界数据流
- 2.2 有界数据流
- 2.3 无界流
- 3.Apache Flink 架构和关键组件
-
- 3.1 Flink 架构
- 3.2 Flink 生态
-
- 3.2.1 DataSet APIs
- 3.2.2 DataStream APIs
- 3.2.3 Complex Event Processing(CEP)
- 3.2.4 SQL & Table API
- 3.2.5 Gelly
- 3.2.6 FlinkML
- 4.Flink 的关键用例
- 5.使用 Apache Flink 的优势
- 6.Apache Flink 的局限性
- 7.作为大数据基础设施堆栈一部分的 Apache Flink
- 8.Apache Flink 作为完全托管服务
- 9.结论
Apache Flink 是一个强大的开源流处理框架,近年来在大数据社区大受欢迎。它允许用户实时处理和分析大量流式数据,使其成为 欺诈检测、股市分析 和 机器学习 等现代应用的理想选择。
在本文中,我们将详细介绍什么是 Apache Flink 以及如何使用它来为您的业务带来益处。
1.现代大数据架构
大数据不仅仅是一个流行语,它已成为各种规模企业的现实。要利用大数据,您需要一个现代化的大数据生态系统。
现代大数据生态系统包括硬件、软件和服务,它们共同处理和分析大量数据。其目标是使企业能够更快地做出更好的决策,并改善其底线。几个组成部分是:
- 数据多样性(
Data Variety): 从多个来源摄取和输出不同类型的数据(结构化、非结构化、半结构化)。 - 速度(
Velocity): 快速摄取和实时处理数据。 - 量(
Volume): 大量数据的可扩展存储和处理。 - 廉价原始存储(
Cheap raw storage): 能够以经济实惠的原始形式存储数据。 - 灵活处理(
Flexible processing): 能够在同一数据上运行各种处理引擎。 - 支持流式分析(
Support for streaming analytics): 流分析是指提供低延迟,以接近实时的方式处理实时数据流。 - 支持现代应用(
Support for modern applications): 能够支持需要快速、灵活数据处理的新型应用,如 BI 工具、机器学习系统、日志分析等。
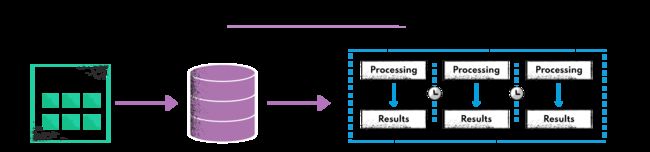
1.1 什么是批处理?
批处理是一种计算流程,包括收集数据并通过一系列任务批量运行。数据会被收集、分类,在此过程中通常会涉及多个步骤。批处理的结果通常被存储起来,以备将来使用。
数十年来,批处理一直被用于管理大量数据,至今仍有许多应用。不过,它并不适合需要近乎瞬时结果的实时应用。
1.2 什么是流处理?
在了解 Apache Flink 之前,有必要先了解一下流处理。流处理是一种处理连续、实时数据流的数据处理方式。
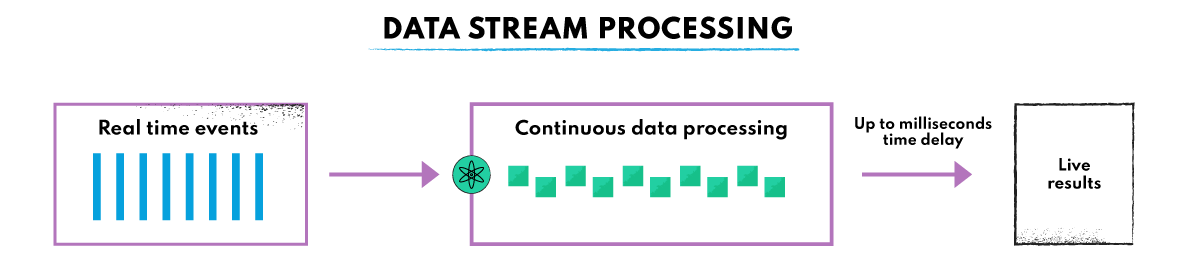
数据流处理不同于批处理,后者处理的是分批处理的离散数据集。批处理处理的是 “静止的数据”,而流处理处理的是 “运动的数据”。

与批处理相比,流处理有以下几个优势:
- 更低的延迟(
Lower latency): 由于流处理器以接近实时的方式处理数据,因此整体延迟较低,并为需要动态检查的多种特定用例提供了机会。 - 灵活性(
Flexibility): 流式处理交易数据通常比批处理更灵活,因为可以轻松处理更多的终端应用、数据类型和格式。它还能适应数据源的变化(例如,在物联网应用中添加新的传感器)。 - 成本更低(
Less expensive): 由于流处理器可以处理连续的数据流,因此总体成本较低(无需在处理数据前存储数据)。

在介绍了大数据和流处理的基础知识后,让我们来仔细了解一下流处理框架。
目前有多种流处理工具可供选择,每种工具都有自己的优缺点。一些最流行的流处理工具包括 Apache Storm、Apache Samza、Apache Spark 和 Apache Flink(本文重点介绍的框架)。
2.Apache Flink 项目
Apache Flink 是 Apache 软件基金会推出的开源流处理框架和分布式处理引擎,具有强大的容错能力和数据处理能力。它的设计结合了批处理和流式处理的优势,允许开发人员在一个系统中创建处理实时和历史数据的应用程序。
2.1 处理无界和有界数据流
Apache Flink 允许有界和无界数据流处理。有界数据流是有限的,而无界数据流是无限的。

2.2 有界数据流
有界数据流有明确的起点和终点;可以在一个批处理作业或多个并行作业中进行处理。Apache Flink 的 DataSet API 用于处理有界数据集,该数据集由用户迭代的单个元素组成。这种类型的系统通常用于对已经存在并提前知道的数据(如客户数据库或日志文件)进行类似批处理。
2.3 无界流
无界数据流则没有起点或终点;它们不断接收需要立即处理的新内容。这种类型的处理需要一个始终运行的系统,一旦有新的元素到来,就能立即接受。为此,Apache Flink 提供了用于实时处理流数据的 DataStream API,允许用户编写处理无限制数据流的应用程序。
3.Apache Flink 架构和关键组件
3.1 Flink 架构
Flink 基于分布式数据流引擎,没有自己的存储层。相反,它利用 外部存储系统,如 HDFS(Hadoop 分布式文件系统)、S3、HBase、Kafka、Apache Flume、Cassandra 和任何带有连接器集的 RDBMS(关系数据库)。这使得 Flink 能够以分布式方式处理任何规模、任何来源的数据。其核心是一个 分布式执行引擎,支持各种工作负载,包括批处理、流式处理、图处理和机器学习。
Flink 架构的下一层是 部署管理。Flink 既可以本地模式部署(用于测试和开发目的),也可以分布式方式用于生产。部署管理层由 Flink-runtime、Flink-client、Flink-web UI、Flink-distributed shell 和 Flink-container 等组件组成。这些组件协同工作,管理分布式集群中 Flink 应用程序的部署和执行。为了作为多节点集群运行,Flink 与 YARN(Yet Another Resource Negotiator)、Mesos、Docker、Kubernetes 等资源管理器紧密集成,或以独立模式(standalone mode)运行。

Flink 内核(Flink Kernel)是 Apache Flink 框架的核心元素。运行时层(runtime layer)提供分布式处理、容错、可靠性和本地迭代处理能力。
执行引擎 负责处理 Flink 任务,这些任务分布在多个集群节点上的分布式计算单元。这确保 Flink 可以在大规模集群上高效运行。

Apache Flink 数据流上的有状态计算,支持 事件驱动应用程序、流管道 以及 流批分析。
Flink 采用 主 / 从架构,包含 作业管理器(JobManager)和 任务管理器(TaskManager)。
- 作业管理器负责调度和管理提交给 Flink 的作业,并通过为任务分配资源来协调执行计划。
- 任务管理器负责在集群中的多个节点上,在分配的资源上执行用户定义的功能。

Apache Flink 主 / 从核心架构,包括 Flink Master 及其 作业管理器(JobManager)和 资源管理器(Resource Manager),以及用于分布式流数据流的 任务管理器(Task Managers)。
这种架构的优势在于,它可以高效扩展,以接近实时的方式处理大型数据集。它还提供容错功能,允许在数据损失最小的情况下重新启动作业,这对于关键任务应用来说是一项至关重要的能力。
3.2 Flink 生态
Flink 不仅仅是一个数据处理工具,还是一个包含多种不同工具和库的生态系统。其中最重要的有以下几种:

Apache Flink 生态系统组件:用于 流处理 的 DataStream API 和用于 批处理 的 DataSet API 以及 支持库: CEP、Table、FlinkML、Gelly 等。

3.2.1 DataSet APIs
DataSet API 是 Flink 用于 批处理 的核心 API。它用于执行 map、reduce、(outer)join、co-group 和 iterate 等操作。
3.2.2 DataStream APIs
DataStream API 用于处理 流数据(无限制和无限实时数据流)。它允许用户对传入事件定义任意操作,如窗口化、每次记录转换,以及通过查询外部数据存储来丰富事件。
3.2.3 Complex Event Processing(CEP)
Flink 的复杂事件处理库允许用户使用正则表达式或状态机指定事件模式。CEP 库与 Flink 的 DataStream API 相集成,可实时对数据进行模式识别。CEP 库的潜在应用包括 网络异常检测、基于规则的警报、流程监控 和 欺诈检测。
3.2.4 SQL & Table API
Flink 生态系统还包括用于关系查询的 SQL 和 Table API。它们提供了一种表达和执行流处理与批处理作业的统一方式。它允许用户编写 SQL 查询,使用 Table API,并根据表模式轻松操作数据,以最小的工作量构建复杂的数据转换管道。
3.2.5 Gelly
Gelly 是一个在 DataSet API 基础上运行的多功能图形处理和分析库。Gelly 与 DataSet API 无缝集成,使其具有可扩展性和健壮性。Gelly 具有标签传播、三角形枚举和页面排名等内置算法,同时还提供了图形 API 以方便自定义图形算法的实施。
3.2.6 FlinkML
FlinkML 是在 DataSet API 基础上运行的分布式机器学习算法库。它为用户提供了一种统一的方式来应用监督和非监督学习技术,如线性回归、逻辑回归、决策树、K-Means 聚类、LDA 等。FlinkML 还具有一个用于构建神经网络的实验性深度学习框架(包装 TensorFlow)。
4.Flink 的关键用例
Apache Flink 是处理大数据和流应用程序的强大工具。它支持有界和无界数据流,是各种案例的理想平台,如:
-
事件驱动型应用程序: 事件驱动型应用程序在本地访问数据,而不是查询远程数据库。通过这种方式,它们可以提高吞吐量和延迟方面的性能。Flink 的许多出色功能都围绕着对 时间 和 状态 的熟练处理。Flink 可以成为有状态应用程序的事件驱动架构的中心点,该架构从一个或多个事件流中摄取事件,并通过 触发计算、状态更新 或 外部操作 对传入事件做出反应(例如,欺诈检测、异常检测、基于规则的警报、业务流程监控、金融和信用卡交易系统、社交网络 和 其他消息驱动型系统)。
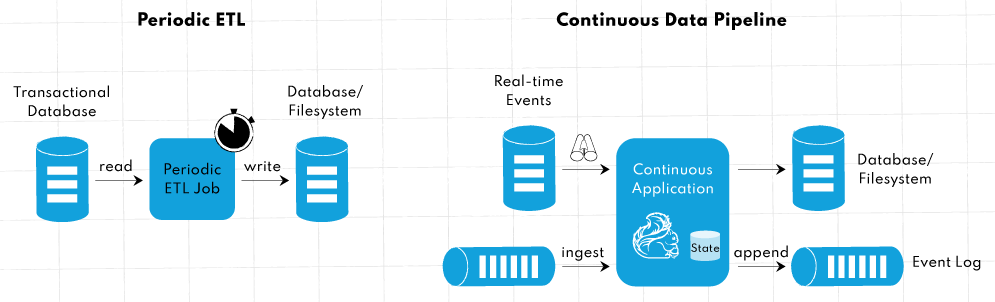
-
连续数据管道: 不需要定期运行 ETL 作业(提取、转换和加载),你可以实现类似的功能,即转换和丰富数据,并以持续流模式将数据从一个存储系统移动到另一个存储系统。
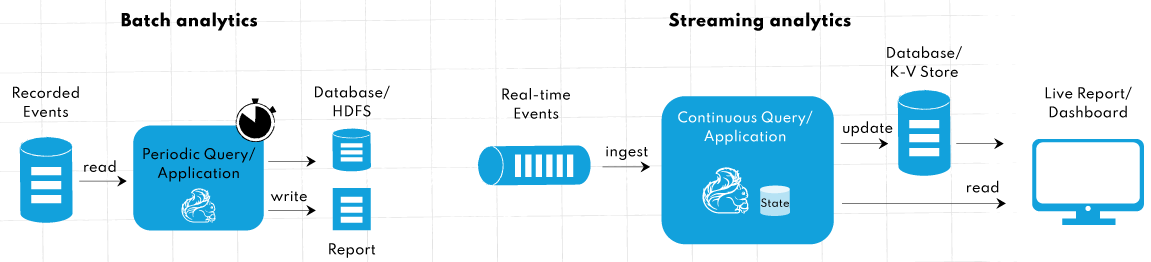
- 实时数据分析: Flink 是一个真正的流引擎,处理延迟极低,是近乎实时处理数据的理想工具,使其成为监控和触发操作或警报的绝佳工具(例如,各行业实时数据的 临时分析、客户体验监控、大规模图形分析 和 网络入侵检测)。
-
机器学习:FlinkML 提供了一个在 DataSet API 基础上运行的分布式机器学习算法库,允许开发人员使用大型数据集快速训练模型。FlinkML 可与其他深度学习框架集成,以实现更复杂的人工智能解决方案。
-
图形处理:Gelly 是一个多功能图形处理和分析库,可在数据集应用程序接口(DataSet API)之上运行,提供图形计算功能。
5.使用 Apache Flink 的优势
Apache Flink 是一个功能强大的分布式处理系统,用于有状态计算,最近越来越受欢迎。Flink 受欢迎的原因有很多,但其中最重要的优势包括速度快、易于使用以及能够处理大型数据集。
我们可以明确指出使用 Apache Flink 的许多优势,包括以下几点:
- 有状态流处理:Flink 的有状态流处理允许用户在连续数据流上定义分布式计算。这样就能对事件流进行复杂的事件处理分析,如窗口连接和聚合、模式匹配等。
- 流处理和批处理:Apache Flink 是需要同时处理流式数据和批处理数据的实时流应用程序的最佳选择。
- 可扩展性: Apache Flink 采用高效的网络通信协议,可扩展至数千个节点,且延迟和吞吐量损失极小。
- API 支持: Apache Flink 支持用 Java 和 Scala 编写流应用程序的 API。
- 容错性和可用性: Apache Flink 框架建立在强大的 Akka 角色系统之上,该系统提供固有的容错功能。Apache Flink 的分布式运行时引擎确保了流处理的高可用性和容错性,使其成为关键任务流应用程序的最佳选择。
- 低延迟、高吞吐量: Apache Flink 的处理速度快如闪电,吞吐量高,非常适合实时分析或处理来自物联网设备传感器测量、机器日志、信用卡交易数据或网络和移动点击流等来源的数据。
- 灵活的数据格式: 管理不同格式的数据可能具有挑战性,但 Apache Flink 支持多种不同的数据格式,如 CSV、JSON、Apache Parquet 和 Apache Avro。
- 优化: Flink 查询优化器提供多种内置优化功能,如 流水线(
pipelining)、数据融合(data fusion)和 循环解卷(loop unrolling),以减少计算时间。Flink Table API 和 SQL 还提供额外的查询优化和调整运算符实现。 - 灵活部署: Apache Flink 为多个常见的集群部署目标提供一流的支持,包括 YARN、Apache Mesos、Docker 和 Kubernetes。它还可以配置为独立集群运行。
6.Apache Flink 的局限性
使用 Apache Spark 也有一些限制和缺点,包括以下几点:
- 学习曲线过长: Apache Flink 是一个功能强大的框架,具有很多特性和功能,这可能会让新用户不知所措。
- 项目成熟度和社区规模: 它不像竞争对手那样流行,但最近越来越受欢迎,Apache Flink 社区也在稳步发展。
- API 支持有限: Apache Flink 目前仅支持 Java 和 Scala API,因此使用其他语言的开发人员必须使用封装器或外部库。
- 基本机器学习支持: 虽然 Apache Flink 通过 FlinkML 库提供了基本的机器学习支持,但与更全面的框架相比,它的支持是有限的(尽管如此,Flink 项目上的 TensorFlow 等社区项目仍提供了对深度学习的支持)。
7.作为大数据基础设施堆栈一部分的 Apache Flink
在大数据环境中,Flink 是一个只专注于计算而不提供存储的组件。作为大数据基础架构栈的一部分,Flink 与其他技术相结合,为希望快速高效地分析大型数据集的企业提供端到端解决方案。通常,它与作为事件日志的 Apache Kafka 以及作为存储层的 HDFS 或其他数据库等系统一起设置,以提供定期 ETL 作业或连续数据管道。
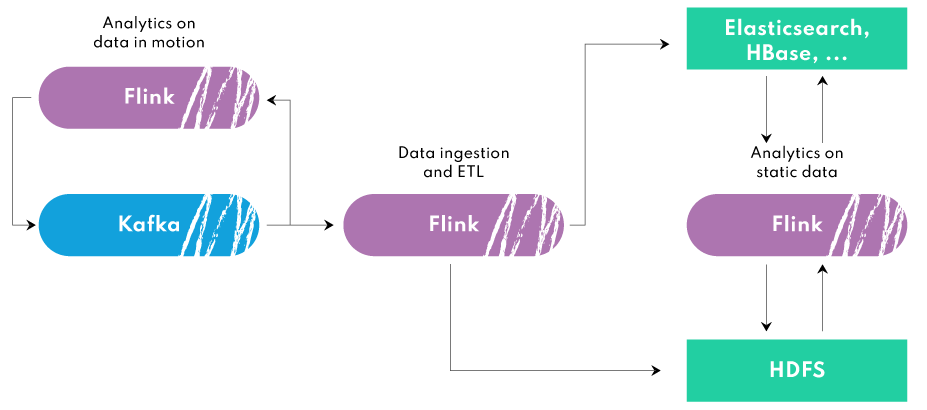
Apache Flink 在数据生态系统中与 Apache Kafka、HDFS、Elasticsearch、HBase 等一起提供数据摄取和 ETL 功能以及批量和流数据分析功能
一些世界领先的公司正在使用 Flink,其中包括 Amadeus、Capital One、Netflix、eBay、Lyft、Uber 和 Zalando。这些用例中的每一种都需要不同的数据处理方法或机器学习解决方案支持,而 Apache Flink 可以轻松处理所有这些用例。
8.Apache Flink 作为完全托管服务
您可以自行实施 Flink,也可以将其作为完全托管服务使用。完全托管服务是开始使用 Flink 的另一种方法,无需担心底层基础设施。
如果您寻求托管解决方案,Apache Flink 可以作为 Amazon EMR、Amazon Kinesis Data Analytics、Google Cloud Dataproc、Microsoft Azure HDInsight、Cloudera 和 Ververica Platform 的一部分。虽然在某些情况下它们可能不太灵活,但这些全面的托管服务为 Flink 提供了底层基础设施,并支持计算资源调配、并行计算、自动扩展和应用程序备份。
9.结论
以上就是对 Apache Flink、常见用例及其诸多优势的简要介绍。与市场上大多数流处理框架一样,它可以与其他工具一起使用,以创建更强大的竞标数据处理架构。
总的来说,Apache Flink 有几个显著的优点,使其成为当今最流行的分析引擎之一。它的速度快如闪电,是一个分布式系统,能以容错的方式处理批处理和流式数据,还能处理大型数据集,这些优点使它成为各种应用的理想选择。
如果您正在寻找一个强大的低延迟流引擎,可以处理您的所有工作负载(甚至更多),那么 Apache Flink 绝对值得考虑。如果您需要入门帮助,请随时联系我们。我们很乐意为您讲解基础知识,帮助您立即启动并运行 Flink 程序!