上一篇文章已经介绍了网站系统最需要关注的5大质量属性,接下来对这些特性进行详细介绍(这部分有部分内容会显得有些陈旧,之后会进行更新)。
高性能架构
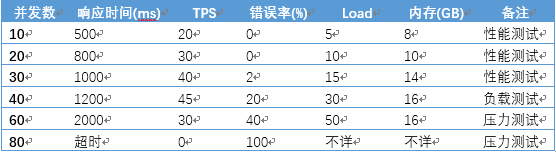
网站性能测试
性能测试时性能优化的前提和基础,也是性能优化结果的检查和度量标准,接下来介绍常见的性能测试指标。
- 响应时间:指一个操作的时间,包括发出请求开始到收到响应数据所需的时间,比如数据库查询一条带索引的记录需要10ms;机械磁盘顺序读取1MB数据需要2毫秒,从SSD需0.3毫秒,从内存则只需要10微秒;Java程序本地方法调用需要几微秒;网络传输2KB数据需要1微秒。
- 并发数:指系统同时处理请求的数据,反应系统的负载特性,通常情况下,网站用户数>>网站在线用户数>>网站并发用户数。在网站设计初期,PM和运营预测出不同阶段大体的用户数,作为系统设计的部分依据。测试程序通过多线程模拟并发用户的办法测试系统并发处理能力,为了模拟真实情况,测试程序并不是启动多线程不同发送请求,而是在两次请求间加入一个随机等待时间(思考时间)。
- 吞吐量:指单位时间内系统的请求数量,体现系统的整体处理能力。常见的量化指标包括TPS每秒事务数、HPS每秒HTTP请求数和QPS每秒查询数。此外,对于网站来说,PV(page view)浏览量,UV(Unique Visitor)独立访客数,IP独立IP数等是衡量一个网站价值的重要依据。李老师举了一个很棒的例子,“在高速公路上,吞吐量就是每天通过收费站的车数量,并发数是正在行驶的车辆,响应时间是车速。车辆少时,车速很快,但收取的费用也少;车辆多时,车速收到影响,但收取的费用提高;车辆继续增加,告诉越来越堵,收费不增反降;到达某个极限值时,车不走了,费也无从收起了,高速就变成了停车场(资源耗尽)”。因此网站性能优化的目的,除了改善响应时间外,还要提高吞吐量,最大限度利用资源。
- 性能计数器:描述服务器性能的一些数据指标,包括SystemLoad(指当前被CPU执行和等待CPU的进程总和,linux可以通过top命令查看)、对象与线程数、内存使用、CPU使用、磁盘与网络IO等,当监控系统发现性能计数器超过阈值时,就会向运维和开发人员报警。
性能测试是一个总称,具体可细分为性能测试、负载测试、压力测试和稳定性测试。
- 性能测试:以系统设计的性能指标为目标,对系统不断施压,验证系统在资源可接受范围内能否达到性能预期。
- 负载测试:不断增加并发请求,直到系统某项或多项指标达到安全临界值。
- 压力测试:在超过安全负载的情况下继续施压,直到系统不可用,以此获得系统最大承压能力。
- 稳定性测试:被测系统在制定环境下,加载一定业务压力,运行较长一点时间,检测系统是否稳定,在模拟时尽量使请求呈波浪形,一般的性能测试曲线如下所示。
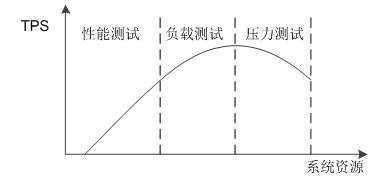
如果性能测试结果不能满足设计或业务的需求,就需要找到瓶颈并分而治之。
- 性能分析:排查网站瓶颈的手段主要是检查请求处理各处的日志,分析出哪个环节响应时间过长;然后检查监控数据,分- 析影响性能的主要因素,比如内存、CPU、网络、还是存储等,亦或者是代码问题、架构不合理、资源确实不足。
- 性能优化:在定位了原因后,可以找到对应层次(Web前端、应用服务器、存储服务器)进行优化,最后来查看一个常见的测试报告。
Web前端性能优化主要的手段包括优化浏览器访问、使用反向代理和CDN等。
- 浏览器访问优化:减少http请求,主要手段是合并CSS、JS和图片,这部分使用前端的打包工具即可;使用浏览器缓存,铜鼓欧设置http头中的Cache-Control和Expires属性,在细节上,如果需要反映静态文件的变化,可以通过改变文件名的方式,此外更新时尽量通过逐量更新的方式,避免突然负载增加;启用压缩,可以通过GZip对Html、css、js等文件进行压缩,不过需要权衡服务器的压力和网络压力;CSS放在页面最上面、Javascript放在页面最下面;减少Cookie传输,Cookie会包含在每次请求和响应的Http的Header中,如果太大会影响数据传输,特别是在访问静态资源时,没有任何意思,尽量考虑静态资源使用独立域名访问。
- CDN加速:Content Distribute Network内容分发网络本质是一个缓存,将数据缓存到离用户最近的地方。通常来说,会在CDN中存放静态资源,这些文件访问率高,可以极大改善网页的响应速度。
- 反向代理:传统的代理服务器位于浏览器一侧,代理浏览器将HTTP请求发送带互联网,而反向代理服务器位于网站机房一侧,代理网站Web服务器接收Http请求。它的功能很多,包括安全功能,在web服务器和公共网络间建立了一个屏障;通过配置缓存加速Web请求,比如Wiki将常用的词条放在反向代理服务器,当内容变化时通知反向代理服务器资源失效即可。
应用服务器性能优化的主要手段有缓存、集群和异步等。
- 缓存:请求访问的资源遵循28定律,因此请谨记网站性能优化第一定律优先考虑使用缓存优化性能。但如何合理的使用缓存是很大的一个难题,接下来介绍几个常见的要点。对于频繁修改的数据(读写比在2:1以下)和没有热点的访问无需进行缓存;需要给缓存的数据设置合适的失效时间,因此需要在业务作为规划,能够容忍数据不一致和脏读;新启动的缓存系统没有热点数据,为了使它尽早进入工作状态,就需要直接加载部分关键数据,比如类目列表等信息,进行缓存预热;如果因为不恰当的业务或恶意工具持续访问某个不存在的数据,那么无法缓存,会持续访问数据库,这种现象称为缓存穿透,可以通过将不存在数据设置为null并缓存起来解决。
- 异步操作:通过消息队列将调用异步化,可改善网站性能、扩展性,特别的,其具有很好的削峰作用,将短时间高并发的事务消息存储在消息队列。在电子商务网站的促销活动中,使用消息队列,可有效抵御促销活动刚开始大量涌入的订单对系统造成的冲击。需要注意的是,由于数据写入消息队列后立即返回给用户,数据的后续校验、写数据库等操作均可能失败,因此需要适当修改业务流程以配合,如提交订单后,数据写入队列,不能立即返回用户成功,需要在消息队列的订单消费者真正处理完该订单,甚至商品出库后,再电子邮件或SMS等方式提醒用户订单成功,以免交易纠纷。
系统中,任何可以晚点做的事情都应该晚点做! - 使用集群:在高并发场景下,使用负载均衡技术为应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器处理,避免单一服务器负载压力过大。根据性能测试曲线,使服务器的并发请求数目控制在最佳运行区间,获得最佳访问延迟。
- 代码优化:对于网站的业务逻辑代码,很多地方必要时值得进行优化,接下来介绍几个常见手段。
多线程:对于网站来说,默认都是采用多线程的方式响应并发用户的请求(不管程序员是否进行多线程编码),通常来说,启动的线程数=[任务执行时间/(任务执行时间-IO等待时间)]*CPU核数。当然在使用多线程时一定要注意线程安全(将对象设计为无状态对象、使用局部对象、并发访问资源使用锁)的问题,不然故障很难排查错误。
资源复用:常见的方式包括单例Singleton和对象池Object Pool,Web开发主要使用贫血模式,从Service到Dao都是无状态的,因此无需重复创建,很适合单例。而对于数据库和Web服务器,通常使用数据库连接池和线程池的方式。
数据结构:程序=数据结构+算法,过去读书时老师就最重视数该部分的教学,因此对于软件项目质量非常重要。缓存部分就涉及Hash算法,Hash表的读写性能很依赖HashCode随机性,常见字符串的Time33算法,其原理为hash(i)=hash(i-1)*33+str[i],如果仍然无法满足要求,可以先对字符串通过md5算法获得信息指纹,然后再进行Hash计算。
垃圾回收:如果Web应用运行在JVM等具有垃圾回收功能的环境中,垃圾回收会对系统产生很大影响,理解垃圾回收机制对于程序优化和参数调优有着积极影响。以JVM为例,内存主要划分为栈stack和堆heap,前者存储线程上下文信息,后者存储对象,因此对象的创建、垃圾回收等均在此处,传统的GC结构可参见JVM快速学习一文。
存储性能优化
- B+树 vs. LSM树:传统的机械磁盘具有快速顺序读写、慢速随机读写的访问特性,为了改善数据访问特性,通常会对数据排序后存储,加快检索效率,这就需要保证数据在不断更新、插入、删除后依然有序。传统数据库系统使用B+树来实现存储,其是专门用于对磁盘存储而优化的N叉排序树,以树节点为单位存储在磁盘,从根开始查找所需数据所在节点和磁盘位置,将其加载到内存继续查找,直到找到所需数据,一次更新操作可能需要5次访盘(3次访问索引和行ID,一次数据文件读和一次写),详情请见Wiki B+树。而对于NOSQL数据库,则多使用LSM树作为数据结构,其可以看做一个N阶合并树,数据的增、改、删都在内存进行,当数据量超过内存阈值时,将这内存中排序树与磁盘中排序树合并,读取时先从内存中查找,未找到则访盘,一次更新操作完全可以在内存中完成,速度很快,详情请见Wiki Log-structured merge-tree。
- RAID vs. HDFS:在互联网RAID现在被HDFS代替,比如Hadoop的分布式文件系统HDFS,其以块(64MB)为单位管理文件内容。当应用程度写文件时,每写完一个块,HDFS会将其自动复制到另外两台机器,实现RAID1的功能。当对文件进行处理时,通过MapReduce兵法计算任务框架,可以启动多个子任务,同时读取多个快,相当于RAID0,详情请参见Hadoop快速入门。
高可用架构
- 网站可用性的度量与考核:网站不可用也被称为网站故障,业界通常用多少个9来衡量,如果QQ就是4个9,一年最多有53分钟不可用,常见指标有网站不可用时间(故障时间)=故障修复时间点-故障发现(报告)时间,网站年度可用性指标=(1-网站不可用时间/年度总时间)
*100%。可用性指标是网站架构设计的重要指标,对外是服务承诺,对内是考核指标。所谓故障分就是对网站故障进行分类加权计算故障责任的方法,公式为故障分=故障时间(分钟)*故障权重,常见的例子如下表所示。
- 高可用的网站架构:传统企业级应用往往依赖于IOE(IBM服务器、Oracle数据库和EMC存储设备),而互联网公司会趋向于选择廉价的服务器、开源的操作系统和数据库,因此硬件故障是常态,就需要实现数据和服务的冗余备份和失效转移。位于应用层的服务器通常为了应对高并发的访问请求,会通过负载均衡设备将服务器组成集群对外服务,当负载均衡设备通过心跳检测等手段监控到某台应用服务器不可用时,就将其从集群列表中剔除,并将请求分发到集群中其他可用机器上,保持整体可用,接下来进行详细介绍。
Session管理:由于应用服务器的高可用基于服务无状态的特性,但实际上,业务总是有状态的,比如电商网站,需要购物车记录用户的购买信息,每次购买都要向购物车中添加商品;在社交网站中,需要记录用户当前的登录状态、最新发布的消息及还有状态等。Web应用中将这些多次请求修改使用的上下文对象称为会话Session,常见的管理手段包括Session复制,Session绑定(通过负载均衡的原地址Hash算法实现,也称为会话黏滞),利用Cookie记录Session,使用Session服务器(用于对Session管理要求比较高的场景,比如利用Session服务集成单点登录SSO,用户服务等功能)。
服务管理:分级管理(区分业务优先级),超时设置(一旦超时通信框架就抛出异常,避免资源占用),异步调用,服务降级(拒绝服务、关闭功能),幂等性设计。此外,服务的失效转移包括失效确认、访问转移和数据恢复。
数据管理:在互联网场景下,通常会强化分布式存储系统的可用性和伸缩性,而牺牲一致性(详情请见CAP原理)。
测试与发布:很多网站都采用Web自动化测试技术,比如ThoughtWorks的Selenium等。而网站发布可以是一次提前预知的服务器宕机,所有过程可以更加柔和,对用户影响更小,通常通过发布脚步完成(更好的是遵循标准的的流程,构建自动化发布系统),对如下步骤进行循环,知道集群中所有机器发布完成。关闭负载均衡上部分服务器路由->关闭这些服务器->同步软件代码包到这些服务器->启动这些服务器->打开负载均衡路由
通常为了避免因环境因素(fat->uat->prod)造成的发布问题,会通过预发布验证的方式,这个特殊预发布服务器也称为堡垒机,其与正式线上服务器的区别是没有配置在负载均衡服务器上,外部用户无法访问。在网站应用中特别强调快速失败,应及早处理错误而不是掩盖错误。
此外,在实践中,还可以通过灰度发布来逐步的进行代码的发布以减少不良影响,这种手段也可以用于ABTest,以验证业务设计的合理性。 - 网站运营监控:监控数据的采集包括供产品经理使用的网站用户行为日志UBT log、业务运行数据和供DevOps使用的系统性能数据等。
用户行为数据通常包括用户使用终端的OS、浏览器版本、IP、网页访问路径、页面停留时间等,这对于统计网站PV/UV指标、分析用户行为、个性化营销和推荐非常有帮助,很多网站都使用类似Storm的日志统计和分析工具(Elastic Search)。
服务器性能监控:监控系统Load、内存占用、磁盘IO、网络IO等信息,便于尽早发现应用故障,常用工具有Ganglia、vi、cat等。发现问题时,常见处理方式包括报系统警、失效转移、自动优雅降级等。
箴言:绝不允许没有监控的系统上线
可伸缩架构
关于伸缩性,比较流行的一个例子就是曾经京东和淘宝的比对,当然现在JD的系统早已完成技术栈的改造跑的很平顺,不过在当时,的确存在用户在提交订单后,页面显示“Service is too busy”,之后东哥声称已购买多台服务器以增加处理能力,结果然并卵,体现了系统的伸缩性不足。
网站架构的伸缩性设计:回顾网站历史可以发现,网站架构的发展就是一部不断向网站添加服务器的过程,只要工程师能通过向网站的服务器集群中添加机器,就能提高网站的整体服务能力,那么就是合格的。通常的手段包括不同功能进行物理分离实现伸缩,比如纵向的分为Web服务器、应用服务器、数据服务器,以及横向的业务划分;针对单一功能通过集群规模实现伸缩。具体来说,应用服务器和数据服务器对数据状态管理的不同,技术实现区别较大,后者还可以分为缓存数据服务器集群和存储数据服务器集群。
- 应用服务器集群:应用服务器被设计为无状态的,通过http请求分发器实现负载均衡,其基础技术包括HTTP重定向负载均衡,DNS域名解析负载均衡,反向代理负载均衡,IP负载均衡,数据链路层负载均衡。对于大型网站来说,通常使用DNS域名解析作为第一级的负载均衡手段,即域名解析得到的一组服务器并不是实际提供服务的服务器,而是系统内部的负载均衡服务器,其作为第二级的负载均衡手段。第二级的负载均衡的实现一般选择反向代理服务器或数据链路层负载均衡服务器,反向代理服务器需要设置双网卡和内部外部两套IP地址,属于应用层负载均衡,优点是部署简单。数据链路层负载均衡是目前大型网站最常用的方式,linux平台上最好的该类开源产品为LVS(Linux Virtual Server),其原理如下图所示,该方式也被称为三角传输方式。
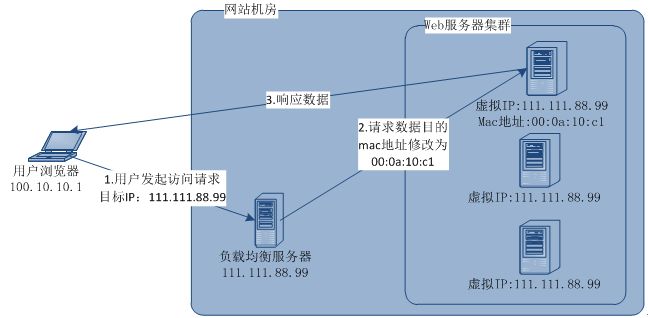
此外,常见的负载均衡算法包括轮询,加权轮训,随机,最小链接,源地址散列等。
- 分布式缓存集群:Memcached是曾经分布式缓存的代表,应用程序通过Memcached客户端访问集群,Memcached客户端主要由一组API、Memcached服务器集群路由算法、Memcached服务器集群列表及通信模块组成,这部分还涉及一个面试中常用的概念
一致性Hash环算法,还可以参考博文Java架构师。 - 数据存储服务器集群:和缓存服务器集群的伸缩性不同,数据存储服务器集群的伸缩性对数据的持久性和可用性提出了更高的要求。对于传统的数据库,比较成熟的,支持数据分片的分布式关系数据库产品有阿里的Cobar,它是一个访问代理,介于应用服务器和数据库服务器之间。应用程序通过JDBC驱动访问Cobar集群,Cobar服务器根据SQL和分库规则分解SQL,分发到MySQL集群不同的数据库实例上执行。其伸缩性通过Cobar服务器集群的伸缩和MySQL服务器集群上的伸缩,当集群扩容时,必须要做数据迁移,这是可以考虑使用一致性Hash算法,尽量使需要迁移的数据最小。对于NOSQL数据库,由于其天然支持扩展性,比如Hadoop,可以参见Hadoop快速入门一文。
可扩展架构
有的网站必须规定系统发布日,一到发布日就如临大敌,人人加班,而有的网站可以随时发布,新功能可以快速上线,这都依赖于网站的扩展性架构设计。通常我们很容易混淆扩展性和伸缩性的概念,扩展性表示对现有系统影响最小的情况,系统功能可持续扩展的能力,符合开闭原则;伸缩性表示系统能够通过增加/减少自身资源规模的方式增强/减少自己处理事务的能力。李老师认为,"软件架构师最大的价值就在于具有将一个大系统切分为N个低耦合的子模块的能力,这些子模块既包括横向的业务模块,也包括纵向的基础技术模块",接下来介绍几种常见手段。
- 分布式消息队列:消息队列通过生产者-消费者模式很好的降低了系统的耦合性,其实现方式包括数据库实现(生产者程序将消息写入数据库,消费者程序读取记录并处理),也可以支持ESB和SOA的复杂形式。
- 分布式服务:这是实践中最合理的方式,当前流行的微服务就是基于该思想。常见的有复杂的基于SOAP协议的Web Service和基于Http协议的RESTful服务。对于大型网站,其SOA架构除了支持服务注册&发现,服务调用等基本功能外,还需要支持负载均衡、失效转移、高效的远程通信、整合异构系统(.NET&JAVA)、对应用最小侵入、版本管理、实时监控的功能。在Java技术栈中,比较常用的SOA开源架构包括阿里巴巴的Dubbo,其架构原理如图所示,详情请参见Dubbo。
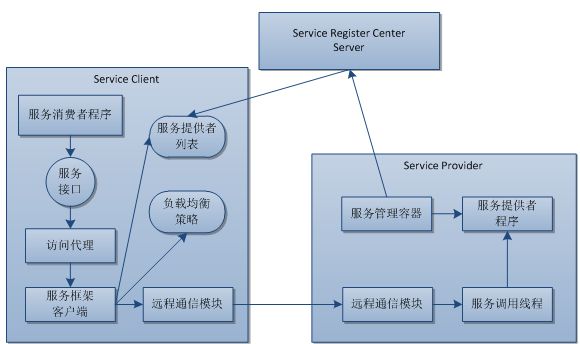
- 可扩展的数据结构:比如NOSQL中的列式存储HBase,其schema通过列族的形式存在,可以随时对其进行扩展。
- 开放平台:其实现主要包括API接口、协议转换、安全、审计、路由、流程等模块。
安全性架构
常见网络攻防:针对网站,常见的攻击手段包括XSS、SQL注入、CSRF、Session劫持等,接下对这些手段进行简要介绍。
- XSS攻击(Cross Site Script跨站脚本攻击):指通过在网页上注入HTML脚本,在用户浏览网页时,达到控制用户浏览器进行恶意操作的攻击方式,常见的比如在评论区注入脚本。其类型包含反射型和持久型两种,属于一种比较“古老”的攻击手段,而抵御这类攻击的主要手段是消毒和HttpOnly。前者是需要对用户提交的任何数据保持怀疑并对内容进行转义;后者要求页面js不能访问带有HttpOnly属性的Cookie,以此来保护用户信息,减小危害。
- 注入攻击:注入攻击主要包括SQL注入攻击和OS注入攻击。前者的原理非常简单,通过在Http请求中注入恶意SQL命令(drop tabele users;),服务器用请求参数构造数据库命令时会携带上恶意参数并执行。因此,SQL注入需要了解网站的数据结构,比如开源系统结构都一样,可以通过对页面请求的错误回显进行判断,最后是根据页面变化进行猜测(盲注)。预防手段包括消毒,即通过正则表达式过滤数据中可能的有害内容;另一种就是通过预编译手段,绑定参数是最好的放SQL注入方法。
- CSRF攻击(Cross Site Request Forgery跨站请求伪造):攻击者通过跨站请求,已合法用户的身份进行非法操作,其核心是利用了浏览器Cookie或服务器Session策略,盗用用户身份。因此其防御手段就是识别请求身份,主要手段包括表单token(主流框架都支持),验证码,Referer check。
- 其他攻击和漏洞:Error Code,在生产环境关闭错误回显,跳转到专门的错误页面给用户;HTML注释,需要在发布前对代码进行扫描,避免HTML注释;文件上传,设置上传文件类型的白名单,禁止可执行程序的上传;路径遍历,攻击者比通过使用相对路径,遍历系统未开放的内容,主要防范手段包括将js和CSS资源部署在独立服务器,使用独立域名,其他文件不适用静态url访问,动态参数不包含文件路径信息。
- 常见防范手段:常用的包括防火墙和网站安全漏洞扫描,推荐一个不错应用防火墙ModSecurity,其对主流平台有不错支持,其采用处理逻辑和攻击规则分离的架构模式,便于扩展规则。
信息加密和密钥管理:还记得2011年底CSDN密码泄露事件么,我也因此去修改自己所有类似的账号密码,可以用户信息安全的重要性,常见的加密手段包括单向散列加密(MD5,SHA),通过添加salt后hash,保存客户密文密码,之后进行密文比对,可以防范拖库或彩虹表;对称加密(DES,RC)和非对称加密(RSA)。此外,由于信息安全依赖秘钥,因此保证秘钥的安全也非常重要,常见手段包括把秘钥和算法做成独立服务;将加密算法放在应用中,但秘钥放在独立服务器,并分片存储。
信息过滤与反垃圾
- 文本匹配:常使用Trie算法或敏感词过滤树,Trie算法本质是一个有限状态自动机,根据输入数据进行状态转移,敏感词树则通过多级hash表进行文本匹配,有时候为了绕过敏感词检查,某些输入会对信息做手脚,如足_球,还需要对信息进行降噪预处理再匹配。
- 分类算法:例如对于垃圾邮件,会将批量已分类的邮件样本输入分类算法进行训练,得带一个垃圾邮件分类模型,然后利用算法和模型对邮件进行识别。比较常见的算法有贝叶斯分类算法,其根据已分类的样本信息获得一组特征值概率,如“篮球 ”这个词出现在垃圾邮件的概率为20%,出现在非垃圾邮件中的概率为1%,得到分类模型。此外还有TAN算法、ARCS算法进行补充,不过有贝叶斯算法最简单高效,实际应用最为广泛。
- 黑名单:可以通过Hash表实现,不过当黑名单信息过多时,Hash表会非常巨大。如果精确性要求不高,可以使用布隆过滤器代替。
电子商务风险控制
电商网站在带来购物便利的同时,也带了巨大的安全风险,在B2B,B2C,C2C等交易场景中,主要风险包括账户风险,账户被黑客盗用,而已注册账号;卖家风险,不良商家进行恶意欺诈,比如货不对板、虚假发货、炒作信用、出售侵权或违禁商品等;买家风险,卖家恶意下单占用库存,黄牛利用促销抢购低价商品,良品拒付,欺诈退款,虚假询盘等;交易风险,信用卡盗刷,支付欺诈,洗钱套现等。因此,大型电商网站都配备专门的风控团队进行风险控制,通过机器自动识别高风险交易和信息并发送给风控审核人员进行人工审核。机器自动风控的手段主要包括规则引擎和统计模型,规则引擎当交易某些指标满足一定条件时,就认为其具有高风险的欺诈可能性。比如用户来自欺诈高发地区,交易金额超过阈值,和上次登录的地区距离差异很大,用户登陆地和收货地不符,用户第一次交易等。当规则越来越复杂时,很多规则间会产生冲突,此时就需要使用统计模型进行风控了,其通过更加复杂的分类算法或机器学习算法进行智能统计,在充分训练后,保证准确率不低于规则引擎,并可以对欺诈行为有一定的预见性。
参考资料
- 李智慧. 大型网站技术架构[M]. 北京:电子工业出版社, 2013.