【c++】入门3
引用
1.swap交换两个变量值的时候可以用引用
2.例题中通过前序遍历数组构建二叉树,可以用引用传别名.
#include i变量是在main函数栈帧中创建的,在调用BinaryTreeCreate(arr,&i);完不会被销毁,可以用引用.
修改如下:
#include 用到引用的地方都是输出型参数
引用做返回值

注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
下面代码输出什么结果?为什么?
#include分析:这个程序是不对的,我们刚才说过要使用引用的话,必须是输出型参数,也就是出了作用域不销毁的参数,而这里的c是局部变量,是临时变量,出了作用域要被销毁的。如果传引用回去的话,c地址上的值会被修改。因为c地址上的值随着栈帧的销毁而被修改。这里为什么会是7,因为再次调用同个函数时,用的是和上一个调用的add函数同样的栈帧,所以原地址上的c地址上的值会被新的值7覆盖,于是ret就是7了.
#include如果删除一行,打印出来的值不一定是3,取决于不同的编译器。栈帧中变量空间是否被回收不知道.
传值返回
1.传参返回时不是直接返回,会产生临时变量.
2.静态变量出栈不会被销毁,也产生临时变量.
传引用返回
1.用于出了作用域。不销毁的变量.
2.减少了临时变量的拷贝.
3.调用者可以修改返回对象,比如上面的ret.
4.栈帧销毁,内存消除不确定.
5.出栈帧不存在的变量会出现错误,就不要用引用返回.
6.静态,全局,上一次栈帧,malloc来的变量可以用引用.
7.传引用返回比传值返回提高了效率,不用建立临时变量.
常引用
权限放大
#include将只读的变量c,使用引用,d变量的权限不能变成既能读,又能写.权限不能放大.
在举一个指针权限放大的:
#include同样也是权限放大,编译器会保错.
权限保持
只读-只读
#include权限缩小
#include指针也一样
权限放大,缩小适用于指针和引用.
下面这个可以吗??
#include强制类型转换是将i的值做强制类型转换后的值存在一个临时变量中,而这里的rd是临时变量的别名,而不是i的别名,临时变量具有常性,也就是只读,这里属于权限放大了,加上const的话属于权限平移.
#include引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间.在底层实现上实际是有空间的,因为引用是按照指针方式来实现的.
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
内联函数
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
内联函数的引出
我们之前学过宏定义函数
#include宏定义的函数不用创建栈帧.
但是宏定义的函数只能是死替换
#include这样死套就会出错,内联函数的引入,也不会创建栈帧
#include
对应汇编语言有call指令说明有创建栈帧.
使用inline函数是否创建栈帧
查看方式:
- 在release模式下,查看编译器生成的汇编代码中是否存在call Add
- 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不
会对代码进行优化,以下给出vs2013的设置方式)
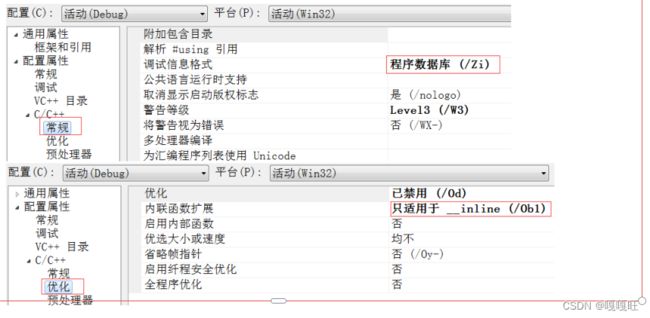
使用inline函数后没有call指令,说明没有创建栈帧

inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性.

#include
此函数没有liline展开成函数体,有call指令,创建了函数栈帧.
面试题
宏的优缺点?
优点:
1.增强代码的复用性。
2.提高性能。
缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用。
3.没有类型安全的检查 。
C++有哪些技术替代宏
短小函数定义 换用内联函数