Reactor和Proactor两种高效的事件处理模式

Reactor模式
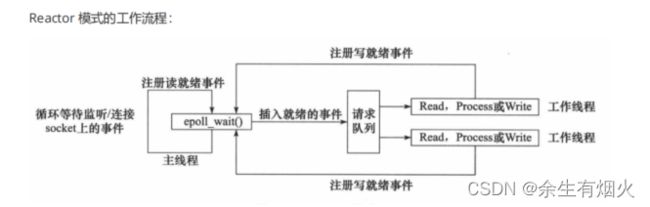
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
「多 Reactor 单进程 / 线程」实现方案相比「单 Reactor 单进程 / 线程」方案,不仅复杂而且也没有性能优势,因此实际中并没有应用。
剩下的 3 个方案都是比较经典的,且都有应用在实际的项目中:
单 Reactor 单进程 / 线程;
单 Reactor 多线程 / 进程;
多 Reactor 多进程 / 线程;
1. 单 Reactor 单进程 / 线程

可以看到进程里有 Reactor、Acceptor、Handler 这三个对象:
- Reactor 对象的作用是监听和分发事件;
- Acceptor 对象的作用是获取连接;
- Handler 对象的作用是处理业务
但是,这种方案存在 2 个缺点:
第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
2.单 Reactor 多线程 / 多进程
如果要克服「单 Reactor 单线程 / 进程」方案的缺点,那么就需要引入多线程 / 多进程,这样就产生了单 Reactor 多线程 / 多进程的方案。
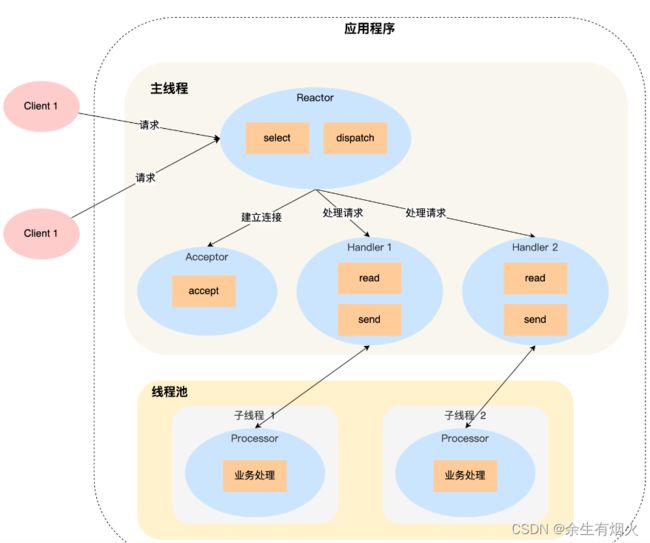
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
引入多线程确实可以充分利用多核 CPU 的性能,但也带来了共享资源的竞争和同步的问题。使用互斥锁是一种常见的手段,但需要小心避免死锁和性能问题。
关于单 Reactor 多进程方案,你提到了一些问题,确实存在挑战。进程间通信的复杂性和父进程需要了解子进程要发送数据给哪个客户端的问题增加了实现的复杂度。相对而言,多线程之间可以共享数据,虽然需要考虑并发问题,但处理起来相对简单。
「单 Reactor」的模式在面对瞬间高并发的场景时可能成为性能瓶颈。这是因为单个 Reactor 在主线程中运行,如果事件处理耗时较长,可能导致其他事件的等待,降低系统的响应性能。这是一个需要权衡的问题,可以通过使用多个 Reactor 实例或者其他更复杂的事件处理模型来解决。
3. 多 Reactor 多进程 / 线程
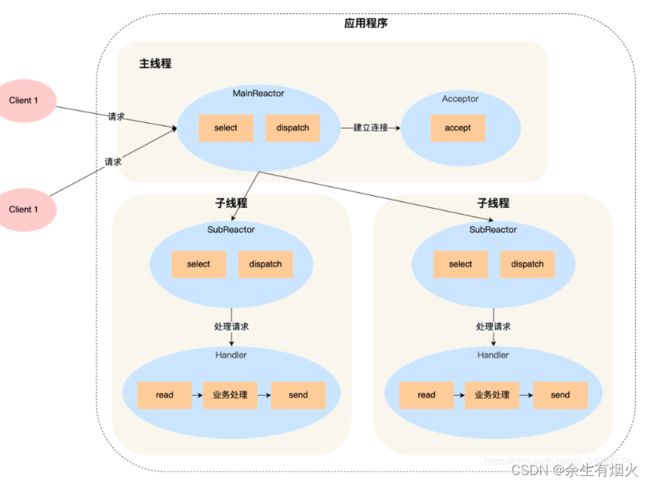
1 .主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
2. 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
3.如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
-
- Nginx 是一个高性能的 HTTP 和反向代理服务器。它采用了多 Reactor 多进程的方案,其中主进程负责初始化 socket,而具体的连接处理则由子进程的 Reactor 负责。这种模型有效地避免了惊群现象,并且每个子进程都有自己的 Reactor 处理连接,提高了并发性。
对于 Nginx 中提到的差异,即主进程只负责初始化 socket,具体的连接处理由子进程的 Reactor 完成,这是一种典型的 Nginx 的优化策略,避免了主进程直接参与连接的处理,降低了主进程的压力。这样的设计有效地避免了惊群现象,提高了整体性能。这种模型也被称为 "master-worker" 模型。
Proactor模式
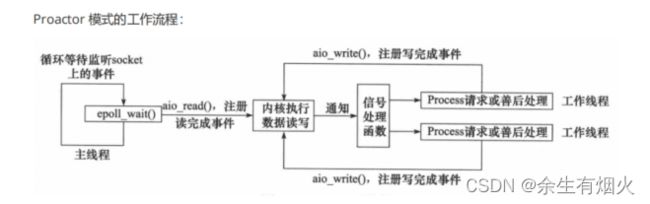
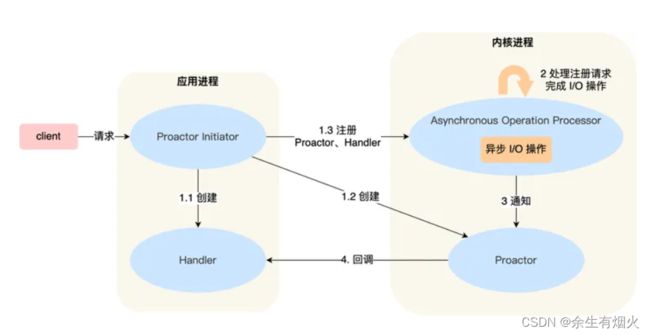
可惜的是,在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
区别:
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
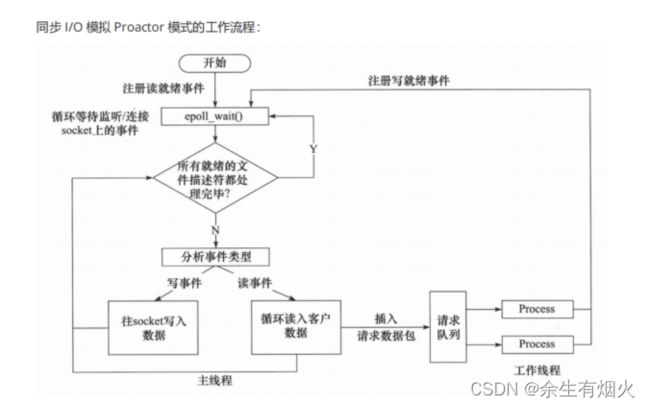
模拟proactor