任务12:使用Hadoop Streaming解压NCDC天气原始数据
任务描述
知识点:
- NCDC原始的气象数据上传到HDFS
- MapReduce程序处理NCDC原始数据
重 点:
- 熟练使用HDFS基础命令
- 查看HDFS文件块的分布情况
- 掌握Linux系统Shell脚本的编写
- 熟练使用MapReduce程序解压缩文件
- 使用MapReduce程序处理NCDC气象数据
内 容:
- NCDC气象数据上传至HDFS
- 检查HDFS文件块的分布情况
- 编写Linux Shell脚本生成input文件
- 编写Shell脚本处理原始的NCDC数据文件,并将其存储在HDFS中
- 使用MapReduce程序运行Shell脚本,处理NCDC数据
任务指导
以上一步中下载的2021和2022两年的数据为例。学生参照下面的步骤可以自行处理其他年份的数据。
1. NCDC气象数据
1)原始的NCDC气象数(noaa/isd-ite数据)据实际是一组经过gzip压缩的gz文件。每个年份的所有气象站的数据单独放在一个文件中。
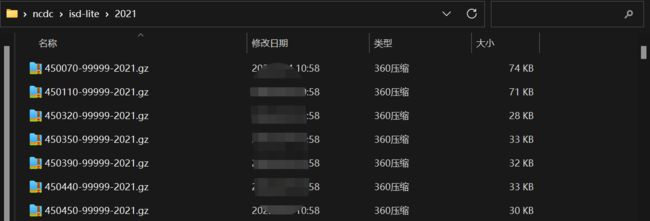
2)每个gzip压缩文件中包含,描述某一气象站在一年中的所有天气数据记录。
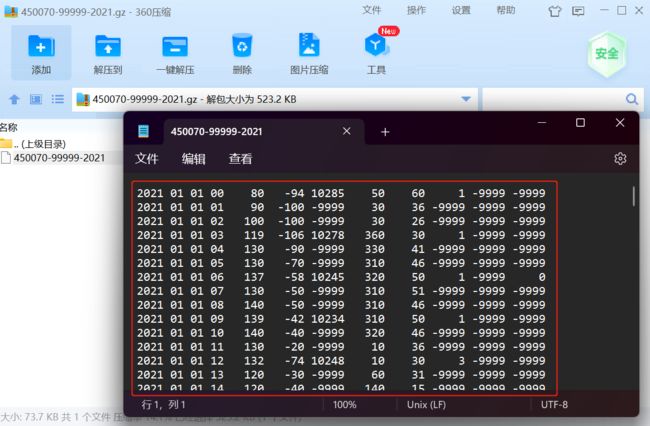
3)气象要素包括:气温、气压、露点、风向风速、云量、降水量等。
- 例如:
![]()
- 各字段的含义如下:
| 年 | 月 | 日 | 时间 | 温度 | 露点温度 | 气压 | 风向 | 风速 | 云量 | 1小时雨量 | 6小时雨量 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2021 | 01 | 01 | 00 | 80 | -94 | 10285 | 50 | 60 | 1 | -9999 | -9999 |
2. NCDC气象数据上传过程
- 准备数据集
- 在HDFS上新建文件夹用于存放气象数据
- 将本地存储NCDC气象数据上传到HDFS中
- 查看文件块的分布情况
3. Hadoop处理NCDC原始数据
在Hadoop集成环境中处理这些原理数据,气象站数以万计,整个数据集实际是一组经过gzip压缩的gz文件,每个年份的所有气象站的数据单独放在一个文件中,所以在本例中需要将每个年度的所有气象站数据(.gz文件)解压缩到以年份命名的文件夹中。上述操作可由一个MapReduce程序来完成,以充分利用其并行处理能力的优势。下面具体演示这个程序。
4. 处理NCDC原始数据实现过程
1)新建generate_input_list.sh脚本,生成MapReduce的input文件
- input文件包含要处理的文件列表
- 为generate_input_list.sh添加执行能力
- 运行generate_input_list.sh脚本,生成包含需要处理的文件夹列表的ncdc_files.txt文件

2)利用bash脚本处理原始的NCDC数据文件,并将其存储在HDFS中
- 新建load_ncdc_map.sh文件
- 给load_ncdc_map.sh添加运行权限
- 使用hadoop-streaming作业运行上面的bash脚本
- 程序运行完成,在HDFS的/GSOD_ALL目录下生成对应年份目录

- 在每个目录下,包含该年份所有气象站的数据文件
任务实现
以上一个任务中下载的2021和2022两年的数据为例。学生参照下面的步骤可以自行处理其他年份的数据。
1. 将NCDC原始的气象数据上传到HDFS上,步骤如下(在master节点上):
1)将下载到本地的NCDC气象数(noaa/isd-ite数据)文件上传到master节点服务器上。(当前项目环境已在对应路径位置提供相应数据,已上传到master节点服务器。)

2)将master节点(NameNode所在的节点)服务器上的本地文件上传到Hadoop集群的HDFS中。
- 在HDFS上新建 GSOD 文件夹保存所有原始气象数据文件
# hdfs dfs -mkdir /GSOD- 在HDFS上新建 GSOD_ALL文件夹来保存重新处理后的气象数据文件
# hdfs dfs -mkdir /GSOD_ALL- 查看文件夹是否建立
# hdfs dfs -ls /输出结果,如下所示:

- 将master节点(NameNode所在的节点)服务器上本地的ncdc文件夹里的气象数据文件上传到HDFS
# hdfs dfs -put /usr/local/data/ncdc/isd-lite/* /GSOD- 查看是否已经上传到HDFS
# hdfs dfs -ls /GSOD输出结果,如下所示:

- 可以通过如下命令查看文件块的分布情况
# hdfs fsck /GSOD -files -blocks -racks输出结果类似:
0. BP-1861083552-192.168.137.10-1420535325500:blk_1073742813_2006 len=88842240 repl=3 [/default-rack/192.168.137.13:50010, /default-rack/192.168.137.12:50010, /default-rack/192.168.137.11:50010]
... 略 ...
Status: HEALTHY
Total size: 92855723 B
Total dirs: 3
Total files: 2083
Total symlinks: 0
Total blocks (validated): 2083 (avg. block size 44577 B)
Minimally replicated blocks: 2083 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 2
Average block replication: 2.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 2
Number of racks: 1
FSCK ended at Mon Mar 13 15:38:44 CST 2023 in 53 milliseconds参数解释:
| 参数 |
详细信息 |
|---|---|
| status |
代表这次hdfs上block检测的结果 |
| Total size |
代表检测目录下文件总大小 |
| Total dirs |
代表检测的目录下总共有多少个目录 |
| Total files |
代表检测的目录下总共有多少文件 |
| Total symlinks |
代表检测的目录下有多少个符号连接 |
| Total blocks(validated) |
代表检测的目录下有多少个block块是有效的 |
| Minimally replicated blocks |
代表拷贝的最小block块数 |
| Over-replicated blocks |
指的是副本数大于指定副本数的block数量 |
| Under-replicated blocks |
指的是副本数小于指定副本数的block数量 |
| Mis-replicated blocks |
指丢失的block块数量 |
| Default replication factor |
1 指默认的副本数是1份(自身一份) |
| Missing replicas |
丢失的副本数 |
| Number of data-nodes |
有多少个节点 |
| Number of racks |
有多少个机架 |
2. Hadoop处理NCDC原始数据
在Hadoop集成环境中处理这些原理数据,气象站数以万计,整个数据集实际是一组经过gzip压缩的gz文件,每个年份的所有气象站的数据单独放在一个文件中,所以在本例中需要将每个年度的所有气象站数据(.gz文件)解压缩到以年份命名的文件夹中。上述操作可由一个MapReduce程序来完成,以充分利用其并行处理能力的优势。下面具体演示这个程序。
该程序只有一个map函数,无reduce函数,因为map函数可并行处理所有文件操作,无需整合步骤。这项处理任务能够用一个Unix脚本进行处理,因而在这里使用Hadoop面向MapReduce的Streaming接口比较合适。
1)新建generate_input_list.sh脚本,用于生成一个MapReduce的input文件,该文件包含要处理的文件夹列表
- 首先创建/home/shell目录作为shell脚本工作目录,然后通过cd命令切换到工作目录
# mkdir /home/shell
# cd /home/shell- 新建一个generate_input_list.sh来生成MapReduce的input文件,代码如下:
#!/bin/bash
a=$1
if [ -e "ncdc_files.txt" ]
then
rm ncdc_files.txt
hdfs dfs -rm /ncdc_file.txt
fi
while [ $a -le $2 ]
do
filename="/GSOD/${a}/"
echo -e "$filename" >> ncdc_files.txt
a=`expr $a + 1`
done
hdfs dfs -put ncdc_files.txt /- 给generate_input_list.sh添加执行能力,命令如下:
# chmod +x generate_input_list.sh- 生成在本例中包含需要处理的文件夹列表的ncdc_files.txt文件,命令如下:
注意:本次仅演示2021-2022年气象数据,参照下面的步骤可以自行处理其他年份的数据
# ./generate_input_list.sh 2021 2022- 查看ncdc_files.txt文件,命令如下:
# more ncdc_files.txt 输出结果,如下所示:
2)利用bash脚本处理原始的NCDC数据文件,并将其存储在HDFS中
创建load_ncdc_map.sh使其可以在MapReduce的Streaming上正常运行。在MapReduce中将读取ncdc_files.txt作为入参,读入的格式是NLineInputFormat。
- 在/home/shell目录下新建一个load_ncdc_map.sh文件,代码如下所示:
#!/bin/bash
read offset hdfs_file
echo -e "$offset\t$hdfs_file"
# RetrievefilefromHDFStolocaldisk
echo "reporter:status:Retrieving" $hdfs_file >&2
/home/hadoop/hadoop-2.9.2/bin/hdfs dfs -get $hdfs_file .
#Createlocaldirectory
target=`basename $hdfs_file`
#Unzipeachstationfileandconcatintoonefile
echo "reporter:status:Un-gzipping $target" >&2
for file in $target/*
do
gunzip $file
echo "reporter:status:Processed$file" >&2
done
#PutgzippedversionintoHDFS
echo "report:status:file $target and putting in HDFS" >&2
rm -rf $target/*.gz
/home/hadoop/hadoop-2.9.2/bin/hdfs dfs -put $target/ /GSOD_ALL/
rm -rf $target文件说明:
处理过程简单说来,首先将HDFS数据下载到本地目录
对每个年度中的气象数据(.gz文件)进行解压缩;
将解压好的文件重新上传到HDFS的/GSOD_ALL目录中;
状态消息输出到“标准错误”(以reporter:status为前缀),输出内容为MapReduce的状态更新,说明该Hadoop脚本正在运行并未挂起。
- 给load_ncdc_map.sh添加运行权限。
# chmod +x load_ncdc_map.sh- 通过如下命令查看结果是否正确。
# ll load_ncdc_map.sh输出结果,如下所示:

3)使用hadoop-streaming作业运行上面的bash脚本
- 运行Streaming作业的脚本结果如下:
# hadoop jar /home/hadoop/hadoop-2.9.2/share/hadoop/tools/lib/hadoop-streaming-2.9.2.jar \
-D mapreduce.job.reduces=0 \
-D mapreduce.map.speculative=false \
-D mapreduce.task.timeout=12000000 \
-inputformat org.apache.hadoop.mapred.lib.NLineInputFormat \
-input /ncdc_files.txt \
-output /output/1 \
-mapper /home/shell/load_ncdc_map.sh \
-file /home/shell/load_ncdc_map.sh这是一个“只有map”的作业,因为reduce任务数为0。 以上脚本还关闭了推测执行(speculative execution),因此重复的任务不会写相同的文件。任务超时参数被设置为一个比较大的值,使得Hadoop不会杀掉那些运行时间较长的任务(例如在解档文件、将文件复制到HDFS或者当进展状态未被报告时)。
- 作业提交后屏幕显示如下:

- 提示运行完毕后使用如下命令查看目标文件是否生成。
# hdfs dfs -ls /GSOD_ALL输出结果,如下所示:
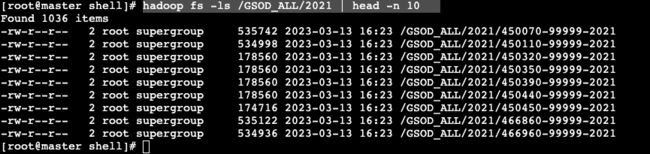
- 在每个文件夹下是解压后的数据文件(以2021年前10个文件为例进行展示)。
# hadoop fs -ls /GSOD_ALL/2021 | head -n 10
- 运行命令查看目录(可选步骤)。
# hadoop fs -ls /output/1
- 使用cat命令查看文件内容(可选步骤)。
# hadoop fs -cat /output/1/part-00000
# hadoop fs -cat /output/1/part-00001输出结果,如下所示:

在结果中,“12”表示输入行的offset,“/GSOD/2022/”是数据路径。
上一个任务下一个任务