clickhouse MergeTree 常用表引擎
文章目录
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- AggregatingMergeTree
- SummingMergeTree
- RelacingMergeTree
- Replication
- ReplicatedMergeTree
- 集成引擎
-
- kafka 表引擎
CollapsingMergeTree
官网
该引擎继承于 MergeTree,并在数据块合并算法中添加了折叠行的逻辑。
CollapsingMergeTree会异步的删除(折叠)这些除了特定列Sign有1和-1的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。更多的细节请看本文的折叠部分。因此,该引擎可以显著的降低存储量并提高
SELECT查询效率。引擎参数:
CollapsingMergeTree(sign)
sign— 类型列的名称:1是«状态»行,-1是«取消»行。- 列数据类型 —
Int8。
建表
CREATE TABLE dpaas_db_dev.CollapsingMergeTree_test
(
id Int64,
name String ,
name1 String ,
name2 String ,
sign Int8
) ENGINE = CollapsingMergeTree(sign)
ORDER BY id;
第一次插入数据
insert into dpaas_db_dev.CollapsingMergeTree_test values(1,'name','name1','name2',1);
第二次插入数据
insert into dpaas_db_dev.CollapsingMergeTree_test values(1,'name','name1','name2',-1),(1,'name','name11','name2',1);
手动合并
optimize table dpaas_db_dev.CollapsingMergeTree_test;
再次查询,只有最后一条记录
算法
以order by 作为主键(
order by指定的字段),当主键存在重复时,合并后会进行折叠当
sign为1时 表示是新增;当进行修改时,需要新增有一条修改前的数据,同时保证主键是相同的,且sign为-1,并新增修改后的数据sign为1
VersionedCollapsingMergeTree
官网
引擎继承自 MergeTree 并将折叠行的逻辑添加到合并数据部分的算法中。VersionedCollapsingMergeTree用于相同的目的 折叠树 但使用不同的折叠算法,允许以多个线程的任何顺序插入数据。 特别是,Version列有助于正确折叠行,即使它们以错误的顺序插入。 相比之下,CollapsingMergeTree只允许严格连续插入。引擎参数:
VersionedCollapsingMergeTree(sign, version)
sign— 指定行类型的列名:1是一个“状态”行,-1是一个“取消”行列数据类型应为
Int8。
version— 指定对象版本状态的列名。列数据类型应为
UInt*
建表
CREATE TABLE dpaas_db_dev.VersionedCollapsingMergeTree_test
(
id Int64,
name String ,
name1 String ,
name2 String ,
sign Int8,
version UInt32
) ENGINE = VersionedCollapsingMergeTree(sign,version)
ORDER BY id;
插入数据
insert into dpaas_db_dev.VersionedCollapsingMergeTree_test values(1,'name','name','name2',1,1);
insert into dpaas_db_dev.VersionedCollapsingMergeTree_test values(1,'name','name1','name2',-1,1),(1,'name','name11','name2',1,2);
查看数据
select * from dpaas_db_dev.VersionedCollapsingMergeTree_test;

手动合并
optimize table VersionedCollapsingMergeTree_test ;
再次查看数据 只剩下一条 version 为2 的数据

算法
当ClickHouse合并数据部分时,它会删除具有相同主键和版本但
Sign值不同的一对行. 行的顺序并不重要。当ClickHouse插入数据时,它会按主键对行进行排序。 如果
Version列不在主键中,ClickHouse将其隐式添加到主键作为最后一个字段并使用它进行排序。
AggregatingMergeTree
官网
聚合合并树,对某些要合并的字段进行聚合
该继承自MergeTree并更改了数据片段的逻辑。 ClickHouse ,将一个组数据片段内所有具有相同主(准确的说是键)的行替换成行,聚合函数的状态。
可以使用
AggregatingMergeTree表来做增量数据的聚合统计,包括物化视图的数据聚合。
创建底表明细表
drop table dpaas_db_dev.agg_gc_test;
CREATE TABLE dpaas_db_dev.agg_gc_test (
id UInt64 COMMENT 'id',
name String COMMENT '名称',
city String COMMENT '城市',
order_count Float64 COMMENT '订单数量',
salary Float64 COMMENT '薪水',
item_count Int64 COMMENT '采购数量',
ds Date default toDate(now()) COMMENT '时区'
) ENGINE = MergeTree()
PARTITION BY ds
ORDER BY (id,name);
创建聚合合并树引擎的物化视图:使用uniqState 或 sumState 或其它聚合函数*State
CREATE materialized view dpaas_db_dev.agg_gc_test_view
engine = AggregatingMergeTree()
PARTITION BY ds
ORDER BY (id,name)
as select
id,
name,
uniqState(city) as city,
sumState(order_count) as order_count,
sumState(salary) as salary,
sumState(item_count) as item_count,
ds
from
dpaas_db_dev.agg_gc_test
group by id,name,ds;
查看物化视图的建表语句 : 要聚合的字段已经被设置为聚合函数了
show CREATE table dpaas_db_dev.agg_gc_test_view ;
CREATE MATERIALIZED VIEW dpaas_db_dev.agg_gc_test_view
(
`id` UInt64,
`name` String,
`city` AggregateFunction(uniq, String),
`order_count` AggregateFunction(sum, Float64),
`salary` AggregateFunction(sum, Float64),
`item_count` AggregateFunction(sum, Int64),
`ds` Date
)
ENGINE = AggregatingMergeTree
PARTITION BY ds
ORDER BY (id, name)
SETTINGS index_granularity = 8192 AS
SELECT
id,
name,
uniqState(city) AS city,
sumState(order_count) AS order_count,
sumState(salary) AS salary,
sumState(item_count) AS item_count,
ds
FROM dpaas_db_dev.agg_gc_test
GROUP BY
id,
name,
ds;
对底表插入明细数据
INSERT INTO agg_gc_test (id, name,city, order_count, salary, item_count, ds) VALUES
(1, 'ZS','HN', 1, 22, 1, toDate(now())),
(2, 'LS','BJ', 2, 23, 2, toDate(now())),
(3, 'WW','SH', 3, 10, 0, toDate(now())),
(4, 'LL','NJ', 4, 35, 4, toDate(now()));
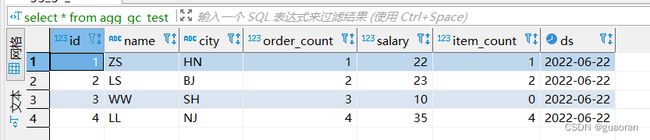
查看物化视图数据:展示的是二进制

通过聚合函数*Merge查看最终数据
select id,name,uniqMerge(city),sumMerge(order_count),sumMerge(salary),sumMerge(item_count),ds from agg_gc_test_view
group by id,name,ds;

对底表再次插入一遍数据后
INSERT INTO agg_gc_test
(id, name,city, order_count, salary, item_count, ds) VALUES
(1, 'ZS','HN', 1, 22, 1, toDate(now())),
(2, 'LS','BJ', 2, 23, 2, toDate(now())),
(3, 'WW','SH', 3, 10, 0, toDate(now())),
(4, 'LL','NJ', 4, 35, 4, toDate(now()));
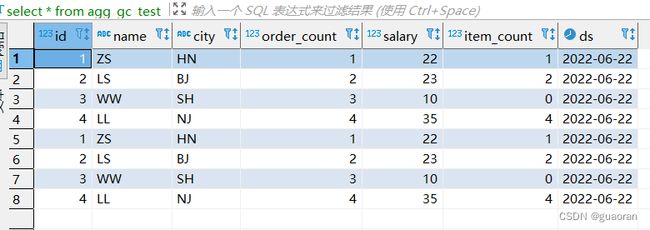
物化视图数据查看:可以看到数据已经执行了具体的聚合函数

算法
对要聚合字段进行聚合函数处理
SummingMergeTree
官网
该引擎继承自 MergeTree。区别在于,当合并
SummingMergeTree表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。我们推荐将该引擎和
MergeTree一起使用。例如,在准备做报告的时候,将完整的数据存储在MergeTree表中,并且使用SummingMergeTree来存储聚合数据。这种方法可以使你避免因为使用不正确的主键组合方式而丢失有价值的数据。引擎参数:
SummingMergeTree([columns])
columns- 包含了将要被汇总的列的列名的元组。可选参数。 所选的列必须是数值类型,并且不可位于主键中。如果没有指定
columns,ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
创建底表
drop table dpaas_db_dev.sum_gc_test;
CREATE TABLE dpaas_db_dev.sum_gc_test (
id UInt64 COMMENT 'id',
name String COMMENT '名称',
city String COMMENT '城市',
order_count Float64 COMMENT '订单数量',
salary Float64 COMMENT '薪水',
item_count Int64 COMMENT '采购数量',
ds Date default toDate(now()) COMMENT '时区'
) ENGINE = MergeTree()
PARTITION BY ds
ORDER BY (id,name);
创建求和合并树引擎物化视图
drop table dpaas_db_dev.sum_gc_test_view;
CREATE materialized view dpaas_db_dev.sum_gc_test_view
engine = SummingMergeTree()
PARTITION BY ds
ORDER BY (id,name)
as select * from dpaas_db_dev.sum_gc_test;
插入数据到底表
INSERT INTO sum_gc_test
(id, name,city, order_count, salary, item_count, ds) VALUES
(1, 'ZS','HN', 1, 22, 1, toDate(now())),
(2, 'LS','BJ', 2, 23, 2, toDate(now())),
(3, 'WW','SH', 3, 10, 0, toDate(now())),
(4, 'LL','NJ', 4, 35, 4, toDate(now()));
查询物化视图
select * from sum_gc_test_view;

再次插入数据到底表并查看物化视图

手动合并分区
optimize table dpaas_db_dev.sum_gc_test_view;
再次查询数据已经被合并
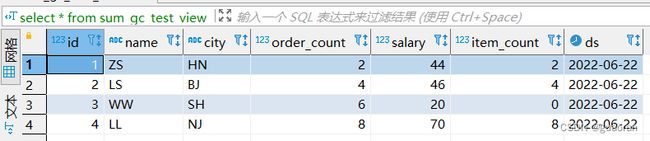
ClickHouse可能不会完整的汇总所有行,因此我们在查询中使用了聚合函数
sum和GROUP BY子句。
select id,name,ds,city,sum(order_count),sum(salary),sum(item_count) from sum_gc_test_view group by id,name,ds,city;
RelacingMergeTree
官网
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用
OPTIMIZE语句发起计划外的合并,但请不要依靠它,因为OPTIMIZE语句会引发对数据的大量读写。因此,
ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。引擎参数:
ReplacingMergeTree([ver])
ver— 版本列。类型为UInt*,Date或DateTime。可选参数。在数据合并的时候,
ReplacingMergeTree从所有具有相同排序键的行中选择一行留下:
- 如果
ver列未指定,保留最后一条。- 如果
ver列已指定,保留ver值最大的版本。具有去重功能,最终一致性。合并去重并不时实时的,解决方法:T+1的数据,可以先定时任务进行手动合并
创建底表
drop table dpaas_db_dev.rep_gc_test;
CREATE TABLE dpaas_db_dev.rep_gc_test (
id UInt64 COMMENT 'id',
name String COMMENT '名称',
city String COMMENT '城市',
order_count Float64 COMMENT '订单数量',
salary Float64 COMMENT '薪水',
item_count Int64 COMMENT '采购数量',
ds Date default toDate(now()) COMMENT '时区'
) ENGINE = ReplacingMergeTree()
PARTITION BY ds
ORDER BY (id,name);
插入数据
INSERT INTO rep_gc_test
(id, name,city, order_count, salary, item_count, ds) VALUES
(1, 'ZS','HN', 1, 22, 1, toDate(now())),
(2, 'LS','BJ', 2, 23, 2, toDate(now())),
(3, 'WW','SH', 3, 10, 0, toDate(now())),
(4, 'LL','NJ', 4, 35, 4, toDate(now()));

再次插入数据
INSERT INTO rep_gc_test
(id, name,city, order_count, salary, item_count, ds) VALUES
(1, 'ZS','HN', 100, 22, 1, toDate(now())),
(2, 'LS','BJ', 200, 23, 2, toDate(now()));

手动合并
optimize table dpaas_db_dev.rep_gc_test;

Replication
官网
副本表需要 Zookeeper 的支持
只有 MergeTree 系列里的表可支持副本:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。
在表引擎名称上加上
Replicated前缀。例如:ReplicatedMergeTree。Replicated*MergeTree 参数
zoo_path— ZooKeeper 中该表的路径。replica_name— ZooKeeper 中的该表的副本名称。
ReplicatedMergeTree
创建底表-副本合并树表-分片
CREATE TABLE dpaas_db.replicated_gc_test on cluster my_cluster
(
`pur_id` Int64 COMMENT '采购商id',
`pur_name` String COMMENT '采购商名称',
`sku_id` String COMMENT '商品编码',
`sku_name` String COMMENT '商品名称',
`pt` Date DEFAULT toDate(now()) COMMENT '分区'
)
ENGINE = ReplicatedMergeTree('/clickhouse/cluster_bigdata/tables/dpaas_db/{shard}/replicated_gc_test', '{replica}')
PARTITION BY pt
ORDER BY pur_id
SETTINGS index_granularity = 8192;
集成引擎
kafka 表引擎
官网
此引擎与 Apache Kafka 结合使用。
Kafka 特性:
- 发布或者订阅数据流。
- 容错存储机制。
- 处理流数据。
引擎参数:
Kafka SETTINGS
kafka_broker_list = ‘localhost:9092’,
kafka_topic_list = ‘topic1,topic2’,
kafka_group_name = ‘group1’,
kafka_format = ‘JSONEachRow’,
kafka_row_delimiter = ‘\n’,
kafka_schema = ‘’,
kafka_num_consumers = 2必要参数:
kafka_broker_list– 以逗号分隔的 brokers 列表 (localhost:9092)。kafka_topic_list– topic 列表 (my_topic)。kafka_group_name– Kafka 消费组名称 (group1)。如果不希望消息在集群中重复,请在每个分片中使用相同的组名。kafka_format– 消息体格式。使用与 SQL 部分的FORMAT函数相同表示方法,例如JSONEachRow。了解详细信息,请参考Formats部分。可选参数:
kafka_row_delimiter- 每个消息体(记录)之间的分隔符。kafka_schema– 如果解析格式需要一个 schema 时,此参数必填。例如,普罗托船长 需要 schema 文件路径以及根对象schema.capnp:Message的名字。kafka_num_consumers– 单个表的消费者数量。默认值是:1,如果一个消费者的吞吐量不足,则指定更多的消费者。消费者的总数不应该超过 topic 中分区的数量,因为每个分区只能分配一个消费者。
创建kafka topic
cd /opt/module/kafka_2.11-2.4.1/bin
# 创建topic
./kafka-topics.sh --create --zookeeper 172.26.20.124:2181 --replication-factor 3 --partitions 3 --topic test_kafka_for_ck
# 发送消息
./kafka-console-producer.sh --broker-list 172.26.20.124:9092 --topic test_kafka_for_ck
# 接收消息
./kafka-console-consumer.sh --bootstrap-server 172.26.20.124:9092 --topic test_kafka_for_ck --from-beginning
创建kafka引擎表
-- 创建引擎表
CREATE TABLE dpaas_db_dev.test_kafka_for_ck on cluster sunyur_cluster(
`message` String
)ENGINE = Kafka()
SETTINGS kafka_broker_list = '172.26.20.124:9092',
kafka_topic_list = 'test_kafka_for_ck',
kafka_group_name = 'clickhouse',
kafka_format = 'CSV',
kafka_row_delimiter= '\n',
kafka_num_consumers = 1;
创建一个MergeTree 表
因为kafka表引擎可以理解为是kafka的一个消费端,每次查询进行查询便是一个消费的过程,而且无法保留历史记录。
这里通过创建一个结构表和物化视图表存储历史记录。
当消息写入到kafka的topic时,ck的kafka引擎表会收到消息将消息通过物化视图存储到结构表中
-- 创建一个结构表
CREATE TABLE dpaas_db_dev.test_kafka_for_ck_daily on cluster sunyur_cluster(
message String
) ENGINE = MergeTree() order by message;
-- 创建物化视图,该视图会在后台转换引擎中的数据并将其放入之前创建的表中
CREATE MATERIALIZED VIEW consumer on cluster sunyur_cluster TO dpaas_db_dev.test_kafka_for_ck_daily
AS SELECT message FROM dpaas_db_dev.test_kafka_for_ck;
生成消息数据
-- 通过模拟数据,直接将数据写入到kafka引擎表中 或者通过kafka生产者发送消息
-- ck 写入到kafka 数据中
insert into dpaas_db_dev.test_kafka_for_ck_consumer2
with 'kafka-0-' as k
select concat(k,toString(number)) from numbers(10);
查看消息
select * from dpaas_db_dev.test_kafka_for_ck_daily;