Flink(十三)【Flink SQL(上)】
前言
最近在假期实训,但是实在水的不行,三天要学完SSM,实在一言难尽,浪费那时间干什么呢。SSM 之前学了一半,等后面忙完了,再去好好重学一遍,毕竟这玩意真是面试必会的东西。
今天开始学习 Flink 最后一部分 Flink SQL ,完了还有不少框架得学:Kafka、Flume、ClickHouse、Hudi、Azkaban、OOzie ... 有的算是小工具,不费劲,但是学完得复习啊,这么多东西,必须赶紧做个小项目练练手。
Flink SQL
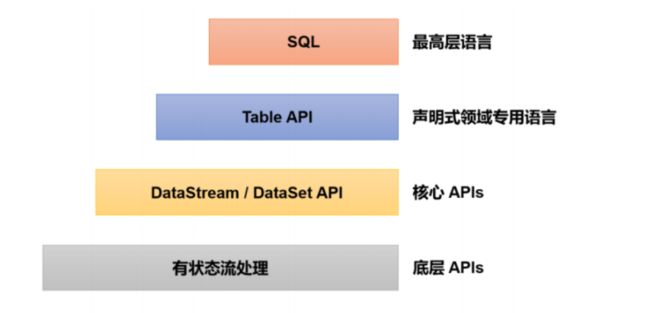
到现在我们学完了底层API(也就是 process)和核心 API(这里由于Flink现在已经流批一体,所以我们只学习 DataStream就好了),然后就是剩下的 Table API(类似于 Spark 中的 DataFrame 和 DataSet)和SQL(类似于Spark SQL)。显然最上层的都是高级 API ,它们的底层还是我们学的这些 DataStream 和 process 算子。不过毕竟是高级 API ,它对 SQL 语句都进行了优化,一般能用 SQL 肯定没人愿意用繁琐的代码去实现,大大降低了开发 Flink 程序的难度,但是一些 SQL 实现不了的东西当然还是得底层核心 API 来实现,就像 Spark 中的 RDD 编程一样。
1、sql-client 准备
为了方便练习演示 Flink SQL 语法,我们需要使用Flink 提供的 sql-client 进行操作。(类似于我们 Hive 中给的 hive 命令进入一个命令行模式就可以进行一些 hive sql 的操作)
1.1、基于 yarn-session 模式
1)启动 Flink
# 先启动 hadoop
myhadoop start
# 不需要启动 flink
/opt/module/flink-1.17.0/bin/yarn-session.sh -d
完了直接从 Yarn 的 Web UI 跳转到 Flink 的 Web UI
2)启动 sql-client
./sql-client.sh embedded -s yarn-session
1.2、常用配置
1)结果显示模式
#默认 table,还可以设置为 tableau、changelog
SET sql-client.execution.result-mode=changelog2)执行环境
SET execution.runtime-mode=streaming; #默认是 streaming,也可以设置为为 batch3)默认并行度
# 默认使用的是 flink 配置文件中的默认值
SET parallelism.default=14)设置状态TTL
SET table.exec.state.ttl=1000 #单位 ms5)通过 sql 文件初始化
我们在
1. 创建 sql 文件
vim sql-client-init.sql
create database mydatabases;2. 启动时,指定sql文件
./sql-client.sh embedded -s yarn-session -i sql-client-init.sql2、流处理中的表
| MySQL | Flink | |
|---|---|---|
| 处理的数据对象 | 字段元祖的有界集合 | 字段元祖的无限序列 |
| 查询对数据的访问 | 可以访问到完整的数据输入 | 无法访问所有数据,必须持续等待流式输入 |
| 查询终止条件 | 生成固定大小的结果集后终止 | 永不停止,根据持续收到的数据不断更新查询结果(停不下来) |
可以看到,关系型数据库 SQL 和我们 Flink SQL 的区别还是很大的。
2.1、动态表和持续查询
流处理面对的数据是连续不断的,未知的,这就导致流处理中的“表”和我们熟悉的传统关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义。
1)动态表(Dynamic Tables)
简答来说,就是来一条数据,插入一行数据,我们的表随着数据的增加也不断扩大,所以叫动态表。
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为“动态表”(Dynamic Tables)。
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是“静态表”;而动态表则完全不同,它里面的数据会随时间变化。
2)持续查询(Continuous Query)
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作“持续查询”(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
也就是说,对于 MySQL ,查询出来的数据是某一刻的数据,但是 Flink 的查询是停不下来的,它的查询结果是一直动态变化的,所以叫持续查询。
由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个“快照”(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了“持续查询”。

持续查询的步骤如下:
(1)流(stream)被转换为动态表(dynamic table);
(2)对动态表进行持续查询(continuous query),生成新的动态表;
(3)生成的动态表被转换成流。
这样,只要API将流和动态表的转换封装起来,我们就可以直接在数据流上执行SQL查询,用处理表的方式来做流处理了。
2.2、将流转换成动态表
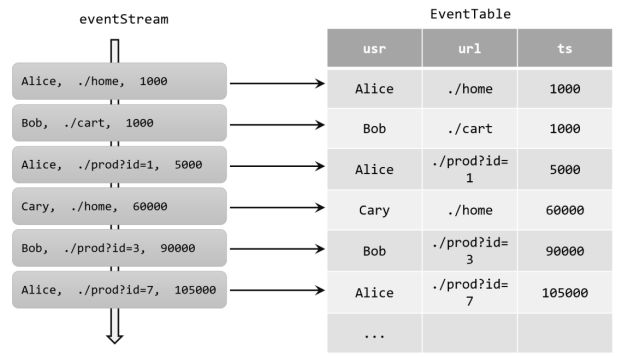
如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
例如,当用户点击事件到来时,就对应着动态表中的一次插入(Insert)操作,每条数据就是表中的一行;随着插入更多的点击事件,得到的动态表将不断增长。
2.3、用 SQL 持续查询
1)更新(Update)查询
我们在代码中定义了一个SQL查询。
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用 toChangelogStream() 方法。

我们新来数据按说是应该追加到后面的,但是这里的第三条数据 "Alice ./prod?id=1 5000"并没有追加到表的后面,而是把我们表的第一行也为 "Alice" 的那一行进行了修改,这就是更新流查询,它是通过回撤流实现的。
2)追加(Append)查询
上面的例子中,查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表EventTable一样,只有插入(Insert)操作了。
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");这样的持续查询,就被称为追加查询(Append Query),它定义的结果表的更新日志(changelog)流中只有INSERT操作。
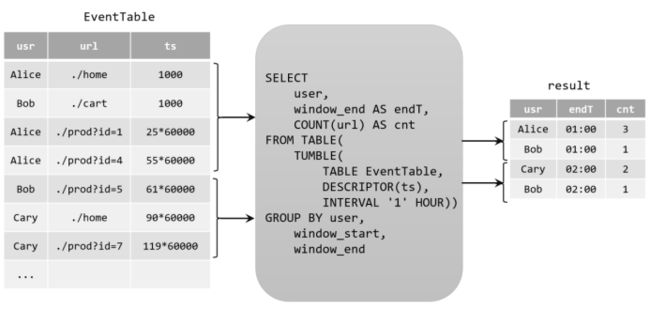
由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入INSERT操作,而没有更新UPDATE操作。所以这里的持续查询,依然是一个追加(Append)查询。结果表result如果转换成DataStream,可以直接调用toDataStream()方法。
2.4、将动态表转换成流
与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)和删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。在Flink中,Table API和SQL支持三种编码方式:
1. 仅追加(Append-only)流
仅通过插入(Insert)更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,其实就是动态表中新增的每一行。
2. 撤回(Retract)流
撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。
具体的编码规则是:INSERT插入操作编码为add消息;DELETE删除操作编码为retract消息;而UPDATE更新操作则编码为被更改行的retract消息,和更新后行(新行)的add消息(把旧的结果撤回,新的结果追加)。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。

3. 更新插入(Upsert)流
更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。
所谓的“upsert”其实是“update”和“insert”的合成词,所以对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息;而DELETE删除操作则被编码为delete消息。

可以看到,更新插入流比撤回流要精炼一点,直接一步到位。
需要注意的是,在代码里将动态表转换为DataStream时,只支持仅追加(append-only)和撤回(retract)流,我们调用toChangelogStream()得到的其实就是撤回流。而连接到外部系统时,则可以支持不同的编码方法,这取决于外部系统本身的特性,也就是说而,更新插入(upsert)是取决于外部系统支持的。
3、时间属性
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在Table API和SQL中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的DDL里直接定义为一个字段,也可以在DataStream转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。
时间属性的数据类型必须为TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。
按照时间语义的不同,可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。都是固定写法,记住就完事了。
3.1、 事件时间
事件时间属性可以在创建表DDL中定义,增加一个字段,通过WATERMARK语句来定义事件时间属性。具体定义方式如下:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
# WATERMARK FOR 时间字段 AS ts - 时间间隔(必须用单引号) 时间单位
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);这里我们把ts字段定义为事件时间属性,而且基于ts设置了5秒的水位线延迟。
时间戳类型必须是 TIMESTAMP 或者TIMESTAMP_LTZ 类型。但是时间戳一般都是秒或者是毫秒(BIGINT 类型),这种情况可以通过如下方式转换
ts BIGINT,
# 精确到miao后面3位,也就是ms
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),10.3.2 处理时间
在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
在创建表的DDL(CREATE TABLE语句)中,可以增加一个额外的字段,通过调用系统内置的PROCTIME()函数来指定当前的处理时间属性。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);4、DDL(Data Definition Language)数据定义
4.1、 数据库
1)创建数据库
(1)语法
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name
[COMMENT database_comment]
WITH (key1=val1, key2=val2, ...)2)查询数据库
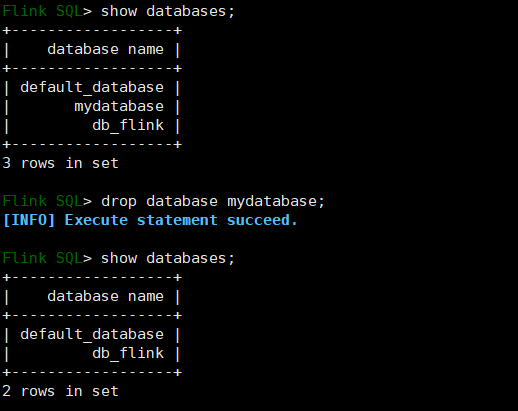
# 查询所有数据库
SHOW DATABASES;
# 查询当前数据库
SHOW CURRENT DATABASE;3)修改数据库
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...);4)删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]- RESTRICT:删除非空数据库会触发异常。默认启用
- CASCADE:删除非空数据库也会删除所有相关的表和函数。
5)切换当前数据库
USE database_name;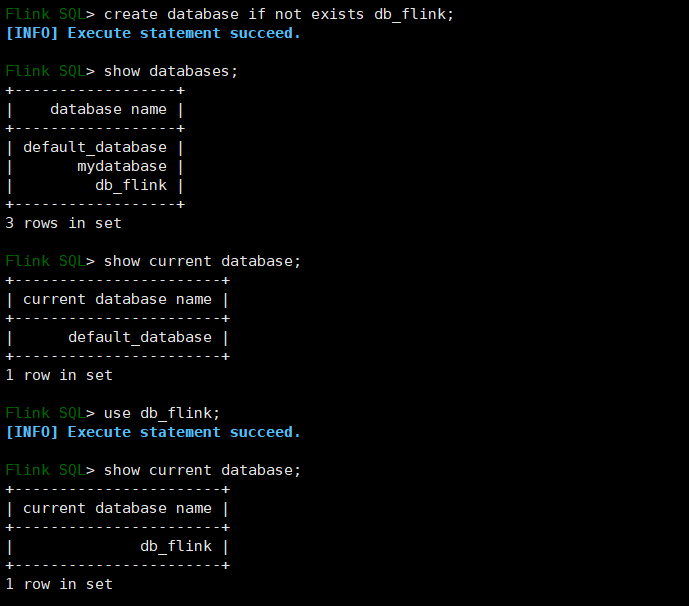
4.2、 表
1)创建表
(1)语法
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
-- 正常的列 以及 元数据(比如Kafka数据携带的时间戳...)
{ | | }[ , ...n]
-- 水印
[ ]
-- 表的限制,比如主键
[ ][ , ...n]
)
-- 给表添加注释
[COMMENT table_comment]
-- 像 hive 一样 partition by
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
-- with 里面指定这张表的一些属性和参数,比如连接器...
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( )] | AS select_query ] ① physical_column_definition
物理列是数据库中所说的常规列。其定义了物理介质中存储的数据中字段的名称、类型和顺序。其他类型的列可以在物理列之间声明,但不会影响最终的物理列的读取。
② metadata_column_definition
元数据列是 SQL 标准的扩展,允许访问数据源本身具有的一些元数据。元数据列由 METADATA 关键字标识。例如,我们可以使用元数据列从Kafka记录中读取和写入时间戳,用于基于时间的操作(这个时间戳不是数据中的某个时间戳字段,而是数据写入 Kafka 时,Kafka 引擎给这条数据打上的时间戳标记)。connector和format文档列出了每个组件可用的元数据字段。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
-- 把元数据赋值给 record_time 字段
`record_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka'
...
);如果自定义的列名称和 Connector 中定义 metadata 字段的名称一样, FROM xxx 子句可省略
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
`timestamp` TIMESTAMP_LTZ(3) METADATA
) WITH (
'connector' = 'kafka'
...
);如果自定义列的数据类型和 Connector 中定义的 metadata 字段的数据类型不一致,程序运行时会自动 cast强转,但是这要求两种数据类型是可以强转的。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
-- 将时间戳强转为 BIGINT
`timestamp` BIGINT METADATA
) WITH (
'connector' = 'kafka'
...
);默认情况下,Flink SQL planner 认为 metadata 列可以读取和写入。然而,在许多情况下,外部系统提供的只读元数据字段比可写字段多。因此,可以使用 VIRTUAL 关键字排除元数据列的持久化(表示只读)。
CREATE TABLE MyTable (
-- 可读可写
`timestamp` BIGINT METADATA,
-- 只读
`offset` BIGINT METADATA VIRTUAL,
`user_id` BIGINT,
`name` STRING,
) WITH (
'connector' = 'kafka'
...
);③ computed_column_definition
计算列是使用语法column_name AS computed_column_expression生成的虚拟列。
计算列就是拿已有的一些列经过一些自定义的运算生成的新列,在物理上并不存储在表中,只能读不能写。列的数据类型从给定的表达式自动派生,无需手动声明。
CREATE TABLE MyTable (
`user_id` BIGINT,
`price` DOUBLE,
`quantity` DOUBLE,
-- 把 price 列和 quanitity 列的值的乘积作为一个新列
`cost` AS price * quanitity
) WITH (
'connector' = 'kafka'
...
);④ 定义Watermark
Flink SQL 提供了几种 WATERMARK 生产策略:
- 严格升序:WATERMARK FOR rowtime_column AS rowtime_column。
Flink 任务认为时间戳只会越来越大,也不存在相等的情况,只要相等或者小于之前的,就认为是迟到的数据。
- 递增:WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '0.001' SECOND 。
一般基本不用这种方式。如果设置此类,则允许有相同的时间戳出现。
- 有界无序: WATERMARK FOR rowtime_column AS rowtime_column – INTERVAL 'string' timeUnit 。
此类策略就可以用于设置最大乱序时间,假如设置为 WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '5' SECOND ,则生成的是运行 5s 延迟的Watermark。一般都用这种 Watermark 生成策略,此类 Watermark 生成策略通常用于有数据乱序的场景中,而对应到实际的场景中,数据都是会存在乱序的,所以基本都使用此类策略。
⑤ PRIMARY KEY
主键约束表明表中的一列或一组列是唯一的,并且它们不包含NULL值。主键唯一地标识表中的一行,只支持 not enforced(这是语法规则,必须加上)。
CREATE TABLE MyTable (
`user_id` BIGINT,
`name` STRING,
PARYMARY KEY(user_id) not enforced
) WITH (
'connector' = 'kafka'
...
);⑥ PARTITIONED BY
创建分区表
⑦ with语句
用于创建表的表属性,用于指定外部存储系统的元数据信息。配置属性时,表达式key1=val1的键和值都应该是字符串字面值。如下是Kafka的映射表:
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`name` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)一般 with 中的配置项由 Flink SQL 的 Connector(链接外部存储的连接器) 来定义,每种 Connector 提供的with 配置项都是不同的。
⑧ LIKE
用于基于现有表的定义创建表。此外,用户可以扩展原始表或排除表的某些部分。
可以使用该子句重用(可能还会覆盖)某些连接器属性,或者向外部定义的表添加水印。
CREATE TABLE Orders (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'earliest-offset'
);CREATE TABLE Orders_with_watermark (
-- Add watermark definition
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
-- Overwrite the startup-mode
'scan.startup.mode' = 'latest-offset'
)
LIKE Orders;⑨ AS select_statement(CTAS)
在一个create-table-as-select (CTAS)语句中,还可以通过查询的结果创建和填充表。CTAS是使用单个命令创建数据并向表中插入数据的最简单、最快速的方法。
CREATE TABLE my_ctas_table
WITH (
'connector' = 'kafka',
...
)
AS SELECT id, name, age FROM source_table WHERE mod(id, 10) = 0;注意:CTAS有以下限制:
- 暂不支持创建临时表。
- 目前还不支持指定显式列(create table 后面不能自己写列字段)。
- 还不支持指定显式水印(不能自己添加水印)。
- 目前还不支持创建分区表。
- 目前还不支持指定主键约束。
(2)简单建表示例
创建一个 test 表,指定连接器为 print :

用 like 关键字创建一个结构和 test 表一样的表 test1 并在它的基础上增加一个字段 value:
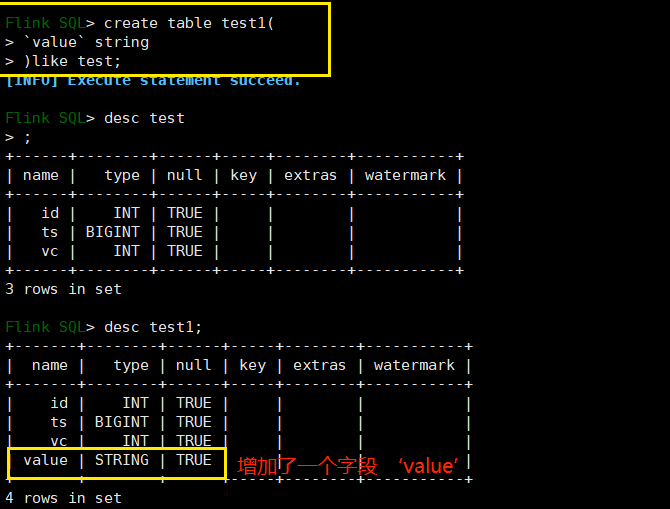
使用查询结果来新建一个表:
 我们可以看到,我们表 test 的查询结果只能被当做一个 Sink 来使用(也就是只能被插入),不能被当做输入源。
我们可以看到,我们表 test 的查询结果只能被当做一个 Sink 来使用(也就是只能被插入),不能被当做输入源。
2)查看表
(1)查看所有表
SHOW TABLES [ ( FROM | IN ) [catalog_name.]database_name ] [ [NOT] LIKE ] 如果没有指定数据库,则从当前数据库返回表。
LIKE子句中sql pattern的语法与MySQL方言的语法相同:
- %匹配任意数量的字符,甚至零字符,\%匹配一个'%'字符。
- _只匹配一个字符,\_只匹配一个'_'字符
(2)查看表信息
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name3)修改表
(1)修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name (2)修改表属性
(2)修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)表的属性,比如连接器等。
4)删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name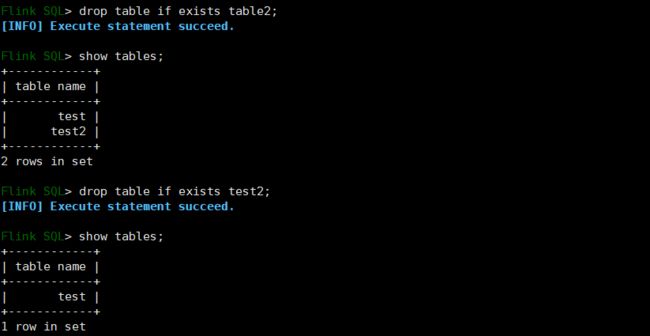
5、 查询
5.1、 DataGen & Print
1)创建数据生成器源表
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
-- flink 自带的数据生成器
'connector' = 'datagen',
-- 每s生成的数据条数
'rows-per-second'='1',
-- 生成类型 sequence代表自增序列,需要指定起始值和结束值
'fields.id.kind'='sequence',
-- id字段自增起始值
'fields.id.start'='1',
-- id字段自增结束值
'fields.id.end'='10000',
-- ts字段的生成类型
'fields.ts.kind'='sequence',
'fields.ts.start'='1',
'fields.ts.end'='1000000',
-- vc字段类型 随机值
'fields.vc.kind'='random',
-- 最小值 1
'fields.vc.min'='1',
-- 最大值 100
'fields.vc.max'='100'
);
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
connector' = 'print'
);

2)查询源表
查询数据:select * from source;
注意:如果发现刷新不动,就退出去查看一下log4j输出了什么警告,有的警告可以忽略,但是有的可能就是原因。比如我是因为没有在环境变量中添加 HADOOP_CONF_DIR ,导致我的数据生成器不生成数据。
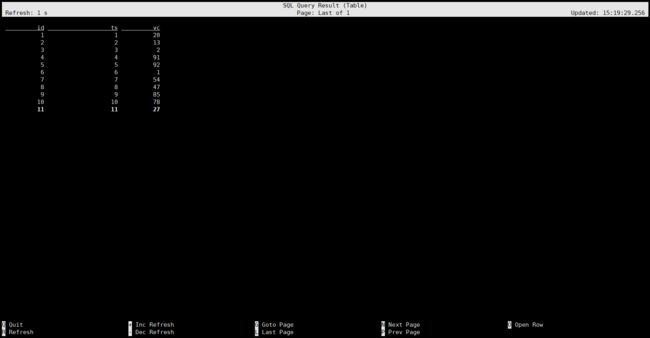
我们可以看到结果显示模式是 table 模式,这是默认的显示模式,我们在前面的常用配置里讲过,还有一种 changelog 模式可以设置。

我们再次查询:

我们可以看到,这种模式下,它的显示比 table 模式多了一列 op ,代表操作,+I 代表新增数据,撤回就是 -U。
此外还有一种模式叫做 tableau:

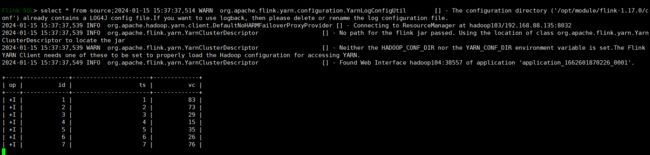
可以看到,这种模式喜爱,我们不会进入那个专门的数据展示界面,更加方便。
select * from source;
3)插入sink表并查询
创建 Sink表:
我们试着把 source 中的数据输出到 sink:
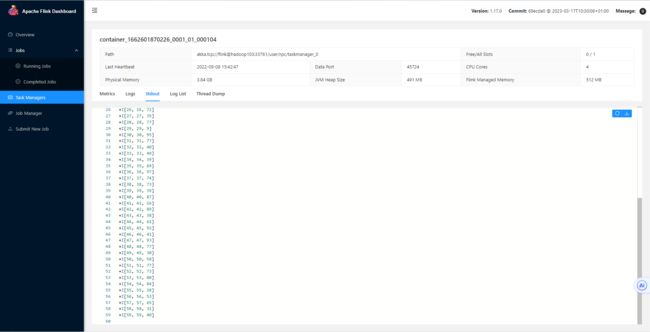
insert into sink select * from source;
可以看到它给我们返回了 一个 Job Id,我们可以直接查询 sink 表,或者也可以在 Web UI 中查看:
select * from sink;或者
5.2、With子句
WITH提供了一种编写辅助语句的方法,以便在较大的查询中使用。这些语句通常被称为公共表表达式(Common Table Expression, CTE),可以认为它们定义了仅为一个查询而存在的临时视图。
1)语法
WITH [ , ... ]
SELECT ... FROM ...;
:
with_item_name (column_name[, ...n]) AS ( ) 2)案例
我们查询这个临时表就相当于执行了 with 内部的查询,比如下面:
WITH source_with_total AS (
SELECT id, vc+10 AS total
FROM source
)
-- 注意这里没有分号 这两个句子是一个作业里面的
SELECT id, SUM(total) FROM source_with_total GROUP BY id;我们查询 source_with_total 就相当于查询了它内部的语句:select id,vc+10 as total from source;当然,我们在查这张临时表的时候可以选择字段。
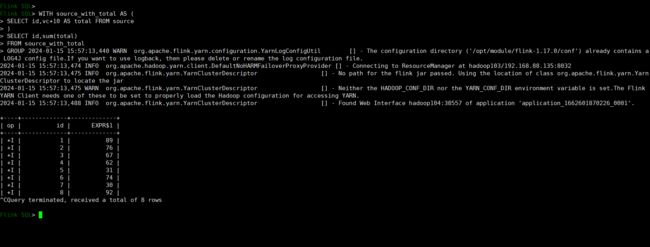
需要注意的地方就是我们生成临时表的句子和查询临时表的句子是一个语句没有分号的,它们同属于一个作业,这个临时表只在这里生效,就像帮我们的查询语句简化了一下,作业结束它也就不存在了。我们完全可以写成这样:
select id,vc+10 as total from source;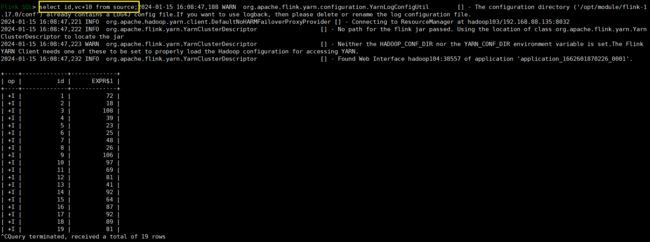
5.3、SELECT & WHERE 子句
1)语法
SELECT select_list FROM table_expression [ WHERE boolean_expression ]2)案例
-- 自定义 Source 的数据
-- 不需要给表 t 的字段显示添加类型(添加会报错) flink会自动识别
SELECT id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price);
SELECT vc + 10 FROM source WHERE id >10;

通过查询结果,我们可以知道id=10的这条数据它的 vc 是<=10 的。
5.4、SELECT DISTINCT 子句
用作根据 key 进行数据去重
SELECT DISTINCT vc FROM source;对于流查询,计算查询结果所需的状态可能无限增长。状态大小取决于不同行数。可以设置适当的状态生存时间(TTL)的查询配置,以防止状态过大。但是,这可能会影响查询结果的正确性。如某个 key 的数据过期从状态中删除了,那么下次再来这么一个 key,由于在状态中找不到,就又会输出一遍。
5.5、分组聚合
SQL中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于“多对一”的转换。比如我们可以通过下面的代码计算输入数据的个数:
select COUNT(*) from source;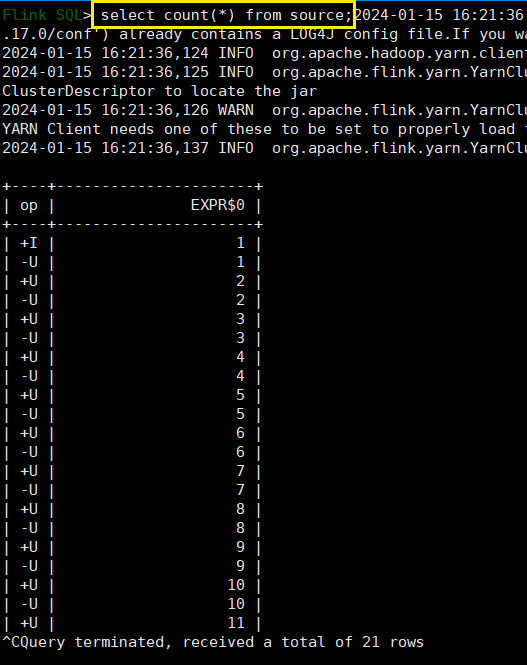
我们之前说过,动态表转为流,对于持续查询来说是一种更新查询,这里很明显是追加流和撤回流,而不是更新插入流。
而更多的情况下,我们可以通过GROUP BY子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计。
SELECT vc, COUNT(*) as cnt FROM source GROUP BY vc;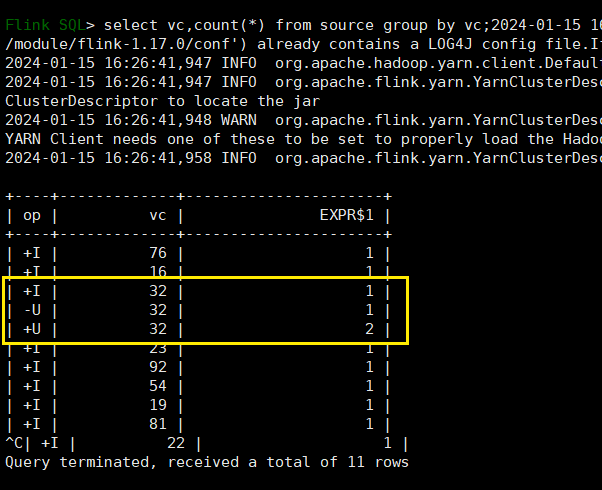
这种聚合方式,就叫作“分组聚合”(group aggregation)。想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成DataStream打印输出,需要调用toChangelogStream()。
分组聚合既是SQL原生的聚合查询,也是流处理中的聚合操作,这是实际应用中最常见的聚合方式。当然,使用的聚合函数一般都是系统内置的,如果希望实现特殊需求也可以进行自定义。
1)group聚合案例
CREATE TABLE source1 (
dim STRING,
user_id BIGINT,
price BIGINT,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
-- 指定了水位线为 row_time 字段 - 5s
WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.dim.length' = '1',
'fields.user_id.min' = '1',
'fields.user_id.max' = '100000',
'fields.price.min' = '1',
'fields.price.max' = '100000'
);
CREATE TABLE sink1 (
dim STRING,
pv BIGINT,
sum_price BIGINT,
max_price BIGINT,
min_price BIGINT,
uv BIGINT,
window_start bigint
) WITH (
'connector' = 'print'
);
insert into sink1
select dim,
count(*) as pv,
sum(price) as sum_price,
max(price) as max_price,
min(price) as min_price,
-- 计算 uv 数
count(distinct user_id) as uv,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint) as window_start
from source1
group by
dim,
-- UNIX_TIMESTAMP得到秒的时间戳,将秒级别时间戳 / 60 转化为 1min,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint);这里可以看到,我们在自动生成数据的时候,并没有指定字段的生成类型(比如是自增序列还是随机数或者字符串) ,因为只要我们指定了 max 和 min 那么这就是一个随机数;如果我们指定了 start 和 end,那么就代表这是自增序列;如果指定了 length ,就代表这是一个字符串。
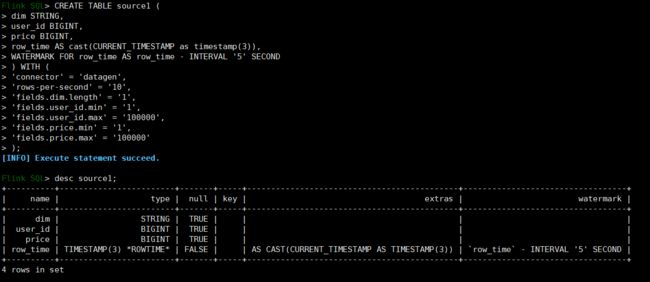
这里我们也可以不用 insert into 到 sink,而是直接查询,效果是一样的
Flink SQL> select dim,
> count(*) as pv,
> sum(price) as sum_price,
> max(price) as max_price,
> min(price) as min_price,
> -- 计算 uv 数
> count(distinct user_id) as uv,
> cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint) as window_start
> from source1
> group by
> dim,
> -- UNIX_TIMESTAMP得到秒的时间戳,将秒级别时间戳 / 60 转化为 1min,
> cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint);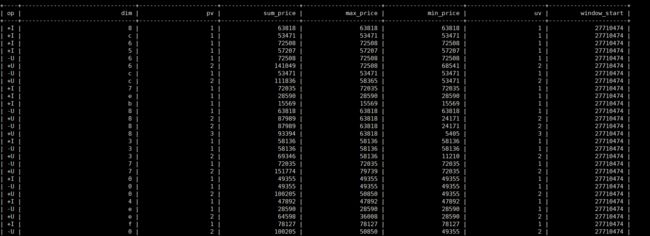
2)多维分析
多维分析,举个例子比如我们要统计关于学生成绩的信息(最高分、最低分、平均分),我们可以从不同维度(年级、学科、性别)去统计,比如每个年级的最高分、最低分、平均分;或者不同性别的最高分... 不同年级不同学科的最高分... 或者不同年级、不同学科、不同性别的最高分...。
Group 聚合也支持 Grouping sets 、Rollup 、Cube,如下案例是Grouping sets:
SELECT
supplier_id
, rating
, product_id
, COUNT(*)
FROM (
VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
)
-- 供应商id、产品id、评级
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS(
(supplier_id, product_id, rating),
(supplier_id, product_id),
(supplier_id, rating),
(supplier_id),
(product_id, rating),
(product_id),
(rating),
()
);这段 Flink SQL 代码的主要目的是对一组产品数据进行分组聚合。
VALUES 语句:
VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
)这部分定义了一个包含四行数据的虚拟表。每一行代表一个产品的供应商ID、产品ID和评级。
2. AS Products(supplier_id, product_id, rating):
AS Products(supplier_id, product_id, rating)这部分将虚拟表重命名为 "Products",并为每一列定义了别名:supplier_id、product_id 和 rating。
3. GROUP BY GROUPING SETS:
GROUPING SETS 是 SQL 中的一种功能,它允许你指定多个分组条件,并为每个分组条件返回一个结果。这在探索多个维度聚合时非常有用。
在这个例子中,我们可以看到以下分组条件:
- supplier_id、product_id、rating
- supplier_id、product_id
- supplier_id、rating
- supplier_id
- product_id、rating
- product_id
- rating
- ()(空分组)
这意味着,对于每个供应商ID、产品ID和评级的组合,都会进行计数。这实际上是计算每个供应商的每个产品以及每个产品的总评级的计数。同时,也计算了每个供应商的总评级、每个产品的总评级以及所有产品的总评级。最后,还计算了所有记录的总数(这是通过空分组实现的)。
SELECT 语句:
这个部分选择了上述 GROUPING SETS 中的所有列,并添加了一个 COUNT(*) 函数来计算每个分组的记录数。
所以,这段代码的输出将为给定的数据集提供以下聚合信息:
- 每个供应商的每个产品的数量以及评级;
- 每个供应商的每个产品的数量;
- 每个供应商的评级数量;
- 每个产品的评级数量;
- 每个供应商的数量;
- 每个产品的数量;
- 评级的数量;
- 所有记录的数量。

剩下的明天补齐