操作系统MIT6.S081:Lab1->Unix utilities
本系列文章为MIT6.S081的学习笔记,包含了参考手册、课程、实验三部分的内容,前面的系列文章链接如下
操作系统MIT6.S081:[xv6参考手册第1章]->操作系统接口
操作系统MIT6.S081:P1->Introduction and examples
文章目录
- 一、sleep
-
- 1.1 实验描述
- 1.2 实验思路
- 1.3 实验代码
- 二、pingpong
-
- 2.1 实验描述
- 2.2 实验思路
- 2.3 实验代码
- 三、primes
-
- 3.1 实验描述
- 3.2 实验思路
- 3.3 实验代码
- 四、find
-
- 4.1 实验描述
- 4.2 实验思路
- 4.3 实验代码
- 五、xargs
-
- 5.1 实验描述
- 5.2 实验思路
- 5.3 实验代码
一、sleep
1.1 实验描述
实验目的
为xv6系统实现UNIX的sleep程序。你的sleep程序应该使当前进程暂停指定的时钟周期数,时钟周期数由用户指定。例如执行sleep 100,则当前进程暂停,等待100个时钟周期后才继续执行。时钟周期是xv6内核定义的时间概念,来自计时器芯片的两次中断之间的时间。你的解决方案包含应该在文件user/sleep.c中。
实验提示
1、在开始编程之前,阅读配套手册的第一章。
2、可以参考/user目录下的其他程序(如echo.c、grep.c和rm.c),了解如何获取和传递给程序相应的命令行参数.
3、如果用户传入参数有误,即没有传入参数或者传入多个参数,程序应该能打印出错误信息。
4、通过字符串传递命令行参数。可以通过atoi(详情见user/ulib.c)函数将字符串转换为整数
5、使用系统调用sleep。
6、有关实现sleep系统调用的xv6内核代码(sys_sleep),请参考kernel/sysproc.c。有关可从用户程序调用sleep的C 定义在user/user.h中,以及有关汇编代码的user/usys.S 从用户代码跳转到内核进行睡眠。
7、确保main函数调用exit()以退出程序。
4、实现的程序应该命名为sleep.c并最后放入user目录下。
8、将你的sleep程序添加到Makefile的UPROGS中。只有这步完成后,make qemu才能编译你写的程序,你才能在shell中运行这个程序。
9、通过Kernighan和Ritchie’s的The C programming language(第2版)学习C语言
测试条件
①在xv6的shell中运行该程序
②如果通过上述命令使程序停止10个时钟周期,则说明你的方案是正确的。运行make grade查看你是否通过了测试。
注:make grade会运行所有测试程序,如果你只想测试当前程序,可以指定要运行的程序,通过以下命令:
你也可以通过下面这条命令测试当前程序

1.2 实验思路
头文件
系统调用sleep的声明在user/user.h中。
user.h中的一些系统调用函数声明使用了一些数据类型,这些数据类型在kerner/type.h中声明。


命令行参数判断
如果命令行参数有错误,则通过write或fprintf输出错误信息
然后通过exit退出
执行sleep操作
①通过atoi将argv[1]参数转换为整数
②调用系统调用函数sleep执行中断操作
③通过exit退出
1.3 实验代码
整体代码如下
#include "kernel/types.h" //一些数据类型声明
#include "user/user.h" //用户可以使用的系统调用声明
int main(int argc, char* argv[])
{
if (argc != 2){ //命令行参数不为2
//也可以调用write
fprintf(2, "Usage: sleep \n" ); //将提示信息写入标准错误端
exit(1); //退出,参数1表示非正常退出
}
int number = atoi(argv[1]); //将字符串转为整数
sleep(number); //调用系统调用sleep
exit(0); //正常退出
}
测试
①首先在makefile文件中添加
$U/_sleep\
②然后sudo make qemu进入xv6
③在终端中测试sleep
④退出xv6,在shell中通过./grade-lab-util sleep测试
注: 如果运行命令./grade-lab-util sleep报/usr/bin/env: ‘python’: No such file or directory错误,可能是因为没装python2或者装的是python3,使用命令vim grade-lab-util,把第一行的python改为python3。如果系统没装python3,则通过命令sudo apt-get install python3安装python3。



二、pingpong
2.1 实验描述
实验目的
使用UNIX系统调用编写一个程序pingpong,在一对管道上实现两个进程之间的通信。父进程通过第一个管道给子进程发送一个信息“ping”,子进程接收父进程的信息后打印
",其中pid是子进程的ID。然后子进程通过另一个管道发送一个信息“pong”给父进程,父进程接收子进程的信息然后打印: received ping" ",其中pid是父进程的ID,然后退出。: received pong"
实验提示
1、通过
pipe创建一个管道
2、通过fork创建一个子进程
3、通过read从管道中读取数据,通过write向管道中写入数据
4、通过getpid获取当前进程的pid
5、将程序添加到Makefile文件中的UPROGS中
6、xv6上的用户程序拥有一些库函数可供使用,你可以在user/user.h中查看这些函数对应的列表。除系统调用外其他函数的源代码位于user/ulib.c、user/printf.c和user/umalloc.c中。
测试条件
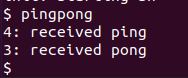
在shell中运行程序并将得到以下结果
如果你的程序在两个进程间传递信息并产生以上结果,则说明你的方案正确。

2.2 实验思路
初始化
创建父进程、子进程的文件描述符数组
父进程、子进程创建管道
创建缓冲区字符数组buf,存放要传递的信息
通过fork创建子进程
父进程
①关闭父进程管道的读取端
②将"ping"通过父进程管道的写入端进行写入
③关闭子进程管道的写入端
④从子进程管道的读取端读取信息到buf中
⑤打印收到的信息
子进程
①关闭父进程管道的写入端
②子进程从父进程管道的读取端读取数据
③打印收到的信息
④关闭子进程管道的读取端
⑤将子进程管道的写入端信息写入buf中
2.3 实验代码
整体代码如下
#include "kernel/types.h"
#include "user/user.h"
int main()
{
int pfd[2]; //父进程的文件描述符数组
int cfd[2]; //子进程的文件描述符数组
pipe(pfd); //父进程创建管道
pipe(cfd); //子进程创建管道
char buf[10]; //缓冲区字符数组,存放传递的信息
int pid = fork(); //创建子进程
if(pid < 0){
fprintf(0, "fork error\n");
exit(1); //创建子进程错误
}
else if(pid == 0){ //子进程
close(pfd[1]); //关闭父进程管道的写入端
read(pfd[0], buf, 4); //将父进程管道的读取端数据读取到buf中
printf("%d: received %s\n", getpid(), buf); //打印收到的信息
close(cfd[0]); //关闭子进程管道的读取端
write(cfd[1],"pong", 4); //将"pong"写入子进程管道的写入端
}else{ //父进程
close(pfd[0]); //关闭父进程管道的读取端
write(pfd[1], "ping", 4); //将"ping"写入父进程管道的写入端
close(cfd[1]); //关闭子进程管道的写入端
read(cfd[0], buf, 4); //将子进程管道的读取端信息读取到buf中
printf("%d: received %s\n", getpid(), buf); //打印收到的信息
}
exit(0); //正常退出
return 0;
}
测试
①首先在makefile文件中添加
$U/_pingpong\
②然后sudo make qemu进入xv6
③在终端中测试pingpong
④执行./grade-lab-util pingpong

三、primes
3.1 实验描述
实验目的
使用管道实现一个能够并发执行的筛选器。这个想法归功于Unix管道的发明者Doug McIlroy。链接中间的图片和周围的文字解释了实现的细节。你的解决方案应该放在user/primes.c文件中。你的目标是使用pipe和fork创建管道。第一个进程将数字2到35送入管道中。对于每个质数,你需要创建一个进程,通过一个管道从其左邻读取,并在另一个管道上写给右邻。由于xv6的文件描述符和进程数量有限,第一个进程可以停止在35。
实验提示
1、注意关闭进程不需要的文件描述符,否则程序将在第一个进程到达35之前耗尽xv6资源。
2、一旦第一个进程到达35,它应该等到整个管道终止,包括所有的子进程、孙子进程等。因此,主进程只有在打印完所有输出后才能退出,即所有其他进程已退出后主进程才能退出。
3、当管道的写入端关闭时,read函数返回0。
4、最简单的方式是直接将32位(4 字节)的整型写到管道中,而不是使用格式化的 ASCII I/O 。
5、你应该根据需要创建进程。
6、将程序添加到Makefile中的UPROGS中
测试条件
如果它实现基于管道的筛子并产生以下输出,则您的解决方案是正确的

3.2 实验思路
Unix筛选器
链接中的筛选器结构如下图所示:
具体流程为:
①主进程中创建一个管道,将2-11输入到管道中。
②创建一个子进程,读取管道的第1个数2并打印。创建一个新管道,将2的倍数全部筛除,剩下的(3、5、7、9、11)输入新管道中。
②创建一个子子进程,读取管道的第1个数3并打印。创建一个新管道,将3的倍数全部筛除,剩下的(5、7、11)输入新管道中。
③创建一个子子子进程,读取管道的第1个数5并打印。创建一个新管道,将5的倍数全部筛除,剩下的(7、11)输入新管道中。
④创建一个子子子子进程,读取管道的第1个数7并打印。创建一个新管道,将7的倍数全部筛除,剩下的(11)输入管道中。
④创建一个子子子子子进程,读取管道的第1个数7并打印。

实验流程
实验流程与上述流程类似,每创建一个进程就递归筛选一次,直到所有的数都被筛选完。需要注意的是每个进程中需要关闭不需要的文件描述符。
3.3 实验代码
实验整体代码如下
#include "kernel/types.h"
#include "user/user.h"
#define N 35
void solve(int* pl){
int prime;
//读取一个质数,如果没有数据了则直接返回
if(read(pl[0], &prime, sizeof(prime)) == 0) return;
printf("prime %d\n", prime); //打印输出
int pr[2];
pipe(pr); //right管道
int pid = fork();
if(pid > 0){ //父进程
close(pr[0]); //关闭right管道读取端
//将当前质数的倍数筛出去,剩下的写入right管道写入端
for(int t; read(pl[0], &t, sizeof(t)) != 0;){
if(t % prime != 0)
write(pr[1], &t, sizeof(t));
}
close(pr[1]); //关闭right管道写入端
close(pl[0]); //关闭left管道读取端
wait(0); //等待子进程完成
exit(0); //正确退出
}else if(pid == 0){
close(pr[1]); //关闭right管道写入端
close(pl[0]); //关闭left管道写入端
solve(pr); //递归处理右邻
close(pr[0]); //关闭right管道读取端
exit(0); //正确退出
}
else{ //创建进程失败
close(pl[0]);
close(pr[1]);
close(pr[0]);
exit(1); //错误退出
}
}
int main(int argc, char argv[]){
int pl[2]; //lefts
pipe(pl); //创建left管道
int pid = fork();
if(pid > 0){ //主进程
close(pl[0]); //关闭left管道读取端
for(int i =2 ; i <= N; ++i){ //将2-35写入left管道写入端
write(pl[1], &i, sizeof(i));
}
close(pl[1]); //关闭left管道写入端
wait(0); //等待子进程完成
exit(0); //成功退出
}else if(pid == 0){ //子进程
close(pl[1]); //关闭left管道写入端
solve(pl); //进行筛选
close(pl[0]); //关闭left管道读取端
exit(0); //正确退出
}else{ //创建进程错误
close(pl[1]);
close(pl[0]);
exit(1);
}
}
测试
①首先在makefile文件中添加
$U/_primes\
②然后sudo make qemu进入xv6
③在终端中测试primes
④执行./grade-lab-util primes


四、find
4.1 实验描述
实验目的
编写一个简单的UNIX find程序:在目录树中查找包含特定名称的所有文件。你的解决方案应放在user/find.c中。
实验提示
①参考
user/ls.c了解如何读取目录。
②使用递归查找子目录下的文件。
③不要递归"." 和"…" 。
④文件系统的变化在qemu的运行过程中持续存在。使用make clean然后再make qemu让一个干净的文件系统运行。
⑤你需要使用C字符串。可以参考K&R的C语言书籍第 5.5 节。
⑥请注意,比较字符串不能像在Python中使用==一样。请使用strcmp()函数。
⑦将程序添加到Makefile的UPROGS中。
测试条件
如果你的文件系统包含文件b和a/b,则输出以下结果代表你的方案是正确的

4.2 实验思路
首先阅读ls.c的代码
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
char*
fmtname(char *path) //将路径转换为文件名,即将中间的/去掉
{
static char buf[DIRSIZ+1];
char *p;
// Find first character after last slash.
//从后往前,查找最后一个斜杠之后的第一个字符,也就是文件名的首字母
for(p=path+strlen(path); p >= path && *p != '/'; p--)
;
p++;
// Return blank-padded name.
//返回空白填充的名称
//如果文件名的长度大于DIRSIZ,则直接返回p。p的长度小于DIRSIZ,则在p的文件名后面补齐空格
if(strlen(p) >= DIRSIZ)
return p;
memmove(buf, p, strlen(p));//从存储区p复制stelen(p)个字节到存储区buf
memset(buf+strlen(p), ' ', DIRSIZ-strlen(p)); //将' '填充到p后面
return buf;
}
void
ls(char *path)
{
char buf[512], *p; //保存文件名的缓冲数组
int fd; //文件描述符
struct dirent de; //目录相关的结构体
struct stat st; //文件相关的结构体,包含文件的状态信息
if((fd = open(path, 0)) < 0){ //路径打开失败
fprintf(2, "ls: cannot open %s\n", path);
return;
}
if(fstat(fd, &st) < 0){ //将文件状态保存到st中
fprintf(2, "ls: cannot stat %s\n", path);
close(fd);
return;
}
switch(st.type){ //文件类型
case T_FILE: //文件,就打印文件名、类型、inode号、大小
printf("%s %d %d %l\n", fmtname(path), st.type, st.ino, st.size);
break;
case T_DIR: //路径
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("ls: path too long\n");
break;
}
strcpy(buf, path); //将路径放入buf中
p = buf+strlen(buf); //指针移动到buf最后一个字符后面
*p++ = '/'; //添加上 /
读取 fd ,如果 read 返回字节数与 de 长度相等则循环
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if(de.inum == 0)
continue;
//把 文件名信息复制 p
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0; //设置文件名结束符
if(stat(buf, &st) < 0){
printf("ls: cannot stat %s\n", buf);
continue;
}
printf("%s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size);
}
break;
}
close(fd);
}
int
main(int argc, char *argv[])
{
int i;
if(argc < 2){
ls(".");
exit(0);
}
for(i=1; i<argc; i++)
ls(argv[i]);
exit(0);
}
思路
ls操作是列出指定路径下的所有文件和目录。find则是列出指定路径下的指定文件。所以find可以参考ls的实现,需要添加的内容为:
①对比当前路径下的文件是否为指定的文件
②如果有文件夹要继续进行递归
③不要递归.和..
4.3 实验代码
实验整体代码如下
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
char* fmtname(char *path) //参考ls中的fmtname代码
{
static char buf[DIRSIZ+1];
char *p;
// Find first character after last slash.
for(p=path+strlen(path); p >= path && *p != '/'; p--)
;
p++;
// Return blank-padded name.
if(strlen(p) >= DIRSIZ)
return p;
memmove(buf, p, strlen(p));
buf[strlen(p)] = 0; //字符串结束符
return buf;
}
void
find(char *path, char *name)
{
char buf[512], *p; //声明的这些结构体、变量等也和ls一样
int fd;
struct dirent de;
struct stat st;
if((fd = open(path, 0)) < 0){ //判断,也和ls一样
fprintf(2, "find open %s error\n", path);
exit(1);
}
if(fstat(fd, &st) < 0){
fprintf(2, "fstat %s error\n", path);
close(fd);
exit(1);
}
switch(st.type){
case T_FILE: //如果是文件类型
if(strcmp(fmtname(path), name) == 0)
printf("%s\n", path); //如果当前路径和文件名相同,则代表找到文件了
break;
case T_DIR: //如果是目录类型
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("find: path too long\n");
break;
}
strcpy(buf, path); //将输入的目录字符串复制到buf中
p = buf+strlen(buf);
*p++ = '/'; //将`/`拼接在后面
//读取 fd ,如果 read 返回字节数与 de 长度相等则循环
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if(de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
//不去递归处理.和..
if(!strcmp(de.name, ".") || !strcmp(de.name, ".."))
continue;
find(buf, name); //继续进入下一层目录递归处理
}
break;
}
close(fd);
}
int
main(int argc, char *argv[])
{
if(argc != 3){
fprintf(2, "usage:find \n" );
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
测试
①首先在makefile文件中添加
$U/_find\
②然后sudo make qemu进入xv6
③在终端中测试find
④执行./grade-lab-util find


五、xargs
5.1 实验描述
实验要求
编写一个简单的UNIX xargs程序:从标准输入中读取行并为每一行运行一个命令,将该行作为命令的参数提供。你的解决方案应该放在user/xargs.c中。下述例子展示了xarg的使用:
注意:
①这里的命令是“echo bye”,附加参数是“hello too”,使得命令“echo bye hello too”输出“bye hello too”。
②UNIX 上的 xargs 进行了优化,它一次向命令提供多个参数。 我们不希望您进行此优化。 要使 UNIX 上的 xargs 的行为符合我们对本实验的要求,请将 -n 选项设置为 1 来运行它。例如
③xargs, find, 和 grep 能够结合使用。下面这条命令将对“.”下目录中名为 b 的每个文件运行“grep hello”。


实验提示
1、使用
fork和exec对每一行输入调用命令。在父进程中使用wait等待子进程完成命令。
2、要读取单行的输入,请一次读取一个字符,直到出现换行符(‘\n’)。
3、kernel/param.h声明了MAXARG,你需要声明一个argv数组,这可能很有用。
4、将程序添加到Makefile的UPROGS中。
5、文件系统的变化在qemu的运行中持续存在。要获得一个干净的文件系统,请运行make clean然后make qemu。
测试条件
要测试你的 xargs 解决方案,请运行shell脚本xargstest.sh。如果产生以下输出,则你的解决方案是正确的:
您可能必须返回并修复查找程序中的错误。输出有很多$是因为 xv6 shell没有意识到它正在处理来自文件而不是来自控制台的命令,并为文件中的每个命令打印一个 $。

5.2 实验思路
思路
①从标准输入读取xargs后面的命令,存放在full_argv数组中。
②去读取前面附加的命令,存放在缓冲区buf中。
③如果读取到换行,则将buf内容填充到full_argv后面去。并创建子进程,子进程中调用exec执行命令。
④父进程等待子进程执行完毕后,清空buf,继续读取命令,循环上述过程,直到没有内容可以读取了。
5.3 实验代码
整体代码参考知乎----炼金术士,如下所示
int main(int argc, char *argv[])
{
char buf[512];
char* full_argv[MAXARG];
int i;
int len;
if(argc < 2){
fprintf(2, "usage: xargs your_command\n");
exit(1);
}
// we need an extra arg and a terminating zero
// and we don't need the first argument xargs
// so in total, we need one extra space than the origin argc
if (argc + 1 > MAXARG) {
fprintf(2, "too many args\n");
exit(1);
}
// copy the original args
// skip the first argument xargs
for (i = 1; i < argc; i++) {
full_argv[i-1] = argv[i];
}
// full_argv[argc-1] is the extra arg to be filled
// full_argv[argc] is the terminating zero
full_argv[argc] = 0;
while (1) {
i = 0;
// read a line
while (1) {
len = read(0,&buf[i],1);
if (len == 0 || buf[i] == '\n') break;
i++;
}
if (i == 0) break;
// terminating 0
buf[i] = 0;
full_argv[argc-1] = buf;
if (fork() == 0) {
// fork a child process to do the job
exec(full_argv[0],full_argv);
exit(0);
} else {
// wait for the child process to complete
wait(0);
}
}
exit(0);
}
测试
①首先在makefile文件中添加
$U/_xargs\
②然后sudo make qemu进入xv6
③在终端中测试xargs
④执行./grade-lab-util xargs
