#AIGC##VDB# 【一篇入门VDB】矢量数据库-从技术介绍到选型方向
文章概览: 这篇文章深入探讨了矢量数据库的基本概念、工作原理以及在人工智能领域的广泛应用。
首先,文章解释了矢量的数学和物理学概念,然后引入了矢量在数据科学和机器学习中的应用。随后,详细介绍了什么是矢量数据库,以及它在搜索引擎、自然语言处理、图像识别等方面的优势。
接着,文章列举了几种矢量数据库的具体应用,包括图像和视频识别、自然语言处理、推荐系统以及新兴领域如医疗保健和金融。在讨论矢量数据库的工作原理时,文章涵盖了索引结构、簇的概念以及查询算法的选择。
最后,文章以VDB的五大主要方向和六种常用矢量数据库为结尾,总结了矢量数据库的优势,强调了其在高维数据处理、搜索功能增强、可扩展性、速度和准确性、机器学习集成等方面的关键作用。
本文旨在为读者提供对矢量数据库全面而清晰的理解。
VDB 基础概念介绍
矢量
矢量嘛,就是个有大小和方向的东西。在数学和物理学里,它帮助我们描述东西的位置、速度啥的。比如在平面上,一个矢量可以分成横向(X轴方向)和纵向(Y轴方向)的部分。
在数据科学和机器学习里,矢量是表达数据的一种方式。数据可以是啥都有,比如文本、图像、音频啥的。在这里,矢量通常就是一串数字,每个数字代表数据的某个特征或属性。这样的表示方式方便机器学习算法处理各种类型的数据,搞模式识别、分类啥的。
搞清楚矢量的概念对理解矢量数据库以及在机器学习和数据科学中的应用挺重要的。如果还有啥问题,随时问哈。
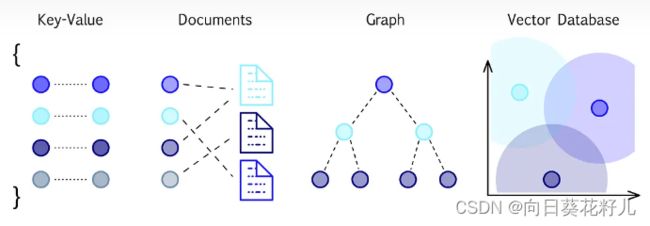
什么是矢量数据库?
如果你得搞数据,可能就要玩搜引擎这一套了。最牛的搜引擎软件虽然很炫,但因为它们的内核设定,找你要的数据时有点小限制。
以数据对象为例:
{ "data": "The Eiffel Tower is a wrought iron lattice tower on the Champ de Mars in Paris." }
要是放传统搜引擎里,可能就靠倒排索引来整理数据。这就意味着你得输入“埃菲尔铁塔”、“锻铁格子”之类的关键词,才能找到你想要的。但如果你有一大堆数据,想找埃菲尔铁塔的相关文档,可如果你搜“法国地标”呢?传统搜引擎就有点捉襟见肘了,这时候矢量数据库就能展现它的强大之处。
矢量数据库就是用向量索引搞数据。有个矢量化模块,比如NLP模块,把你那些数据对象在矢量空间里搞了个映射,放在“法国的地标”这文本附近。这就意味着Weaviate可不一定百分之百地找到完全匹配的,但总能找到挺接近的匹配,然后给你个结果。
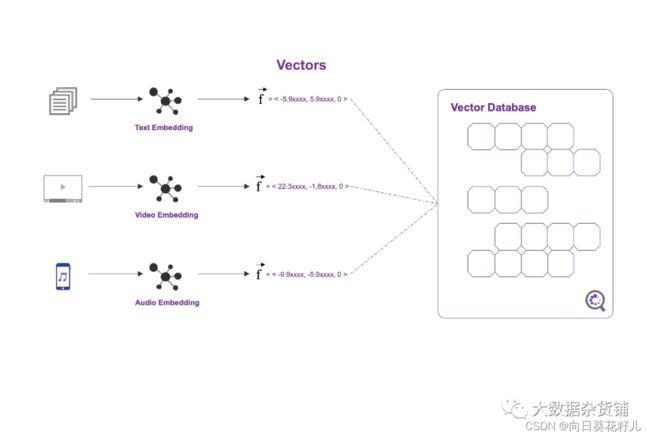
上面的例子是针对文本(NLP)的,但你其实可以对任何矢量化的机器学习模型使用矢量搜索,比如图像、音频、视频,甚至基因数据。就是把你的数据搞成矢量,然后用这套搜寻方法找相似的东西。
矢量数据库管理系统(VDBMS),也就是矢量数据库或者说矢量存储,就是个能存矢量(一串数字的列表)和其他数据的数据库。这玩意一般都搞了一堆近似最近邻算法(ANN:Approximate Nearest Neighbor),所以可以用查询来搜索数据库,找到最接近的匹配记录。
矢量数据库和关系数据库不太一样,它把数据表示成多维空间中的点,不是传统的行和列那一套。特别适合那些需要基于相似性而不是完全一样值来快速匹配数据的应用。你可以把矢量数据库想象成一个超大的仓库,而人工智能就像是个经验丰富的仓库管理员。在这个仓库里,每个项目(数据)都装在一个盒子(矢量)里,整齐地摆在多维空间的货架上,就像《新堆栈》中马克·辛克尔说的那样。
矢量数据库的用例
矢量数据库真的很牛,特别是在搜东西方面。你想找个东西跟某个东西相似,这玩意就能秒搜出来。还有就是它还参与了一些高级玩意,比如产品推荐、图像/音频/视频搜相似的玩意,甚至还能帮你查异常。
另外,它还牛逼地用在了一些叫做检索增强生成 (RAG) 的玩意上,这个东西可以提高在某个领域的查找效果。大概的操作是用户给个提示,计算提示的特征矢量,然后搜数据库找最相关的文档。这些东西自动加到大型语言模型的上下文,让它继续根据上下文生成对提示的响应。挺神奇的。

具体使用方向:
图像和视频识别:
视觉内容主导着我们的视觉文化,矢量数据库在其中大放异彩。他们擅长筛选大量图像和视频存储库,以找出与给定输入惊人相似的图像和视频。这不仅仅是逐像素匹配;这是关于理解潜在的模式和特征。这些功能对于面部识别、物体检测,甚至媒体平台中的版权侵权检测等应用至关重要。

自然语言处理和文本搜索:
同义词、释义和上下文可能使精确的文本匹配成为一项艰巨的任务。然而,矢量数据库可以辨别短语或句子的语义本质,使它们能够识别措辞可能不相同但上下文相似的匹配。这种能力改变了聊天机器人的游戏规则,确保它们正确响应用户的查询。同样,搜索引擎可以提供更相关的结果,从而增强用户体验。

推荐系统:
矢量数据库在个性化中发挥着关键作用。通过了解用户偏好和分析模式,这些数据库可以推荐与听众品味产生共鸣的歌曲或符合购物者偏好的产品。这一切都是为了衡量相似性并提供引起用户共鸣的内容或产品。
新兴应用:
矢量数据库的范围不断扩大。在医疗保健领域,他们通过分析分子结构以获得潜在的治疗特性来帮助药物发现。在金融领域,矢量数据库正在协助异常检测,发现可能表明欺诈活动的异常模式。
随着生成式人工智能的兴起,矢量数据库成为重要的推动者,帮助开发人员将复杂的人工智能蓝图转变为实用的、价值驱动的工具。
矢量数据库如何工作?
高效查询大量矢量需要索引,矢量数据库支持矢量的专用索引。不同于其他数据类型,矢量没有固有的逻辑顺序。最常见的用例是查询在点积、余弦相似度或欧几里得距离等距离度量方面最接近其他某个矢量的 k 个矢量,这就是所谓的“k(精确)最近邻”或“KNN”查询。
虽然没有通用的高效KNN查询算法,但有一些有效的算法可以找到k个近似最近邻(“ANN”)。这些ANN算法牺牲了一些准确性,尤其是召回率,以极大地提高速度。由于很多用例已经认为计算矢量嵌入的过程有一些不精确,所以它们通常可以接受一些召回损失以换取性能的显著提升。

为了通过与其他矢量的距离来查询矢量,矢量索引的结构方式是将附近矢量的簇通常分组在一起。常见的矢量索引类型可以构造为一组列表,其中每个列表代表给定簇中的矢量;每个矢量都连接到其最近邻的几个矢量的图;树的分支对应于父节点簇的子集;等等。每种索引类型都在查找速度、召回率、内存消耗、索引创建时间和其他因素之间进行权衡。
不过,大多数数据库查询不仅仅基于语义相似性。例如,用户可能正在找描述类似于“关于孩子和狗的温馨故事”的书,但还希望价格在20美元以下。专用矢量数据库可能提供一些有限的额外过滤功能,有时称为“限制”;而通用数据库可以使用SQL等标准语言组成丰富的谓词,这些谓词可以与矢量相似性排序相结合,实现非常强大、富有表现力的查询。
单词、句子甚至整个文档都可以转换成能捕捉其本质的矢量。比如,Word2Vec就是一种常见的词嵌入方法。通过Word2Vec,有相似含义的单词由多维空间中接近的矢量表示。最有名的例子就是:国王-男人+女人=女王。把“国王”和“女人”相关的矢量加起来,同时减去“男人”相关的矢量,就得到“女王”相关的矢量。

使用 VBD
矢量数据库方向
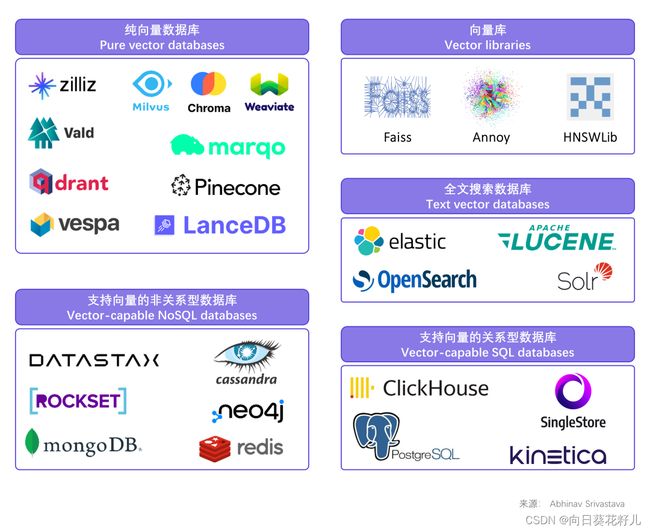
选矢量数据库得权衡一下,这里有五个主要方向:
- 纯矢量数据库,比如Pinecone,还有建立在Faiss基础上的。专门搞矢量的。
- 全文搜索数据库,比如ElasticSearch,以前搞搜索引擎,现在也搞矢量存储和检索。
- 矢量库,像Faiss、Annoy和Hnswlib,虽然不是数据库,但擅长处理矢量。
- 支持矢量的NoSQL数据库,比如MongoDB、Cosmos DB和Cassandra,老牌存储但加入了矢量的操作。
- 支持矢量的SQL数据库,比如SingleStoreDB或PostgreSQL,和前面不同的是支持SQL语句。
除了这五个,还有一些功能更广泛的东西像Vertex AI和Databricks,这里不深入讨论。看你需求选哪套。
AI开发常用的6种VDB(矢量数据库概览)
PGVector
- 特点:
- 强调与Postgres的集成,支持矢量与其他数据类型混合存储。
- 具有通用性,适用于任何带有Postgres客户端的语言。
- 支持多种距离度量,如L2距离、内积和余弦距离。
- 注意:
- 对Postgres的依赖可能不适合所有用例,尤其是对专门的矢量数据库功能有需求的情况。
Weaviate
- 特点:
- 人工智能原生矢量数据库,结合了矢量和关键词搜索。
- 提供双重搜索功能,支持多种神经搜索框架。
- 提供矢量化模块,增强语义理解和准确性。
- 注意:
- 功能丰富,可能对初学者有较高的学习曲线。
ChromaDB
- 特点:
- 注重简单性和开发效率,特别适用于构建Python或JavaScript应用程序。
- 开发者友好,拥有完全类型化、经过测试和文档化的应用程序接口。
- 可扩展,可在python笔记本中运行,并支持集群扩展。
- 注意:
- 简单性可能会限制某些需要复杂数据库操作的高级用例。
Milvus
- 特点:
- 云原生矢量数据库,具有高度可扩展性和弹性。
- 实现毫秒级搜索在大规模数据集上。
- 支持混合搜索,包括向量和标量数据类型。
- 注意:
- 对于小型项目可能显得过于复杂。
Qdrant
- 特点:
- 用Rust编写,注重性能和可靠性。
- 支持扩展过滤,适用于各种应用。
- 提供生产就绪的应用程序接口。
- 注意:
- 基于Rust,可能对不熟悉该语言的团队带来一定困难。
ElasticSearch
- 特点:
- 不是专用的矢量数据库,但适用于存储和搜索矢量数据。
- 具有分布式架构,适用于大型数据集的实时搜索。
- 通用性,可处理多种搜索需求。
- 注意:
- 可能需要额外配置以优化矢量特定用例。
-
- 可能需要额外配置以优化矢量特定用例。
VDB 优点
矢量数据库在各种人工智能应用中有着关键的优势,特别是涉及到复杂和大规模数据分析的应用。以下是一些主要的优点:
1. 高效处理高维数据
矢量数据库专为高效处理高维数据而设计。相比传统数据库,矢量数据库在存储、处理和检索高维空间的数据时性能更强,不容易受到复杂性和数据规模的影响。
2. 增强的搜索功能
矢量数据库最显著的优势之一是能够执行相似性和语义搜索。它们能够快速找到与给定查询最相似的数据点,这对于推荐引擎、图像识别和自然语言处理等应用至关重要。
3. 可扩展性
矢量数据库必须具备高度可扩展性,能够处理大规模的数据集而不损失性能。这对于那些需要定期生成和处理大量数据的企业和应用程序非常重要。
4. 速度和准确性
相对于传统数据库,矢量数据库提供更快的查询响应,尤其是在处理大规模数据集的复杂查询时。而且,这种速度并不是以准确性为代价的,因为矢量数据库利用先进的算法能够提供高度相关的结果。
5. 改进的机器学习和人工智能集成
矢量数据库特别适合人工智能和机器学习应用。它们能够有效地存储和处理训练以及运行机器学习模型所需的数据,尤其在深度学习和自然语言处理等领域。
6. 促进高级分析和见解
通过支持复杂的数据建模和分析,矢量数据库使组织能够从数据中获取更深入的见解。这对于数据驱动的决策和预测分析至关重要。
7. 个性化
这些数据库通过分析用户行为和偏好来支持个性化用户体验的开发。在营销、电子商务和内容交付平台等领域,个性化可以显著提高用户参与度和满意度。

参考文献
Vector database https://en.wikipedia.org/wiki/Vector_database
what-is-a-vector-database https://www.datastax.com/guides/what-is-a-vector-database
https://cloud.google.com/discover/what-is-a-vector-database
https://www.mongodb.com/basics/vector-databases
https://zilliz.com/learn/what-is-vector-database
AssemblyAI (Director). (2022, January 5). A Complete Overview of Word Embeddings. https://www.youtube.com/watch?v=5MaWmXwxFNQ
Grootendorst, M. (2021, December 7). 9 Distance Measures in Data Science. Medium. https://towardsdatascience.com/9-distance-measures-in-data-science-918109d069fa
Langchain. (2023). Welcome to LangChain — LangChain 0.0.189. https://python.langchain.com/en/latest/index.html
OpenAI. (2022). Introducing text and code embeddings. https://openai.com/blog/introducing-text-and-code-embeddings
OpenAI (Director). (2023, March 14). What can you do with GPT-4? https://www.youtube.com/watch?v=oc6RV5c1yd0
Porsche AG. (2023, May 17). ChatGPT & enterprise knowledge: “How can I create a chatbot for my business unit?” #NextLevelGermanEngineering. https://medium.com/next-level-german-engineering/chatgpt-enterprise-knowledge-how-can-i-create-a-chatbot-for-my-business-unit-4380f7b3d4c0
Tazzyman, S. (2023). Neural Network models. NLP-Guidance. https://moj-analytical-services.github.io/NLP-guidance/NNmodels.html
https://towardsdatascience.com/all-you-need-to-know-to-build-your-first-llm-app-eb982c78ffac