数据结构与算法:快速排序
数据结构与算法:快速排序
-
- 快速排序
-
- 荷兰国旗问题
- 霍尔版本
- 递归优化
-
- 小区间优化
- PartSort优化
-
-
- 三数取中
- 挖坑法
- 前后指针法
-
- 非递归法
快速排序
荷兰国旗问题
想要理解快速排序,就先理解这个问题:
[LeetCode75.颜色分类]

荷兰国旗是由红白蓝三色组成的:
现在将其颜色打乱
然后根据一定的算法,将其复原为红白蓝三色,这就叫做荷兰国旗问题。


在LeetCode的题目中,其将荷兰国旗的三个颜色用0,1,2来表达,也就是说我们要把大于1的放到1的右边,小于1的放到1的左边,这就是解决这个问题的基本思路。
快排的基本思路也是如此:在一趟排序中,将一个值作为key值,然后将大于这个key值的数放到右边,小于key的放到key的左边。
比如这样个数组

假设我们将第一个值作为key值,那么高于这个红线的值都要到右边作为大于区,低于这个红线的值都要到左边作为小于区,然后再把key放到大于区和小于区的中间。
比如这样:

然后再把key值插入到中间:

这样左边的值都小于key,右边的值都大于key。
那么这要如何实现呢?我们先看到最古早的快速排序–霍尔版本
霍尔版本
我们的目的是:把大于key的值放到右边,小于key的值放到左边。
此时霍尔想到,安排两个变量left与right,左边的变量left往右寻找大于这个key的值,右边的变量right往左寻找小于这个key的值,一旦left和right都找了值,交换left与right的值。
示例:
一开始选定第一个值作为key值:

然后i变量往右移动,直到找到一个值大于key:

接着right往左移动,找到一个值小于key:
交换两个值:

循环以上步骤:
当我们完成这个过程后,数组状态如下:

红色区域是小于区,绿色区域是大于区。
接下来就是要把key放到小于区和大于区的中间,这个过程,只需要将key与小于区的最后一个元素交换位置即可:
这样我们就完成了一趟排序。
一趟排序的代码如下:
int left = 0, right = n;
int keyi = 0;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
以下是对代码的解释:
- 初始化变量
left和right,分别表示数组的左右边界。left初始为0,right初始为n,其中n表示数组长度。- 初始化变量
keyi,表示选取的基准元素的下标,初始为0。- 进入循环,循环条件是
left<right,即左边界小于右边界。- 第一个while循环:从右边开始向左遍历数组
a,寻找第一个小于基准元素a[keyi]的元素。循环条件是left < right并且a[right]大于等于a[keyi],如果满足条件,说明当前元素不是要找的元素,则right减1,寻找下一个元素。- 第二个while循环:从左边开始向右遍历数组a,寻找第一个大于基准元素
a[keyi]的元素。循环条件是left < right并且a[left]小于等于a[keyi],如果满足条件,说明当前元素不是要找的元素,则left加1,寻找下一个元素。- 当两个while循环结束后,说明找到了需要交换的两个元素。调用Swap函数,将
a[left]和a[right]交换位置。- 继续下一轮循环,直到left >= right。
- 当循环结束,交换
a[left]和a[keyi],即把key值和小于区的最后一个元素交换位置,让key到达正确位置。
图示:

这个过程中,left左侧的值(紫色)都小于key,right右侧的值(绿色)都大于key,当相遇时,两者分别就维护了一段大于区和一段小于区,直接将key插入即可。
那么这一趟排序有什么用呢?虽然最后没有把整个数组变成有序,但是我们的key值找到了正确的位置。
也就是说,经过这一趟排序,key的位置此后都不会改变了,key的位置就是完全有序状态下的位置。
这是为什么?
不妨想想一个完全有序的数组,取其中某一个值出来,不就是左边的所有值都小于等于这个元素,右边所有值大于等于这个元素吗?
那么我们要如何进行接下来的步骤,让整个数组有序?
答案是递归。
经过这一趟排序,我们将数组拆分为了三个区域:[小于区]:[key]:[大于区]
接下来我们不断将小于区和大于区拆分出来执行这个过程:
1.选key
2.筛选新的小于区和大于区

当快速排序递归到底层时,每个子数组只含有一个元素或没有元素,这些子数组都可以看作是有序的。由于每次递归都确保了基准元素的左右两个部分分别有序,最终整个数组就会有序。
我们看一看快速排序的主体部分:
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
//单趟排序
QuickSort(a, begin, keyi - 1);//递归小于区间
QuickSort(a, keyi + 1, end);//递归大于区间
}
函数QuickSort接受一个整型数组a以及两个整数begin和end作为参数,表示对数组的子区间[begin, end]进行排序。如果begin >= end,即子区间为空或只有一个元素,那么不需要排序,直接返回。
在每次递归调用中,函数将主区间分为两个子区间:小于key的区间和大于key的区间。通过递归调用自身,对两个子区间进行排序。
通过递归调用QuickSort(a, begin, keyi - 1),对小于关键字的区间进行排序。递归调用QuickSort(a, keyi + 1, end)对大于关键字的区间进行排序。
经过多次递归调用后,整个数组将被划分为若干个有序的子区间,最后合并起来得到整体有序的数组。
完整代码:
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
//单趟排序开始---------------------------------------
int left = begin, right = end;
int keyi = begin;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
//单趟排序结束---------------------------------------
keyi = left;
QuickSort(a, begin, keyi - 1);//递归小于区间
QuickSort(a, keyi + 1, end);//递归大于区间
}
其中,我们将单趟排序称为PartSort,递归主体就是快排主体,我们会如下拆分代码:
int PartSort(int* a, int begin, int end)
{
int left = begin, right = end;
int keyi = begin;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
keyi = left;
return keyi;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = PartSort(a, begin, end);
QuickSort(a, begin, keyi - 1);//递归小于区间
QuickSort(a, keyi + 1, end);//递归大于区间
}
总效果图:
至此,我就为大家解释完了快排的基本思想,但是快排至此还不是完全体,后人对快排做了非常多的优化,使得快排性能一步一步提高。
递归优化
小区间优化
快速排序是基于递归的排序,其递归是会向左右区间递归,那么就会形成一个二叉树的结构。而二叉树的最后一层的节点占比可以高达50%。
假设满二叉树的深度为h,那么最后一层的节点数目为2(h-1)个,而满二叉树的总节点数目为2h - 1个。
因此,最后一层占所有节点的百分比为: (2(h-1))/(2h - 1) * 100%。
当递归层数足够深,这个式子就可以看为: (2(h-1))/(2h ) * 100% = 50% 。
而当快速排序递归到最后一层,区间内只有一两个数字需要排序了,此时再递归是没必要的。我们可以选用其它的排序来进行最后几个数字的排序,这样可以大量节省递归的消耗,提高性能。
在此,我们可以利用begin和end的差值来控制递归,当其差值小于一定值时,我们改用插入排序来收尾。因为快速排序到了最后几层,递归出来的小数组已经十分接近有序,而插入排序对有序数组的适应性较好,所以这里选用插入排序。
代码如下:
void QuickSort(int* a, int begin, int end)
{
int THRESHOLD = 10; // 设定阈值为10
if (begin >= end)
return;
if (end - begin + 1 <= THRESHOLD)
{
InsertSort(a, begin, end);// 使用插入排序对小区间进行排序
}
else
{
int keyi = PartSort(a, begin, end);
QuickSort(a, begin, keyi - 1); // 递归小于区间
QuickSort(a, keyi + 1, end); // 递归大于区间
}
}
此处我们将阈值设为了10,也就是当递归划分数组的长度小于10时,就进行插入排序,这个阈值可以减少大约3-4层递归,最后一层递归就已经50%了,三四层递归可以节省80-90%的递归次数。
这个优化看似效率很高,但是其实现在的递归消耗并不高,哪怕节省了80-90%的递归次数,也许优化效果并没有那么好。
PartSort优化
三数取中
我们目前的快速排序仍然有一个缺点:对已经有序的数组适应性非常差。
比如这样一个数组:

我们对其进行快速排序,由于其已经有序,而我们每次选取key值又选的是第一个值,这就会导致一趟PartSort下来,小于区间为0,大于区间为n-1,接着我们递归到大于区间,不断循环上述过程:
那么这样对于一个n个数字的数组,我们就需要递归n层。这样实在太浪费资源了。
我们是否有办法,减少在有序情况或者接近有序的情况的递归层数?
于是三数取中出现了,三数取中是指,每次选取key值时:
1.先挑出最左侧下标值,最右侧下标值以及中间下标值(依据下标选出三个值)
2.选取三个值中的中间值
那么为什么三数取中可以减少递归的层数?
我们看一个实例:

我先为大家解释此图:
每一层是一一层递归,红色值是本次递归的key值,蓝色是大于区,绿色是小于区。下一层递归是,蓝色区和绿色区分别递归,并重新筛选key值。
在选取第一个值作为key的图中,由于一直没有小于区出现,一次每层递归只能排序一次,而右侧由于选择了中间值作为key值,会尽可能保证大于区和小于区都存在,下一层递归就能处理更多的数据。
这样我们左侧递归了9层,而右侧只递归了4层。这就是三数取中带来的效率优化。一般来说,取第一个值最多需要递归n层,而三数取中一般为logn层。
我们先选一个三数取中的函数:
//三数取中
int GetMidi(int* a, int begin, int end)
{
int midi = (begin + end) / 2;
//选begin end midi 的中位数
if (a[begin] < a[midi])
{
if (a[midi] < a[end])
return midi;
else if (a[begin] > a[end])
return begin;
else
return end;
}
else
{
if (a[end] < a[midi])
return midi;
else if (a[end] > a[begin])
return begin;
else
return end;
}
}
这个函数就是实现三数取中:
1.先挑出最左侧下标值,最右侧下标值以及中间下标值(依据下标选出三个值)
2.选取三个值中的中间值
那么取出了中间值,要如何让快排将其作为key值?
我们先前的快排是把第一个值的位置作为key,如果取中间值作为key,那么这个值碍在中间,会不会影响left和right的移动判断?
所以我们选出中间数后,先将其与第一个值交换,把中间值放到第一个位置,防止它碍在中间。
代码如下:
//霍尔三数取中快排
int PartSort1(int* a, int begin, int end)
{
int midi = GetMidi(a, begin, end);
Swap(&a[midi], &a[begin]);//将取出的中间值放在首位做key
int left = begin, right = end;
int keyi = begin;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
keyi = left;
return keyi;
}
挖坑法
挖坑法是对霍尔版本的优化,霍尔版本中我们利用了left与right分别找大找小,然后将left与right的值进行交换。到了最后再把key和小于区的最后一个值交换。
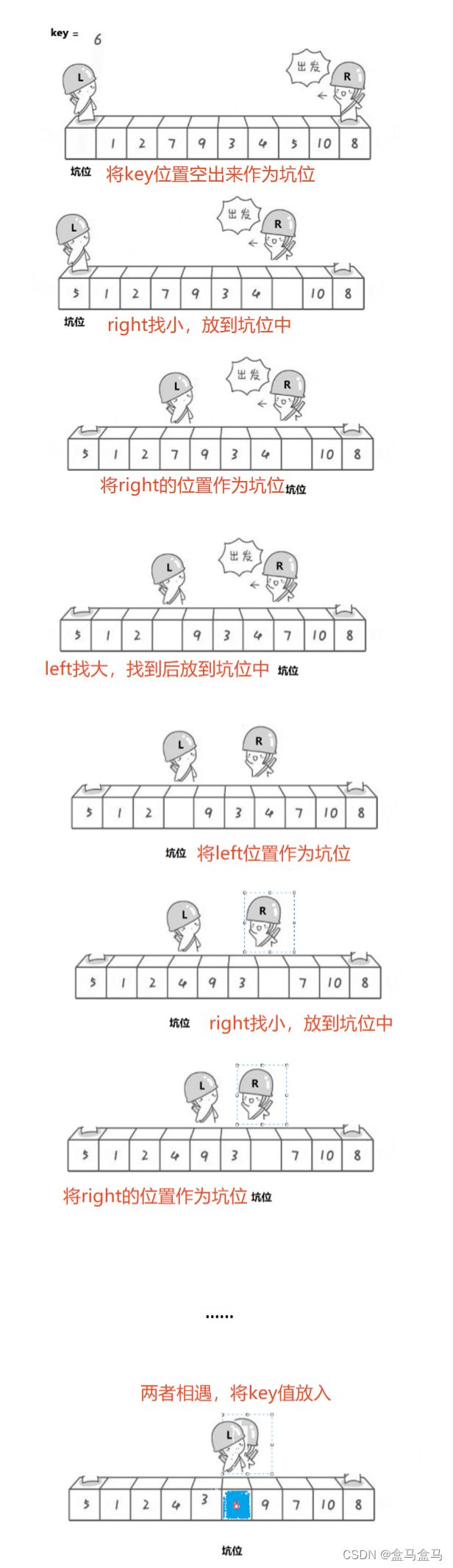
挖坑法的思路是:
- 一开始将
key值的位置空出来作为坑位- 右边
right找小,找到后直接放到key的位置(坑位),然后将此位置作为坑位- 左边
left找大,找到后放到坑位(刚刚右边空出来的位置),然后将此位置作为坑位- 循环2,3步骤,直到
left与right相遇- 相遇后,将key值放到相遇点
图解如下:
代码如下:
// 快速排序挖坑法
int PartSort2(int* a, int begin, int end)
{
//三数取中
int midi = GetMidi(a, begin, end);
Swap(&a[midi], &a[begin]);
int key = a[begin];
int hole = begin;
while (begin < end)
{
//右边找小,填到右左边的坑
while (begin < end && a[end] >= key)
{
end--;
}
a[hole] = a[end];//填坑
hole = end;//换坑
//左边找大,填到右边的坑
while (begin < end && a[begin] <= key)
{
begin++;
}
a[hole] = a[begin];//填坑
hole = begin;//换坑
}
a[hole] = key;
return hole;
}
代码解析如下:
- 首先,通过调用
GetMidi函数,找到数组a中的三个元素(起始索引begin、终止索引end以及中间索引midi)的中值,并将中值与起始索引的元素交换位置。这样做是为了通过将中值作为基准值,降低快速排序的时间复杂度。
- 定义变量
key为基准值,hole为开始时的坑的位置(即起始索引begin)。
- 进入一个循环,循环条件是开始索引小于结束索引。
- 在循环中,先从右向左扫描数组,找到第一个小于基准值的元素,将其填入坑中(即将
a[end]赋值给a[hole]),然后将坑的位置更新为已填入元素的位置。
- 再从左向右扫描数组,找到第一个大于基准值的元素,将其填入右边的坑中(即将
a[begin]赋值给a[hole]),然后将坑的位置更新为已填入元素的位置。
- 重复步骤4和步骤5,直到开始索引不小于结束索引为止。
- 将基准值填入最后一个坑中,此时基准值左边的元素都小于它,右边的元素都大于它。
- 返回基准值的索引。
前后指针法
回顾一下霍尔法以及挖坑法的基本思路,其用left与right来拓展小于区和大于区,最后将key放在了中间。
像这样:
这个过程中,right右边的是大于的区域,left左边的是小于的区域。
当我们同时确定了大于的区域和小于的区域,再把key值插入。
那么我们一定要同时维护大于区和小于区吗?
不妨想一想,我们只维护一段小于区,把所有小于等于key的值都放进小于区,剩下的值不就是大于key的值了吗?
也就是说我们可以只维护一段区域,剩下的区域会自动生成,这就是前后指针法的思路。
先看代码,后解析。
代码如下:
// 快速排序前后指针法
int PartSort3(int* a, int begin, int end)
{
int midi = GetMidi(a, begin, end);
Swap(&a[midi], &a[begin]);
int prev = begin;
int cur = prev + 1;
int keyi = begin;
while (cur <= end)
{
if (a[cur] < a[keyi])//避免自己和自己交换
Swap(&a[++prev], &a[cur]);
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
思路:
使用一个
prev指针维护一段小于区,用cur指针在数组中查找小于key的值,找到后放进小于区,并且++prev,意味着小于区扩展了一位。最后把key放到小于区的后面,此时大于区已经自动生成在了key的右侧。
代码详解:
首先,通过调用
GetMidi函数获取中间元素的下标midi,然后将中间元素与起始元素交换位置,将中间元素作为基准元素。
接下来,定义两个指针
prev和cur,prev指向基准元素的位置,cur指向prev的下一个位置。
然后,定义一个keyi变量来保存基准元素的位置。
进入循环,在循环内部首先判断
cur所指向的元素是否小于基准元素,并且判断prev和cur是否相等,避免自己和自己交换。如果满足条件,则将prev指向的元素与cur指向的元素交换位置,prev向后移动一位(此时相当于小于区扩大了一位)。
循环结束后,将
prev所指向的元素与基准元素交换位置,将基准元素放在正确的位置上,然后返回基准元素的位置keyi。
这样就完成了一次快速排序的分割操作。
示意图如下:

要注意,由于前两次交换,prev和cur还没有拉开差距,也就是说没有发现比key大的值,所以是自己和自己交换。
非递归法
那么也没有不递归的快速排序法呢?
也是有的,我们在递归排序时利用的思路是,每次递归key左侧的小于区以及右侧的大于区,把这个区域进行一次PartSort。
也就是说我们要想办法把下一次需要单趟排序的范围存储下来。
这里可以用到一个栈结构,每次单趟排序,把排序的区间从栈中取出来,排序完后根据key划分区域,再把需要排序的子区域入栈。
代码如下:
此处不对栈这个结构的实现做详解,受C语言限制,这个栈需要手撕。
// 快速排序 非递归实现
void QuickSortNonR(int* a, int begin, int end)
{
Stack s;
StackInit(&s);//初始化栈
StackPush(&s, end);//入栈数组尾部
StackPush(&s, begin);//入栈数组头部
while (!StackEmpty(&s))
{
//取出栈顶的左右元素,作为本次排序的范围
int left = StackTop(&s);
StackPop(&s);
int right = StackTop(&s);
StackPop(&s);
int keyi = PartSort(a, left, right);//一趟排序
if (left < keyi - 1)//将本次排序的子区间入栈
{
StackPush(&s, keyi - 1);
StackPush(&s, left);
}
if (keyi + 1 < right)//将本次排序的子区间入栈
{
StackPush(&s, right);
StackPush(&s, keyi + 1);
}
}
StackDestroy(&s);//销毁栈
}
下面是对代码的详细解释:
- 定义了一个函数
QuickSortNonR,参数为待排序数组a的起始位置begin和结束位置end。
- 初始化一个栈
s,用于保存待排序区间。调用StackInit函数初始化栈。
- 将数组的起始位置和结束位置分别入栈。即
StackPush(&s, end)和StackPush(&s, begin)。
- 进入循环,判断栈是否为空。如果栈不为空,则继续执行排序操作;否则结束排序。
- 在循环内部,首先从栈顶取出左右边界,即
left和right。分别将它们出栈。
- 调用
PartSort函数进行一趟排序,将数组a中left到right之间的元素按照某个基准值进行划分,返回基准值的下标。
- 如果左边区间的起始位置
left小于基准值的下标keyi-1,则将该区间入栈。即StackPush(&s, keyi-1)和StackPush(&s, left)。
- 如果右边区间的结束位置
keyi+1小于right,则将该区间入栈。即StackPush(&s, right)和StackPush(&s, keyi+1)。
- 回到步骤5,继续下一次排序操作。
- 当栈为空时,表示所有的子区间都已经排序完成,结束循环。
- 调用
StackDestroy函数销毁栈s,释放内存。