NeRF算法原理总结概述
简介
本文旨在对NeRF算法进行总结。论文翻译见博客:《NeRF算法论文解析与翻译》
参考链接:
神经网络辐射场NeRF、实时NeRF Baking、有向距离场SDF、占用网络Occupancy、NeRF 自动驾驶
NeRF详解
NeRF入门之体渲染 (Volume Rendering)
NeRF中的位置编码
1.算法概述
整体上NeRF干了这么一件事,输入一组静态场景的连续RGB图像和每帧图像对应的位姿,基于体渲染技术构建损失函数,通过借助一个全连接神经网络MLP得到关于新视角图像中每个像素对应3D点的体积密度和RGB颜色信息。其中不包含3D场景重建,只是将场景隐式的通过一个函数进行表达。
算法整体的pipeline如下图所示:
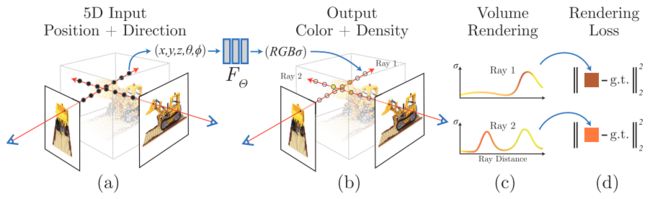
其主要的工作在于:
- 将连续场景表示为一个5D输入的神经辐射场,输入采样点的3D坐标和方向,可以得到其体积密度和颜色信息
- 在寻找采样点时使用一种分层采样,”粗采样“计算相机射线上的点的分布,”细采样“获取概率分布较大处的点,避免过多选择"空"处的无效点,以及忽略"密集处"的好点
- 对位置和方向坐标使用位置编码,以提高渲染的分辨率
- 基于体渲染技术构建损失函数,并对位置和颜色进行分层训练
主要内容大概可以分为:数据预处理、分层体积采样、位置编码、MLP网络、损失函数
2.数据输入
2.1 数据信息说明
这里要区分一下NeRF的算法输入数据和MLP的神经网络输入。对于NeRF算法,输入只需要一组关于静态场景的RGB图像数据和每帧图像对应的位姿。然后,通过数据预处理模块会将RGB图像数据转换为MLP神经网络需要的5D坐标,包括xyz位置信息,和2D的旋转信息。
(1)xyz位置信息
背景:已经知道位于真实场景下的3D空间点[x,y,z]通过相机投影落在成像平面上会得到一个对应的像素[u,v],即连接真实世界中某个3D点和相机光心之间的连线,和相机成像平面相交于对应的像素位置。
在进行3D重建或是本文的新视角图像合成工作时,已知的是2D图像和对应的相机光心位置(位姿),需要很据这些信息反推出3D点的位置。对于3D重建工作可以通过视差或者深度滤波器来进行估计,在本文中是通过在这条射线上进行采样来得到深度学习网络的输入,也就是上面图像中左图中射线上的黑点。
根据相机投影原理,由像素坐标[u,v]可以得到3D采样点的[x,y]坐标,然后当采样点的位置确定后可以确定3D点的z坐标。

(2)旋转信息(θ,φ)
从相机光心出发,连接图像中的每个像素会得到一组射线,这里的旋转信息指的是每条相机射线的方向信息。3D空间中的方向可以由一个方向矢量表示,这个方向矢量由相机光心坐标和像素在焦距f处的3D坐标决定,然后通过相机位姿可以将该方向转换为世界坐标系下,并以方位角θ和仰角φ形式作为神经网络的输入。
2.2 分层体积采样
-
首先,根据数据集中稀疏地图可以得到一个地图中点到光心的最大最小距离,称之为
边界。 -
然后,在每条射线上的边界范围内,均匀选择
N_c个采样点(如下面左图),使用coarse网络对其进行训练可以得到每条射线上点的体积密度和颜色信息 -
然后,将
coarse网络的预测结果(体积密度和颜色)带入到相关的体渲染函数中,可以得到关于该光线的概率密度分布函数( w ^ i \hat{w}_{i} w^i)

![]()
-
然后,根据估计出的分布进行第二次重要性采样,共计
N_f个点(如下面右图橘色点) -
最后,将两次采样共
N_c+N_f个点送到fine网络进行训练
此过程将更多样本分配给我们希望包含可见内容的区域(即采样点分布比较密集的区域)。这解决了与重要性采样类似的目标,但我们使用采样值作为整个积分域的非均匀离散化,而不是将每个样本视为整个积分的独立概率估计。

3.位置编码
目前深度学习网络对低频的数据训练效果较好,因为现实场景中的变化在低频数据中的反映差距更明显(参考一下逆深度的概念),但是场景的3D点一般是高频数据,比如位置(237, 332, 198)和位置(237,332,199)这两个点作为MLP的输入,如果直接将原始数据送入到网络中进行训练,MLP可能对个位不够敏感,导致输出过平滑的问题,最终无法得到高分辨率的结果,具体表现为最终的渲染图片会出现模糊,如下图中第4张图像:

针对这一问题,作者选择对位置数据和方向信息进行位置编码,即将原始的数据送入到一个映射函数:
![]()
当然,也如公式所示,我们并不以单一的频率来表示位置编码,比如我们挨个用[1,2,4,8,16,32,64,128,256,512]这10种频率来表示编码位置(只需用公式r=sin(p*x),然后简单concat到一起)。这就完成了基本的位置编码。当然,我们还可以加入相位平移,把cos(p*x)的结果也concat到一起。
所以,对于一个位置p(x,y,z),我们用10种频率来编码,每种频率采用两种相位(sin和cos),那编码后的位置应该有3×10×2=60维来表示原始的三维坐标向量。
NeRF除了位置(x,y,z)输入外,还需要输入观测角度(θ,ϕ)。观测角度可以用ray direction来表示,通常采用三维向量。也需要进行编码,也可以统称为位置编码。我们用同样的方法,但可以少用一些频率,比如我们用[1,2,4,8]这四种频率来编码观测角度。编码后的维度也可计算出来:3x4x2=24

4.MLP网络
该MLP网络先使用8个全连接层处理三维位置(x,y,z),输出体素密度σ和256维特征向量(因此体素密度σ仅是关于三维位置(x,y,z)的函数);
然后将上面得到的256维特征向量与二维方位视角(θ,φ)concat,接着用1个全连接层处理,输出颜色c=(r,g,b)。

5.损失函数
再次回顾一下NeRF的任务:即通过对一个3D场景进行学习,然后实现该场景新视角下的图像合成。只要知道每个像素对应的RGB信息即可以得到一张图像,NeRf通过将生成的每个光线对应像素的体积密度信息和颜色信息,带入到体渲染公式中可以得到一个基于NeRF的预测值,然后通过和对应图像的真值结果作差得到2范数的损失函数。
然后,综合上述coarse网络和fine网络的预测结果可以得到最终的误差损失函数。
