Golang数组、切片和map
数组
数组可以存放多个同一类型数据。数组也是一种数据类型,在Go中,数组是值类型。
初始化的四种方式
package main
import "fmt"
func main() {
//四种初始化方式
var numArr01 [3]int = [3]int{1, 2, 3}
fmt.Println("numArr01=", numArr01)
var numArr02 = [3]int{1, 2, 3}
fmt.Println("numArr02=", numArr02)
//[...]是固定的写法
var numArr03 = [...]int{1, 2, 3}
fmt.Println("numArr03=", numArr03)
//指定下标
var numArr04 = [...]int{1: 100, 2: 200, 0: 300}
fmt.Println("numArr04=", numArr04)
//类型推导
numArr05 := [...]string{1: "tom", 2: "jack", 0: "mary"}
fmt.Println("numArr05=", numArr05)
}
for-range遍历
for index , value := range array01 {
...
}
- 第一个返回值index是数组的下标
- 第二个value是在该下标位置的值
- 他们都是仅在for循环内部可见的局部变量
- 遍历数组元素的时候,如果不想使用下标index,可以直接把下标index标为下划线_
- index和value的名称不是固定的,即程序员可以自行指定,一般命名为index和value.
package main
import "fmt"
func main() {
var heroes [3]string = [3]string{"宋江", "无用", "卢俊义"}
fmt.Println(heroes)
for i, v := range heroes {
fmt.Println("i=%v,v=%v", i, v)
}
}
数组的细节和注意事项
-
数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的,不能动态变化。
-
var arr []int这时arr就是一个slice切片.
-
数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用。
-
数组创建后,如果没有赋值,有默认值数值类型数组:
1)默认值为0
2)字符串数组:默认值为""
3)bool数组:默认值为 false
-
使用数组的步骤
1)声明数组并开辟空间
2)给数组各个元素赋值
3)使用数组
-
数组的下标是从0开始的。
-
数组下标必须在指定范围内使用,否则报panic:数组越界,比如var arr [5]int则有效下标为0-4
-
Go的数组属值类型,在默认情况下是值传递,因此会进行值拷贝。数组间不会相互影响
-
如想在其它函数中,去修改原来的数组,可以使用引用传递(指针方式)
-
长度是数组类型的一部分,在传递函数参数时需要考虑数组的长度,
随机生成五个数,并反转打印
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
//随机生成五个数,并反转打印
//随机生成,rand.Intn()函数
rand.Seed(time.Now().UnixNano())
var intArr [5]int
for i := 0; i < len(intArr); i++ {
intArr[i] = rand.Intn(100)
}
fmt.Println(intArr)
for i := 0; i < len(intArr)/2; i++ {
intArr[len(intArr)-1-i], intArr[i] = intArr[i], intArr[len(intArr)-1-i]
}
fmt.Println(intArr)
}
切片
- 切片的英文是slice
- 切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递的机制。
- 切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度len(slice)都一样。
- 切片的长度是可以变化的,因此切片是一个可以动态变化数组。切片定义的基本语法: var 变量名 []类型 比如: var a [] int
package main
import "fmt"
func main() {
var inArr [5]int = [...]int{1, 22, 33, 44, 5}
slice := inArr[1:3] //引用intArr数组的起始下表为1,最后的下标为3,但不包含3
fmt.Println("intArr=", inArr)
fmt.Println("slice 的元素是=", slice) //22 33
fmt.Println("slice 的元素个数=", len(slice)) //2
fmt.Println("slice 的容量 = ", cap(slice)) // 切片的容量是可以动态变化的
}

切片使用的方式
第一种方式:定义一个切片,然后让切片去引用一个已经创建好的数组,比如前面的案例就是这样的。
第二种方式:通过make来创建切片。语法: var 切片名 []type = make([]type,len,[cap]),cap可以不写,写了cap>=len
package main
import "fmt"
func main() {
var slice []float64 = make([]float64, 5, 10)
slice[1] = 10
slice[3] = 20
fmt.Println(slice)
fmt.Println(len(slice))
fmt.Println(cap(slice))
}
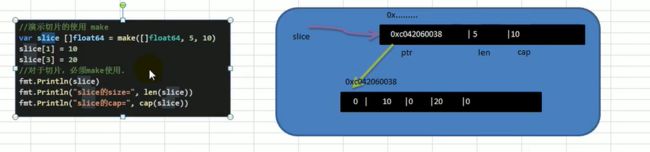
1)通过make方式创建切片可以指定切片的大小和容量
2)如果没有给切片的各个元素赋值,那么就会使用默认值[int , float=> 0 string ="" bool =>false]
3)通过make方式创建的切片对应的数组是由make底层维护,对外不可见,

第3种方式:定义一个切片,直接就指定具体数组,使用原理类似make的方式。
package main
import "fmt"
func main() {
var slice []string = []string{"tom", "jack", "mary"}
fmt.Println("slice=", slice)
fmt.Println(len(slice)) //3
fmt.Println(cap(slice))
}
切片的遍历
package main
import "fmt"
func main() {
//使用常规的for循环遍历切片
var arr [5]int = [...]int{10, 20, 30, 40, 50}
slice := arr[1:4]
for i := 0; i < len(slice); i++ {
fmt.Printf("slice[%v]=%v\n", i, slice[i])
}
//for -range方式遍历
for i, v := range slice {
fmt.Printf("slice[%v]=%v\n", i, v)
}
}
切片的细节说明

append内置函数
可以对切片进行动态追加
package main
import "fmt"
func main() {
//append**可以对切片进行动态追加**
var slice []int = []int{100, 200, 300}
fmt.Println(slice)
slice = append(slice, 400, 500, 600)
slice = append(slice, slice...)
fmt.Println(slice)
}
切片append操作的底层原理分析
- 切片append操作的本质就是对数组扩容
- go底层会创建一下新的数组newArr(安装扩容后大小)
- 将slice原来包含的元素拷贝到新的数组newArr
- slice重新引用到newArr
- 注意newArr是在底层来维护的,程序员不可见.
切片的拷贝
切片才可以拷贝
package main
import "fmt"
func main() {
//切片的拷贝
var slice []int = []int{1, 2, 3, 4, 5}
var slice2 = make([]int, 10)
copy(slice2, slice)
fmt.Println("slice =", slice)
fmt.Println("slice2 =", slice2)
}
- copy(para1,para2)参数都是切片
- 两个切片的数据空间是独立的,相互不影响
两个切片长度大小不同的拷贝,不会影响,大长度的可以拷贝到小长度的切片,多于的部分会舍弃
切片是引用类型
string和slice的关系
1.string底层是一个byte数组,因此string也可以进行切片处理。
package main
import "fmt"
func main() {
//string底层是一个byte数组,因此string也可以进行切片处理。
str := "hellojt"
//使用切片处理获取jt
slice := str[5:]
fmt.Println(slice)
}
2.string和切片在内存的形式

3.string是不可变得,也就是不能通过str[0]='z’方法来修改字符串
4.如果需要修改字符串,可以先将string ->[]byte/或者[]rune ->修改-→>重写转成string
package main
import "fmt"
func main() {
//string底层是一个byte数组,因此string也可以进行切片处理。
//将h该为z
str := "hellojt"
arr1 := []byte(str)
arr1[0] = 'z'
str = string(arr1)
fmt.Println(str)
//细节,我们转成[]byte后,可以处理英文和数字,但是不能处理中文
//原因是[]byte字节来处理,而一个汉字,是3个字节,因此就会出现乱码
//将string转出 []rune即可,[]rune是按照字符处理的,兼容汉字
arr2 := []rune(str)
arr2[0] = '江'
str = string(arr2)
fmt.Println(str)
}
排序
内部排序
指将需要处理的所有数据都加载到内部存储器中进行排序。包括(交换式排序法、选择式排序法和插入式排序法);
外部排序法:
数据量过大,无法全部加载到内存中,需要借助外部存储进行排序。包括(合并排序法和直接合并排序法)。
交换排序:
1)冒泡排序
2)快速排序
交换式排序属于内部排序法,是运用数据值比较后,依判断规则对数据位置进行交换,以达到排序的目的。
冒泡排序
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从后向前(从下标较大的元素开始),依次比较相邻元素的排序码,若发现逆序则交换,使排序码较小的元素逐渐从后部移向前部(从下标较大的单元移向下标较小的单元),就象水底下的气泡一样逐渐向上冒。
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志flag判断元素是否进行过交换。从而减少不必要的比较(优化)。

package main
import "fmt"
//冒泡排序
func BubbleSort(arr *[5]int) {
temp := 0 //临时变量
for j := 0; j < len(*arr)-1; j++ {
for i := 0; i < len(*arr)-1-j; i++ {
if (*arr)[i] > (*arr)[i+1] {
temp = (*arr)[i]
(*arr)[i] = (*arr)[i+1]
(*arr)[i+1] = temp
}
}
}
}
func main() {
//定义数组
arr := [5]int{24, 69, 88, 57, 13}
BubbleSort(&arr)
fmt.Println(arr)
}
查找
顺序查找
package main
import "fmt"
func main() {
names := [4]string{"白眉鹰王", "金毛狮王", "紫衫龙王", "青翼蝠王"}
var heroName = ""
fmt.Println("请输入要查找的人名...")
fmt.Scanln(&heroName)
//顺序查找:第一种
for i := 0; i < len(names); i++ {
if heroName == names[i] {
fmt.Printf("找到%v,下标%v", heroName, i)
break
} else if i == len(names)-1 {
fmt.Println("没有找到")
}
}
//顺序查找:第二种
index := -1
for i := 0; i < len(names); i++ {
if heroName == names[i] {
index = i
break
}
}
if index != -1 {
fmt.Printf("找到%v,下标%v", heroName, index)
} else {
fmt.Println("没有找到")
}
}
二分查找(该数组有序)

package main
import "fmt"
//二分查找
func BinaryFind(arr *[6]int, leftIndex int, ringIndex int, findVal int) {
if leftIndex > ringIndex {
fmt.Println("找不到")
return
}
middle := (leftIndex + ringIndex) / 2
if (*arr)[middle] > findVal {
BinaryFind(arr, leftIndex, middle-1, findVal)
} else if (*arr)[middle] < findVal {
BinaryFind(arr, middle+1, ringIndex, findVal)
} else {
fmt.Printf("找到了%v,下标%v\n", findVal, middle)
}
}
func main() {
//定义数组
arr := [6]int{1, 8, 10, 89, 1000, 1234}
BinaryFind(&arr, 0, len(arr)-1, 1000)
}
二维数组

二维数组的遍历
双层for循环完成遍历
//for循环遍历
for i := 0; i < len(arr); i++ {
for j := 0; j < len(arr[i]); j++ {
fmt.Printf("%v\t", arr[i][j])
}
fmt.Println()
}
for-range方式完成遍历
//for-range
for i, v := range arr {
for j, v2 := range v {
fmt.Printf("arr[%v][%v]=%v\t", i, j, v2)
}
fmt.Println()
}
package main
import "fmt"
func main() {
//二维数组的遍历
var arr [2][3]int = [2][3]int{{1, 2, 3}, {4, 5, 6}}
//for循环遍历
for i := 0; i < len(arr); i++ {
for j := 0; j < len(arr[i]); j++ {
fmt.Printf("%v\t", arr[i][j])
}
fmt.Println()
}
//for-range
for i, v := range arr {
for j, v2 := range v {
fmt.Printf("arr[%v][%v]=%v\t", i, j, v2)
}
fmt.Println()
}
}
map
map是key-value数据结构,又称为字段或者关联数组。类似其它编程语言的集合,在编程中是经常使用到。
基本语法
var map变量名 map [keytype]valuetype
key可以是什么类型
golang中的map,的 key可以是很多种类型,比如 bool,数字,string,指针,channel ,还可以是只包含前面几个类型的接口,结构体,数组,通常为int . string
value可以是什么类型
value的类型和key基本一样,通常为:数字(整数,浮点数),string,map,struct
声明是不会分配内存的,初始化需要make ,分配内存后才能赋值和使用。
package main
import "fmt"
func main() {
var a map[string]string
//在使用map前,需要先make , make的作用就是给map分配数据空间
a = make(map[string]string, 10)
a["no1"] = "dasd"
a["no2"] = "sad"
fmt.Println(a)
}
- map在使用前一定要make
- map的key是不能重复,如果重复了,则以最后这个key-value为准
- map的value是可以相同的
- map是无序的
map使用方式
package main
import "fmt"
func main() {
//map的使用
//方式一:
var a map[string]string
a = make(map[string]string, 10)
a["no1"] = "adc"
a["no2"] = "ap"
fmt.Println(a)
//方式二:
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "上海"
fmt.Println(cities)
//方式三
heroes := map[string]string{
"hero1": "宋江",
"hero2": "宋江2",
}
fmt.Println(heroes)
}
map的增删改查操作
map增加和更新
map[“key”] = value ll如果key还没有,就是增加,如果key存在就是修改。
map的删除
delete(map,“key”),delete是一个内置函数,如果key存在,就删除该key-valge,如果key不存在,不操作,但是也不会报错
1)如果我们要删除map的所有key ,没有一个专门的方法一次删除,可以遍历一下key,逐个删除
2)或者map = make(…),make一个新的,让原来的成为垃圾,被gc回收
map的查找
//查找
val, ok := cities["no1"] //也可以只返一个val值
fmt.Println(val)
fmt.Println(ok)//ok是true/false
map的遍历
map的遍历使用for-range的结构遍历
package main
import "fmt"
func main() {
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "上海"
fmt.Println(cities)
//for-range遍历
for k, v := range cities {
fmt.Printf("%v,%v\n", k, v)
}
studentMap := make(map[string]map[string]string)
studentMap["stu1"] = make(map[string]string)
studentMap["stu1"]["name"] = "tom"
studentMap["stu1"]["sex"] = "男"
studentMap["stu1"]["address"] = "四川"
studentMap["stu2"] = make(map[string]string)
studentMap["stu2"]["name"] = "mary"
studentMap["stu2"]["sex"] = "女"
studentMap["stu2"]["address"] = "四川"
fmt.Println(studentMap)
//for-rang遍历
for k1, v1 := range studentMap {
fmt.Printf("k1=%v", k1)
for k2, v2 := range v1 {
fmt.Printf("\t k2=%v v2=%v\n", k2, v2)
}
fmt.Println()
}
}
map的长度
len := len(map)
fmt.Println(len)
map切片
切片的数据类型如果是map,则我们称为slice of map,map切片,这样使用则map个数就可以动态变优了。
package main
import "fmt"
func main() {
var monsters []map[string]string
monsters = make([]map[string]string, 2)
if monsters[0] == nil {
monsters[0] = make(map[string]string)
monsters[0]["name"] = "牛魔王"
monsters[0]["age"] = "500"
}
if monsters[1] == nil {
monsters[1] = make(map[string]string)
monsters[1]["name"] = "狐狸精"
monsters[1]["age"] = "500"
}
fmt.Println(monsters)
//使用append动态增加
newMonster := map[string]string{
"name": "新的妖怪",
"age": "100",
}
monsters = append(monsters, newMonster)
fmt.Println(monsters)
}
map排序
- 先将map的key 放入到 切片中
- 对切片排序
- 遍历切片,然后按照key来输出map的值
package main
import (
"fmt"
"sort"
)
func main() {
//map的排序
map1 := make(map[int]int, 10)
map1[10] = 100
map1[1] = 13
map1[4] = 56
map1[8] = 90
fmt.Println(map1)
//如果按照map的key的顺序进行排序输出
//1.先将map的key 放入到 切片中
//2.对切片排序
//3.遍历切片,然后按照key来输出map的值
var keys []int
for k, _ := range map1 {
keys = append(keys, k)
}
//排序
sort.Ints(keys)
fmt.Println(keys)
for _, k := range keys {
fmt.Printf("map1[%v] = %v \n", k, map1[k])
}
}
map细节
-
map是引用类型,遵守引用类型传递的机制,在一个函数接收map
-
map的容量达到后,再想map增加元素,会自动扩容,并不会发生panic,也就是说map能动态的增长键值对(key-value)
-
map的value也经常使用struct 类型,更适合管理复杂的数据(比前面value是一个map更好),比如value为 Student结构体