存内计算技术打破常规算力局限性
目录
前言
关于存内计算
1、常规算力局限性
2、存内计算诞生记
3、存内计算核心
存内计算芯片研发历程及商业化
1、存内计算芯片研发历程
2、存内计算先驱出道
3、存内计算商业化落地
基于知存科技存内计算开发板ZT1的降噪验证
(一)任务目标以及具体步骤
1、主模块
2、子模块(烧录时候需要用到)
3、主模块设置
4、连接效果
(二)模拟及验证结果
1、啸叫环境模拟
2、啸叫抑制效果
体验与收获
结束语
参考文献
前言
众所周知,人工智能的高速发展颠覆了人们传统的生活和工作方式,AI已经逐渐“渗透”到各个领域,与AI相关的一切也都在发生重大改变。就拿人工智能比较核心的深度学习算法来讲,它让芯片领域也发生了巨大的技术变革,比如在人工智能发展的早期,基于AI的芯片是使用传统的冯·诺依曼计算架构的,但是随着芯片存储性能的劣势逐渐凸显,使得AI芯片研发工程师们不得不采取其他新技术来规避这种缺点,这就使得存内计算应运而生。那么本文就来简单分享一下关于存内计算技术是如何打破常规算力局限性的,以及对应的存内计算芯片产品的体验分享。
关于存内计算
1、常规算力局限性
首先来了解一下冯·诺依曼计算架构,冯·诺依曼结构也称普林斯顿结构,它是一种将程序指令存储器和数据存储器合并在一起的存储器结构,是由数学家冯·诺依曼提出的计算机制造的三个基本原则:采用二进制逻辑、程序存储执行以及计算机由五个部分组成(运算器、控制器、存储器、输入设备、输出设备),这个理论体系被称为冯·诺依曼体系结构。
如果内存的传输速度跟不上CPU的性能,就会导致计算能力受到限制,也就是出现“内存墙”,比如CPU处理运算一道指令的耗时假若为1ns,但内存读取传输该指令的耗时可能就已达到10ns,这就严重影响了CPU的运行处理速度。另外,如果读写一次内存的数据能量比计算一次数据的能量多消耗几百倍,也就是说的存在的“功耗墙”。
随着近几年云计算和人工智能(AI)应用的发展,面对计算中心的数据洪流,数据搬运慢、搬运能耗大等问题成为了计算的关键瓶颈。冯·诺依曼架构由于指令和数据共享同一内存,使得处理器不能同时取指令和数据,会导致在程序执行过程中可能发生数据和指令冲突,造成处理器的等待周期,这会降低系统的执行效率和速度。这里不得不提一下存算一体,存算一体(Computing in Memory)其实就是在存储器中嵌入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算,也为后面的新的存内计算诞生埋下了伏笔。
2、存内计算诞生记
在2018年的时候,Google针对自己产品的耗能情况做了一项研究调查,发现整个系统耗能的62.7%浪费在CPU和内存的读写传输上,也就是传统冯·诺依曼架构导致的高延迟和高耗能的问题成为急需解决的问题,而其中的短板存储器成为了制约数据处理速度提高的主要瓶颈。
但是经过一系列的技术攻关,诞生的存内计算可以有效消除存储单元与计算单元之间的数据传输耗能过高、速度有限的情况,从而有效解决冯·诺依曼架构的瓶颈。而且存内计算存在多种基于不同存储介质的技术路径,比如SRAM、Flash及其它新型存储器。
3、存内计算核心
存内计算(Computing in Memory)是指将计算单元直接嵌入到存储器中,顾名思义就是把计算单元嵌入到内存当中,通常计算机运行的冯·诺依曼体系包括存储单元和计算单元两部分。在本质上消除不必要的数据搬移的延迟和功耗,从而消除了传统的冯·诺依曼架构的瓶颈,打破存储墙。据悉,存内计算特别适用于需要大数据处理的领域,比如云计算、人工智能等领域,最重要的一点是存内计算是基于存储介质的计算架构,而且存内计算是一种新型存储架构且轻松打破传统存储架构的瓶颈。
根据存储介质的不同,存内计算芯片可分为基于传统存储器和基于新型非易失性存储器两种。传统存储器包括SRAM, DRAM和Flash等;新型非易失性存储器包括ReRAM、PCM、FeFET、MRAM等。其中,距离产业化较近的是基于NOR Flash和基于SRAM的存内计算芯片。虽然基于各类存储介质的存算一体芯片研究百花齐放,但是各自在大规模产业化之前都仍然面临一些问题和挑战。存算一体技术在产业界的进展同样十分迅速,国内外多家企业在积极研发,例如我国台湾的台积电,韩国三星、日本东芝、美国Mythic,国内的知存科技等。
但是当前最接近产业化的主要是台积电、Mythic和知存科技。从2019年至今,台积电得益于其强大的工艺能力,已基于SRAM与ReRAM发表了一系列存算一体芯片研究成果,具备量产代工能力。Mythic已于2021年推出基于NOR Flash的存内计算量产芯片M1076,可支持80 MB神经网络权重,单个芯片算力达到25 TOPS,主要面向边缘侧智能场景。国内的知存科技于2021年发布基于NOR Flash的存内计算芯片WTM2101,是率先量产商用的全球首颗存内计算SoC芯片,已经应用于百万级智能终端设备。
存内计算芯片研发历程及商业化
1、存内计算芯片研发历程
其实早在2012年,深度学习算法在图像分类竞赛中展现出的显著性能提升,就引发了新一轮的AI热潮。而在2015年,深度学习算法对芯片的快速增长需求引发了AI芯片的创业热潮。但是拥抱AI芯片的设计者们很快就发现,使用经典的冯·诺依曼计算架构AI芯片即使在运算单元算力大幅提升,但是在存储器性能提升速度较慢的情况下,两者的性能差距越来越明显,这使得“内存墙”的问题越来越显著。
在传统计算机的设定里,存储模块是为计算服务的,因此设计上会考虑存储与计算的分离与优先级。但如今存储和计算不得不整体考虑,以最佳的配合方式为数据采集、传输和处理服务。存储与计算的再分配过程就会面临各种问题,主要体现为存储墙、带宽墙和功耗墙问题。存算一体的优势是打破存储墙,消除不必要的数据搬移延迟和功耗,并使用存储单元提升算力,成百上千倍的提高计算效率,降低成本。
其实,利用存储器做计算在很早以前就有人研究,上世纪90年代就有学者发表过相关论文,但没有人真正实现产业落地,究其原因,一方面是设计挑战比较大,更为关键的是没有杀手级应用。但是随着深度学习的大规模爆发,存内计算技术才开始产业化落地,存内计算的产业化落地历程,与知存科技创始人的求学创业经历关系密切。
2、存内计算先驱出道
2011年,郭昕婕本科毕业于北大信息科学技术学院微电子专业,本科毕业之后郭昕婕开始了美国加州大学圣塔芭芭拉分校(UCSB)的博士学业,她的导师Dmitri B.Strukov教授是存内计算领域的学术大牛,2008年在惠普完成了忆阻器的首次制备,2010年加入了美国加州大学圣塔芭芭拉分校。郭昕婕也成为了Dmitri B.Strukov教授的第一批博士生,开始了基于NOR FLASH存内计算芯片的研究。
2013年,随着深度学习的研究热潮席卷学术界,在导师的支持下,郭昕婕开始尝试基于NOR FLASH存内计算的芯片研发。耗时4年,历经6次流片,郭昕婕终于在2016年研发出全球第一个3层神经网络的浮栅存内计算深度学习芯片(PRIME架构),首次验证了基于浮栅晶体管的存内计算在深度学习应用中的效用。相较于传统冯诺伊曼架构的传统方案,PRIME可以实现功耗降低约20倍、速度提升约50倍,引起产业界广泛关注。随着人工智能等大数据应用的兴起,存算一体技术得到国内外学术界与产业界的广泛研究与应用。
在2017年微处理器顶级年会(Micro 2017)上,包括英伟达、英特尔、微软、三星、加州大学圣塔芭芭拉分校等都推出了他们的存算一体系统原型。也就是在2017年,郭昕婕就进一步攻下7层神经网络的浮栅存内计算深度学习芯片。
3、存内计算商业化落地
AIoT是存内计算技术率先落地的重点领域,因其强调人机交互,同时先进的存算存储技术以及制造业能够为其提供最短路径支持。知存科技是目前唯一实现市场规模化应用的存内计算企业,2021年发布的WTM2101芯片主要布局在语言唤醒语音活动检测(Voice Activity Detection,VAD)、语音识别、通话降噪、声纹识别等,已落地应用在嵌入式领域中,包括智能手表健康监测以及较低功耗(毫安级)的智能眼镜语音识别。
据悉,WTM2101成功开拓市场以后,知存科技重点布局的将是AI视觉领域。据官方资料,知存科技将发布首个存内计算AI视觉芯片,支持至少24Tops AI算力,支持极低功耗的图像处理和空间计算。此外,九天睿芯产品主要用于语音唤醒,或者时间序列传感器信号计算处理;定位推广可穿戴及超低功耗IOT设备;后摩智能相关芯片应用于无人车边缘端以及云端推理和培训等场景,2022年5月,后摩智能自主研发的存算一体技术大算力AI芯片跑通智能驾驶算法模型。可以预见,存内计算技术的商业化应用正在呈现百花齐放的局面,也期待这些企业能够推动我国AI算力的突破性发展,实现更多AI应用落地。
全球首个存内计算社区创立,涵盖最丰富的存内计算内容,以存内计算技术为核心,绝无仅有存内技术开源内容,囊括云/边/端侧商业化应用解析以及新技术趋势洞察等, 邀请业内大咖定期举办线下存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。
传送门:https://bbs.csdn.net/forums/computinginmemory?category=10003;
社区最新活动存内计算大使招募中,享受社区资源倾斜,打造属于你的个人品牌,点击下方一键加入。
https://bbs.csdn.net/topics/617915760

基于知存科技存内计算开发板ZT1的降噪验证
接下来是本文的重头戏,也就是直接对基于存内计算ZT1开发板的降噪验证。在开始实际操作之前,需要进行一些准备工作,本文是基于已经有ZT1开发板来讲的,主要是对开发板进行连线和配置操作。首先来看一下开发板全貌,主要分为:主模块、子模块、耳机三部分组成,具体如下所示。先来看一下知存ZT1开发板,另外需要注意,ZT1开发板目前只支持Windows系统的电脑连接关联。
(一)任务目标以及具体步骤
1、主模块
主模块的概览,如下所示。

2、子模块(烧录时候需要用到)
这里的子模块,分为正反两面,根据模块的提示字符,与主模块进行关联即可。


3、主模块设置
这里的设置主要是把开关放在对应的USB这个位置,具体如下图所示:

4、连接效果
根据上面的逐一介绍,再加上官方的指导视频,具体的板子关联效果如下所示。

(二)模拟及验证结果
在执行完上面的板子、耳机连接,以及通过数据线连接板子和电脑的之后,就是插电验证啸叫抑制的效果,在耳机连接之后,会出现高分贝杂音啸叫,接着再打开板子,杂音马上消失,这就是ZT1开发板成功啸叫抑制的结果。由于不能上传演示视频,这里只做图片说明的结果展示。
1、啸叫环境模拟
未使用ZT1开发板的,啸叫环境下,噪音环境声音:75db,啸叫:85db,具体演示局部如下所示。

打开使用ZT1开发板,直接精准啸叫抑制,时间延迟<1ms,噪音环境声音:75db,啸叫:0db,非常快,非常专业,具体演示掠影如下所示。

2、啸叫抑制效果
最后引用一下知存科技的最后啸叫抑制的对比效果,具体如下所示。
啸叫抑制前:
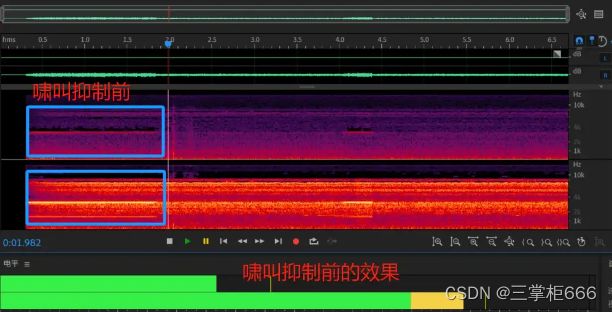
啸叫抑制后:

功耗验证:
 功耗笔测试的数据图
功耗笔测试的数据图
体验与收获
通过上面关于基于存内计算ZT1开发版的降噪验证体验,颠覆了自己对AI领域的常规认知,也是自己距离AI最近的一次,尤其通过使用知存的ZT1开发板进行啸叫抑制的测试体验,彻底让我知道存内计算的先进性和魅力,然后通过这次近距离的操作体验,让自己真真切切体验了一把AI就在我“旁边”的无距离接触。
对我自己来说,虽然AI已经火了一年多了,但是我实际接触AI的情景却不多,除了之前对一些国内外AI大模型的使用体验,还有对国内的某一个大模型进行开发使用之外,就很少接触真正的AI相关的核心内容。通过这次对知存的ZT1开发板使用体验,让我一下子就步入了AI入门水平,而且还是直接接触了AI的核心中的核心内容:存内计算,以及AI芯片,个人觉得于我来说是个非常有价值的事情,也让自己涉猎了新的核心内容,受益匪浅。
虽然这次只做了简单的使用体验,没有深度的参与开发板的烧录等实践,但是这已经非常不错了,成功的操作体验也让我对AI领域有了更浓厚的兴趣,也让我很有成就感,更重要的是这次使用体验让我感受到了AI对硬件领域的技术影响巨大,倒逼传统技术模式的变革,尤其是AI芯片等领域的快速发展。
经过本次的使用体验,也让我加深了一些人工智能知识的掌握,以及对知存的ZT1开发板的深度了解,为我后面使用知存的ZT1开发板烧录体验以及更多存内计算开发奠定基础。虽然我自己现阶段关于AI的学习和掌握还停留在入门水平,但是在这次体验实践之后,未来可能在AI硬件和软件领域都会有更深入的使用和学习。
结束语
通过上文的详细介绍和体验分享,想必读者对传统的冯·诺依曼计算架构的局限性以及存内计算技术的明显优势都有了深入的体会吧。存内计算的独有优势也是给AI芯片计算带来了不可估量的优势,解决了影响算力的大问题,非常值得表扬。随着AI的快速发展,诞生的存内计算可以有效消除存储单元与计算单元之间的数据传输耗能过高、速度有限的情况,从而有效解决冯·诺依曼架构的瓶颈。知存科技的基于存内计算ZT1开发版的降噪验证,也是给人工智能领域带来了强心剂,从个人使用体验来讲,这是一个非常棒的经历,切实感受到了它的强大功能及特点。我相信,在不久的以后关于人工智能的新技术还会相继而出,也希望人工智能领域继续完善和发展,也期待存内计算再创新的辉煌,也预祝知存科技的相关技术更上一层楼!
参考文献
1、存内计算的使用手册:WTM2101 EVB(ZT1)用户使用手册V1.1
2、存内计算芯片研究进展及应用_郭昕婕
3、中国移动研究院完成业界首次忆阻 器存算一体芯片的端到端技术验证 - 移动通信网