【大模型】大语言模型前沿技术系列讲座-学习笔记2:Transformer ->ChatGPT
最近参加了深蓝学院举办的 《大型语言模型前沿技术系列分享》,该系列分享以大模型(LLM)为背景,以科普、启发为目的,从最基本的Transformer开始讲起,逐步涉及一些更高阶更深入的课题,涵盖大模型基础、大模型对齐、大模型推理和大模型应用等内容。
系列讲座的内容由浅入深,讲解非常细致,没有任何水分,很适合我这种NLP刚入门的小白,听了这些讲座之后感觉收获满满
8.26 讲座安排(实际时长17:30-21:30)

本篇博客记录第二个讲座:《Transformer->ChatGPT》
文章目录
- 1. 语言模型 (Language Model)
-
- 1.1. 如何构建语言模型?
- 1.2. 理解ChatGPT的关键 (自回归)
- 2. GPT (Generative Pre-training) 基础
-
- 2.1. 什么是Attention?
- 2.2. 什么是Self-Attention?
- 2.3. 如何改进Self-Attention?
- 2.4. 什么是Multi-Head Attention?
- 3. Transformer Block
-
- 3.1. 位置编码 (Position Embedding)
- 3.2. 掩码 (Masking)
- 3.3. 如何解码 (decode)?
- 4. GPT
-
- 4.1. GPT 发展历程
- 4.2. 论文/报告/讨论/工具箱
- 4.3. 未来研究方向
- 5. 直播间问题
1. 语言模型 (Language Model)
大模型-大的语言模型,学习大模型之前必须了解什么是语言模型
语言模型可视为一个函数,输入是一个句子,输出是一个分数,此分数是评估所输入的句子是人说的话的概率
判断是不是句子,基于当前的词预测下一个词
语言模型本身是统计模型 probability of a sentence

1.1. 如何构建语言模型?
最朴素的想法是数数,就是给定大量语料,然后数输入的句子在语料中出现的次数
问题:语料可能比较稀疏(输入的句子不在语料中)-> 近似

1.2. 理解ChatGPT的关键 (自回归)
由词 x 1 , x 2 , . . . x n x_1,x_2,...x_n x1,x2,...xn 组成的序列(句子) X X X,放进语言模型得到一个概率分布 P θ ( X ) P_θ(X) Pθ(X)
语言模型构建:给定前n-1个词,估计得到第n个词

例子:

市面上大部分的大模型都是以自回归模型为基础,自回归是序列建模的一个概念,简而言之就是输入自己,然后预测自己下个位置是什么,通过i-1个词预测第i个词。
构建语言模型任务 -> 近似计算每个词的条件概率
近似 (Approximate) 计算方法:FFN / CNN / RNN / Transformer …
ChatGPT如何根据语言模型生成文本?
循环预测(将前一个输出作为后一个输入),形成序列(文本)
生成过程中有一些trick,比如防止重复输入等等,本质上都是形成决定下一个词是什么的规则
2. GPT (Generative Pre-training) 基础
GPT基础:Transformer

Transformer模块:输入长度为N的词向量,输出长度为N的词向量
如何得到第N+1个词?取出输出的最后一个词 (第N个词),线性映射然后softmax即可得到第N+1个词的概率
Transformer的一个重要模块:Multi-Head Attention 多头注意力,学习 Multi-Head Attention 之前先了解什么是 Self-Attention
2.1. 什么是Attention?
可以简单理解为加权平均
输入长度为N的词向量序列,在每个位置上对N个词向量做加权平均 (做N次),最终得到N个输出向量,每做一次加权平均,可视为对输入做了一次Attention
2.2. 什么是Self-Attention?
Self-Attention 中,加权平均用的权重 (系数) ω i j \omega_{ij} ωij 如何确定?
ω i j ′ = x i ⋅ x j \omega_{ij}'=x_i \cdot x_j ωij′=xi⋅xj
用自己的输入做点乘,作为权重(Self 的概念)

3个重要要素:Query (下图中每个位置左边的 x 2 x_2 x2)、Key (和Query做点乘计算权重的,下图中上面一层 x 1 − x 4 x_1-x_4 x1−x4)、Value (输入向量,用于平均,下图中下面一层 x 1 − x 4 x_1-x_4 x1−x4)
对于Attention,Query、Key和Value不一定都要来自于自己的
Self-Attention 的特点:上述3个要素均是来自自己的 ( x x x),没有其他

What can we get?
- The dot product returns large values when the two vectors are similar. The softmax normalises the resulting vectors;
- The output y i y_i yi is the weighted sum of all input vectors, weighted by their similarity withinput x i x_i xi;
- We have no trainable parameters.
- The input is a position invariant, having no way to represent word order.
2.3. 如何改进Self-Attention?
改进1:
Query、Key、Value 先做映射(线性变换,乘映射矩阵 W q W_q Wq, W k W_k Wk, W v W_v Wv),再做Self-Attention
Advanced Self-Attention
Every input vector x i x_i xi is used in three ways in self-attention:
- Query: compare x i x_i xi to every other vector to compute attention weights for its own output y i y_i yi;
- Key: compare x i x_i xi to every other vector to compute attention weights for the other outputs y j y_j yj;
- Value: use x i x_i xi in the weighted sum to compute every output vector based on these weights.
We can make attention more flexible by assuming separate, trainable weights for each of these roles: W q W_q Wq, W k W_k Wk,and W v W_v Wv.


改进2(Scaling the Dot Product):

计算权重先归一化(softmax),使得权重总和为1,符合概率分布,再做加权平均
进行softmax之前先缩放,除以 ( 512 ) \sqrt(512) (512),使得权重更平滑

2.4. 什么是Multi-Head Attention?
多头注意力机制——Attention多样化
Multi-head attention enables the model to jointly attend to different parts of the input.

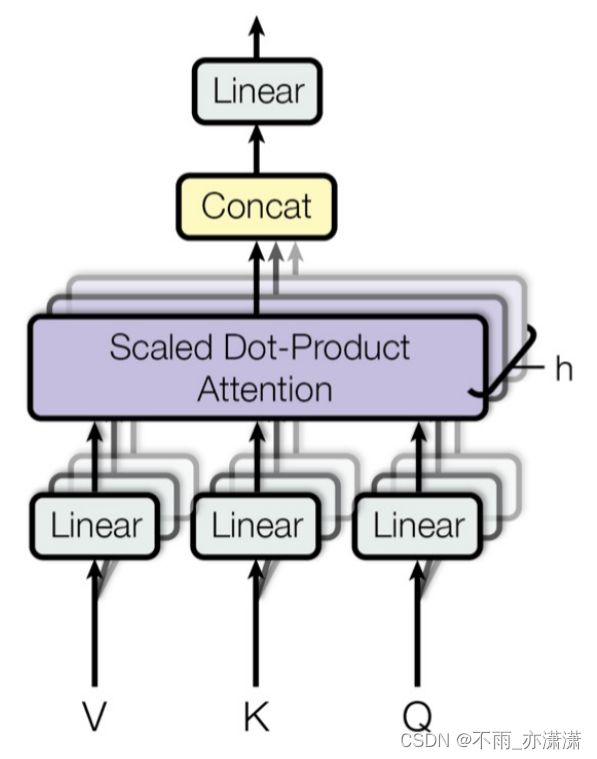
拆成h份。例如输入512向量,把512维向量拆成4份,分别做Self-Attention,y2得到4个128维向量然后拼接复原至512维。
目的:每个头都可以注意不同内容,发展多样化权重分布。
这样能提升性能,但参数变多时解码速度变慢,其中一种改进方法——Multi-Query Attention,Key和Value只共享一份,用不同的Query做Self-Attention,只拆解Query,降低计算量。
3. Transformer Block

- Self-Attention 输入输出长度一样
- 残差连接 输入加到是输出上,使得优化变得更容易
- Layer norm 层正则化,对每个正则化表示向量求均值和方差,然后减去均值除以方差,使特征更平滑
- MLP 多层感知器,简单的前馈神经网络,一般是两层

3.1. 位置编码 (Position Embedding)
原本输入顺序不影响输出,不符合实际,为了体现位置的概念,设置位置编码
Transformer 原论文提出的位置编码方案:

GPT:用可学习的向量作为位置编码
3.2. 掩码 (Masking)

为了保证能够用 i 时刻的输出预测 i+1 时刻的输入,在自回归模型中引入 Masking(掩码)

加了Masking之后,下图的 x 3 x_3 x3 将不会用于 y 2 y_2 y2 的计算输出,这样才能用 y 2 y_2 y2 预测 x 3 x_3 x3

3.3. 如何解码 (decode)?




4. GPT
4.1. GPT 发展历程
语言模型(神经网络、Transformer)
GPT 是第一个用 Transformer 模型构建语言模型
最开始 GPT (GPT-1)只是用于预训练模型,需要在下游任务做微调才能用

每个下游任务都做微调似乎不太合适,人类语言可以涵盖各种NLP任务
Problems of GPT:
- The prevalence of single task training on single dataset limits thegeneralizability. (Maybe Multi-task Learning helps?)
- Require supervised training in order to perform a task.
lntuition: Language Model == Unsupervised Multi-task Learning
lf we train language model with “the translation of the word machinelearning in Chinese is 机器学习”, then we have a machine translationsystem which can translate “machine learning” to Chinese.
We need larger model and larger dataset.
GPT-2 相比于 GPT-1,堆叠更多的 Transformer Block,参数量变大,层级变多
把 NLP 任务建模成语言模型任务(文本生成任务)


不需要微调

GPT-3 训练曲线未收敛(数量级可以更大、训练时间可以更长)


- Codex: 加入代码数据
- WebGPT: 模拟人类浏览网页
- InstructGPT: ChatGPT 的前身,让语言模型遵循人类的指令,流程如下:
收集高质量文本补全结果(数据量不大)-> 微调 -> 收集更多数据进行 RLHF (训练奖励模型,对不同输出进行排序,然后用强化学习PPO算法优化)

4.2. 论文/报告/讨论/工具箱
InstructGPT 论文 https://arxiv.org/pdf/2203.02155.pdf

Deepmind 发布的技术报告 https://www.deepmind.com/blog/building-safer-dialogue-agents
讨论:


工具箱:

4.3. 未来研究方向

如何收集数据?
GPU机器维护、GPU提速
其他模型
MOE

不同前馈神经网络(FFN)(称为专家),用Router(路由)选择不同的FFN
更快地让参数量达到更大级别,但优化难度增加
有传闻 GPT-4 是 MOE 模型
一般而言,模型参数量变大,计算量增大,生成每个词的速度变慢(硬件限制),推理速度被限制,进而模型规模大小被限制
而采用 MOE 模型,在训练时可以投入更多的算力,在推理时只需要用被激活的专家做推理,减少推理时的计算量
5. 直播间问题
(1) post-layer norm和pre-layer norm有啥讲究吗?
答:下图为 post-layer norm,layer norm 在 self attention 后面
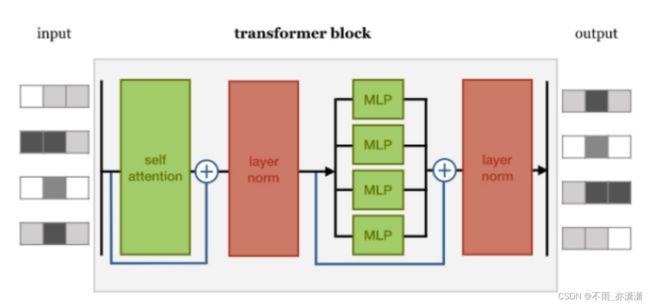
最初采用这种形式,后来发现这种结构会使得优化不稳定,进而把 layer norm 放在 self attention 前面,即 pre-layer norm。post-layer norm 和 pre-layer norm 性能差不多,但 pre-layer norm 更适合更深的模型。
(2) 使用multi-head attention会减少参数量吗?
答:不会。拆成h份之后,Q、K、V映射的矩阵仍然是一样的大小。
(3) query value key这三个矩阵每次是随机生成的吗?
答:Query value key 是模型的训练参数,和模型其他位置的训练参数是一样的,最开始都是随机生成的。
(4) 如果想在个人笔记本先做LLM的训练,推理方面的,老师有什么工具推荐?
答:gptq(大模型量化)
Making LLMs lighter with AutoGPTQ and transformers
(5) chatgpt使用的时候将temperature=0, 为何结果还有随机性呢?
答:可以设为0,则不会有随机性。
(6) 如何计算推理到对应并发所需要的GPU?
答:Try and error
对于我这种NLP入门不久的小白来说,学这些有点吃力,先记录下来,或许以后就理解了。