论文笔记(三十六):6-DoF Pose Estimation of Household Objects for Robotic Manipulation: ... and Benchmark
6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
- 文章概括
- 摘要
- 1. 介绍
- 2. 方法
-
- A. 一组对象
- B. 3D 纹理物体模型
- C. 捕捉真实图像
- D. 用地面实况标注图像
- E. 深度校准
- F. 对称意识度量
- 3. 实验
-
- A. 注释验证实验
- B. 姿势预测基线
- C. BOP 挑战赛
- D. 详细实验
- 4. 与以前工作的关系
- 5. 结论
- 致谢
文章概括
作者:Stephen Tyree, Jonathan Tremblay, Thang To, Jia Cheng, Terry Mosier, Jeffrey Smith, and Stan Birchfield
来源:2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) | 978-1-6654-7927-1/22/$31.00 ©2022 IEEE | DOI: 10.1109/IROS47612.2022.9981838
原文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9981838
代码、数据和视频:
系列文章目录:
上一篇:
https://blog.csdn.net/xzs1210652636?spm=1000.2115.3001.5343
下一篇:
摘要
我们为已知物体的 6-DoF 姿态估计提供了一个新的数据集,重点用于机器人操纵研究。我们提出了一组玩具杂货对象,这些对象的物理实例可随时购买,且大小适合机器人抓取和操纵。我们提供了这些物体的三维扫描纹理模型(适合生成合成训练数据),以及这些物体在具有挑战性的杂乱场景中的 RGBD 图像,这些场景显示了部分遮挡、极端的光照变化、每幅图像中的多个实例以及大量不同的姿势。利用半自动化的 RGBD 与模型纹理对应关系,我们为图像标注了精确度在几毫米以内的地面实况姿势。我们还基于匈牙利赋值算法提出了一种名为 ADD-H 的新姿势评估指标,该指标对物体几何对称性具有鲁棒性,无需明确枚举。我们共享所有玩具杂货对象的预训练姿势估计器,以及它们在验证集和测试集上的基准性能。我们将该数据集提供给社区,以帮助将计算机视觉研究人员的工作与机器人专家的需求联系起来https://github.com/swtyree/hope-dataset。
1. 介绍
估计场景中物体的姿态对于机器人在制造、医疗保健、商业和家庭等多个领域的抓取和操纵非常重要。例如,在拾放任务中,机器人必须知道物体的身份和位置,才能抓取它们,避免在移动过程中与其他物体发生碰撞,并将它们与其他物体相对放置。然而,即使在今天,机器人实验室中的物体也经常被改装成靶标,如 ARTags [1] 或 AprilTags [2],以支持检测和姿势估计。之所以需要这样的改装,是因为目前还没有广泛使用的现成通用技术。
为了缩小研究实验室与真实世界场景之间的差距,许多研究人员开发了从 RGB 或 RGBD 图像中检测物体并估计其姿态的方法。最近在这个 6-DoF(“自由度”)姿态估计问题上取得了重大进展 [3]、[4]、[5]、[6]、[7]、[8]、[9]、[10]、[11]、[12]、[13]。尽管仍有许多未解决的研究问题,但基本问题已经解决。
然而,从机器人学的角度来看,另一个重要的局限性依然存在: 现有的姿态估计器都是针对大多数研究人员无法获得的物体进行训练的。从 6D 物体姿态估计 BOP 基准[14]https://bop.felk.cvut.cz/datasets/ 的综合数据集列表中不难看出这一局限性。由于无法轻松获取大多数物理对象,机器人研究人员往往无法利用已使用这些数据集训练好的姿态网络进行真正的机器人实验。
在这些现有数据集中,可以说最容易访问的是 YCB [15] 和 RU-APC [16]。然而,随着时间的推移,在商店中找到这些数据集中的匹配对象变得越来越困难。例如,尽管我们住在组建 YCB 数据集的研究人员附近,但我们一直未能找到与原物外观相匹配的糖盒(YCB 第 004 项)或明胶盒(YCB 第 009 项)。失败的原因之一是这类产品的外观不断变化。特别是,食品制造商经常会根据季节、促销或品牌更新等因素改变产品的设计。因此,在 YCB 数据集上训练的网络在应用于从商店获取的实际物品时表现出性能下降。另一个问题是,有些物品的尺寸、形状和重量对于普通机器人抓手来说并不合适。
为了解决这些问题,我们发布了用于机器人操纵研究的 6-DoF 姿态估计数据集和基准。该数据集旨在:
- 无障碍。 理想情况下,世界上的任何人都能获得实物。因此,我们选择了可以在网上购买的玩具杂货。我们还对这些物品进行了扫描,并分享了扫描得到的三维纹理模型,以帮助生成训练图像。
- 具有挑战性。 我们捕捉到的这些物体的真实图像具有以下特点: 1) 明显的遮挡和杂乱;2) 每个物体的实例数量各不相同;3) 姿势多种多样;4) 极具挑战性的照明条件。
- 准确。 我们用地面真实姿态对图像进行了仔细标注,经定量评估,标注姿态的误差在世界坐标范围内仅为几毫米。
测试和验证图像的数据集以及后者的注释可供下载。此外,BOP 基准评估服务器还计算了测试集注释的指标。我们提供了使用 DOPE [4] 和 CosyPose [3] 得出的初步结果,CosyPose 的预训练网络权重已作为现成系统发布,供机器人实验室使用,同时也是该领域进一步研究的基准方法。我们还提供三维物体网格,用于生成合成数据进行训练。我们将我们的数据集称为 “HOPE”,即 “用于姿势估计的家庭物体”。
2. 方法
本节将介绍数据集和基准背后的方法。
A. 一组对象
由于我们的目标是支持机器人操纵研究,因此这组物体必须: 1)具有一定的现实性;2)具有适当的尺寸和形状,便于各种机器人终端效应器抓取;3)便于世界各地的研究人员使用。机器人操纵的一个新兴领域是用于洗衣房或厨房日常杂务自动化的家用机器人。此类应用对于促进就地养老、辅助生活和类似的医疗保健相关挑战至关重要。虽然我们最初打算扫描杂货店里的真实物品,但我们很快意识到这种方法有几个基本限制: 1) 世界其他地区的研究人员无法广泛获得此类物品;2) 许多此类物品的反射金属特性给扫描和渲染带来了困难;3) 由于季节性营销活动的影响,现实世界中物品的表面纹理经常发生变化。同样,我们仅仅为感知研究人员提供一个数据集来设计和测试他们的算法是不够的,我们还希望为那些需要在自己的实验室中利用最新感知研究成果的机器人研究人员提供支持。因此,前者训练好的网络应能立即为后者所用。
为此,我们选择了一组 28 件玩具杂货,如图 1 所示。这些玩具在网上可以买到,总价不到 60 美元。由于它们不是真正的杂货,因此不存在易腐烂或运输问题。此外,这些物体的大小和形状都适合典型的机器人抓手,所有物体至少有一个尺寸在 2.4 厘米到 7.2 厘米之间。
.
B. 3D 纹理物体模型
每个物体都使用低成本的 EinScan-SE 台式 3D 扫描仪进行扫描,以生成纹理化的 3D 物体网格。扫描过程对物体的尺寸和材料都带来了另一个限制,因为扫描仪无法处理任何一边大于 20 厘米的物体。该软件生成的纹理贴图往往比较零碎,因此我们使用 Maya 对纹理进行了进一步细化。图 2 显示了三维纹理物体模型的合成渲染,渲染使用的是 Python-interfaced 光线跟踪库 NViSII [17]。纹理物体模型可用于生成训练数据,如 DOPE [4] 或 BlenderProc [18]。
C. 捕捉真实图像
为了获取数据集的图像,我们将真实物体放置在 10 个不同的环境中,每个环境有 5 种物体排列方式/摄像机姿势。环境如图 3 所示,其中一个环境的物体排列如图 4 所示。这 50 个不同的场景展示了各种各样的背景、杂物、姿势和光线。在某些布置中,物体被放置在其他容器(如盒子、袋子或抽屉)内,以提供额外的杂乱和部分遮挡。每个场景都使用全高清分辨率(1920 × 1080)的英特尔 RealSense D415 RGBD 摄像头采集 RGB 和深度图像。图像采集距离为 0.5 至 1.0 米,这是机器人抓取的典型距离。

在环境中摆放好物体并设置好摄像机后,我们通过开/关灯、打开窗帘等方式获取不同光照条件下的多幅图像。由于场景是静态的,注释(如下所述)不会改变,因此不需要额外的工作。通过这种方式,我们收集到了大量不同的光照条件,见图 5。
数据集共包含 50 个独特场景、238 张图像(每个场景平均有 4.8 种光照变化)和 914 个物体姿势。来自两个环境(“椅子”)和(“窗口 1”)的图像被提供为验证集的基本事实,而其余场景被保留为测试集。物体的最小和最大尺寸范围分别为 2.4-7.2 厘米和 6.8-25.0 厘米。物体的平均可见度为 83%,只有 39% 的物体处于未遮挡姿势(可见度大于 95%)。物体的摆放方向多种多样,物体距离在 39.0-141.0 厘米之间,平均距离为 73.8 厘米。
D. 用地面实况标注图像
我们通过手动识别图像与三维纹理物体模型之间的点对应关系,为数据集标注了基本真实的物体姿态。在我们注释工具的 PnP 版本中,注释者在物体模型的二维纹理图和物体出现的图像中选择对应点,然后通过 RANSAC 的 PnP 对齐三维模型和图像。另外,在 RGBD 版本中,三维纹理模型和 2.5D RGBD 深度图之间进行对应,并通过 Procrustes 对齐。RGBD 标注工具的操作速度通常较快,但在深度测量中可能会出现噪音或偏差,而 PnP 则更容易在从摄像机到物体的投影射线上出现误差。大多数标注都是使用 RGBD 工具进行的,只有在基于深度的标注效果不理想时才会使用 PnP。所有标注均由 SimTrack [19] 自动完善。然后,如有必要,再进行手动调整,直到重新投影的模型在视觉上与图像和深度图一致。
E. 深度校准
深度校准根据 Hodan 等人的研究[20],我们检查了 RealSense 摄像机的深度校准,并发现了一个很小的系统误差。我们使用 RealSense 左红外摄像机拍摄了 50 多张距离在 0.5 米到 2 米之间的棋盘图像。我们自动检测了棋盘的边角,然后使用 PnP 和摄像头的固有技术将其解射为三维图像。将得到的坐标与从 2.5D 深度图中得到的相应 3D 坐标进行比较。拟合比例因子 0.9804 将测量值之间的平均绝对差异从 19.3 毫米缩小到 7.6 毫米。数据集中的深度图像在注册为 RGB 之前,都按此系数进行了缩放。
F. 对称意识度量
平均距离(ADD)度量[21]也许是评估姿态估计的最常用、最易解释的度量,它计算的是三维物体模型中相应顶点在地面实况 ( P ˉ ) (\bar{P}) (Pˉ)和预测 ( P ^ ) (\hat{P}) (P^)姿态下的平均成对距离:
![]()
其中,![]() 是模型顶点在物体坐标系中的位置,
是模型顶点在物体坐标系中的位置,![]() 是
是![]() 。
。
由于 ADD 不考虑物体的对称性,因此它只能根据预测姿态对检测到的物体的可抓取性提供有限的洞察,因为平移误差与旋转误差受到的惩罚类似。此外,在对称物体的情况下,即使无法从输入图像中确定真实姿态,ADD 也会对预测进行惩罚。为了克服这些限制,一些研究人员采用了平均最近点距离(ADD-S)[22]:
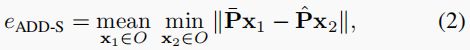
其中,地面实况模型中的每个顶点都与预测模型中最近的顶点配对,而不管与其他分配是否一致。正如本节下文所示,由于配对不真实,这一指标可能会大大低估姿态误差。
另一种处理对称性的方法是直接建立与物体相对应的对称变换集 SO 的模型。从公式 (1) 中的 ADD 开始,就可以得到平均对称性感知表面距离 (MeanSSD):
![]()
MeanSSD 需要计算或手动识别给定物体的所有有效(离散和/或连续)对称性,这对大量不同的物体来说可能是一项繁重的任务。如果将公式 (3) 中的均值算子替换为最大值,MeanSSD 就变成了 Hodan 等人提出的最大对称感知表面距离 (MSSD)[23]:
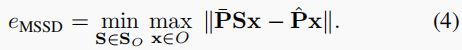
作为不准确的 ADD-S 指标和劳动密集型 MeanSSD/MSSD 指标之间的折中方案,我们提出了平均距离指标的变体,即通过解决线性和分配问题来实现地面实况和预测模型之间的顶点对应。这一赋值问题最有名的解决方案是匈牙利算法[24],因此我们用 ADD-H 表示这一指标。赋值![]() 产生了一个从预测姿态中的模型顶点到地面实况姿态中的模型顶点的双射映射。如果我们让 A = { ( f A ( x 2 ) , x 2 ) (f_{A}(\mathbf{x}_2), \mathbf{x}_2) (fA(x2),x2) }成为这种对应关系的集合,那么可以计算出使配对顶点之间的距离总和最小的集合为:
产生了一个从预测姿态中的模型顶点到地面实况姿态中的模型顶点的双射映射。如果我们让 A = { ( f A ( x 2 ) , x 2 ) (f_{A}(\mathbf{x}_2), \mathbf{x}_2) (fA(x2),x2) }成为这种对应关系的集合,那么可以计算出使配对顶点之间的距离总和最小的集合为:
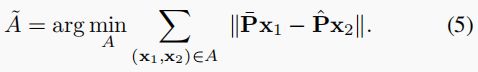
我们使用匈牙利算法(作为 scipy.optimize.linear sum 赋值实现。请注意,0.17.0 之前的 SciPy 版本使用的算法要慢得多。)的现代变体来计算式 (5)。 然后计算分配对![]()
之间的平均距离:
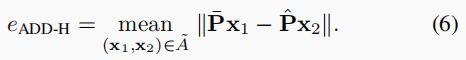
图 6 展示了在计算瓶子的真实姿态和预测姿态之间的误差时,每个度量所使用的顶点对应关系。左侧的插入渲染图描述了该场景,其中预测姿态(半透明灰色)与地面实况姿态(着色顶点)的偏移量为:绕垂直轴旋转 150 ◦,水平平移约为物体宽度的一半(3 厘米)。

图的右侧描绘了每个度量的顶点分配:每个模型![]() 中的顶点根据地面实况模型
中的顶点根据地面实况模型![]() 中的配对顶点着色。由于 ADD 使用的是基于原始顶点排序的固定双射赋值,因此误差很大。相比之下,ADD-S 会将最近的地面实况顶点分配给每个目标,从而产生非注入式映射,即只使用地面实况右侧的点,整个目标网格上的绿色和紫色就是这种非注入式映射的结果。MeanSSD 使用与 ADD 相同的顶点分配,但会明确选择误差最小的对称性保留旋转,从而使旋转排列更能代表预测中与抓取相关的几何形状。最后,ADD-H 优化了姿势之间的双射映射,以最小化误差–实现反映姿势对称性的顶点分配,这与 MeanSSD 类似。
中的配对顶点着色。由于 ADD 使用的是基于原始顶点排序的固定双射赋值,因此误差很大。相比之下,ADD-S 会将最近的地面实况顶点分配给每个目标,从而产生非注入式映射,即只使用地面实况右侧的点,整个目标网格上的绿色和紫色就是这种非注入式映射的结果。MeanSSD 使用与 ADD 相同的顶点分配,但会明确选择误差最小的对称性保留旋转,从而使旋转排列更能代表预测中与抓取相关的几何形状。最后,ADD-H 优化了姿势之间的双射映射,以最小化误差–实现反映姿势对称性的顶点分配,这与 MeanSSD 类似。
为了进一步比较这些指标,图 7 显示了 28 个 HOPE 物体中每个物体从初始位置开始以 1 厘米为增量平移时,5 次试验的平均误差。在左图中,每个物体首先通过其中一种保持对称的变换随机旋转,而在右图中,每个物体首先通过任意变换随机旋转。ADD-H 与 MeanSSD 误差非常接近,无需明确列举对象的对称性,尤其是在旋转是保持对称性的情况下。相比之下,ADD 和 ADD-S 分别明显高估和低估了误差。
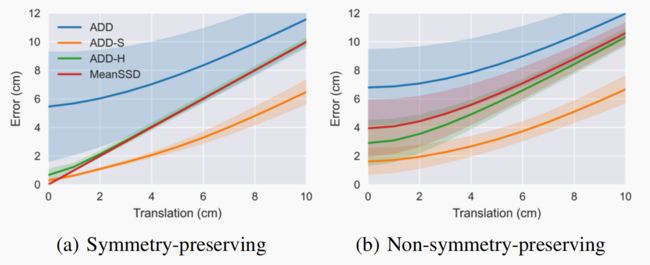
虽然 ADD-H 的计算成本比相关方法高,但通过使用高效算法来解决赋值问题,它可以应用于几百个顶点的网格。在实验中,我们使用了 500 个顶点,结果一致,计算速度也足够快。
3. 实验
我们首先介绍了一项验证实验,以检验我们标注的准确性。然后,我们提供了一个基线实验,对多个姿势检测器进行了训练,并报告了数据集的准确度指标。
A. 注释验证实验
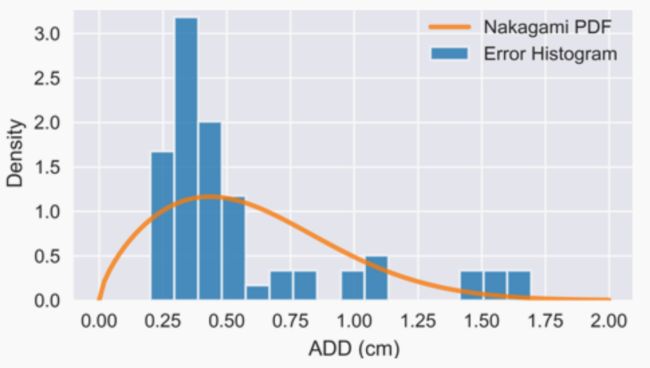
为了估算地面实况姿势标注的误差,我们拍摄了三个静态场景的正交视图(摄像机轴线之间的夹角为 90 度)。如图 8 所示,两个视图中的物体都是独立标注的。通过对除一个注释对象外的所有对象的姿势进行稳健的 Procrustes 对齐,我们估算出了两个摄像机视图之间的外特征。被遮挡物体的姿态从第一个视图投射到第二个视图,并计算出转移姿态与直接在第二个视图中进行的标注之间的 ADD 误差。通过依次重复上述过程,我们估算出了场景中所有物体的注释误差。图 9 显示了三个场景中 64 个物体实例的 ADD 直方图。ADD 的平均值和中值分别为 5.7 毫米和 4.3 毫米。因此,我们得出结论,地面实况的精确度为几毫米。
B. 姿势预测基线
我们使用深度物体姿态估计法(DPE)[4] 和 CosyPose [3],为每个物体类别训练了基线姿态预测模型,用于检测和预测 RGB 图像中的物体姿态。对于 DOPE,模型是通过使用域随机化[25]从合成图像中训练出来的。与最初的 DOPE 论文不同,我们没有使用任何逼真的渲染图像进行训练,这无疑会降低性能。因此,我们将基线称为 DOPEDR。我们考虑了 50 × 50 和 400 × 400 输出地图的两种结构变体,分别称为 DOPE-DR-50 和 DOPE-DR-400。对于 CosyPose,我们使用 BlenderProc 工具渲染的逼真图像进行训练[18]。
由于 DOPE 和 CosyPose 都是仅使用 RGB 的方法,因此这两种方法都会在从摄像机到物体的投影射线上产生误差。我们考虑了一种使用 RGB-D 点云进行细化的简单方法:在给定预测姿态的情况下,通过线搜索确定的标量因子调整预测平移,使可见模型顶点与深度图对齐。我们用"-LS "表示这种方法。CosyPose 有一个明显的优势,即可以使用来自 Mask R-CNN 检测器的物体遮罩来过滤物体网格和 RGB-D 点云,从而限制遮挡物体的影响。
C. BOP 挑战赛
表 I 显示了 BOP 基准[14]计算的三个指标下的平均召回率(AR): 最大对称表面距离(MSSD)、可见表面差异(VSD)和最大对称投影距离(MSPD)。MSSD 用于测量模型顶点的三维对齐情况,与机器人应用最为相关。VSD 可测量分别为 GT 和预测姿势渲染的二维距离图之间的差异。MSPD 测量模型顶点二维投影之间的差异,从而捕捉视觉对齐情况,并着眼于增强现实应用。
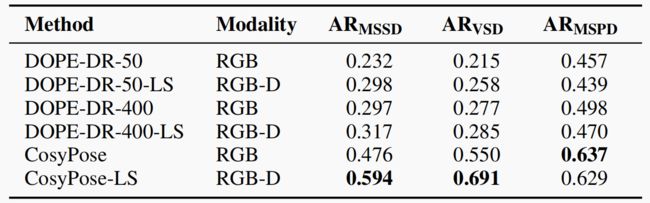
与 DOPE-400-LS 相比,CosyPose-LS 的 ARMSSD 提高了近 2 倍。此外,沿着投影射线投射到物体时所犯的错误也是一个重要的误差来源,我们简单的深度细化(-LS)所带来的巨大改进就是证明。在所有三种方法中,深度细化都显著提高了 MSSD 和 VSD 分数,其中 CosyPose 提高了 25%。由于 MSPD 对视觉对齐的细微变化非常敏感,因此尽管 3D 对齐整体上有所改善,但在深度细化后,MSPD 仍略有下降。
BOP 指标有两个方面值得注意: 1) 如前所述,BOP 对对称性的定义既要求几何相似性,也要求(近乎)精确的视觉相似性,这意味着在 BOP 挑战中,没有一个 HOPE 物体被认为是对称的;2) 召回误差阈值是根据物体大小定义的,从物体直径的 5%到 50%不等[23]。
D. 详细实验
由于我们的重点是可抓取性,因此我们使用绝对检测阈值(从 0.5 厘米到 10 厘米不等)得出了更多结果。我们还认为所有对象都是几何对称的,忽略了罐盖上的标签等小细节。为了定义几何对称性,我们将网格手动对齐到一组一致的坐标轴上,并将其分为三类:圆柱体(围绕垂直轴旋转 360◦,增量为 1◦,上下翻转 180◦)、长方体(沿任意轴翻转 180◦)和瓶子(前后翻转 180◦)。
图 10 显示了四次实验的结果,Y 轴表示地面实况对象的检测率(召回率),X 轴表示正面检测的最大误差阈值。我们展示了验证集和测试集上的结果。为了便于熟悉现有指标的人进行解释,我们使用了 MeanSSD 指标。
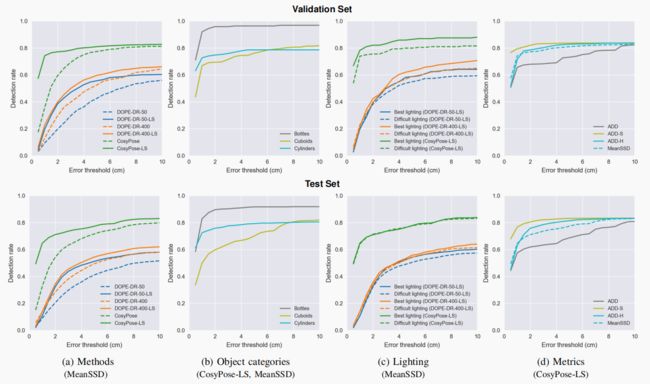
在接下来的分析中,我们特别强调了两个特定误差阈值下的性能:2 厘米和 10 厘米。较小的阈值(2 厘米)大致表示误差足以满足抓取要求,当然这也会因抓手而异。较大的阈值(10 厘米)表示的误差足以满足系统的要求,该系统能够收集检测到的物体的其他视图,以获得更精细的结果,例如,当摄像头位于机器人手部时–尽管该阈值也只是一个近似值。
图 10 (a) 使用 MeanSSD 指标对 CosyPose 和 DOPE 进行了比较。CosyPose-LS 使用逼真图像进行训练,包含视觉细化步骤,并使用我们的简单深度细化进行增强,能够预测 HOPE 测试集中 70% 以上 2 厘米以内的物体。考虑到 DOPE,图中显示了更大的输出图(DOPE-DR-400-* )–它提高了 DOPE 方法中关键点预测的精度–和线搜索深度细化(DOPE-DR-*-LS)的正交优势。通过线搜索和深度细化,HOPE 测试集中超过 30% 的物体预测结果在 2 厘米以内。
图 10 (b) 显示了 CosyPose-LS 使用 MeanSSD 指标在三个物体类别中的表现。立方体是一个特殊的挑战,因为它们对微小旋转误差的抵抗力较弱。在本数据集中,立方体也往往是较大的物体,在某些场景布置中,它们距离摄像机较远,而且位于其他物体的后面。瓶子的成功率最高,几乎 90% 的预测结果都在 2 厘米以内。
图 10 © 通过比较每个场景中最有利图像和最困难图像(主观确定)的检测率(再次使用 MeanSSD),描述了光照变化的影响。特别是在比验证集大很多的测试集上,准确率的差异很小,这表明这些经过合成训练的方法具有良好的鲁棒性。
最后,图 10 (d) 比较了使用 CosyPose-LS 预测的各种指标,证实了之前的观察结果,即 ADD-H 是一个合理的折中方案,与 MeanSSD 的结果相匹配,而无需明确枚举对象对称性。如前所述,ADD 高估了误差,而 ADD-S 低估了误差。
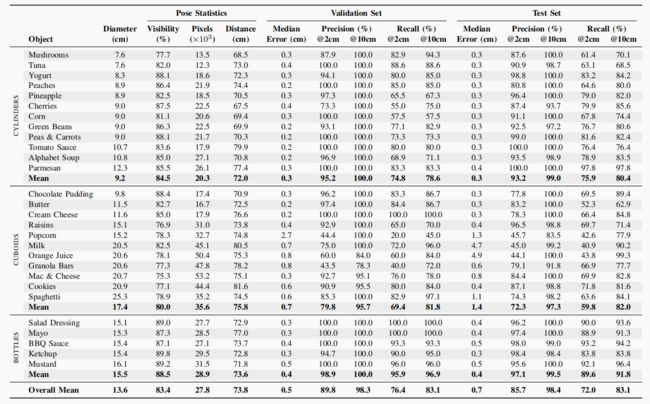
最后,表 II 利用 MeanSSD 指标详细统计了 CosyPose-LS 对每个物体类别的预测结果,以及地面实况(GT)物体姿态的一些统计数据。表中包括 10 厘米阈值内检测到的物体的 MeanSSD 误差中值,以及 2 厘米和 10 厘米阈值下的精确度和召回率。在最宽松的 10 厘米检测阈值下,CosyPose-LS 可以检测到 83% 的地面真实物体(在测试集中),而在较宽松的 2 厘米检测阈值下,CosyPose-LS 可以检测到 72% 的地面真实物体,这意味着抓取是可行的。CosyPose-LS 可以从改进的物体检测步骤中受益,因为有近 20% 的物体未被检测到。误报问题似乎不那么严重,在 10 厘米阈值下的精确度大于 98%。这些结果提供了改进的空间,同时也表明像 CosyPose 这样的现有方法可以作为现成的预测器,对这些物体进行合理成功的预测。
4. 与以前工作的关系
许多现有数据集都侧重于已知物体的 6-DoF 姿态估计任务[22]、[26]、[21]、[20]、[14]、[27]、[28]、[29]。例如,最初的 LineMOD 数据集[21]为数据集中的 15 个物体中的每个物体提供了约 1000 张图像的人工物体注释。LineMOD-Occluded 数据集由原始数据集的附加注释组成[30]。T-LESS 包含无纹理制造部件的真实图像[20]。坠物(FAT)数据集 [26] 由合成生成的随机 YCB [15] 物体图像组成,这些物体在三维场景中受到模拟重力的影响而坠落。YCB-Video 数据集提供了大量来自视频序列的图像,图像之间具有高度相关性,每幅图像平均可见五个物体[22], [31]。YCBInEOAT(“手臂末端工具”)数据集[12]包含 5 个 YCB 物体的抓取和移动视频,每次一个。DexYCB 数据集 [32] 包含人类一次抓取 20 个 YCB 物体的多摄像头视频。我们的 HOPE 数据集包含 50 个杂乱场景中的 28 个物体,每个场景有近 5 种光照变化(共 238 幅图像),每个场景平均有超过 18 个物体。HOPE 物体还出现在我们的 HOPE-Video 数据集中[33],这是一个由安装在机械臂上的摄像头捕获的 10 个 RGBD 短视频序列的集合,每个序列描述了桌面工作区中的 5-20 个物体。
最近,BOP(6D 物体姿态估计基准)挑战赛[14]提出将多个 6-DoF 姿态估计数据集组合起来,作为评估算法的核心资源。它由以下数据集组成: LineMOD [34]、LineMOD-Occluded [30]、T-LESS [20]、ITODD [35]、HomebrewedDB [36]、YCB-Video [22]、Rutgers APC [16]、IC-BIN [37]、IC-MI [38]、TUD Light [14]、Toyota Light [14],以及现在的 HOPE。随着这些 HOPE 对象的加入,我们相信该基准与机器人研究人员的关系更加密切。
5. 结论
在这项工作中,我们提供了一个可立即应用于机器人操纵研究的姿态估计基准。研究人员可以使用我们数据集所附带的三维纹理网格渲染合成图像,从而训练 28 种不同物体的姿态估计模型。这些模型可以使用我们具有挑战性的、准确注释的真实世界图像进行评估。最后,姿势预测可直接用于机器人实验室检测和操纵相同物体的物理复制品,这些复制品可随时从在线零售商处获得。我们希望这个数据集能成为计算机视觉和机器人学研究人员之间有用而实用的桥梁。
致谢
作者感谢 Tomas Hodan 在整个工作过程中提供的反馈和帮助,并感谢他将 HOPE 数据集整合到 BOP 基准中。