【软件测试】学习笔记-统一测试数据平台
这篇文章主要探讨全球大型电商企业中关于准备测试数据的最佳实践,从全球大型电商企业早期的测试数据准备实践谈起,分析这些测试数据准备方法在落地时遇到的问题,以及如何在实践中解决这些问题。其实,这种分析问题、解决问题的思路,也是推动着测试数据准备时代从1.0到2.0再到3.0演进的原因。
在这个过程中,跟着时代的演进,理解测试数据准备技术与架构的发展历程,并进一步掌握3.0时代出现的业内处于领先地位的“统一测试数据平台”的设计思路。
我们就先从数据准备的1.0时代谈起吧。
测试数据准备的1.0时代
其实,据我观察,目前很多软件企业还都处于测试数据准备的1.0时代。
这个阶段最典型的方法就是,将测试数据准备的相关操作封装成数据准备函数。这些相关操作,既可以是基于API的,也可以是基于数据库的,当然也可以两者相结合。
有了这些数据准备函数后,你就可以在测试用例内部以On-the-fly的方式调用它们实时创建数据,也可以在测试开始之前,在准备测试环境的阶段以Out-of-box的方式调用它们事先创建好测试数据。
那么,一个典型的数据准备函数长什么样子呢?我们一起来看看这段代码吧,里面的createUser函数,就是一个典型的数据准备函数了。
public static User createUser(String userName, String password, UserType userType, PaymentDetail paymentDetail, Country country, boolean enable2FA)
{
//使用API调用的方式和数据库CRUD的方式实际创建测试数据
...
}乍一看,你可能觉得,如果可以将大多数的业务数据创建都封装成这样的数据准备函数,那么测试数据的准备过程就变成了调用这些函数,而无需关心数据生成的细节,这岂不是很简单、直观嘛。
但,真的是这样吗?
这里,我建议你在继续阅读后面的内容之前,先思考一下这个方法会有什么短板,然后再回过头来看答案,这将有助于加深你对这个问题的理解。当然,如果你已经在项目中实际采用了这个方法的话,相信你已经对它的短板了如指掌了。
好了,现在我来回答这个问题。利用这种数据准备函数创建测试数据方法的最大短板,在于其参数非常多、也非常复杂。在上面这段代码中,createUser函数的参数有6个。而实际项目中,由于测试数据本身的复杂性、灵活性,参数的数量往往会更多,十多个都是很常见的。
而在调用数据准备函数之前,你首先要做的就是准备好这些参数。如果这些参数的数据类型是基本类型的话,还比较简单(比如,createUser函数中userName、password是字符串型,enable2FA是布尔型),但这些参数如果是对象(比如,createUser函数的userType、paymentDetail和Country就是对象类型的参数)的话,就很麻烦了。为什么呢?
因为,你需要先创建这些对象。更糟糕的是,如果这些对象的初始化参数也是对象的话,就牵连出了一连串的数据创建操作。
下面这段代码,就是使用createUser函数创建测试数据的一个典型代码片段。
//准备createUser的参数
UserType userType = new UserType("buyer");
Country country = new Country("US");
//准备createPaymentDetail的参数
PaymentType paymentType = new PaymentType("Paypal");
//调用createPaymentDetail创建paymentDetail对象
PaymentDetail paymentDetail = createPaymentDetail(paymentType,2000);
//对主要的部分,调用createUser产生用户数据
User user=createUser(“TestUser001”, “abcdefg1234”, userType, paymentDetail, country, true);由此可见,每次使用数据准备函数创建数据时,你都要知道待创建数据的全部参数细节,而且还要为此创建这些参数的对象,这就让原本看似简单的、通过数据准备函数调用生成测试数据的过程变得非常复杂。
那么,你可能会问,这个过程是必须的吗,可以用个某些技术手段“跳过”这个步骤吗?
其实,绝大多数的测试数据准备场景是,你仅仅需要一个所有参数都使用了缺省值的测试数据,或者只对个别几个参数有明确的要求,而其他参数都可以是缺省值的测试数据。
以用户数据创建为例,大多情况下你只是需要一个具有缺省(Default)参数的用户,或者是对个别参数有要求的用户。比如,你需要一个美国的用户,或者需要一个userType是buyer的用户。这时,让你去人为指定所有你并不关心的参数的做法,其实是不合理的,也没有必要。
为了解决这个问题,在工程实践中,就引入了如图1所示的封装数据准备函数的形式。
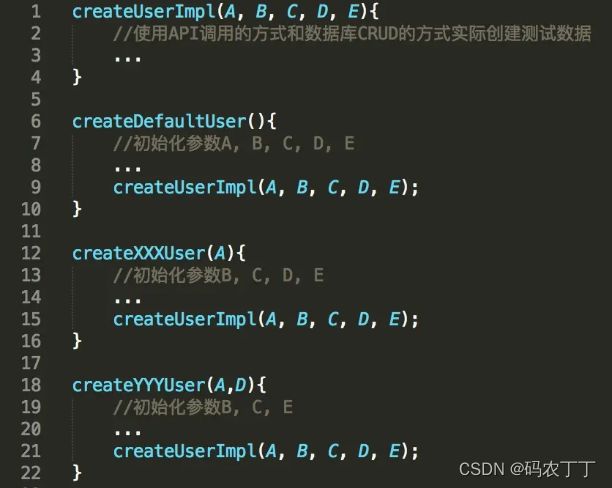
图1 数据准备函数的封装
在这个封装中,我们将实际完成数据创建的函数命名为createUserImpl,这个函数内部将通过API调用和数据库CRUD操作的方式,完成实际数据的创建工作,同时对外暴露了所有可能用到的user参数A、B、C、D、E。
接着,我们封装了一个不带任何参数的createDefaultUser函数。函数内部的实现,首先会用默认值初始化user的参数A、B、C、D、E,然后再将这些参数作为调用createUserImpl函数时的参数。
那么,当测试用例中仅仅需要一个没有特定要求的默认用户时,你就可以直接调用这个createDefaultUser函数,隐藏测试用例并不关心的其他参数的细节,此时也就真正做到了用一行代码生成你想要的测试数据。
而对于那些测试用例只对个别参数有要求的场景,比如只对参数A有要求的场景,我们就可以为此封装一个createXXXUser(A)函数,用默认值初始化参数B、C、D、E,然后对外暴露参数A。
当测试用例需要创建A为特定值的用户时,你就可以直接调用createXXXUser(A)函数,然后createXXXUser(A)函数会用默认的B、C、D、E参数的值加上A的值调用createUserImpl函数,以此完成测试数据的创建工作。
当然,如果是对多个参数有特定要求的场景,我们就可以封装出createYYYUser这样暴露多个参数的函数。
通过这样的封装,对于一些常用的测试数据组合,我们通过一次函数调用就可以生成需要的测试数据;而对于那些比较偏门或者不常用的测试数据,我们依然可以通过直接调用最底层的createUserImpl函数完成数据创建工作。可见,这个方法相比之前已经有了很大的进步。
但是,在实际项目中,大量采用了这种封装的数据准备函数后,还有一些问题亟待解决,主要表现在以下几个方面:
- 对于参数比较多的情况,会面临需要封装的函数数量很多的尴尬。而且参数越多,组合也就越多,封装函数的数量也就越多。
- 当底层Impl函数的参数发生变化时,需要修改所有的封装函数。
- 数据准备函数的JAR包版本升级比较频繁。由于这些封装的数据准备函数,往往是以JAR包的方式提供给各个模块的测试用例使用的,并且JAR会有对应的版本控制,所以一旦封装的数据准备函数发生了变化,我们就要升级对应JAR包的版本号。- 而这些封装的数据准备函数,由于需要支持新的功能,并修复现有的问题,所以会经常发生变化,因此测试用例中引用的版本也需要经常更新。
为了可以进一步解决这三个问题,同时又可以最大程度地简化测试数据准备工作,我们就迎来了数据准备函数的一次大变革,由此也将测试数据准备推向了2.0时代。
在1.0时代,为了让数据准备函数使用更方便,避免每次调用前都必须准备所有参数的问题,我和你分享了很多使用封装函数隐藏默认参数初始化细节的方法。
但是,这种封装函数的方式,也会带来诸如需要封装的函数数量较多、频繁变更的维护成本较高,以及数据准备函数JAR版本升级的尴尬。所以,为了系统性地解决这些可维护性的问题,我们对数据准备函数的封装方式做了一次大变革,也由此进入了测试数据准备的2.0时代。
测试数据准备的2.0时代
在测试数据准备的2.0时代,数据准备函数不再以暴露参数的方式进行封装了,而是引入了一种叫作Builder Pattern(生成器模式)的封装方式。这个方式能够在保证最大限度的数据灵活性的同时,提供使用上的最大便利性,并且维护成本还非常低。
事实上,如果不考虑跨平台的能力,Builder Pattern可以说是一个接近完美的解决方案了。关于什么是“跨平台的能力”,我会在测试数据准备的3.0时代中解释,这里先和你介绍我们的主角:Builder Pattern。
Builder Pattern是一种数据准备函数的封装方式。在这种方式下,当你需要准备测试数据时,不管情况多么复杂,你一定可以通过简单的一行代码调用来完成。听起来有点玄乎?没关系,看完我列举的这些实例,你马上就可以理解了。
实例一:你需要准备一个用户数据,而且对具体的参数没有任何要求。也就是说,你需要的仅仅是一个所有参数都可以采用默认值的用户。那么,在Builder Pattern的支持下,你只需要执行一行代码就可以创建出你需要的这个所有参数都是默认值的用户了。这行代码就是:
UserBuilder.build();实例二:你现在还需要一个用户,但是这次需要的是一个美国的用户。那么这时,在Builder Pattern的支持下,你只用一行代码也可以创建出这个指定国家是美国,而其他参数都是默认值的用户。这行代码就是:
UserBuilder.withCountry("US").build();实例三:你又需要这样一个用户数据:英国用户,支付方式是Paypal,其他参数都是默认值。那么这时,在Builder Pattern的支持下,你依然可以通过一行简单的代码创建出满足这个要求的用户数据。这行代码就是:
UserBuilder.withCountry("US").withPaymentMethod("Paypal").build();通过这三个实例,你肯定已经感受到,相对于1.0时代的通过封装函数隐藏默认参数初始化的方法来说,Builder Pattern简直太便利了。
趁热打铁,我再来和你总结一下Builder Pattern的便利性吧:
- 如果仅仅需要一个全部采用缺省参数的数据的话,你可以直接使用TestDataBuilder.build()得到;
- 如果你对其中的某个或某几个参数有特定要求的话,你可以通过“.withParameter()”的方式指定,而没有指定的参数将自动采用默认值。
这样一来,无论你对测试数据有什么要求,都可以以最灵活和最简单的方式,通过一行代码得到你要的测试数据。
在实际工程项目中,随着Builder Pattern的大量使用,又逐渐出现了更多的新需求,为此我归纳总结了以下4点:
- 有时候,出于执行效率的考虑,我们不希望每次都重新创建测试数据,而是希望可以从被测系统的已有数据中搜索符合条件的数据;
- 但是,还有些时候,我们希望测试数据必须是全新创建的,比如需要验证新建用户首次登录时,系统提示修改密码的测试场景,就需要这个用户一定是被新创建的;
- 更多的时候,我们并不关心这些测试数据是新创建的,还是通过搜索得到的,我们只希望以尽可能短的时间得到需要的测试数据;
- 甚至,还有些场景,我们希望得到的测试数据一定是来自于Out-of-box的数据。
为了能够满足上述的测试数据需求,我们就需要在Builder Pattern的基础上,进一步引入Build Strategy的概念。顾名思义,Build Strategy指的是数据构建的策略。
为此,我们引入了Search Only、Create Only、Smart和Out-of-box这四种数据构建的策略。这四类构建策略在Builder Pattern中的使用很简单,只要按照以下的代码示例指定构建策略就可以了:
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.SEARCH_ONLY.build();
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.CREATE_ONLY).build();
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.SMART).build();
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.OUT_OF_BOX).build();结合着这四类构建策略的代码,我再和你分享一下,它们会在创建测试数据时执行什么操作,返回什么样的结果:
- 当使用BuildStrategy.SEARCH_ONLY策略时,Builder Pattern会在被测系统中搜索符合条件的测试数据,如果找到就返回,否则就失败(这里,失败意味着没能返回需要的测试数据);
- 当使用BuildStrategy.CREATE_ONLY策略时,Builder Pattern会在被测系统中创建符合要求的测试数据,然后返回;
- 当使用BuildStrategy.SMART策略时,Builder Pattern会先在被测系统中搜索符合条件的测试数据,如果找到就返回,如果没找到就创建符合要求的测试数据,然后返回;
- 当使用BuildStrategy.OUT_OF_BOX策略时,Builder Pattern会返回Out-of-box中符合要求的数据,如果在Out-of-box中没有符合要求的数据,build函数就会返回失败;
由此可见,引入Build Strategy之后,Builder Pattern的适用范围更广了,几乎可以满足所有的测试数据准备的要求。
但是,不知道你注意到没有,我们其实还有一个问题没有解决,那就是:这里的Builder Pattern是基于Java代码实现的,如果你的测试用例不是基于Java代码实现的,那要怎么使用这些Builder Pattern呢?
在很多大型公司,测试框架远不止一套,不同的测试框架也是基于不同语言开发的,比如有些是基于Java的,有些是基于Python的,还有些基于JavaScript的。而非Java语言的测试框架,想要使用基于Java语言的Builder Pattern的话,往往需要进行一些额外的工作,比如调用一些专用函数等。
我来举个例子吧。对于JavaScript来说,如果要使用Java的原生类型或者引用的话,你需要使用Java.type()函数;而如果要使用Java的包和类的话,你就需要使用专用的importPackage()函数 和 importClass() 函数。
这些都会使得调用Java方法很不方便,其他语言在使用基于Java的Builder Pattern时也有同样的问题。
但是,我们不希望、也不可能为每套基于不同开发语言的测试框架都封装一套Builder Pattern。所以,我们就希望一套Builder Pattern可以适用于所有的测试框架,这也就是我在前面提到的测试准备函数的“跨平台的能力”了。
为了解决这个问题,测试数据准备走向了3.0时代。
测试数据准备的3.0时代
为了解决2.0时代跨平台使用数据准备函数的问题,我们将基于Java开发的数据准备函数用Spring Boot包装成了Restful API,并且结合Swagger给这些Restful API提供了GUI界面和文档。
这样一来,我们就可以通过Restful API调用数据准备函数了,而且由于Restful API是通用接口,所以只要测试框架能够发起http调用,就能使用这些Restful API。于是,几乎所有的测试框架都可以直接使用这些Restful API准备测试数据。
由此,测试数据准备工作自然而然地就发展到了平台化阶段。我们把这种统一提供各类测试数据的Restful API服务,称为“统一测试数据平台”。
最初,统一测试数据平台就是服务化了数据准备函数的功能,并且提供了GUI界面以方便用户使用,除此以外,并没有提供其他额外功能。如图1所示就是统一测试数据平台的UI界面。
图1 最初的统一测试数据平台UI界面
后来,随着统一测试数据平台的广泛使用,我们逐渐加入了更多的创新设计,统一测试数据平台的架构也逐渐演变成了如图2所示的样子。
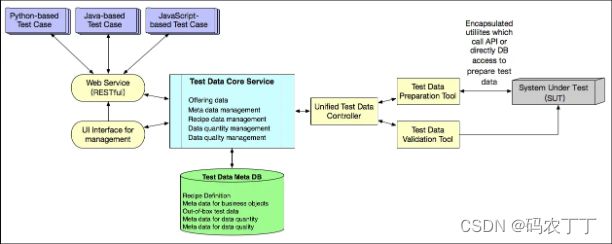
图2 演变后的统一测试数据平台架构
接下来,我和你分享一下统一测试数据平台的架构设计中最重要的两个部分:
- 引入了Core Service和一个内部数据库。其中,内部数据库用于存放创建的测试数据的元数据;Core Service在内部数据库的支持下,提供数据质量和数量的管理机制。
- 当一个测试数据被创建成功后,为了使得下次再要创建同类型的测试数据时可以更高效,Core Service会自动在后台创建一个Jenkins Job。这个Jenkins Job会再自动创建100条同类型的数据,并将创建成功的数据的ID保存到内部数据库,当下次再请求创建同类型数据时,这个统一测试数据平台就可以直接从内部数据库返回已经事先创建的数据。- 在一定程度上,这就相当于将原本的On-the-fly转变成了Out-of-box,缩短整个测试用例的执行时间。当这个内部数据库中存放的100条数据被逐渐被使用,导致总量低于20条时,对应的Jenkins Job会自动把该类型的数据补足到100条。而这些操作对外都是透明的,完全不需要我们进行额外的操作。
这就是测试数据准备的3.0时代的最佳实践了。
总结
在1.0时代,准备测试数据最典型的方法就是,将测试数据准备的相关操作封装成数据准备函数。归纳起来,这个时代的数据准备函数,主要有两种封装形式:
- 第一种是,直接使用暴露全部参数的数据准备函数,虽说灵活性最好,但是每次调用前都需要准备大量的参数,从使用者的角度来看便利性比较差;
- 第二种是,为了解决便利性差的问题,我们引入了更多的专用封装函数,在灵活性上有了很大的进步,但是也带来了可维护差的问题。
2.0时代的Builder Pattern在提供了最大限度的数据灵活性的同时,还保证了使用上的最大便利性,并且维护成本还非常低。如果不考虑跨平台能力的话,Builder Pattern已经是一个接近完美的解决方案了。
3.0时代统一测试数据平台,其实是将所有的数据准备函数在Spring Boot的支持下转变为了Restful API,为跨平台和跨语言的各类测试框架提供了统一的数据准备方案。