SQL进阶3
二、多表连结
1、什么叫联结
下面,我们举个例子来说明:
学校的安排的课程信息,我们平时都会为主要人员负责的对应课程信息创建表格,让其更好地检索得到对应数据信息。学生可以查到自己本身的课程信息,而老师也可以查到自己负责对应的课程信息。这两个表之间会有课程信息的关联。一般来说,我们将这些有关联的表,都称之为“关系表”。
如果,这时我们需要同时查询到课程信息和对应的教师信息,就要使用到联结。
联结可以在使用一条select语句中关联到多个表,然后返回我们所需要的一组数据信息。
2、创建联结
为了更好地展示,我们先创建两个表---课程表和教师表。
课程表(courses):
| 列名 | 类型 | 注释 |
|---|---|---|
| id | int unsigned | 主键 |
| name | varchar | 课程名称 |
| student_count | int | 学生总数 |
| created_at | date | 创建课程时间 |
| teacher_id | int | 讲师 id |
课程表 courses 的数据:
+----+-------------------------+---------------+------------+------------+
| id | name | student_count | created_at | teacher_id |
+----+-------------------------+---------------+------------+------------+
| 1 | Senior Algorithm | 880 | 2020-06-01 | 4 |
| 2 | System Design | 1350 | 2020-07-18 | 3 |
| 3 | Django | 780 | 2020-02-29 | 5 |
| 4 | Web | 340 | 2020-04-22 | 4 |
| 5 | Big Data | 700 | 2020-09-11 | 1 |
| 6 | Artificial Intelligence | 1660 | 2018-05-13 | 3 |
+----+-------------------------+---------------+------------+------------+教师表(teachers):
| 列名 | 类型 | 注释 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 讲师姓名 |
| varchar | 讲师邮箱 | |
| age | int | 讲师年龄 |
| country | varchar | 讲师国籍 |
教师表teachers的数据:
+------+------------------+---------------------------+------+---------+
| id | name | email | age | country |
+------+------------------+---------------------------+------+---------+
| 1 | Eastern Heretic | [email protected] | 20 | UK |
| 2 | Northern Beggar | [email protected] | 21 | CN |
| 3 | Western Venom | [email protected] | 28 | USA |
| 4 | Southern Emperor | [email protected] | 21 | JP |
| 5 | Linghu Chong | NULL | 18 | CN |
+------+------------------+---------------------------+------+---------+根据两个表之间的信息找到相关联的条件:
teachers.id=courses.teacher_id;根据相关联的条件,然后我们在使用select语句和join连接子句的语法对返回的数据信息查询。下面我先说明,join连接子句语法到底是怎么样的使用条件。
3、JOIN连接子句
JOIN连接子句用于将数据库中两个或者两个以上表中的记录组合起来。
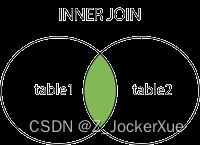
(1)INNER JOIN(内连接)
又被称为“等值连接”。
如果表中至少有一个匹配,则返回行。 简单来说,内连接就是取两个表的交集,返回的结果就是连接的两张表中都满足条件的部分。
例子:
查询课程表中的课程名称以及教师表中上的对应课程的教师名。
select c.name,t.name
from courses c
inner join teachers t on c.teacher_id=t.id;courses c 等同于courses AS c ,给courses表取别名为c;
teachers t等同于teachers AS t,给teachers表取别名为t;
inner join也可写作join。(inner可以省略不写)
执行输出结果:
+----+-------------------------+------------------+
| id | course_name | teacher_name |
+----+-------------------------+------------------+
| 1 | Senior Algorithm | Southern Emperor |
| 2 | System Design | Western Venom |
| 3 | Django | NULL |
| 4 | Web | Southern Emperor |
| 5 | Big Data | Eastern Heretic |
| 6 | Artificial Intelligence | Western Venom |
+----+-------------------------+------------------+(2)OUTER JOIN (外连接)
左/右/全外连接--语法:
select column1_name,column2_name,...,column3_name
from table1_name
left / right /full join table2_name
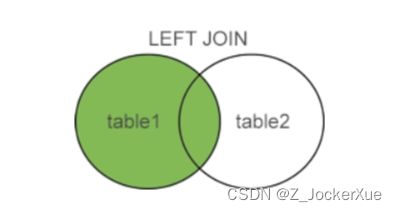
on condition;---进行匹配的条件1.LEFT JOIN(左连接)
右边的表中的数据信息没有匹配,返回左边表的所有行。简单来说,就是左外连接的结果是以左表(table1)中的所有记录为主,当右表(table2)中没有匹配的记录时,left join仍然返回行记录,只是该行的左表字段有值,右表字段用NULL填充。
返回左表中的所有记录,具体有分为以下的三种情况:
1、如果左表中的某条记录在右表中刚好只有一条记录可以匹配,那么返回的结果中会生成新的行。
2、如果左表中的某条记录在右表中有N条记录可以匹配,那么在返回结果中也会生成N行新的数据信息,这些数据信息包含左表中的字段会有重复。
3、如果左表中的某条记录在右表中没有匹配的记录,那么在返回结果中就会生成新的行,但是生成新的行的字段值都是NULL。
语法:
select table1.column1, table2.column2...
from table1
left join table2
on table1.common_column1 = table2.common_column2;--两个表的连接条件以上 SQL 语句将产生左表 (table1) 的全集,而右表( table2 )中匹配的则有值,不能匹配的则以 NULL 值取代,如下图所示:
例子:查询所有的在校教师姓名及其所教课程的名称。(teachers作为左表,courses作为右表)
select c.name as courses_name,t.name as teacher_name
from teachers t
left join courses c on
on c.teacher_id=t.id;执行输出的结果:
+------------------------+--------------------+
| course_name | teacher_name |
+------------------------+--------------------+
| Big Data |Eastern Heretic |
| Data Analysis |Eastern Heretic |
| Dynamic Programming |Eastern Heretic |
| NULL |Northern Beggar |
| System Design |Western Venom |
| Django |Western Venom |
| Artificial Intelligence|Western Venom |
| Java P6+ |Western Venom |
| Senior Algorithm |Southern Emperor |
| Web |Southern Emperor |
| Object Oriented Design |Southern Emperor |
| NULL |Linghu Chong |
+------------------------+--------------------+2.RIGHT JOIN(右连接)
左边的表中的的数据信息没有匹配,返回右边表的所有行。
右连接和左连接的实现结果是相对的。同以上的左连接的讲述。
语法:
select table1.column1, table2.column2...
from table1
right join table2
on table1.common_column1 = table2.common_column2;以上 SQL 语句将产生 table2 的全集,而 table1 中匹配的则有值,不能匹配的则以 NULL 值取代,如下图所示:

例子:查询教师名称,邮箱以及所教课程名称,课程名称的字段以courses_name作为输出,教师名称的字段以teacher_name作为输出,教师邮箱的字段以teacher_email作为输出。(“teachers”作为右表,“courses”作为左表)
select c.name as courses_name,t_name as teacher_name,t.email as teacher_email
from courses c
right join teachers t
on c.teacher_id=t.id;执行输出的结果:
+------------------------+----------------------+---------------------------+
| course_name | teacher_name | teacher_email |
+------------------------+----------------------+---------------------------+
| Dynamic Programming | Eastern Heretic | [email protected] |
| Data Analysis | Eastern Heretic | [email protected] |
| Big Data | Eastern Heretic | [email protected] |
| Dynamic Programming | Northern Beggar | [email protected] |
| Java P6+ | Western Venom | [email protected] |
| Artificial Intelligence| Western Venom | [email protected] |
| Django | Western Venom | [email protected] |
| System Design | Western Venom | [email protected] |
| Object Oriented Design | Southern Emperor | [email protected] |
| Web | Southern Emperor | [email protected] |
| Advanced Algorithms | Southern Emperor | [email protected] |
| NULL | Linghu Chong | NULL |
+------------------------+----------------------+---------------------------+(3)FULL JOIN(全连接)
只要其中的一个表中存在匹配,就返回所有行。
FULL JOIN 将左表(table1)和右表(table2)中的所有记录,相当于LEFT JOIN 和RIGHT JOIN的叠加。FULL JOIN先执行LEFT JOIN遍历左表,后执行RIGHT JOIN遍历右表,最后RIGHT JOIN 的结果直接放到LEFT JOIN后面。但是,FULL JOIN的输出结果会有重复记录的存在。
SQL Sever语法:
select column1_name,column2_name,...,columnn_name
from table1
full join table2
on table1.common_column1=table2.common_column2;以上 SQL 语句将产生 table1 和 table2 的并集,如下图所示:

例子:查询课程名称和对应的授课教师年龄。
select c.name as courses_name,t.age as teacher_age
from courses c
full join teachers t
on c.teacher_id=t.id;执行输出的结果:
+------------------------+---------------+
| course_name | teacher_age |
+------------------------+---------------+
| Advanced Algorithms | 21 |
| System Design | 28 |
| Django | 28 |
| Web Southern | 21 |
| Big Data | 20 |
| Artificial Intelligence| 28 |
| Java P6+ | 28 |
| Data Analysis Eastern | 20 |
| Object Oriented Design | 21 |
| Dynamic Programming | 20 |
| Linghu Chong | 18 |
| NULL | 21 |
| NULL | 18 |
+------------------------+---------------+(4) SELF JOIN (自连接)
很明确,一个表和自己自身进行连接。连接的表需要进行重命名,表和连接的表都独立存在。
自连接通常用于将表的某个字段与该表的同一字段的其它值进行比较。
语法:
select a.column1,b.column1...
from table1 as a,table1 as b
where a.commom_column < b.common_column;注意:
SELF JOIN 连接是通过WHERE子句达成自连接的目的。
例子:查询比某个课程的教师的年龄大的其他所有的教师.
select a.id,a.name,b.name as teacher_name,a.age,b.age as teacher_age
from teachers as a,teachers as b
where a.age > b.age;执行输出的结果:
+----------+------------------+------------+-------------------+--------------+
| id | name | age | teacher_name | teacher_age |
+----------+------------------+------------+-------------------+--------------+
| 5 | Linghu Chong | 18 | Eastern Heretic | 20 |
+----------+------------------+------------+-------------------+--------------+
| 5 | Linghu Chong | 18 | Northern Beggar | 21 |
+----------+------------------+------------+-------------------+--------------+
| 5 | Linghu Chong | 18 | Western Venom | 28 |
+----------+------------------+------------+-------------------+--------------+
| 5 | Linghu Chong | 18 | Southern Emperor | 21 |
+----------+------------------+------------+-------------------+--------------+
| 1 | Eastern Heretic | 20 | Northern Beggar | 21 |
+----------+------------------+------------+-------------------+--------------+
| 1 | Eastern Heretic | 20 | Western Venom | 28 |
+----------+------------------+------------+-------------------+--------------+
| 1 | Eastern Heretic | 20 | Southern Emperor | 21 |
+----------+------------------+------------+-------------------+--------------+
| 2 | Northern Beggar | 21 | Western Venom | 28 |
+----------+------------------+------------+-------------------+--------------+
从执行结果可以发现,SELF JOIN 以右表为主,它先将左表中的每一行与右表中的第一行进行比较,然后再将左表中的第一行与右表中的第二行进行比较,以此类推,直到右表的最后一行。
(5) CROSS JOIN(交叉连接/笛卡尔积)
两个表的数据 一 一 对应,返回的结果行数等于两个表行数的乘积。
CROSS JOIN 称为“交叉连接”或者“笛卡尔连接”。SQL CROSS JOIN 连接用于从两个或者多个连接表中返回记录集的笛卡尔积,即将左表的每一行与右表的每一行合并。
什么是笛卡尔积?
笛卡尔积(Cartesian product)是指两个集合 A 和 B 的乘积。
例如,A 集合和 B 集合分别包含如下的值:
A = {1,2}
B = {3,4,5}
A×B 和 B×A 的结果集分别表示为:
A×B={(1,3), (1,4), (1,5), (2,3), (2,4), (2,5) };
B×A={(3,1), (3,2), (4,1), (4,2), (5,1), (5,2) };
A×B 和 B×A 的结果就叫做两个集合的笛卡尔积。
从以上结果可以看出:
- 笛卡尔积不满足交换率,即 A×B≠B×A。
- 笛卡尔积的元素个数 = A 集合元素个数 × B 集合元素个数。
语法:
笛卡尔连接有两种语法,可以使用 CROSS JOIN 关键字,也可以使用不带 WHERE 子句的 SELECT FROM 命令,如下所示:
#第一种写法
select table1.column1, table2.column2...
from table1 cross join table2
#第二种写法
select table1.column1, table2.column2...
from table1, table2根据以上所述,我们举个例子来简单说明,
以下有两个表:
客户表(A):
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+订单表(B):
+-----+---------------------+-------------+--------+
|OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+然后现在我们用cross join连接子句的语法,将所要的结果进行返回。
查询客户表的序号和客户名称以及订单花费和订单日期。
select ID,NAME,AMOUT,DATE
from customers
cross join orders
on customers.ID=orders.customer_ID;或者
select ID,NAME,AMOUT,DATE
from customers
cross join orders
where customers.ID=orders.customer_ID;执行输出得到的结果:
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+----+----------+--------+---------------------+