GPT2 & GPT3
what is prompt
综述1.Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing(五星好评)
综述2. Paradigm Shift in Natural Language Processing(四星推荐)
综述3. Pre-Trained Models: Past, Present and Future
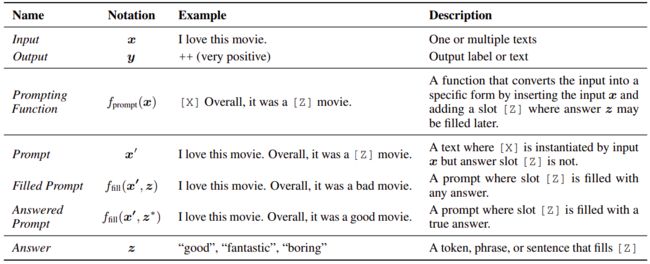
Prompt即提示学习,是继预训练+微调范式后众望所归的第四范式。在预训练+微调的范式中我们调整预训练模型来匹配下游任务数据,本质是对预训练学到的众多信息进行重新排列和筛选。而Prompt是通过引入“提示信息”,让模型回忆起预训练中学过的语言知识,也就是调整下游数据来适配预训练模型,进而把所有NLP任务都统一成LM任务。
举几个例子,以下[x]为prompt提示词,[z]为模型预测
-
分类任务: 相比情绪分类对应的多分类0~N的输出,Prompt会输出对应代表情绪的token

-
抽取任务

-
生成任务

看着非常玄妙!但其实部分原理就来自于于超大的预训练数据中包含的丰富文本知识。例如English2French的翻译任务,在预训练文本中会自然出现一些英法的对应文本如下。而提示词的加入可以理解为尝试还原模型在以下场景中的上下文(Attention)

那和预训练+微调的范式相比,Prompt有什么优势?
-
微调参数量更小:这几年模型越来越大,连微调都变成了一件很奢侈的事情,而prompt出现提供了新的选择,可以freeze模型只对提示词进行微调
-
小样本场景: 不少Prompt模型是面向zero-shot,few-shot场景设计的
-
多任务范式统一:一切皆为LM!
Prompt模型的设计主要包含以下几个模块,
-
Pretrain Model Choice:GPT等Decoder,BERT等Encoder,BART等Encoder-Decoder
-
Prompt Engineering:离散模板(文本),连续模板(embedding)的设计。模型效果对模板的敏感性,以及人工模板设计的不稳定的和难度是需要解决的问题
-
Answer Engineering: 包括答案文本的搜索,和预测文本到标签的映射。相比分类标签,Prompt范式输出的答案多为文本,因此多了一步文本到标签的解析
-
Training Strategy:主要有4种不同类型,LM和Prompt都冻结的Tunning-free,微调LM冻结Prompt,冻结LM微调Prompt,和LM+Prompt微调
我们先按照Training Strategy的不同,来梳理下各个方向的基础模型,再进阶的前沿模型,哈哈所以得花点时间才能轮到ChatGPT。第一章介绍Tunning-Free Prompt,在下游任务使用中LM和Prompt都是冻结的,不需要针对下游任务进行微调,可以用于Zero-shot和few-shot场景,主要介绍下GPT2,GPT3,LAMA和AutoPrompt。
GPT2
GPT2:Language Models are Unsupervised Multitask Learners,2019.2
任务:NLG
Prompt: Discrete + Hand crafted Prompt
核心:Language Model本身就是无监督的多任务学习
在前BERT时代,通用文本表征-GenSen就探索过通过多任务得到在不同下游任务中泛化能力更好的文本表征,而后BERT时代,MQPN,MTDNN等模型也探索过如何通过多任务学习得到更加通用的大模型。
GPT2更往前迈了一步,它认为如果语言模型足够优秀,则在拟合P(output|input)的过程中,对p(output|input,task)也会进行学习,因为NLP任务信息本身就会在丰富的预训练预料中出现,例如上面我们举的翻译的case。和GPT相比,GPT2的创新就是在“LM是无监督多任务”这个观点上,所以GPT2的评测是基于无finetune的zero-shot场景进行的,旨在证明足够优秀的语言模型是可以不经过微调直接用在不同的下游场景中的。
那如何让模型针对不同的任务给出预测呢?作者通过在原始Input上加入任务相关提示词的方式,这不prompt就来了!举个栗子
-
Translation:English = 输入 French = ?
-
Summarization:文章 + TL;DR:?,这里TL;DR是Too Long; Didn't Read的缩写,可类比咱的‘一言以蔽之‘,会出现在大段文本的末尾作为总结升华,或者对话中
几年前看GPT2的论文,只觉得模型更大了(评估是用的1542M的版本是Bert-large的5倍),样本更多了,zero-shot的能力挺新奇但是效果差点意思。如今从Prompt的角度重读,GPT2更像是在探索模型zero-shot能力的时候不小心推开了prompt的大门,从最直观的视角构建了Prompt提示词,也就是类似的任务在常规文本中是以什么形式(关键词)出现的,就以该形式构建文本输入即可~
除此之外GPT2对模型的微调以及构造了更大质量更高的数据集这里就不细说了~
GPT3
GPT3: Language Models are Few-Shot Learners, 2020.5
Making pre-trained language models better few-shot learners
任务:无所不能
Prompt: Discrete + Hand crafted Prompt + Prompt Augmentation
核心:大力出奇迹!175B大模型在few-shot,zero-shot的模型表现甚至可以比肩微调
GPT3是GPT2的延续,一方面旨在进一步提高模型的zero-shot能力,方法简单粗暴加参数就完事了!175Billion的参数首次证明了规模的量变会带来质变![Ref8]详细论证了大模型会带来一些奇迹般的能力,包括更强的复杂推理,知识推理,和样本外泛化能力!
另一方面GPT3在few-shot场景做了很多尝试,提出了自带神秘光环的in-context learning,可以被归类为multi-prompt中的prompt augmentation方案~
175Billon!

GPT3的模型结构延续GPT系列,但测试了不同模型参数量级的8个模型在不同下游任务上的效果,从125M到175B,模型效果在zero/one/few-shot的设定下都有稳步提升。在TriviaQA等任务上175B的GPT3甚至超越微调模型拿到了SOTA,算是预训练模型超越微调模型的第一次。但在NLI(判断两个句子是相似,对立,中性),WiC(判断一个单词是否在两个句子中含义相同)两个任务上GPT3的表现非常差,看起来似乎对涉及两个句子间逻辑推断的任务并不擅长。或许因为类似两个文本的逻辑推断在预训练文本中未出现过?
针对GPT3变态的模型大小,咱不聊技术垄断,OpenAI好有钱blabla我更好奇的是增长的参数究竟是如何提升模型能力?是更多的参数可以记忆更多的知识?还是更大的向量空间可以让模型学到更加线性可分的空间表征,使得下游任务对信息的解码更加简单,所以在few-shot场景有更好的表现?还没看到较严谨的论证,有知道的盆友求答疑解惑
In-context learning
论文在GPT2已有的zero-shot的基础上,提出了In-Context learning的概念,也称类比学习,上下文学习或者语境学习。有one-shot和few-shot两种方案,对应不同的增强Prompt的构建方式。随着模型参数量级的提升,few-shot,one-shot带来的效果提升更加显著。以英翻法任务为例
-
zero-shot: Prompt为任务描述

-
one-shot: Prompt Augmentation,任务描述+一个带答案的样本

-
few-shot: Prompt Augmentation,任务描述+多个带答案的样本

GPT3对其他NLP任务的prompt构建方案详见论文附录G~
对于Prompt Augmentation带来的效果提升,个人感觉in-context这个词的使用恰如其分,就是带答案的样本输入其实做了和任务描述相似的事情,也就是让待预测的输入处于和预训练文本中任务相关语料相似的上下文。带答案的样本比任务描述本身更接近自然的上下文语境。
不过prompt增强的构建还有许多细节待研究,例如抽取哪些样本更好,不同样本模型预测结果是否稳健,样本答案的构建方式,样本的顺序是否有影响等等。针对素材生成的场景没啥所谓,但是对抽取,分类,QA等任务,如果不同的prompt会得到显著不同的结果,就让人很头疼了~
[Ref6]的论文更深入的探究了in-context具体提供了哪些信息,作者定位到以下4类信息
-
输入标签的对应关系: 把样本标签改成错误标签,模型效果下降有限
-
标签分布:把标签改成随机单词,模型效果有显著下降
-
输入分布:在prompt中加入领域外文本,模型效果有显著下降
-
输入输出格式:改变双输入格式,在prompt中只保留标签或者只保留输入,模型效果都会有显著下降
GPT3正式推开了in-context learning的大门,模型参数也断层式的增长进入了Billon级别,后面的Flan,PaLM,LaMDA皆是这个大小。不过就效果而言GPT3在部分任务上依旧会被小模型T5吊打,以至于模型规模增长到底是否是正确的技术方向一度被质疑,直到之后的Chain of Thought出现才被逆转,这个放在后面章节再说~