Netty 核心源码解读 —— 开篇

谈起 Netty 现在大家都很熟悉了,它在很多中间件和平台架构里都有扮演很关键的角色,我最早了解到 Netty 是在阅读 dubbo 源码时,而后来在工作中构建平台级的 TCP 长连接网关时也主要使用到了 Netty,包括我现在负责的百亿级流量网关也主要是基于 Netty 和 Mina 搭建实现的。
Netty 是一个可用于快速开发可维护的高性能协议服务器和客户端的异步的事件驱动网络应用框架(引自 netty.io),就我个人理解,它在实现基于 TCP NIO 长链接的通信领域可以提供了强大的框架支持。所以,了解 Netty 是非常大有裨益的,推荐书籍《Netty in Action》(Norman Maurer)。
我一直认为,要想真正的 Cover 住一个框架,就一定要阅读过它的源码,否则始终是浮在表面上的。我之前读 Netty 的源码也是断断续续,也没有系统的看过,所以,这次就打算好好整理一下,对 Netty 核心组件的源码进行一次解读。
在学习 Netty 之前,一定要对 NIO 技术有一定的了解,包括 I/O 多路复用、Reactor 设计模式、Zero Copy 零拷贝等等,所谓磨刀不误砍柴工嘛。本篇文章我会先介绍一下这些知识点,然后从下篇开始就正式分析 Netty 每个核心组件的源码,而我们讨论的 Netty 核心组件有:Channel,EventLoop、EventTrigger、ChannelFuture、ChannelHandler、ChannelPipeline 和 Bootstrapping 共7个。
下面就进入本篇要点:
1、I/O 多路复用(I/O multiplexing)
先想一想,I/O 多路复用与 BIO、NIO 有什么不同?
举个例子,当用户访问 taobao.com,用户线程会将请求从用户态发送到内核态,操作系统在内核里操作网卡把数据发出去,并等待结果从网卡里返回来,而整个数据传输的过程就是一次网络 I/O 传输的过程,其中,用户线程在等待请求返回的过程中,BIO、NIO、I/O 多路复用采用的方式有所不同。
BIO 是同步阻塞 I/O,用户线程向内核发起 read 调用后就阻塞并进入休眠,直到数据从内核态拷贝到用户态,内核再把用户线程唤醒。
NIO 是同步非阻塞 I/O,与 BIO 不同的是,用户线程会不断的发起 read 调用,直到数据到了内核态,read 调用会把数据从内核态拷贝到用户态,不过用户线程在等待数据这段时间里还是阻塞的,等数据到了用户态,内核再把线程叫醒。
I/O 多路复用,与 NIO 不同的是,用户线程把 read 调用分成了两步,第一步线程先发起 select 调用,检查数据是否到了内核态,第二步如果数据到了内核态,用户线程再发起 read 调用,同样在等待数据从内核态拷贝到用户态这段时间里,线程还是阻塞的。那为啥叫 I/O 多路复用呢?这首先要清楚这个“多路”和“复用”指的是什么,其实“多路”指的是多个数据通道(或多个 Socket 套接字),而“复用”指的是复用一个或少量线程,串起来理解就是通过复用一个或少量线程来跟踪每一个 Socket(I/O 流)的状态来同时管理多个 I/O 流,具体来讲,线程一次 select 调用可以获取内核态中多个数据通道的数据状态,顾称 I/O 多路复用。
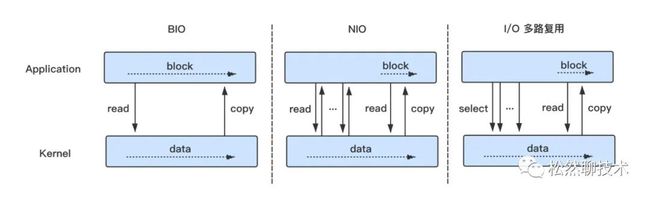
select、poll、epoll 都是 I/O 多路复用的具体实现,关键点是当有 I/O 事件发生了,如何知道这个事件是哪个 I/O 的?select、poll、epoll 都是通过将当前进程加载到对应的 fd 中,当有 fd 事件发生,调用 fd 事件回调函数,唤醒对应进程。select/poll 与 epoll 不同的是,select/poll 是在用户态管理 fd 监听列表,这就需要 select/poll 先要把监听 fd 列表从用户态传到内核态,每当 fd 有事件,唤醒当前进程,遍历 fd 全部列表,检查就绪事件,再将 fd 全部列表从内核态传回用户态;而 epoll 是在内核态管理 fd 监听列表(采用红黑树存储),epoll 通过增量式操作监听 fd,每当 fd 有事件,唤醒当前进程,会将发生事件的 fd 插入 epoll 的就绪队列,这样 epoll 就不需要遍历 fd 全部列表,只需返回就绪队列的 fd。
epoll 有两种事件模式:水平触发(Level Triggered)、边缘触发(Edge Triggered)。LT 模式下,只要有数据到达内核,就会触发 fd 事件,如果用户线程不对这个 fd 进行操作,内核会不断的将 fd 事件从内核态传回用户态,select/poll 都是 LT 模式;ET 模式下,当 fd 有事件就绪后,epoll 会将发生事件的 fd 插入 epoll 的就绪队列,epoll 会认为用户线程已操作过 fd 事件,之后就不会再触发这个 fd 事件。
Netty 的 I/O 模型就是基于非阻塞 I/O 实现的,底层依赖的是 JDK NIO 框架的 Selector(多路复用器)。一个多路复用器 Selector 可以同时轮询多个 Channel,在 JDK1.5_update10 使用了 epoll 代替 select 后(解决最大连接句柄1024/2048的限制),只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
2、Reactor 设计模式
随着 I/O 多路复用的出现,出现了很多事件处理模式。
我们已经知道了,I/O 多路复用可以复用一个或少量线程来获取多个数据通道的数据状态,当有数据处于就绪状态后,就会将就绪状态的事件分发给各读写事件的处理者,那么谁是这个事件分发者呢?这里就还需要有一个事件分发器(event dispather),它负责将读写事件源分发给对应的读写事件处理者(event handler),而涉及这个事件分发器的两种设计模式有:Reactor 和 Proactor,Reactor 采用同步 I/O, Proactor 采用异步 I/O。
Reactor 模式是将所有要处理的 I/O 事件注册到一个 I/O 多路复用器上,主线程阻塞在 I/O 多路复用器上,当有 I/O 事件准备就绪后(边沿触发或水平触发),I/O 多路复用器会将 I/O 事件通过事件分发器分发到对应的处理器中。

Reactor 模式可以细分为 Reactor 单线程模式、Reactor 多线程模式和 Reactor 主从模式,在 Netty 采用的是 Reactor 主从模式,就是我们常说的 bossGroup 和 workerGroup,bossGroup 负责处理 socket I/O 的连接事件,workerGroup 负责处理 I/O 的读写事件。
3、Zero-copy 零拷贝
零拷贝,这个概念我最早是在学习消息队列时知道的,我们知道 Kafka 和 RocketMQ 都是文件存储设计架构,在 broker 上进行消息的投递。在传统模式下,拉取消息会先从磁盘中 read 后 copy 到内核态的 kernel 缓冲区,再 copy 到用户态,然后数据再从用户态 write 到内核态的 socket 缓冲,之后内核从网卡把数据发送出去,这里,数据在内核态与用户态之间一共进行了4次拷贝,以及进行了4次用户态与内核态间的上下文切换,所以,零拷贝技术就是来解决数据在内核态与用户态之间来回拷贝的问题。
零拷贝提供 mmap、sendfile 和 gather 三种方式。
mmap+write 的方式利用了虚拟内存,将内核态和用户态的虚拟地址映射到同一个物理地址,内核态和用户态共享同一个 buffer,mmap 的核心流程就是把内核 Kernel Buffer 的数据由 CPU 直接 Copy 到 Socket Buffer 中,减少了1次数据拷贝,不过上下文的切换还是4次。RocketMQ 采用 mmap+write 的方式。
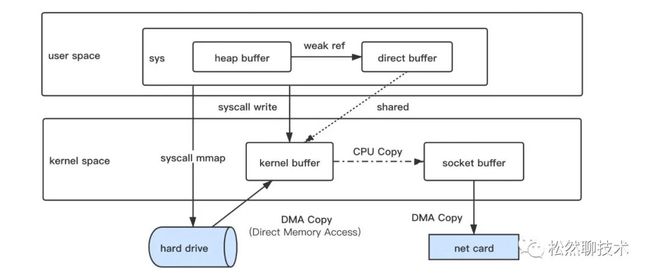
sendfile 的方式相比 mmap 都是3次数据拷贝,但是 sendfile 只有2次上下文切换,这是因为 sendfile 合并了 syscall write 和 mmap,sendfile 1次 syscall 就完成了 mmap+write 2次 syscall 的操作。Kafka 使用了 sendfile 零拷贝方式。
gather 的方式(Linux 2.4)把最后一次 CPU Copy 也去掉了,就是连 Kernel Buffer 到 Socket Buffer 的数据拷贝都不需要了,gather 的实现本质上和虚拟内存的解决思路一样,gather 是将 Kernel Buffer 的内存地址、偏移量记录到 Socket Buffer 中。
总结
本篇作为《Netty 核心源码解读》专栏的开篇,简单的介绍了 I/O 多路复用、Reactor 设计模式、Zero Copy 零拷贝等基础知识点,但很多点还不够深,在后续的文章里,我会继续与大家讨论。开篇内容不多,但足足有一个月,我仔细反复研究这些知识点的定义和原理,力求表述的准确性,但如果写的有误,还望大家给予指正。
最后,下一篇就正式开始进入《Netty 核心源码解读》专栏的第一篇:Channel,还请大家多多关注我的个人博客或公账号。