【后端】架构演进方案分析与落地实践
1. 架构师职责:
第1步: 业务需求的分析能力:
a. 对项目与业务负责,背后真实的需求是什么?
第2步: 架构设计:
a. 单机、SOA、微服务、ServiceMesh
第3步: 架构选型:
a. 语言技术栈的选型
第4步: 落地实现
2. 架构思维模型:
(1). 结合场景将静态的知识使用思维模型动态的来运用实践.
①. 如什么样的场景用什么样的数据库.
(2). 七种思维模型:
①. 业务需求至简抽象分析能力思维模型[1].
②. 哲学本质架构设计思维模型[2]:
a. 每个架构的本质的分析:
(1). 场景、优缺点、方案、资源、预期的收益等.
(2). 比较抽象,概念太大,将架构细化抽象分析,并映射成能符合的几个基本定律思考?
1. CAP定律
2. BASE定律
b. CAP架构设计思维模型[3]
c. BASE架构设计思维模型[4]
③. 根据场景Balance架构设计思维模型[5]:
a. 折中设计能力
b. 阿里的大中台方案转移到其它公司,不一定适合:
(1). 因为业务需求、量级、人员、运维、成本、新旧系统兼容不同...etc
(2). 其它因素.
c. 并不是根据潮流技术选型
d. 折中引发的"合适"架构设计思维模型[6]
(1). 适度超前半年、1年
(2). 防止过渡设计
(3). 适度超前架构设计思维模型[7]
(3). 架构设计能力:
①. 以达到以不变应万变的架构设计能力:
a. 不变的是指7种思维模型
b. 万变的是业务场景
②. 以极低的成本、更高的效率、适度超前给出优雅的架构设计方案.
(4). 架构设计哲学本质(降本增效):
①. 降低人力成本、运维成本、开发成本
②. 增加公司开发、人员、运营效率
1. 架构演进方向:
单机 => 垂直架构 => SOA => 微服务 => 中台
(1). 单体架构:
①. 表现:
a. 功能集中:
(1). 单体就会把新业务与旧业务合并在一起.
b. 同一个包发布
(1). 有bug会延缓整个团队的上线
(2). 没有并行发布效率高
c. 运行在一个进程中
②. 问题点:
a. 开发效率低:
(1). 需要排期,考虑现有业务是否有冲突、兼容
b. 功能交付周期长
c. 新人培养周期长
(2). 垂直架构(加个负载均衡,方便扩展)
(3). soa(通过service解决应用系统间集成和互通)
(4). 微服务:
①. 表现:
a. 微服务是网状结构、敏捷速度快、每个服务开发的周期就短.
b. 业务可以并行开发,而不是线行开发. => 单体架构是线行开发
②. 问题点:
a. 微服务分的太多、松散、复杂、凌乱 => 逐渐压缩成中台.
③. 考量的指标:
a. 应用体量大不大
b. 分布式服务需要更新迭代快,不同的branch需要快速的响应和部署、新业务诞生.
2. 转型:
①. 信息化转型:
a. 对单体架构进行转型
b. 主要是需要面向外部客户,来支撑企业的数字化转型.
②. 云化转型:
a. 把所有的业务变成云化体系
b. 分布式云端应用,带来更多的业务和合作.
③. 智能化转型:
a. 在产品经理的角度有很多新的feature用AI的技术来解决,但不影响前面的云化.
b. 智能化的前提是业务变的非常大,这样的架构才能支撑这么大的业务.
1.为什么做着做着服务就要分离出去?
(1). 团队一般有两种:
①. 很会找钱的老板,有认识的人脉,找到钱也不还.
②. 疯狗一样的团队.
(2). 现实是很残酷的:
往往在创业时,选择了复杂的架构,认为项目是可以走很多年的.做着做着越来越复杂,规模越来越庞大.考虑的比较乐观,而且过度设计架构了.在没有钱的时候,最好是功能迭代实现(功能的升级、功能的全面).
①. 很多创业公司的网上线,一年没几个流量.
②. 上线后一直没有盈利,2年后转型.
③. 如果找不到金主,也许倒闭.
(3). MVC的痛点:
①. 网站的所有功能,肯定有主营的功能模块.
比如java开发的,商品访问量大,而修改代码,重新编译,就要将所有代码全部编译一次.
②. 多点服务的话,可能还会有一个存储配置来专门管理config.如etd.
④. 当服务器的ip经常变,会有一个服务注册服务器consul.
2. go、php、Java承担角色:
2.1 公司混合架构:
①. PHP组:RPC调用核心库、http api与前端交互等
②. java、go核心业务组:核心业务封装、RPC微服务体系建设
③. 运维组:
④. 产品组:
⑤. 前端组:vue/react、移动端
注:
①. 核心的原因不是因为技术上不能实现(在一定的范围内),而是技术栈、第三方库的成熟度的不同.
②. 虽然grpc也可以同时发布http api,但是灵活度和可控度不如直接使用某一个语言来做.
2.2 混合语言:
(1). Go负责:
①. grpc负责核心模块的核心业务逻辑开发(订单、用户等).
如下订单下到php,具体业务处理是由php来调用grpc功能.
②. Go-Micro负责微服务体系的建设:
a. 具体调用是直连api,还是通过微服的方式consul来进行服务注册与发现是由go-micro来负责的.
b. rpc api
③. gin负责前端交互部分(订单、用户等):
a. 负责http api,取交互数据.
(2). PHP部分(swoft 2.x):
①. 负责大部分模块的数据获取API,调用go写的grpc服务.
②. 以http api为主,接入go微服务体系(sidecar):
php来调用go写的相关体系,在这个体系再转向grpc对应的地址进行调用.
分布式锁线上真实案例架构设计哲学本质解剖
1. 业务场景驱动:
①. 交易商品库锁定,防止用户重复下单.
②. MQ消息去重,防止消息重复消费:
a. 发送端去重
b. 消费端去重
③. 订单操作变更协同:
a. 在用户对商品下单后,订单状态为待支付,在某一时刻用户正在对该订单做支付操作,商家对该订单进行改价操作.
b. 其它类似状态的修改行为,也需要做串行处理,避免出现数据不一致性.
2. 业务场景共性:
(1). 共享资源:
①. 有哪些共享资源?
a. 用户、订单消息、订单.
②. 举例:
a. 比如分布式系统中,下单过程中,请求两台order服务的过程中,什么资源是可以控制的?
b. 如用户id下过单,用一种方式记录下来,再来下单的时候,就不能下单了.
c. 此时,用户id就变成一个共享资源了.
(2). 解决思路:
①. 共享资源互斥.
②. 共享资源串行化.
(3). 解决方案:
①. 在并发下,通过加锁对共享资源进行串行化.
②. 锁的问题:
a. 本地锁弊端
(1). 如果只是在分布式某一个服务加本地锁,是没有作用的.
(2). 可以使用分布式锁(集中化管理).
b. 分布式锁
(1). 只有申请共享资源通过,才能使用.否则,拒绝.
3. 基于redis的分布式锁实现方案:
redis集群,原理是因为redis单线程串行处理.
(1). SETNX方案:
①. SETNX(Set if not exists):
a. 命令在指定的key不存在时,为key设置指定的值.
b. SETNX Key Value设置成功,返回1.设置失败,返回0.
c. 没有有效期的
②. 原子操作(多个执行命令):
Multi
SETNX Key Value
expire key seconds // 设置失效时间
exec
③. 两条命令要求是原子操作:
a. 如果有可能会某一条命令失败,如expire失败了,这把锁就没有有效期,就会变成死锁.
b. 要求是要么都成功、要么都失败.
c. redis把原子性的操作变成一个lua脚本.
④. 弊端:
a. Multi不检查语义本身,导致后果是有可能一个命令执行失败.
(1). set name 'david'
incr name // 报错了,但是multi还是会执行成功.
b. 事务是不严谨的.
(2). set方案:
①. set key value NX PX milliseconds:
a. 命令在指定的key不存在时,为key设置指定的值,并设置生存时间.
②. 弊端 - 单机redis一般不会开持久化:
a. 在用户1拿到锁的时候,这个锁还没有释放,突然进程挂了.
b. 马上redis重启,内存是空的.
c. 此时,用户2又可能拿到同一把锁,存在同一把锁会被拿多次的情况.
③. 改进 - 分布式redis:
a. 一台主节点、一台从节点,主从是异步来同步数据的(不是同步的过程).
b. 用户A在主节点加锁后,会在一定时间内同步到从节点.
c. 在用户B访问时,主节点挂了,从节点会成为主节点,再去拿同一把锁,发现是存在的.
④. 疑问?
a. 当主节点锁还没有同步过从节点时,主节点挂了.
b. 此时,从节点升级为主节点,还是会产生同一把锁被拿多次的情况.
⑤. 深层次挖掘:
a. 因为锁只有能一个,所以是CP模型.
b. redis主从分布式来实现这个锁,它的模型是AP模型.
(1). 主从缓存走的是吞吐量.
c. 总结:
(1). 这个锁是CP模型,但是用的redis主从是AP模型.
(2). 所以,最终还是会达到一个锁拿两次的情况.
4. 一切架构都不能脱离业务场景来设计:
①. 短信消息场景(AP模型):
a. 利用分布式锁来对消息去重,比如发一个短信,没有锁住,重复又发了一次.
b. 只是说体验不是太好,目的最终还是达到了.
②. 交易的场景(CP模型):
a. 重复转了两次,肯定是业务不能接受的.
③. 总结:
a. 业务的容忍度决定架构的设计.
高并发下接口幂等性解决方案
1. 幂等性概念:
①. 一个幂等操作指任意多次执行所产生的影响跟一次执行的影响相同.
②. 幂等函数(幂等方法):
a. 可以使用相同参数重复执行,并能获得相同结果的函数.
b. 这些函数不会影响数据状态,也不用担心重复执行会对数据造成改变.
c. 如:"getUsername()"、"setTrue()"就是一个幂等函数.
③. 总结:
幂等就是一个操作不论执行多少次,产生的效果和返回的结果都是一样的.
2. 业务场景:
①. 前端重复提交选中的数据,后台只能产生一个反应结果.
②. 发起一笔付款请求,只能扣用户账户一次钱,当遇到网络重发或系统bug重发,也只能扣一次钱.
③. 发送短信、极光推送等消息,也只能发一次.
④. 创建业务订单,一次业务请求只能创建一个.
3. 技术场景:
(1). mysql:
①. 查询操作:
a. 在数据不变的情况下,查询一次和多次的结果是一样的.
b. select是天然的幂等操作.
②. 删除操作:
a. 删除一次和多次都是把数据删除,会体现在返回结果不一样.
b. 删除的数据不存在,返回0.
c. 删除的数据多条,返回多条值.
③. 唯一索引:
a. 防止新增脏数据.
b. 如:支付宝每个用户只能有一个资金账户,将资金账户表的用户ID加唯一索引,可以防止给用户创建资金账户多个.
c. 唯一索引或唯一组合索引是用来防止新增数据存在脏数据.
④. 悲观锁:
a. 加锁获取数据:
select * from table_xxx where id='xxx' for update;
b. 注:id字段一定是主键或唯一索引,否则会锁表.
c. 悲观锁使用时,一般伴随事务一起使用,数据锁定时间可能会很长(根据实际情况选用).
⑤. 乐观锁:
a. 只在更新数据那一刻锁表,其它时间不锁表.
b. 相对于悲观锁,效率更高.
c. 实现方式可以通过version或其他状态条件:
1. 通过版本号实现:
update table_name set name=xx, version=version+1 where id=#id# and version=xxx
2. 通过条件限制实现:
update table_name set avai_amount=avai_amount-#subAmount# where id=#id# and avai_amount-#subAmount# >= 0
要求:quality-#subQuality# >= ,这个情景适合不用版本号,只更新是做数据安全校验,适合库存模型,扣份额和回滚份额,性能更高;
d. 注:乐观锁的更新操作,最好加主键或唯一索引来更新,这样是行锁,否则更新时会锁表.
(2). redis:
```js
①. token机制:
a. 防止页面重复提交.
b. 当客户端请求页面时,服务器会生成一个随机数Token保存到redis或session中,再将Token发给客户端(hidden表单).
c. 下次客户端提交请求时,Token会随着表单一起提交到服务器端.
d. 服务器端第一次验证相同通过后,会将Token值更新,若是用户重复提交,第二次的验证判断将会失败.
(3). 分布式锁:
如果是分布是系统,构建全局唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统(redis或zookeeper),在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路。
要点:某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行完成后,释放分布式锁(分布式锁要第三方系统提供)。
1. CAP:
①. 强一致性(Consistency):
a. 数据写入后,任何一个节点都马上读最近的数据.
②. 可用性(Availability):
a. 用户在任何时间、地区都能访问这个服务.
③. 网络分区容错性(Partition tolerance):
a. 当负载的多台设备网络节点之间,在通与不通的时候,都能得到数据.
2. 分布式系统三者同时满足二者:
①. 模型:
CA、CP、AP
②. 模型:
a. CA模型一般说的是单机,其实失去意义了.
b. CP模型:
(1). 牺牲了可用性.
(2). 数据一定要是一致性的,但是可以允许短时间不可用.
c. AP模型:
(1). 牺牲的是不一致性.
(2). 对数据一致性要求一定不高,但是一定要保证可用性.
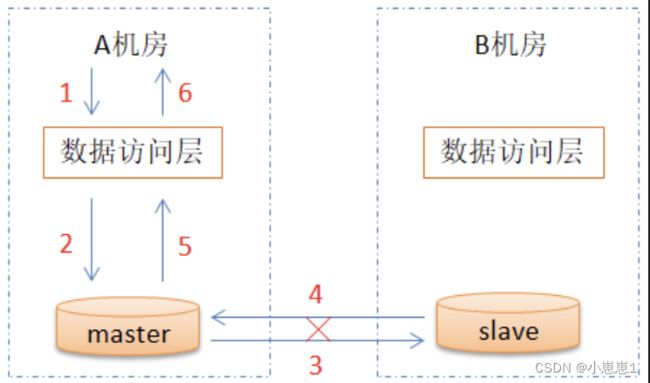
(2). 数据库更新案例:
①. 各模型:
a. C => 数据库主节点更新,从节点也要更新.
b. A => 必须保证两个数据节点都是可用的.
c. P => 当主从节点出现网络分区,必须保证系统对外可用.
②. 在数据强一致性下,整个链路分析:
a. 请求A机房的数据访问层,再到master主节点,再到solve从节点.
b. 返回master节点,再返回数据访问层.
③. 在数据强一致性下,只要主从出现网络分区,A就无法满足:
a. 假如master与slave之间网络不通了,虽然写主库可以成功,但是同步从库不成功.
b. 因为要求数据一致性,一直在等待写从库.
c. 写请求是没有办法返回的,表示这个写请求就是不可用了.
④. 前提是写DB操作的超时时间(timeout),远远小于等于网络恢复的时间.