【腾讯云HAI域探密】- HAI为NPL保驾护航
近些年,随着机器学习技术的蓬勃发展,以GPU为代表的一系列专用芯片以优越的高性能计算能力和愈发低廉的成本,在机器学习领域得到广泛认可和青睐。GPU等专用芯片以较低的成本提供海量算力,已经成为机器学习和AI人工智能领域的核心利器,在人工智能时代发挥着越来越重要的作用。
今天给大家推荐和介绍的“高性能应用服务HAI”,是一款大幅降低GPU云服务器使用门槛,多角度优化产品使用体验,开箱即用。拥有澎湃算力,即开即用。以应用为中心,匹配GPU云算力资源,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。

探讨一下如何利用“高性能应用服务HAI”进行业务场景赋能,已经是很多公司目前需要面临的问题。本文分享一下“高性能应用服务HAI”在医疗NLP体系中的实践过程,希望能通过“高性能应用服务HAI”的方案对公司的业务进行将本增效。

一、为什么在AI的领域需要使用GPU呢?
在这些领域中,GPU 可以加速训练模型、处理海量数据等计算密集型任务,显著提高了计算效率和速度。因此,GPU 已成为现代计算机的重要组成部分,被广泛应用于各种领域。
1. GPU 和 CPU 的主要区别体现在以下几个方面:
2. GPU 的工作原理:
二、“高性能应用服务HAI”能够带来什么?
2.1 什么是HAI呢?
高性能应用服务(Hyper Application Inventor,HAI)是一款面向 Al、科学计算的GPU 应用服务产品,提供即插即用的澎湃算力与常见环境。助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用,原生集成配套的开发工具与组件,大幅提高应用层的开发生产效率。
2.2 平时在使用AIGC应用的痛点:
2.3 高性能应用服务HAI可以让我们干什么?
通过“高性能应用服务HAI”的StableDiffusion模型可以进行AI绘画,是一种利用深度学习算法进行创作的绘图方式,被广泛应用于游戏、数字媒体、电影、广告设计、动画等领域,可以让设计师加快绘图相关的工作,从“人工”GC逐渐的转向AIGC人工智生产内容。
AIGC时代,企业和开发者需要的不只是GPU和大模型,还有好用、易用的服务,我们将算力和模型封装成不同形态,供企业和开发者在云上取用。
● 面向大模型训练需求,在IaaS层提供实惠大碗的HCC高性能计算集群与各类GPU算力;
● 面向数据清洗、分类、处理等需求,在PaaS层提供云原生数据湖仓和向量数据库,以及为大规模训练加速的TI平台;
● 面向模型精调、部署需求,在模型层提供腾讯混元大模型和行业模型解决方案,以及MaaS(Model-as-a-Service)一站式服务。


2.4 “高性能应用服务HAI”降本增效的结果:
2.5 “高性能应用服务HAI”全面的AI应用托管服务:
“高性能应用服务HAI”是根据应用匹配推选GPU算力资源,实现最高性价比,是面向开发者和企业的AI工程化平台,提供了覆盖数据提供、模型开发、模型训练、模型部署的全流程服务。

同时,打通必备云服务组件,大幅简化云服务配置流程,为机器学习开发的每个步骤加速创新,包括:
- 分钟级自动构建LLM、AI作画等应用环境,适合模型开发、模型训练、模型部署
- 提供多种预装模型环境,包含如StableDiffusion、ChatGLM等热门模型
- 提供开发者友好的图形界面,支持JupyterLab、WebUI等多种算力连接方,AI研究调试超低门槛。
- 学术加速为企业提供训练加速和推理加速的能力,提高AI训练和推理的速度、易用性和稳定性,极大提升AI计算的效率。

“高性能应用服务HAI”基于软硬件一体优化技术,超大规模分布式深度学习任务运行,具备高性能、高效率、高利用率等核心优势,实现AI开发及应用过程的降本增效。
三、对比GPU云服务器,高性能应用服务HAI解决的业务痛点问题:
3.1 总结优势与劣势:
3.2 高性能应用服务HAI快捷部署优势体现:
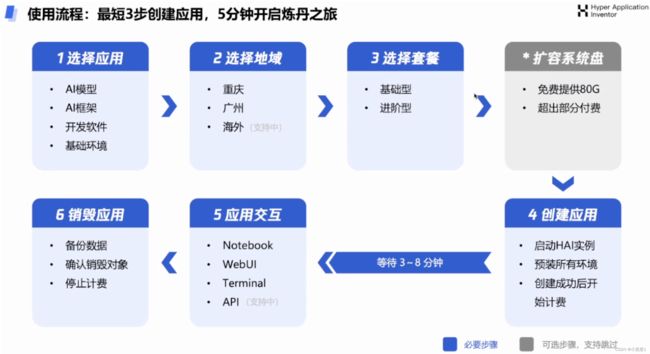
随着人工智能(AI)大模型技术的迅速发展,智能化时代正在开启,AI将成为各行各业的新型生产力,并对算力提出更高要求。
从底层算力到AI平台再到模型服务,腾讯云加大研发投入,推动腾讯云进行全面的技术升级和创新,并推出一站式大模型应用开发平台“高性能应用服务HAI”,加速推动大模型开发应用迈入“零门槛”时代。该平台极大降低大模型应用开发门槛,开发者可在5分钟内开发一款大模型应用,几小时即可“炼”出一个企业专属模型,让开发者把更多精力专注于应用创新。
“高性能应用服务HAI”为电商、外贸、企业服务、搜索、导航、文娱等多业务场景,提升产品体验与经营效率,共同塑造面向未来的新增长引擎。
3.3 高性能应用服务HAI友好的图形化交互:
3.4 高性能应用服务HAI技术优势:

小结:
高性能应用服务(Hyper Application Inventor,HAI)是一款面向 Al、科学计算的GPU 应用服务产品,提供即插即用的澎湃算力与常见环境。助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用,原生集成配套的开发工具与组件,大幅提高应用层的开发生产效率。
四、“高性能应用服务HAI”的应用场景有哪些?




五、基于Stable Diffusion实现医疗行业商务宣传素材生成:
“高性能应用服务HAI”中的Stable Diffusion文生图模型是开源流行的跨模态生成模型,用于生成与给定文本对应的图像。可以一键部署AIGC Stable Diffusion SDWebUI绘画的AI-Web应用,以便在该应用中进行模型推理验证,实现自动生成图像等功能。
通过提供的手册,一键部署AI-Web应用的方式部署Stable Diffusion文生图模型,下面介绍如何通过API的方式,集成Stable Diffusion文生图模型推理验证,体验AIGC生产方式。
5.1 测试多人同时使用一个SDWebUI出图:
在WebUI页面,进行模型推理验证。
- 在文生图页签提示词(Prompt)区域,自定义输入内容,单击生成,即可开启AIGC之旅。
- 本案例在提示词(Prompt)区域输入“Medical related imagesMedical related images”,单击生成,推理结果如下图所示。
经过测试发现,只有当第一个图生成完,才会再去生成另外一张图。不能并发同时去生成图,这样就不能并发去生成图片,可能要考虑当任务比较多、比较急的时候,需要临时去开多个实例来支撑。
5.2 通过API的方式来提供给业务人员使用:
高性能应用服务HAI 快速为开发者提供 StableDiffusion API 服务。
python /root/stable-diffusion-webui/launch.py --nowebui --xformers --opt-split-attention --listen --port 8000

使用postman进行发送post请求。

相关前端相关请求代码:
<template>
<view class="">
<myBg :background="mybackground"></myBg>
<view class="container">
<u-skeleton rows="5" :loading="skeletonLoading"></u-skeleton>
<view class="swiper-box" v-if="!skeletonLoading">
<swiper class="swiper" circular="true" autoplay="true" @change="swiperChange">
<swiper-item v-for="swiper in swiperList" :key="swiper.id">
<view class="swiper-item">
<image :src="swiper.img_url_full" @click="toSwiper(swiper)" mode="widthFix"></image>
</view>
</swiper-item>
</swiper>
<view class="indicator">
<view class="dots" v-for="(swiper, index) in swiperList" :key="index"
:style="{'--length': swiperList.length}" :class="[currentSwiper >= index ? 'on' : '']">
</view>
</view>
</view>
<view class="category-list" v-if="!skeletonLoading">
<view class="category" v-for="(row, index) in services" :key="index" @click="toCategory(row)">
<view class="img">
<image :src="row.icon"></image>
</view>
<view class="text">{{ row.title }}</view>
</view>
</view>
<view class="ad-banner" v-if="ads.length > 0 && !skeletonLoading">
<swiper circular="true" autoplay="true" class="swiper">
<swiper-item v-for="swiper in ads" :key="swiper.id">
<view class="swiper-item">
<image :src="swiper.img_url_full" @click="turnTo(swiper.link)" mode="widthFix"></image>
</view>
</swiper-item>
</swiper>
</view>
<!-- 活动区 -->
<view class="promotion">
<view class="list">
<block v-for="(row, index) in Promotion" :key="index">
<view class="column" @click="toPromotion(row)">
<view>
<view class="top">
<view class="title">{{row.title}}</view>
</view>
<view class="left">
<view class="ad">{{row.ad}}</view>
</view>
</view>
<view class="right">
<image :src="row.img"></image>
</view>
</view>
</block>
</view>
</view>
</view>
</view>
</template>
<script>
import myBg from 'components/background/background';
import myNavbar from 'components/navbar/navbar';
export default {
components: {
myNavbar,
myBg
},
data() {
return {
showHeader: true,
afterHeaderOpacity: 1, //不透明度
currentSwiper: 0,
swiperList: [],
ads: {},
services: [],
loadingText: '正在加载...',
skeletonLoading: true
};
},
onLoad(options) {
//获取首页配置信息
this.getConfigData();
this.getHomeApps();
},
methods: {
async getConfigData() {
var res = await this.$http.requestApi('GET', 'client/getHomeData');
this.swiperList = res.data.banners;
this.ads = res.data.ads;
this.skeletonLoading = false;
},
async getHomeApps() {
var res = await this.$http.requestApi('GET', 'client/getHomeApps');
this.services = res.data.apps;
this.skeletonLoading = false;
},
turnTo(url) {
if (!url) {
uni.showToast({ //提示
title: "敬请期待",
icon: "none"
});
return false;
}
uni.navigateTo({
url: url
});
},
toCategory(e) {
if (e.mini_wx_path == '') {
uni.showToast({
title: '敬请期待',
icon: 'none'
});
return false;
}
},
swiperChange(event) {
this.currentSwiper = event.detail.current;
}
}
};
</script>
<style lang="scss">
page {
background-color: #fff;
padding-bottom: 30rpx;
}
.container {
width: 92%;
position: relative;
overflow: scroll;
z-index: 10;
margin: 0 auto;
}
.header {
height: 100rpx;
display: flex;
align-items: center;
z-index: 10;
.input-box {
width: 100%;
height: 70rpx;
background-color: rgba(255, 255, 255, .6);
border-radius: 40rpx;
position: relative;
display: flex;
align-items: center;
.icon {
display: flex;
align-items: center;
position: absolute;
top: 0;
right: 0;
width: 72rpx;
height: 72rpx;
font-size: 34rpx;
color: #1cc48c;
}
input {
padding-left: 28rpx;
height: 28rpx;
font-size: 28rpx;
}
}
.icon-btn {
width: 120rpx;
height: 60rpx;
flex-shrink: 0;
display: flex;
.icon {
width: 60rpx;
height: 60rpx;
display: flex;
justify-content: flex-end;
align-items: center;
font-size: 42rpx;
}
}
}
.place {
background-color: #ffffff;
height: 100rpx;
}
.swiper-box {
margin-top: 6rpx;
display: flex;
justify-content: center;
height: 300rpx;
position: relative;
z-index: 1;
overflow: hidden;
border-radius: 14rpx;
.swiper {
width: 100%;
height: 100%;
.swiper-item {
image {
width: 100%;
height: 100%;
border-radius: 14rpx;
}
}
}
.indicator {
position: absolute;
bottom: 20rpx;
left: 20rpx;
background-color: rgba(255, 255, 255, 0.4);
width: 150rpx;
height: 5rpx;
border-radius: 3rpx;
overflow: hidden;
display: flex;
.dots {
width: 0rpx;
background-color: rgba(255, 255, 255, 1);
transition: all 0.3s ease-out;
&.on {
width: calc(100% / var(--length));
}
}
}
}
.category-list {
margin: 20rpx auto;
padding: 0 0 50rpx 0;
background-color: #ffffff;
border-radius: 14rpx;
display: flex;
flex-wrap: wrap;
.category {
width: 25%;
margin-top: 50rpx;
display: flex;
flex-wrap: wrap;
.img {
width: 100%;
display: flex;
justify-content: center;
image {
width: 100rpx;
height: 100rpx;
}
}
.text {
margin-top: 16rpx;
width: 100%;
display: flex;
justify-content: center;
font-size: 24rpx;
color: #3c3c3c;
}
}
}
.ad-banner {
margin: 30rpx auto;
height: 160rpx;
.swiper {
width: 100%;
height: 160rpx;
.swiper-item {
image {
width: 100%;
height: 100%;
}
}
}
image {
width: 100%;
}
}
.promotion {
margin: 20rpx auto;
.text {
width: 100%;
height: 80rpx;
font-size: 34rpx;
font-weight: 600;
margin-top: -10rpx;
}
.list {
width: 100%;
display: flex;
justify-content: space-between;
.column {
width: 42.5%;
padding: 3%;
background-color: #fff;
border-radius: 14rpx;
overflow: hidden;
display: flex;
justify-content: space-between;
flex-wrap: wrap;
.top {
width: 100%;
display: flex;
align-items: center;
margin-bottom: 5rpx;
line-height: 60rpx;
.title {
font-size: 30rpx;
}
.countdown {
margin-left: 20rpx;
display: flex;
height: 40rpx;
display: flex;
align-items: center;
font-size: 20rpx;
view {
height: 30rpx;
background-color: #f06c7a;
display: flex;
justify-content: center;
align-items: center;
color: #fff;
border-radius: 4rpx;
margin: 0 4rpx;
padding: 0 2rpx;
}
}
}
.left {
width: 100%;
display: flex;
flex-wrap: wrap;
align-content: space-between;
.ad {
margin-top: 5rpx;
width: 100%;
font-size: 22rpx;
color: #acb0b0;
}
}
.right {
width: 110rpx;
height: 110rpx;
image {
width: 110rpx;
height: 110rpx;
}
}
}
}
}
</style>
通过“高性能应用服务HAI”的Stable Diffusion应用,我们可以快速的搭建一套生成图片的素材库,而不用去网上花费大量的时间去搜索需要素材图片,减少产出的时间,提高自我的结果产出。

六、基于ChatGLM2-6B实现智能客服系统:
随着ChatGPT和通义千问等大模型在业界的引爆,LLM大模型的推理应用成为当下最热门的应用之一。ChatGLM2-6B是一个开源的、支持中英双语的对话语言模型,基于General Language Model(GLM)架构,具有62亿参数。ChatGLM2-6B使用了和ChatGPT相似的技术,针对中文问答和对话进行了优化。经过约1T Token的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。
下面将以ChatGLM2-6B基础模型为例,为您介绍如何使用“高性能应用服务HAI”在医疗行业患者咨询就医师一键部署ChatGLM2应用来为企业进行降本增效,让AI开发人员将像GPT-4这样的大语言模型(LLM)和外部数据结合起来,从而在尽可能少消耗计算资源的情况下,获得更好的性能和效果。
通过官方提供的第二个实验手册:未来对话:HAI创作个人专属的知识宇宙,我们可以在3-5分钟就可以初始化一个“高性能应用服务HAI”的ChatGLM2-6B智能AI对话应用。
“高性能应用服务HAI”相对传统的GPU云服务自建AI应用,是属于更为上层的应用,屏蔽了很多的繁琐的工作量,如环境搭建、选型、系统运维维护。

6.1 简单的试用“高性能应用服务HAI”中ChatGLM2-6B的AI对话功能:
通过打开控制台,点击“Gradio WebUI”,输入我们需要的答案就可以查询相关医疗相关的知识。
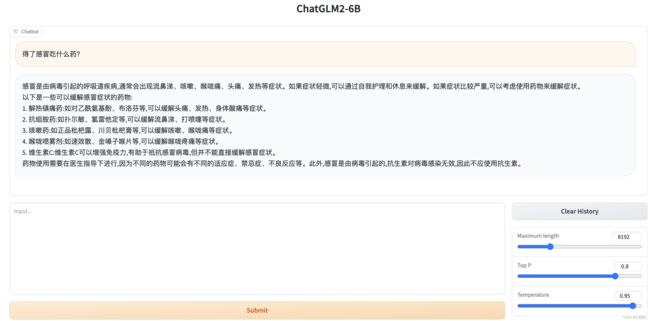
在同时访问的时候,和不同地址访问的时候,也是不会互相影响,相当于“单独的个体”,可以让不同的部门进行使用,不致于产会“串行”、“阻塞”的问题。

上面我们可以很容易就上线了一个AI对话的应用,可以提供了业务不同的部门进行使用,比如商务团队的需要写医疗相关专业术语标书、运营团队需要写相关活动的文案、医疗咨询师需要查询一些专业病理知识,使用默认的web页面不太方便,且没有受到权限控制,可以用以下API接口的形式接入到我们的自己业务平台中。
6.2 基于“高性能应用服务HAI”的ChatGLM2-6B以API接口提供web服务:
根据官方的手册中提到,脚本中有一个api.py的文件,使用它就可以提供API的服务,不过,出现了报错:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 108.00 MiB. GPU 0 has a total capacty of 14.58 GiB of which 43.38 MiB is free. Process 10594 has 11.76 GiB memory in use. Process 12441 has 2.78 GiB memory in use. Of the allocated memory 2.68 GiB is allocated by PyTorch, and 1.85 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF

由于资源不足导致无法启动,通过以下的命令进行关闭不需要的额外资源:
apt-get update && apt-get install sudo
sudo apt-get update
sudo apt-get install psmisc
sudo fuser -k 6889/tcp #执行这条命令将关闭 HAI提供的 chatglm2_gradio webui功能
在控制台中开通8000端的网络安全规则。
![]()
再能过postman进行访问IP + 端口(8000)端口,也可以修改其它的端口,需要修改脚本/root/ChatGLM2-6B/api.py。
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda()
# 多显卡支持,使用下面三行代替上面两行,将num_gpus改为你实际的显卡数量
# model_path = "THUDM/chatglm2-6b"
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# model = load_model_on_gpus(model_path, num_gpus=2)
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
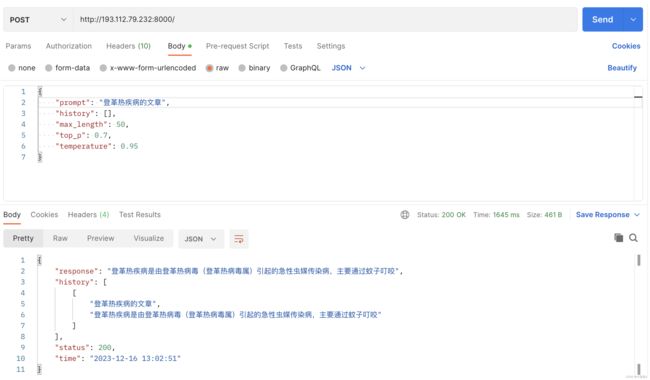
此时,我们就可以启动一个web API形式的服务,提供post接口,这样,其它的业务平台,可以通过接口访问的方式来调用。

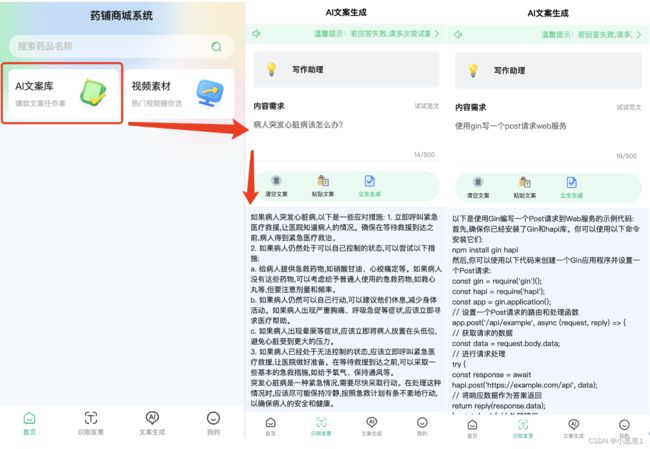
6.3 小程序中提供AI分析助手:
在小程序的代码中,请求基于“高性能应用服务HAI”的ChatGLM2-6B以API接口提供web服务,可以有效的进行权限的控制,防止外部人员使用。
<template>
<view>
<u-sticky>
<u-notice-bar direction="row" text="" url="/pages/user/myQuestion"
linkType="navigateTo" mode="link" speed="60" bgColor="#e7f9f3" color="#1acc89">
</u-notice-bar>
</u-sticky>
<view style="width: 94%;margin: 30rpx auto;" v-if="skeletonLoading">
<u-skeleton rows="5" :loading="skeletonLoading"></u-skeleton>
</view>
<view class="container" v-if="!skeletonLoading">
<view class="pre-form">
<u-transition :show="true" mode="fade-left">
<view class="option-item">
<view class="option-content">
<view class="sd-model-item sd-model-item-after" @click="sencePopupOpen()">
<view class="sd-item">
<view style="border-radius: 6px;">
<u--image :src="chatSenceSelected.icon_full_path" radius="6" width="100rpx"
height="100rpx" :lazyLoad="false"
:customStyle="{'background-color': '#fff!important'}">
</u--image>
</view>
<view class="sd-item-context">
<view class="sd-item-title sd-item-title-weight">
{{chatSenceSelected.role}}
</view>
<view class="sd-item-tips">
{{chatSenceSelected.explain}}
</view>
</view>
</view>
</view>
</view>
</view>
<view class="option-item">
<view class="title layout">
<view class="title-item">内容需求</view>
<view class="tips-item" @click="resetExample">试试范文</view>
</view>
<view class="option-content">
<view class="sd-model-item-context">
<u--textarea v-model="chatParams.prompt"
:placeholder="chatSenceSelected.placeholder || '请输入内容需求'" count maxlength='500'
border="bottom" height="240" :customStyle="{'padding':'0'}" confirmType="done">
</u--textarea>
</view>
</view>
</view>
<u--form labelPosition="left" :labelStyle="{'font-weight':'600'}">
<u-form-item label="字数要求" labelWidth="auto" v-if="chatSenceSelected.max_output">
<template slot="right">
<u-number-box v-model="chatParams.words" :step="100" integer inputWidth="50" :min="50"
:max="chatSenceSelected.max_output">
</u-number-box>
</template>
</u-form-item>
</u--form>
</u-transition>
</view>
</view>
<u-popup :show="sencePopup" mode="left" @close="senceClose" :closeable="true" :safeAreaInsetBottom="false">
<scroll-view :scroll-top="scrollTop" scroll-y="true" :style="{height:`${systemInfo.windowHeight}px`}"
@scroll="sencePopupScroll">
<view class="popup-box" style="margin: 80rpx 30rpx 30rpx 30rpx;">
<view class="option-item popup-list" v-for="(sence,senceIndex) in chatSence" :key="senceIndex">
<view class="option-item-title">{{sence.case_title}}</view>
<view class="option-content option-content-flex">
<view class="sd-model-item sd-model-item-margin" v-for="(item,index) in sence.child"
:key="index" @click="setChatSence(senceIndex,index)"
:class="chatSenceSelected.id == item.id ? 'sd-model-item-selected':''">
<view class="sd-item">
<view class="sd-item-context" style="margin: 0;">
<view class="sd-item-title sd-item-font">{{item.role}}</view>
</view>
</view>
</view>
</view>
</view>
</view>
</scroll-view>
</u-popup>
<!-- 功能按钮区域 -->
<view class="tool">
<u-grid :border="false" col="4">
<u-grid-item @click="goAppStore">
<u-icon :name="assetUrl + 'apps.png'" size="48rpx"></u-icon>
<text class="grid-text">应用中心</text>
</u-grid-item>
<u-grid-item @click="resetQuestion">
<u-icon :name="assetUrl + 'delete.png'" size="48rpx"></u-icon>
<text class="grid-text">清空文案</text>
</u-grid-item>
<u-grid-item @click="pasteContent">
<u-icon :name="assetUrl + 'paste.png'" size="48rpx"></u-icon>
<text class="grid-text">粘贴文案</text>
</u-grid-item>
<u-grid-item @click="onSubmitGPT">
<u-icon :name="assetUrl + 'txtcheck.png'" size="48rpx"></u-icon>
<text class="grid-text grid-text-color">立即提问</text>
</u-grid-item>
</u-grid>
</view>
<!-- #ifdef MP-WEIXIN -->
<view class="ad-container" style="width: 94%;margin: 30rpx auto;">
<view class="ad-view">
<wxAdVideo />
</view>
<u-gap height="20rpx"></u-gap>
</view>
<!-- #endif -->
</view>
</template>
<script>
import wxAdVideo from '@/components/wxad/adVideo.vue';
export default {
components: {
wxAdVideo
},
data() {
return {
gptLoading: false,
chatParams: {
prompt: '',
words: 200
},
chatSence: [],
chatSenceSelected: {},
chatSenceExample: [],
assetUrl: this.$configData.assetsUrl,
sencePopup: false,
whiteColor: '#fff',
skeletonLoading: true,
scrollTop: 0,
scrollTopOld: 0,
systemInfo: uni.getSystemInfoSync(),
};
},
onShareAppMessage(res) {
return {
title: '轻松创作,爱上文案',
path: '/pages/index/index'
}
},
onShareTimeline(res) {
return {
title: '轻松创作,爱上文案',
path: '/pages/index/index'
}
},
onLoad() {
this.getPromptList();
},
methods: {
sencePopupScroll: function(e) {
this.scrollTopOld = e.detail.scrollTop;
},
async getPromptList() {
var _data = {
provider: 1,
item_id: 17
};
var _res = await this.$http.requestApi('GET', 'agi/getCopyWritingPrompt', _data);
if (_res.status == 200) {
this.chatSence = _res.data;
this.chatSenceSelected = _res.data[0].child[0];
this.chatSenceExample = _res.data[0].child[0].example_arr;
this.skeletonLoading = false;
} else {
uni.showToast({
icon: 'none',
title: _res.msg
});
}
},
goAppStore() {
uni.navigateTo({
url: '/pages/appCenter/appCenter'
})
},
sencePopupOpen() {
this.sencePopup = true;
this.skeletonLoading = true;
this.scrollTop = 0;
this.$nextTick(function() {
this.scrollTop = this.scrollTopOld;
});
},
setChatSence(senceIndex, caseIndex) {
let that = this;
//设置文案场景
that.chatSenceSelected = that.chatSence[senceIndex].child[caseIndex];
that.chatSenceExample = that.chatSenceSelected.example_arr;
//this.sencePopup = false;
that.chatParams.words = 200;
that.resetQuestion();
},
resetExample() {
if (this.chatSenceExample.length <= 0) {
uni.showToast({
icon: 'none',
title: '暂无范文'
});
return;
}
//随机案例
let min = 0;
let max = this.chatSenceExample.length - 1;
let index = Math.ceil(Math.random() * (max - min) + min);
this.chatParams.prompt = this.chatSenceExample[index];
},
checkToken() {
const token = uni.getStorageSync('token');
if (token == '' || token == undefined) {
return false
} else {
return true
}
},
resetQuestion() {
this.chatParams.prompt = '';
},
pasteContent() {
var that = this;
uni.getClipboardData({
success: function(res) {
that.chatParams.prompt = res.data;
}
});
},
modeChange(index) {
this.modeCurrent = index;
},
imgStyleChange(type) {
this.chatParams.style = type;
},
senceClose() {
this.skeletonLoading = false;
this.sencePopup = false;
},
onSubmitGPT() {
//检测用户是否登录
let islogin = this.checkToken();
if (!islogin) {
uni.navigateTo({
url: '/pages/login/index'
});
return false;
}
this.gptLoading = true;
//已经登录,则调用后端接口数据
let postData = {
question: encodeURIComponent(this.chatParams.prompt),
words: this.chatParams.words,
sence_id: this.chatSenceSelected.id,
q_type: 0,
loginType: 1
};
this.$http.requestApi('POST', 'aigc/question/answer', postData).then(res => {
const resCode = res.status;
this.gptLoading = false;
if (resCode == 10000) {
return false;
}
if (resCode == 200) {
uni.navigateTo({
url: '/pages/detail/index?avg=' + encodeURIComponent(res.data.qaId)
});
} else {
uni.showToast({
title: res.msg,
duration: 2000,
icon: 'none'
});
}
})
}
}
}
</script>
<style lang="scss" scoped>
.container {
width: 92%;
margin: 30rpx auto;
.switch-tabbar {
margin: 30rpx 0;
}
.pre-form {
margin: 20rpx 0;
}
.diy-form {
margin: 0 auto;
z-index: 999;
.header {
margin-bottom: 30rpx;
.title {
text-align: center;
color: #fff;
margin: 30rpx 0rpx;
}
}
.panel {
padding: 30rpx;
background-color: #fff;
border-radius: 15rpx;
box-shadow: 0rpx 10rpx 10rpx #eee;
.head {
display: flex;
flex-direction: row;
justify-content: space-between;
.tips {
color: #dd6161;
}
}
.textarea {
margin-top: 30rpx;
}
.btn-group {
display: flex;
flex-direction: row;
justify-content: space-between;
margin-top: 30rpx;
.get {
width: 100%;
}
}
}
}
}
.option-item {
.title {
padding: 30rpx 0;
font-size: 30rpx;
font-weight: 600;
}
.title-padding {
padding-top: 0 !important;
}
.option-item-title {
font-size: 28rpx;
margin: 20rpx auto;
font-weight: 600;
}
.option-content-flex {
display: flex;
justify-content: space-between;
flex-wrap: wrap;
}
.option-content {
.sd-model-item {
margin-bottom: 20rpx;
background-color: #f1f2f4;
padding: 20rpx;
color: #222;
border-radius: 12rpx;
position: relative;
.sd-item {
display: flex;
.sd-item-context {
margin: 0 30rpx;
display: flex;
flex-direction: column;
justify-content: center;
line-height: 48rpx;
.sd-item-title {
font-size: 30rpx;
}
.sd-item-title-weight {
font-weight: 600;
}
.sd-item-tips {
font-size: 24rpx;
color: #999;
line-height: initial;
}
.sd-item-font {
font-size: 28rpx;
}
}
}
}
.sd-model-item-selected {
background-color: #e7f9f3;
color: #1acc89;
}
.sd-model-item-after {
.sd-item::after {
content: '';
position: absolute;
right: 30rpx;
top: calc(50% - 12rpx);
width: 20rpx;
height: 20rpx;
border-top: 4rpx solid;
border-right: 4rpx solid;
border-color: #999;
content: '';
transform: rotate(45deg);
}
}
.sd-model-item-margin {
margin-bottom: 30rpx;
width: 43%;
}
.sd-model-item-green {
background-color: #e7f9f3;
color: #1acc89;
.sd-item {
.sd-item-context {
.sd-item-tips {
color: #1acc89;
opacity: 0.5;
}
}
}
}
}
}
.sence-popup-title {
position: fixed;
width: 100%;
text-align: center;
height: 50px;
line-height: 50px;
font-size: 36rpx;
font-weight: bold;
}
.layout {
display: flex;
justify-content: space-between;
align-items: center;
.tips-item {
font-weight: 400;
font-size: 24rpx;
color: #999;
}
}
.tool {
margin: 10rpx 30rpx 20rpx 30rpx;
width: calc(100% - 60rpx);
border-radius: 100rpx;
background-color: #e7f9f3;
padding: 12rpx 0;
.u-grid {
.u-grid-item {
.grid-text {
font-size: 24rpx;
transform: scale(0.9);
color: #222;
padding-top: 12rpx;
}
.grid-text-color {
font-weight: 600;
color: #1acc89;
}
}
}
}
</style>
可以通过集成API的形式,首先需要登录到小程序,才能提供类似病例查询、文案生成、IT技术学习等场景。
6.4 后管记录生成过的AI列表:
如果有人生成过一些问题,可以存到数据库,下次使用的时候,直接从数据库查,就不需要经过AI服务,当使用量大的时候,做一层缓存隔离,是非常有必要的,毕竟好刀用在刀刃上。
每次推理用户的输入会首先在本地知识库中查找与输入问题相近的答案,并将知识库答案与用户输入一起输入大模型生成基于本地知识库的定制答案。
<div class="elTable" style="margin-top: 17px">
<el-table
:data="state.tableList"
border
style="width: 100%"
:header-cell-style="{ background: '#EDF3FD', color: '#333333' }"
header-align="center"
>
<el-table-column type="index" label="序号" width="60" header-align="center" align="center"/>
<el-table-column prop="batchId" label="搜索文案" header-align="center" align="center"/>
<el-table-column prop="insuredName" label="姓名" header-align="center" align="center" />
<el-table-column prop="insuredIdNum" label="证件号" header-align="center" align="center" />
<el-table-column prop="insuredPhone" label="手机号" header-align="center" align="center"/>
<el-table-column prop="insuredSex" label="查询时间" header-align="center" align="center" /> -->
</el-table>
<div class="elPagination">
<el-pagination
style="margin-top: 20px; text-align: right"
:current-page="state.pageNumber"
:page-sizes="[10, 20, 30, 40]"
layout="total, sizes, prev, pager, next, jumper"
:total="state.total"
@size-change="handleSizeChange"
@current-change="handleCurrentChange"
/>
</div>
</div>

通过对基于“高性能应用服务HAI”的ChatGLM2-6B以API接口提供web服务,集成到小程序中,使用API来集中管理,将生成的记录同时,存一份到数据库或缓存中,下次再有相同的答案可以直接先走中间服务,不用再到AI服务器上再消耗资源,因为其实在医疗行业,有很多的问题,都是比较常用的。

七、基于PyTorch 实现NLP自然语言处理:
基于NLP和自然语言处理技术将门诊/住院病历、检查检验报告、处方/医嘱等医疗文档自动识别、转换为结构化数据,支持下游可视化、统计分析、推理等应用,可用于健康档案、质控、保险理赔及临床科研等业务场景,获取医疗知识,节约医疗资源。
在公司的业务场景中,患者的病例需要手动去针对性的打标签,比如,标注这个患者是眼疾,实际上会有很多的问题存在:
- 工作的性质比较单一枯燥的动作,纯粹的人工作业方式
- 有人工成本的消耗
- 操作不准确,评判的标准不一致,容易产出错误
7.1 文本csv内容准备,如下为一些患者的病例一些常见的症状描述。

7.2 安装jieba库:

7.3 使用结巴jieba库将语句进行分词库统计词频:
为了对中文文本数据进行预处理,以便进行NLP分析,代码使用中文分词库jieba对患者的数据进行处理。代码读取患者数据的csv文件,去除第一行(其中包含每列的标签),然后循环处理每一行数据。对于每一行,提取内容并使用jieba进行分词。
import jieba
data_path = "sources/data.csv"
data_list = open("data_path").readlines()[1:]
for item in data_list:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all = False)
for seg_item in seg_list:
print(seg_item)
可以看到一些标点符号,和一些没有语义的词也会被匹配出来,得到的分词结果被过滤以去除任何停用词(不具有意义的词,如“和”或“的”)。

7.4 停用词stopwords处理:
停用词的作用是在文本分析过程中过滤掉这些常见词语,从而减少处理的复杂度,提高算法效率,并且在某些任务中可以改善结果的质量,避免分析结果受到这些词的干扰。
在自然语言处理(NLP)研究中,停用词stopwords是指在文本中频繁出现但通常没有太多有意义的词语。这些词语往往是一些常见的功能词、虚词甚至是一些标点符号,如介词、代词、连词、助动词等,比如中文里的"的"、“是”、“和”、“了”、“。“等等,英文里的"the”、“is”、“and”、”…"等等。
import jieba
data_path = "./sources/his.csv"
data_stop_path = "./sources/hit_stopwords.txt"
data_list = open(data_path).readlines()[1:]
stops_word = open(data_stop_path, encoding='UTF-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")
for item in data_list:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all = False)
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
print(content)
print(seg_res)

7.5 加载数据集:
使用PyTorch的提供的dataset的接口,根据项目重写dataset和dataloader。
import jieba
data_path = "./sources/his.csv"
data_stop_path = "./sources/hit_stopwords.txt"
data_list = open(data_path).readlines()[1:]
stops_word = open(data_stop_path, encoding='UTF-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")
voc_dict = {}
min_seq = 1
top_n = 1000
UNK = ""
PAD = ""
for item in data_list:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all = False)
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
if seg_item in voc_dict.keys():
voc_dict[seg_item] += 1
else:
voc_dict[seg_item] = 1
voc_list = sorted([_ for _ in voc_dict.items() if _[1] > min_seq],
key=lambda x: x[1],
reverse=True)[:top_n]
voc_dict = {word_count[0]: idx for idx, word_count in enumerate(voc_list)}
voc_dict.update({UNK: len(voc_dict), PAD: len(voc_dict) + 1})
print(voc_dict)
# 保存字典
ff = open("./sources/dict.txt", "w")
for item in voc_dict.keys():
ff.writelines("{},{}\n".format(item, voc_dict[item]))
![]()
7.6 搭建模型结构:
import numpy as np
import jieba
from torch.utils.data import Dataset, DataLoader
def read_dict(voc_dict_path):
voc_dict = {}
dict_list = open(voc_dict_path).readlines()
print(dict_list[0])
for item in dict_list:
item = item.split(",")
voc_dict[item[0]] = int(item[1].strip())
return voc_dict
# 将数据集进行处理(分词,过滤...)
def load_data(data_path, data_stop_path):
data_list = open(data_path, encoding='utf-8').readlines()[1:]
stops_word = open(data_stop_path, encoding='utf-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")
voc_dict = {}
data = []
max_len_seq = 0
np.random.shuffle(data_list)
for item in data_list[:]:
label = item[0]
content = item[2:].strip()
seg_list = jieba.cut(content, cut_all=False)
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
if seg_item in voc_dict.keys():
voc_dict[seg_item] = voc_dict[seg_item] + 1
else:
voc_dict[seg_item] = 1
if len(seg_res) > max_len_seq:
max_len_seq = len(seg_res)
data.append([label, seg_res])
# print(max_len_seq)
return data, max_len_seq
# 定义Dataset
class text_CLS(Dataset):
def __init__(self, voc_dict_path, data_path, data_stop_path):
self.data_path = data_path
self.data_stop_path = data_stop_path
self.voc_dict = read_dict(voc_dict_path)
self.data, self.max_len_seq = load_data(self.data_path, self.data_stop_path)
np.random.shuffle(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, item):
data = self.data[item]
label = int(data[0])
word_list = data[1]
input_idx = []
for word in word_list:
if word in self.voc_dict.keys():
input_idx.append(self.voc_dict[word])
else:
input_idx.append(self.voc_dict["" ])
if len(input_idx) < self.max_len_seq:
input_idx += [self.voc_dict["" ] for _ in range(self.max_len_seq - len(input_idx))]
# input_idx += [1001 for _ in range(self.max_len_seq - len(input_idx))]
data = np.array(input_idx)
return label, data
# 定义DataLoader
def data_loader(data_path, data_stop_path, dict_path):
dataset = text_CLS(dict_path, data_path, data_stop_path)
return DataLoader(dataset, batch_size=10, shuffle=True)
data_path = "./sources/his.csv"
data_stop_path = "./sources/hit_stopwords.txt"
dict_path = "./sources/dict.txt"
train_dataLoader = data_loader(data_path, data_stop_path, dict_path)
for i, batch in enumerate(train_dataLoader):
print(batch[0], batch[1].size())
print(batch[0], batch[1])

7.7 网络模型的配置:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config():
def __init__(self):
'''
self.embeding = nn.Embedding(config.n_vocab,
config.embed_size,
padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed_size,
config.hidden_size,
config.num_layers,
bidirectional=True, batch_first=True,
dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size,
config.num_classes)
self.softmax = nn.Softmax(dim=1)
'''
self.n_vocab = 1002
self.embed_size = 128
self.hidden_size = 128
self.num_layers = 3
self.dropout = 0.8
self.num_classes = 2
self.pad_size = 32
self.batch_size = 128
self.is_shuffle = True
self.learn_rate = 0.001
self.num_epochs = 100
self.devices = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embeding = nn.Embedding(config.n_vocab,
padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(input_size=config.embed_size,
hidden_size=config.hidden_size,
num_layers=config.num_layers,
bidirectional=True,
batch_first=True, dropout=config.dropout)
self.maxpooling = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size, config.num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
embed = self.embeding(x)
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpooling(out).reshape(out.size()[0], -1)
out = self.fc(out)
out = self.softmax(out)
return out
# 测试网络是否正确
cfg = Config()
cfg.pad_size = 640
model_textcls = Model(config=cfg)
input_tensor = torch.tensor([i for i in range(640)]).reshape([1, 640])
out_tensor = model_textcls.forward(input_tensor)
print(out_tensor.size())
print(out_tensor)
![]()
7.8 训练脚本的搭建:
model_text_cls = Model(cfg)
model_text_cls.to(cfg.devices)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_text_cls.parameters(), lr=cfg.learn_rate)
for epoch in range(cfg.num_epochs):
for i, batch in enumerate(train_dataloader):
label, data = batch
# data1 = torch.tensor(data).to(cfg.devices)
# label1 = torch.tensor(label).to(cfg.devices)
data1 = data.sourceTensor.clone().detach().to(cfg.devices)
label1 = label.sourceTensor.clone().detach().to(cfg.devices)
optimizer.zero_grad()
pred = model_text_cls.forward(data1)
loss_val = loss_func(pred, label1)
print("epoch is {},ite is {},val is {}".format(epoch, i, loss_val))
loss_val.backward()
optimizer.step()
if epoch % 10 == 0:
torch.save(model_text_cls.state_dict(), "./models/{}.pth".format(epoch))

7.9 小结:
可以通过基于PyTorch 实现NLP自然语言处理将患者病例实现AI技术进行转换,从而让业务能够快速实现自动化打标签,可以起到降本增效的结果。

“高性能应用服务HAI”基于PyTorch 优化的其它类似的场景应用方案:
八、体验“高性能应用服务HAI”的优化与建议:
8.1 支持挂载自己的模型及输出目录:
一般来说,模型下载 Stable Diffusion (简称SD) 模型主要从 Huggingface, github, Civitai 下载,但是由于某些网络的问题(你懂的),导致下载慢,下载443,导致下载各种问题。
虽然官方支持了不少有主流的模型,但是在实际的应用中,各行各业的需求不太一样,如果在开源社区下载了模型或自己训练得到了Lora或SD等模型要用于SDWebUI,最好能把输出数据可以挂载到COS Bucket的目录下,或其它第三方的配置和插件安装来支持文件挂载方式来实现。

8.2 体验过程中,有时候会服务长时间卡住:
体验过程中,遇到创建实例差不多半小时,也没有办法进行销毁操作,一直卡在控制台中,建议提供在创建的过程也可以进行销毁的操作,避免出现异常后,无法使用。当时,通过提工单处理成功。

8.3 无法进行在线扩充云硬盘,导致模型下载失败:
在实际的应用中,我们经常会下载一些其它的模型,这些模型有的非常大,在系统运行期间,无法进行在线扩充云硬盘,导致需要更换更大的实例。建议在线、离线可以进行云硬盘的扩充,可以满足在运行期间进行不停机维护。

8.4 实例创建后,再启动IP会变化:
创建好的实例,如果在关机,一般会在一段时间内不收费,有时候,在做测试的需求时,为了费用的考虑,会进行关机操作,但是第二天重新开机后,会发现IP会有变化,又需要修改第三方应用的请求地址,如果能在一定的时间段,保持IP不变,体验上会好点,如果能支持域名的话,就可以进行https的访问,相对应集成到系统中稍微安全一点。

8.5 多人不能同时使用一个SDWebUI出图:
正常部署的SDWebUI为单机版仅支持单个人使用,多人使用需要等待排队。当企业级多人使用时,可能需要集群版SDWebUI,同时多人使用时开启多个服务实例数,来保证AI绘画的出图速度和稳定性。
部署集群版SDWebUI后,有以下优势:
- 多个团队可以通过相同的URL访问应用,互不干扰。
- 支持多人共享一张卡,同时单一服务按照实际使用量进行弹性扩缩容,从而提高集群的使用率,实现降本增效的目的。
- 对接企业内部账号体系,按用户身份区分每个人的出图模型、图片成果和插件等。

8.6 Stable Diffusion web UI默认支持中文:
通过默认打开的Stable Diffusion web UI是英文显示的,最后是默认使用中文打开。大多数人,都还是喜欢使用中文的界面。
总体来说,“高性能应用服务HAI”提供了很多一键部署的应用,非常方便的降低了门槛,引入了大量的使用者。同时,在进行体验中,希望有一些建议能够优化一下。

九、总结:
随着业务的快速发展,各行各业的难题是随着模型在线推理服务数量的增加,服务也变得越来越庞大、臃肿,难以管理。这种状况不仅导致了资源浪费,还增加了维护和升级的成本。
为了解决这些“顽疾”,“高性能应用服务HAI”具有澎湃算力,即开即用,基于腾讯云GPU云服务器底层算力,提供开箱即用的高性能云服务。

以应用为中心,匹配GPU云算力资源,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用, 降低运行成本,大幅提升服务可用性,平均部署周期由之前的天缩短至分钟,大幅提升了研发迭代效率,从而加速商业化应用的进程,为各行各业提供新的增长动力。
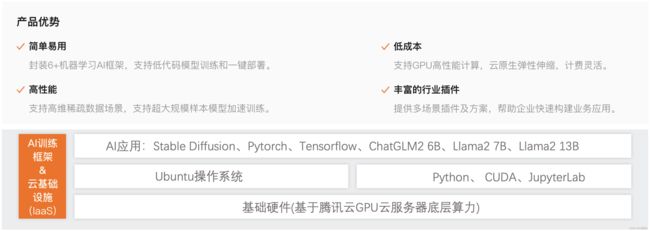
“高性能应用服务HAI”是面向开发者和企业的云原生机器学习/深度学习工程平台,服务覆盖AI开发全链路,内置6+AI框架和模型,具备丰富的行业场景插件。

在降本增效的行业背景下,“高性能应用服务HAI”已经成为AI应用落地最为明晰的方向。从数据中获得更深入的洞察,同时降低成本。“高性能应用服务HAI”通过最全面的人工智能(AI)和机器学习(ML)服务、基础设施和实施资源,在AIGC领域之旅的每个阶段为您提供帮助。
凭借丰富的用户场景,“高性能应用服务HAI”为多个业务正基于AI大模型技术,进行业务场景和服务模式创新,构建面向未来的全新想象力。