阶段十-分布式锁
5.1 节 为什么要使用分布式锁
锁是多线程代码中的概念,只有当多任务访问同一个互斥的共享资源时才需要。如下图:

在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVm之下。但当我们的应用是分布式集群工作的情况下,属于JVM下的工作环境,JVM之间已经无法通过多线程的锁来解决同步问题。需要更加高级的锁机制,来处理跨机器的进程的数据之间的同步问题——这就是分布式锁
5.2 节 分布式锁的几种方式
分布式锁的核心思路是记住外力解决多JVM进程操作共享数据时需要使用互斥锁问题。常见的方式有:
-
mysql数据库
-
zookeeper
-
redis
5.3 节 搭建测试分布式锁的环境
【1】创建工程distributed-lock-study ,pom如下
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.7.6
top.psjj
distributed-lock-study
0.0.1-SNAPSHOT
pom
distributed-lock-study
distributed-lock-study
moduleB
moduleA
8
8.0.26
1.2.1
3.5.2
org.apache.dubbo
dubbo-spring-boot-starter
${dubbo.starter}
org.apache.dubbo
dubbo-registry-zookeeper
${dubbo.registry.zookeeper}
mysql
mysql-connector-java
${mysql-connection.version}
runtime
com.alibaba
druid-spring-boot-starter
${druid.version}
com.baomidou
mybatis-plus-boot-starter
${mybatis-plus.version}
cn.hutool
hutool-all
${hutool.version}
org.springframework.boot
spring-boot-starter-web
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-starter-web
com.baomidou
mybatis-plus-boot-starter
mysql
mysql-connector-java
runtime
com.alibaba
druid-spring-boot-starter
org.springframework.boot
spring-boot-starter-data-redis
org.apache.commons
commons-pool2
org.springframework.boot
spring-boot-maven-plugin
org.projectlombok
lombok
【2】创建moduleA和moduleB两个模块
【3】在两个模块中编写application.yml
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lock_db?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: root
redis:
host: 192.168.9.132
port: 6379
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms
server:
port: 1111spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lock_db?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: 123456
redis:
host: 192.168.184.200
port: 6379
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms
server:
port: 2222【4】编写启动类
package com.sh;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 20:55
* @Decsription: com.sh
* @version: 1.0
*/
@SpringBootApplication
@MapperScan("com.sh.ma.mapper")
public class ModuleAApplication {
public static void main(String[] args) {
SpringApplication.run(ModuleAApplication.class,args);
}
}package com.sh;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 20:55
* @Decsription: com.sh
* @version: 1.0
*/
@SpringBootApplication
@MapperScan("com.sh.ma.mapper")
public class ModuleBApplication {
public static void main(String[] args) {
SpringApplication.run(ModuleBApplication.class,args);
}
}【5】准备数据库local_db,并出入下张表
/*
Navicat Premium Data Transfer
Source Server : conn
Source Server Type : MySQL
Source Server Version : 80026
Source Host : 127.0.0.1:3306
Source Schema : lock_db
Target Server Type : MySQL
Target Server Version : 80026
File Encoding : 65001
Date: 12/01/2024 15:43:48
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_goods
-- ----------------------------
DROP TABLE IF EXISTS `t_goods`;
CREATE TABLE `t_goods` (
`id` int(0) NOT NULL AUTO_INCREMENT COMMENT '主键',
`goods` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL DEFAULT NULL,
`count` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_unicode_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_goods
-- ----------------------------
INSERT INTO `t_goods` VALUES (1, '手机', -1);
INSERT INTO `t_goods` VALUES (2, '笔记本', 100);
SET FOREIGN_KEY_CHECKS = 1;
【6】编写po 、mapper 、service 、controller,两个模块代码完全一样
package com.sh.ma.po;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 21:01
* @Decsription: com.sh.ma.po
* @version: 1.0
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_goods")
public class Goods implements Serializable {
@TableId(type = IdType.AUTO)
private Integer id;
private String goods;
private Integer count;
}
package com.sh.ma.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.sh.ma.po.Goods;
import org.apache.ibatis.annotations.Update;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 21:01
* @Decsription: com.sh.ma.service
* @version: 1.0
*/
public interface GoodsMapper extends BaseMapper {
@Update("update t_goods set count = count-1 where id=#{id}")
void subCount(Integer id);
}
package com.sh.ma.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.sh.ma.po.Goods;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 21:02
* @Decsription: com.sh.ma.service
* @version: 1.0
*/
public interface GoodsService extends IService {
void updateGoodsCount(Integer id);
}
package com.sh.ma.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.sh.ma.mapper.GoodsMapper;
import com.sh.ma.po.Goods;
import com.sh.ma.service.GoodsService;
import org.springframework.stereotype.Service;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 21:02
* @Decsription: com.sh.ma.service.impl
* @version: 1.0
*/
@Service
public class GoodsServiceImpl extends ServiceImpl implements GoodsService {
@Override
public void updateGoodsCount(Integer id) {
Goods goods = this.baseMapper.selectById(id);
Integer count = goods.getCount();
if(count>0){
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.baseMapper.subCount(id);
}
}
}
package com.sh.ma.controller;
import com.sh.ma.service.GoodsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 21:03
* @Decsription: com.sh.ma.controller
* @version: 1.0
*/
@RestController
@RequestMapping("/goods")
public class GoodsController {
@Autowired
private GoodsService goodsService;
@RequestMapping("/update")
public String updateGoodsCount(Integer id){
goodsService.updateGoodsCount(id);
return "ok";
}
}
【最后】测试


出现了超卖问题
5.4 节 基于Mysql实现的分布式锁
5.4.1 mysql实现分布式锁原理
基于分布式锁的实现,首先肯定是想单独分离出一台mysql数据库,所有服务要想操作文件(共享资源),那么必须先在mysql数据库中插入一个标志,插入标志的服务就持有了锁,并对文件进行操作,操作完成后,主动删除标志进行锁释放,其与服务会一直查询数据库,看是否标志有被占用,直到没有标志占用时自己才能写入标志获取锁。
但是这样有这么一个问题,如果服务(jvm1)宕机或者卡顿了,会一直持有锁未释放,这样就造成了死锁,因此就需要有一个监视锁进程时刻监视锁的状态,如果超过一定时间未释放就要进行主动清理锁标记,然后供其与服务继续获取锁。
如果监视锁字段进程和jvm1同时挂掉,依旧不能解决死锁问题,于是又增加一个监视锁字段进程,这样一个进程挂掉,还有另一个监视锁字段进程可以对锁进行管理。这样又诞生一个新的问题,两个监视进程必须进行同步,否则对于过期的情况管理存在不一致问题。
因此存在以下问题,并且方案变得很复杂:
-
监视锁字段进程对于锁的监视时间周期过短,仍旧会造成多售(jvm1还没处理完其持有的锁就被主动销毁,造成多个服务同时持有锁进行操作)。
-
监视锁字段进程对于锁的监视时间周期过长,会造成整个服务卡顿过长,吞吐低下。
-
监视锁字段进程间的同步问题。
-
当一个jvm持有锁的时候,其余服务会一直访问数据库查看锁,会造成其余jvm的资源浪费。
5.4.2 基于update实现分布锁(特殊情况)
举一个电商系统,商品数量超卖问题:
如果库存递减使用下面的伪代码会产生超卖现象,超卖现象的本质都是多线程数据同步问题,因为时分布式系统,不能单纯的加锁处理,如果处理下面的逻辑需要使用分布式锁,关于分布式锁,因为我们的代码直接执行语句,有数据库行级锁,不会产生超卖问题
//mysql行锁解决分布锁问题
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.baseMapper.subCount2(goods);@Update("update t_goods set count=count-1 where id=#{id} and count>0")
void subCount2(Goods goods);条件中要有一个字段 携带唯一索引,两个条件要在同一张表中
5.4 节 基于Redis实现分布式锁
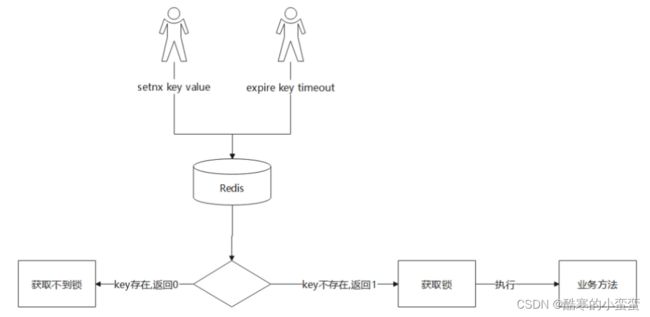
5.4.1 Redis实现分布式锁优点
(1)Redis有很高的性能; (2)Redis命令对此支持较好,实现起来比较方便
5.4.2 命令介绍
(1)SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
5.4.3 Redis实现分布式锁原理
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
5.4.4 Redisson分布式锁使用
1)引入依赖
org.springframework.boot
spring-boot-starter-data-redis
org.redisson
redisson-spring-boot-starter
3.14.0
2)配置文件
spring:
redis:
host: 192.168.9.132
port: 6379关键代码
//创建锁
RLock lock = redissonClient.getLock("goods-" + id);
//加锁
try {
lock.lock();
Goods goods = this.baseMapper.selectById(id);
Integer count = goods.getCount();
if(count>0){
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.baseMapper.subCount(id);
}
} catch (RuntimeException e) {
throw new RuntimeException("超卖了");
} finally {
//释放锁
lock.unlock();
}5.4.5 总结
可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能,同时,很多缓存服务都是集群部署的,可以避免单点问题。并且很多缓存服务都提供了可以用来实现分布式锁的方法,比如Tair的put方法,redis的setnx方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
使用缓存实现分布式锁的优点
-
性能好,实现起来较为方便。
使用缓存实现分布式锁的缺点
-
通过超时时间来控制锁的失效时间并不是十分的靠谱。
后面项目中采用的Redisson,就是采用redis实现分布式锁
Redisson是Redis官方推荐的Java版的Redis客户端。它提供的功能非常多,也非常强大,此处我们只用它的分布式锁功能。
5.5 节 基于Zookeeper实现的分布式锁
基于以上两种实现方式,有了基于zookeeper实现分布式锁的方案。由于zookeeper有以下特点:
-
维护了一个有层次的数据节点,类似文件系统。
-
有以下数据节点:临时节点、持久节点、临时有序节点(分布式锁实现基于的数据节点)、持久有序节点。
-
zookeeper可以和client客户端通过心跳的机制保持长连接,如果客户端链接zookeeper创建了一个临时节点,那么这个客户端与zookeeper断开连接后会自动删除。
-
zookeeper的节点上可以注册上用户事件(自定义),如果节点数据删除等事件都可以触发自定义事件。
-
zookeeper保持了统一视图,各服务对于状态信息获取满足一致性。
Zookeeper的每一个节点,都是一个天然的顺序发号器。
在每一个节点下面创建子节点时,只要选择的创建类型是有序(EPHEMERAL_SEQUENTIAL 临时有序或者PERSISTENT_SEQUENTIAL 永久有序)类型,那么,新的子节点后面,会加上一个次序编号。这个次序编号,是上一个生成的次序编号加一
比如,创建一个用于发号的节点“/test/lock”,然后以他为父亲节点,可以在这个父节点下面创建相同前缀的子节点,假定相同的前缀为“/test/lock/seq-”,在创建子节点时,同时指明是有序类型。如果是第一个创建的子节点,那么生成的子节点为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,依次类推,等等。

5.5.1 Zookeeper实现分布式锁原理

-
创建一个目录mylock;
-
线程A想获取锁就在mylock目录下创建临时顺序节点;
-
获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
-
线程B获取所有节点,判断自己不是最小节点,设置监听比自己小的节点;
-
线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
来看下Zookeeper能不能解决前面提到的问题。
-
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
-
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
-
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
-
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
5.5.2 基于Curator 客户端实现分布式锁
Curator Framework提供了简化使用zookeeper更高级的API接口。它包涵很多优秀的特性,主要包括以下三点
-
自动连接管理:自动处理zookeeper的连接和重试存在一些潜在的问题;可以watch NodeDataChanged event和获取updateServerList;Watches可以自动被Cruator recipes删除;
-
更干净的API:简化raw zookeeper方法,事件等;提供现代流式API接口
-
Recipe实现:leader选举,分布式锁,path缓存,和watcher,分布式队列等。
单独使用依赖
org.apache.curator
curator-framework
4.0.1
org.apache.curator
curator-recipes
4.0.1
代码:
package com.sh.ma.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.sh.ma.mapper.GoodsMapper;
import com.sh.ma.po.Goods;
import com.sh.ma.service.GoodsService;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
/**
* @Auther: 世豪讲java
* @Date: 2024/1/14 - 01 - 14 - 21:02
* @Decsription: com.sh.ma.service.impl
* @version: 1.0
*/
@Service
public class GoodsServiceImpl extends ServiceImpl implements GoodsService {
@Autowired
private RedissonClient redissonClient;
@Override
public void updateGoodsCount(Integer id) {
// Goods goods = this.baseMapper.selectById(id);
// Integer count = goods.getCount();
// if(count>0){
// try {
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// throw new RuntimeException(e);
// }
//this.baseMapper.subCount(id);
//this.baseMapper.subCount2(goods);
//创建锁
// RLock lock = redissonClient.getLock("goods-" + id);
// try {
// //加锁
// lock.lock();
// Goods goods = this.baseMapper.selectById(id);
// Integer count = goods.getCount();
// if (count > 0) {
// try {
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// throw new RuntimeException(e);
// }
// this.baseMapper.subCount(id);
// }
// } catch (RuntimeException e) {
// throw new RuntimeException(e);
// } finally {
// //释放锁
// lock.unlock();
// }
//zookeeper 分布式锁解决超卖问题
//1.创建zookeeper连接
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3);
CuratorFramework client= CuratorFrameworkFactory.newClient("192.168.9.132:2181", retryPolicy);
client.start();
//创建分布式锁
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/ordersettinglock");
try {
interProcessMutex.acquire();
Goods goods = this.baseMapper.selectById(id);
Integer count = goods.getCount();
if(count>0){
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.baseMapper.subCount(id);
}
} catch (Exception e) {
throw new RuntimeException("超卖了");
}finally {
//释放锁
try {
interProcessMutex.release();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}
5.5.3 总结
使用Zookeeper实现分布式锁的优点
-
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
使用Zookeeper实现分布式锁的缺点
-
性能上不如使用缓存实现分布式锁。 需要对ZK的原理有所了解,比较复杂
5.6 节 分布式锁总结
上面几种方式,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以,根据不同的应用场景选择最适合自己的才是王道。
从理解的难易程度角度(从低到高)
-
数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)
-
Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)
-
缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)
-
Zookeeper > 缓存 > 数据库