【论文笔记】Summarizing source code through heterogeneous feature fusion and extraction
Summarizing source code through heterogeneous feature fusion and extraction
-
- Abstract
- 1. Introduction
- 2. HCG construction
-
- 2.1 Source code to AST
- 2.2 AST pruning
- 2.3 Feature fusion with heterogeneous edges
- 3. HetCoS model
-
- 3.1. Overview
- 3.2. HCG encoder
- 3.3. Decoder with copying mechanism
- 4. Experimental results
- 5. Discussion
-
- 5.1 Strengths of HetCoS
- 5.2 Limitations
- 6. Conclusion

Abstract
在 HetSum 的和基础上,提出 HetCoS 通过探索源代码固有的异构性来提取源代码的语法和顺序特征以进行代码摘要。具体来说,我们首先构建一个异构代码图(HCG),它将语法结构和代码序列与图节点之间设计的八种类型的边/关系融合在一起。此外,我们提出了一种异构图神经网络来捕获 HCG 中的不同关系。然后将表示的 HCG 输入 Transformer 解码器,然后采用基于多头注意力的复制机制来支持高质量摘要生成。
1. Introduction
现有的代码摘要研究仍然存在两个主要局限性:
- 较少关注代码语法结构的异构性。边缘同质性影响了 AST 的结构独特性,这削弱了 GNN 识别 AST 节点之间不同关系的学习能力。
- 基于原始 AST 的语法结构通常很深。在之前的工作中,AST底部的节点与顶部的节点进行通信更加困难,这可能会影响编码过程中的结构特征提取。

为了解决上述限制,我们通过引入八种类型的有向边,在修剪后的 AST 上构建异构代码图(HCG)。
- 为了减少 HCG 的深度,我们考虑到源代码的布局和语法信息,删除了 AST 中的一些非叶节点(例如图 1 中的节点“block”和“expression_statement”)。删除节点后,其子节点将重新连接到其父节点以保持层次结构。保留的非叶节点可以是表示值或名称的叶节点的父节点(例如,节点“标识符”),也可以是 AST 中最深的节点(例如系节点‘‘augmented_assignment’’和‘‘if_statement’’,他们将一整行或多行源代码标记作为其后代)。直观上,图 1 中代码片段 A 前两行的 HCG 将仅由四个节点层组成。
- 为了增强 HCG 表示,我们还引入了异构边,将数据流图 (DFG)、兄弟关系以及明文代码序列集成到修剪后的 AST 中。特别地,HCG中设计了八种类型的有向边来将HCG节点连接到它们的各种邻居,包括它们的父/子节点、右/左兄弟节点、下一个/上一个DFG节点以及下一个/上一个叶节点。请注意,叶子之间的有向边可以表示明文代码序列,因为 HCG 中的叶子对应于源代码标记。边异构性可以有效地融合HCG节点之间的各种关系,同时基于指定的边类型很好地保留了HCG的结构唯一性。
- 为了利用 HCG 进行代码摘要,本文提出了一种新颖的基于编码器-解码器的方法 HetCoS。特别是,我们将广泛使用的 GraphSAGE 扩展为异构代码图神经网络(HCGNN),用于融合 HCG 特征提取。
- 在摘要生成过程中,考虑到摘要和源代码中都存在许多标记,例如变量和函数名称,HetCoS 在 Transformer 解码器和 HCG 编码器之上引入了基于多头注意力的复制机制 。复制机制允许从摘要词汇表中选择摘要令牌并从HCG节点复制,从而有利于产生更高质量的代码注释。
2. HCG construction
源代码的 HCG 构建过程如图所示。
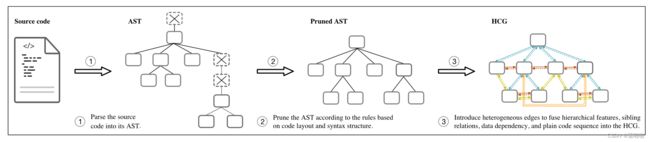
2.1 Source code to AST
给定一个代码片段,我们首先将其解析为 AST,它携带了源代码的基本层次语法特征,并且在代码理解方面取得了优异的性能。根据先前的研究,我们将连接的标识符名称(例如“snake_case”和“CamelCase”)拆分为小写的子标记(例如“snake case”和“”CamelCase’')并将它们视为单独的 AST 节点。如图所示,“bool_tag”被拆分为“bool”和“tag”作为 AST 中的两个节点。

2.2 AST pruning
根据我们的调查,代码的 AST 总是很深。这使得很难将消息从 AST 中的底部节点传播到 GNN 邻域聚合中的顶部节点。为此,我们在代码布局的指导下通过剪掉一些非叶子节点来对 AST 进行剪枝,同时保留代码的结构信息。保留的非叶节点要么是表示值或名称的叶节点的父节点,要么是 AST 中具有一整行或多行源代码标记作为其后代的最深节点。更具体地说,满足下面四个条件之一的非叶节点会被保留:
- 它在 AST 中具有最大深度并且所有叶节点都作为其后代
- 它有一个指示其值或名称的叶子节点
- 它有一个叶子节点,对应于某一源代码行中的第一个标记
- 它有一个满足第二个和第三个条件的子代。
不满足四个要求之一的节点将被删除。例如,在上图中,节点“if_statement”满足第一个和第三个条件。节点“identifier”和“augmented_assignment”分别满足第二个和第四个条件。由于节点“module”、“block”和“expression_statement”不符合任何上述标准,因此它们在 HCG 中被删除。请注意,如果删除节点,其子节点将连接到其父节点。第一是为了保证代码语法的树状结构。第二是有助于区分用户定义的值/名称(例如,节点“a”)与预定义的关键字(例如,节点“∕=”)。每个满足第三或第四条件的节点都覆盖了一行或多行源代码,直观地描绘了代码布局信息。例如,保留节点“augmented_assignment”以覆盖第二行源代码的信息。删除节点“expression_statement”和“block”后,节点“augmented_assignment”成为节点“if_statement”的子节点,该节点也连接到与第一个代码行相关的节点。
2.3 Feature fusion with heterogeneous edges
我们通过在父子对、兄弟对、DFG 节点对和叶子对之间引入异构有向边进行特征融合,将剪枝后的 AST 改进为 HCG。即,边可以从HCG节点指向其父/子节点、右/左兄弟节点、下一个/上一个DFG节点或下一个/上一个叶节点。父子边表示源代码的基本层次语法结构。兄弟节点之间的边代表HCG中的兄弟关系。 DFG 边指示每个变量来自或去向的位置,这可以进一步获取数据依赖性以实现更好的代码理解。在本研究中,从节点到其下一个(上一个) DFG 节点的边表示该节点的数据流向(来自)其下一个(上一个) DFG 节点。明文代码序列在代码摘要生成中起着至关重要的作用,通过与顺序源代码标记相对应的下一个或前一个叶之间的边集成到 HCG 中。
通过定义八种边,精确指定HCG节点之间的关联关系,将源代码的相应特征融合成统一的图。更重要的是,边异构性可以全面、唯一地保留源代码的句法和顺序信息,从而防止歧义的图表示。
3. HetCoS model
3.1. Overview
本节介绍 HetCoS 使用 HCG 生成代码摘要。如下图所示,HetCoS主要包括HCG编码器和具有复制机制的摘要解码器。给定初始 HCG 嵌入 E n 0 ∈ R l n × d E^0_n ∈ R^{l_n×d} En0∈Rln×d ,HCGNN 被设计为提取 HCG 中的融合代码特征 E n ′ ∈ R l n × d E^{'}_n ∈ R^{l_n×d} En′∈Rln×d ,其中 l n l_n ln 表示 HCG 节点的数量, d d d 表示嵌入大小。之后,HetCoS 对嵌入的摘要标记 E s 0 ∈ R l s × d E^0_s ∈ R^{l_s×d} Es0∈Rls×d 和学习的 HCG 表示 E n ′ E'_n En′ 执行 Transformer 解码器,以生成解码向量 e s ′ ∈ R d e'_s ∈ R^d es′∈Rd ,其中 l s l_s ls 表示摘要长度。为了处理同时出现在摘要和源代码中的标记(例如变量和函数名称),我们引入了基于多头注意力的复制机制来根据 E n ′ E'_n En′ 和 e ′ e′ e′ 预测后续的摘要标记 s m s_m sm 。它允许从摘要词汇表中选择 s m s_m sm 并从 HCG 节点复制。每个组件将在以下小节中详细介绍。

3.2. HCG encoder
鉴于 GraphSAGE 在图表示学习方面的成功,我们通过扩展 GraphSAGE 来捕获 HCG 中的异构特征来开发 HCGNN。上图描述了 HCG 编码器由六个不同的 HCGNN 层组成。在第 k k k 层中,HCG首先由异构的 GraphSAGE 处理。具体来说,对于 HCG 节点 i i i,其状态通过其邻居与通向该节点的异构边的两步聚合来更新。
第一步,将具有不同边缘类型的邻居分别聚合到不同的邻居组中。对于边类型 g g g,聚合形式化如下:
![]()
其中 N g ( i ) \mathcal{N}_g(i) Ng(i) 表示节点 i i i 的边类型为 g g g 的邻居集合; e g , j k − 1 ∈ R d e^{k−1}_{g,j} ∈ R^d eg,jk−1∈Rd 表示第 ( k − 1 ) (k−1) (k−1) 层产生的边类型为 g g g 的第 j j j 个邻居向量; A g g r 1 Aggr1 Aggr1 表示聚合运算符。
第二步,对邻居组进行变换和聚合,以更新节点 i i i 的状态。该过程正式如下:
![]()
其中 e i k − 1 ∈ R d e^{k−1}_{i} ∈ R^d eik−1∈Rd 表示前一层生成的节点 i i i 的向量表示; G ( i ) \mathcal{G}(i) G(i) 表示指向节点 i 的边的类型; W 0 , W g ∈ R d × d W_0,W_g ∈ R^{d×d} W0,Wg∈Rd×d 表示可训练的权重矩阵; A g g r 2 Aggr2 Aggr2 是聚合函数。
所有节点状态更新后,状态向量被连接并发送到 R e L U ReLU ReLU 激活中进行非线性变换:
![]()
随着更多 HCGNN 层的堆叠,节点会从更远的距离收集其邻近信息,提取更多的异构特征。为了减轻多层计算中的梯度消失和过多的向量偏移,我们将残差连接以及图归一化合并到每个HCGNN模块中,其形式化如下:

其中 E n k − 1 ∈ R l n × d E^{k−1}_n ∈ R^{l_n×d} Enk−1∈Rln×d 表示第 ( k − 1 ) (k−1) (k−1) HCGNN层输出的 HCG 节点状态向量。
3.3. Decoder with copying mechanism
HetCoS 中的解码器设计有八个普通 Transformer 解码层堆栈。每层包含三个子层,包括用于对现有摘要标记进行自注意力编码的屏蔽多头注意力、用于对学习的 HCG 节点进行解码的标准多头注意力以及完全连接的位置式前馈网络(FFN)。所有子层都执行残差连接和层归一化。提供来自第 ( k − 1 ) (k − 1) (k−1) 层的现有摘要标记的向量 E s k − 1 ∈ R l s × d E^{k−1}_s ∈ R^{l_s×d} Esk−1∈Rls×d和提取的 HCG 表示 E n ′ ∈ R l n × d E'_n ∈ R^{l_n×d} En′∈Rln×d ,第 k k k 个 Transformer 层的解码过程形式化如下:
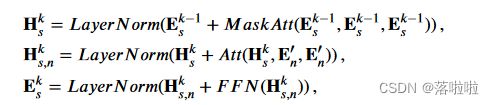
其中 M a s k A t t MaskAtt MaskAtt 和 A t t Att Att 分别表示屏蔽多头注意力和标准多头注意力,两者都以查询、键和值向量作为输入来挖掘它们之间的关系。
解码后,HetCoS 在解码器和编码器上实现基于多头注意力的复制机制,以生成后续的摘要令牌。对于第 m m m 个输出 token,复制机制首先从摘要词汇和 HCG 节点导出两个概率分布 p v p_v pv 和 p n p_n pn,然后利用它们来确定 token 的输出概率。为了获得 p v p_v pv,我们对解码后的摘要标记向量 e s ′ ∈ R d e'_s ∈ Rd es′∈Rd 执行线性子层,然后执行 S o f t m a x Softmax Softmax,其公式如下:
![]()
请注意,如果标记 w w w 未包含在摘要词汇表中,则 p v ( w ) p_v(w) pv(w) 被分配为 0。
为了计算 p n p_n pn,我们首先在解码向量 e s ′ ∈ R d e'_s ∈ Rd es′∈Rd 以及学习的 HCG 表示 E n ′ ∈ R l n × d E'_n ∈ R^{l_n×d} En′∈Rln×d 上部署多头注意力子层,其公式如下:
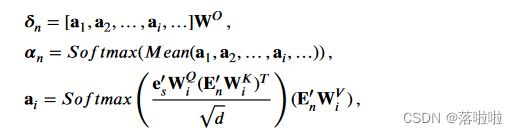
其中 W i Q , W i K , W i V , W O W^Q_i,W^K_i,W^V_i,W^O WiQ,WiK,WiV,WO 表示可训练参数。然后,总结标记 w w w 的概率 p n ( w ) p_n(w) pn(w) 可以计算如下:

其中 w i w_i wi表示 HCG 中的节点 i i i。最终,标记 w w w 的输出似然,表示为 p s ( w ) p_s(w) ps(w),将由概率 p v p_v pv 和 p n p_n pn 的加权和确定:
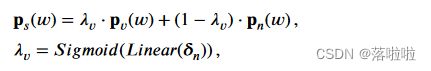
其中 λ v ∈ [ 0 , 1 ] λ_v ∈ [0, 1] λv∈[0,1] 是权重值。
4. Experimental results

本节对两个数据集进行消融研究,以研究我们的方法中组件的有用性。为此,我们首先设计了六个变体模型进行比较,每个模型都去除了HetCoS的一个重要组成部分,包括:
- 丢弃复制机制的R-Copy
- 去除编码器中残留连接的R-EncRes
- 忽略HCG中的异质性的R-Het
- 排除HCG中代码标记(即叶节点)之间的边的R-CodeEdge
- 排除HCG中兄弟节点之间的边的R-SibEdge HCG
- R-DFG,排除HCG中的DFG。
为了进一步验证,我们构建了四个变体:
- 保留 AST 所有节点进行编码的 V-AST
- 使用 GCN 覆盖 HCGNN 中使用的 GraphSAGE 的 V-HetGCN
- V- HetGAT 引入 GAT 代替 GraphSAGE
- V-HetGT 用 Graph Transformer 代替 GraphSAGE。

5. Discussion
5.1 Strengths of HetCoS
HetCoS 有两个优点导致其在代码摘要方面的优越性:
- 好处之一在于源代码的异构融合图表示。基于修剪后的 AST,所提出的 HCG 将源代码的顺序和句法特征融合成异构结构,同时减少 AST 深度。通过利用八种类型的边,HCG 在保留其结构唯一性的同时精确捕获各种节点到节点的关系。
- 有效的基于编码器-解码器的神经模型为代码摘要增强提供了进一步的优势。特别是,HetCoS 模型堆叠多个 HCGNN 层来提取 HCG 中的异构代码特征,以实现卓越的代码理解。多头注意力复制机制还有助于生成更高质量的代码注释。
5.2 Limitations
值得一提的是,这项研究仍然存在三个局限性,我们希望在后续工作中克服:
- 第一个限制涉及 HCG 结构代码表示的能力。在本文中,我们设计了HCG来减少AST深度并融合图节点之间的各种关系。尽管如此,我们建议挖掘源代码中新的异构结构特征并将其融合到 HCG 中,以实现更好的代码理解。
- 我们的 HetCoS 模型的可扩展性是第二个限制。这项工作旨在挖掘源代码的结构异构性来提升代码摘要生成的性能。因此,它与依赖预训练范式的方法是正交的。即便如此,HetCoS 有潜力通过纳入预训练范式来得到加强,我们将其作为未来研究的重要主题。
- 第三个限制与本研究的可扩展性有关。具体来说,我们的工作集中在自动代码摘要的任务上。事实上,所提出的HetCoS框架还可以应用或转移到其他相关任务,例如代码完成和编程语言翻译。这些任务的表现需要大量的实验来证明。
6. Conclusion
本文提出了一种基于编码器-解码器的代码摘要架构 HetCoS。给定一个代码片段,HetCoS 首先设计一个具有八种不同类型边的 HCG,以融合源代码的异构特征。同时,提出了HCGNN来对HCG表示进行编码。然后,HetCoS引入了Transformer解码器进行摘要解码,并通过结合基于多头注意的复制机制进一步改进。通过在 Java 和 Python 两个基准上进行的综合实验,结果表明 HetCoS 在代码摘要方面比竞争基准具有更优越的性能。