解析Transformer模型
原文地址:https://zhanghan.xyz/posts/17281/
进入Transformer
RNN很难处理冗长的文本序列,且很容易受到所谓梯度消失/爆炸的问题。RNN是按顺序处理单词的,所以很难并行化。
用一句话总结Transformer:当一个扩展性极佳的模型和一个巨大的数据集邂逅,结果可能会让你大吃一惊。
Transformer是如何工作的?
1.位置编码(Positional Encodings)
RNN中按照顺序处理单词,很难并行化。
位置编码的思路:将输入序列中的所有单词后面加上一个数字,表明它的顺序。
[("Dala",1),("say",1),("hello",1),("world",1)]
原文中使用正弦函数进行位置编码
要点:将语序存储作为数据,而不是靠网络结构,这样你的神经网络就更容易训练了。
2.注意力机制(Attention)
注意力是一种机制,它允许文本模型在决定如何翻译输出句子中的单词时“查看”原始句子中的每个单词。
图源:[1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate (arxiv.org)
模型如何知道在每个时间步长中应该注意哪些单词:就是从训练数据中学到的东西,通过观察成千上万的法语和英语句子,学会了什么类型的单词是相互依赖的。
3.自注意力机制(Self-Attention)
如何不是试图翻译单词,而是建立一个理解语言中的基本含义和模式的模型——一种可以用来做任何数量的语言任务的模型,怎么办?
自注意力帮助神经网络消除单词歧义,做词性标注,命名实体识别,学习语义角色等等。
以上仅为读【解析 Transformer 模型:理解 GPT-3、BERT 和 T5 背后的模型】
的笔记,以下是我对Transformer进行的详细理解和技术解析。
Transformer技术解析
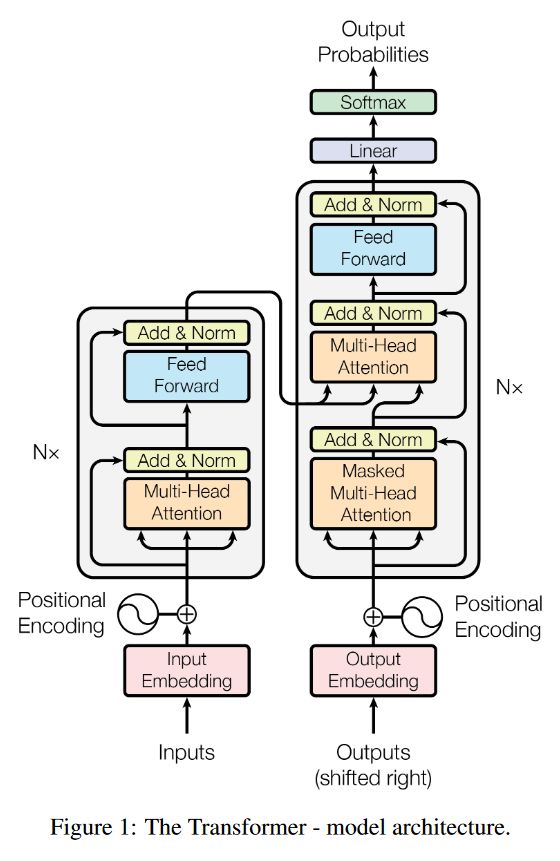
1.位置编码Positional Encoding
从上面的整体框架图可以看出,Transformer中的Encoder和Decoder都是通过堆叠多头自注意力和全连接层得到的,不管是Encoder还是Decoder的输入,都进行了Positional Encoding,对于位置编码的作用,在原文是这样解释的:
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed
由于我们的模型不包含递归和卷积,为了使模型能够利用序列的顺序,我们必须在序列中注入一些关于token的相对或绝对位置的信息。为此,我们在编码器和解码器堆栈底部的输入嵌入中加入位置编码。位置编码与embeddings具有相同的维数d,因此可以将两者求和。位置编码有多种选择,有学习的,也有固定的。
Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
理想状态下,编码方式应该要满足以下几个条件,
- 对于每个位置的词语,它都能提供一个独一无二的编码
- 词语之间的间隔对于不同长度的句子来说,含义应该是一致的
- 能够随意延伸到任意长度的句子
以下是Transformer中使用的位置编码的公式:

PE将正弦函数用于偶数嵌入索引i,余弦函数用于奇数嵌入索引i。


代码实现:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 初始化位置编码矩阵
pe = torch.zeros(max_len, d_model)
# 计算位置编码
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 将位置编码矩阵转换为张量
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
这里再引申一下为什么位置嵌入会有用:

得出一个结论: P E p o s + k PE~pos+k~ PE pos+k 可以被 P E p o s PE~pos~ PE pos 线性表示。从这一点来说,位置编码是可以反应一定的相对位置信息。
但是这种相对位置信息会在注意力机制那里消失。
2.多头注意力机制
为什么Transformer 需要进行 Multi-head Attention?
最终的原因可以通过两句话来概括:
①为了解决模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身位置的问题;
②一定程度上ℎ越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
self-Attention自注意力机制
所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型。
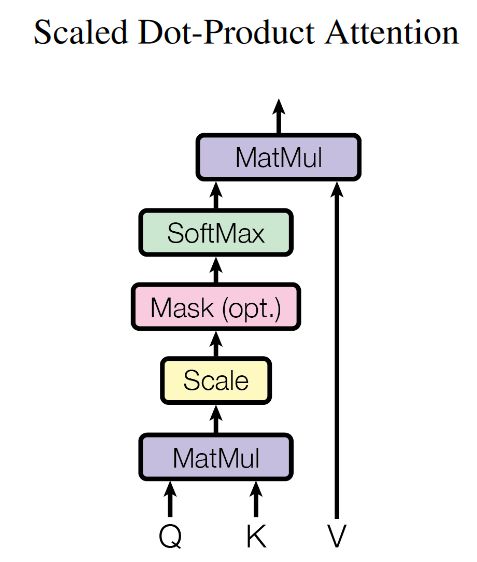
从上图可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:
q i = W q ⋅ a i k i = W k ⋅ a i v i = W v ⋅ a i α i , j = q i ⋅ k j A = softmax ( Q K T d k ) Attention ( Q , K , V ) = A V \\\begin{align*}q^{i} &= W^{q} \cdot a^{i} \\k^{i} &= W^{k} \cdot a^{i} \\v^{i} &= W^{v} \cdot a^{i} \\\alpha_{i,j} &= q^{i} \cdot k^{j} \\A &= \text{softmax}\left(\frac{QK^{T}}{\sqrt{d_k}}\right) \\\text{Attention}(Q, K, V) &= AV\\\end{align*} qikiviαi,jAAttention(Q,K,V)=Wq⋅ai=Wk⋅ai=Wv⋅ai=qi⋅kj=softmax(dkQKT)=AV
- 首先,对于输入序列中的每个元素,我们计算查询向量(Query)、键向量(Key)和值向量(Value),其中,Wq、Wk和Wv是需要学习的参数矩阵,ai是输入序列的第i个元素。
- 然后,我们利用查询向量和键向量来计算注意力得分(Attention Score),这里,αi,j表示第i个元素和第j个元素之间的注意力得分。
- 接着,我们对注意力得分进行缩放处理并应用softmax函数,以得到注意力权重。其中,Q和K分别是所有查询向量和键向量构成的矩阵,dk是键向量的维度。
- 最后,我们利用注意力权重和值向量来计算自注意力机制的输出。其中,V是所有值向量构成的矩阵,A是注意力权重矩阵。

通过这种自注意力机制的方式确实解决了“传统序列模型在编码过程中都需顺序进行的弊端”的问题,有了自注意力机制后,仅仅只需要对原始输入进行几次矩阵变换便能够得到最终包含有不同位置注意力信息的编码向量。
MultiHeadAttention
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,因此提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
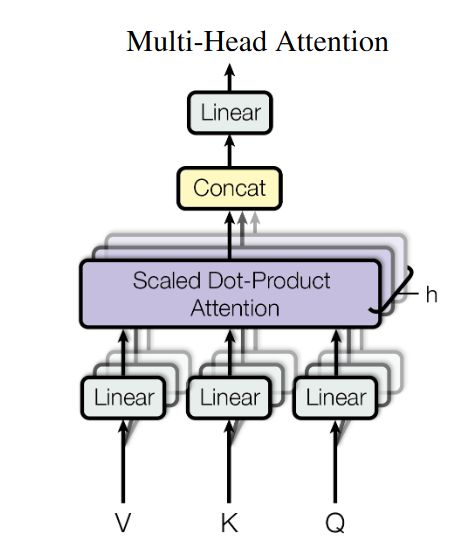
所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理过程;然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。
Q i = W i Q ⋅ X K i = W i K ⋅ X V i = W i V ⋅ X α i , j = Q i ⋅ K j d k A i = softmax ( α i , j ) head i = A i ⋅ V i MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head H ) ⋅ W O \begin{align*}Q_i &= W_i^Q \cdot X \\K_i &= W_i^K \cdot X \\V_i &= W_i^V \cdot X \\\alpha_{i,j} &= \frac{Q_i \cdot K_j}{\sqrt{d_k}} \\A_i &= \text{softmax}(\alpha_{i,j}) \\\text{head}_i &= A_i \cdot V_i \\\text{MultiHead}(Q, K, V) &= \text{Concat}(\text{head}_1, ..., \text{head}_H) \cdot W^O\end{align*} QiKiViαi,jAiheadiMultiHead(Q,K,V)=WiQ⋅X=WiK⋅X=WiV⋅X=dkQi⋅Kj=softmax(αi,j)=Ai⋅Vi=Concat(head1,...,headH)⋅WO
为什么要使用多头
根据下图多头注意力计算方式我们可以发现,在dm固定的情况下,不管是使用单头还是多头的方式,在实际的处理过程中直到进行注意力权重矩阵计算前,两者之前没有任何区别。当进行进行注意力权重矩阵计算时,ℎ越大那么Q,K,V就会被切分得越小,进而得到的注意力权重分配方式越多。图源:
This post is all you need(上卷)——层层剥开Transformer
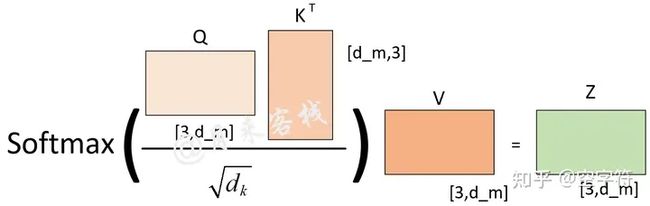
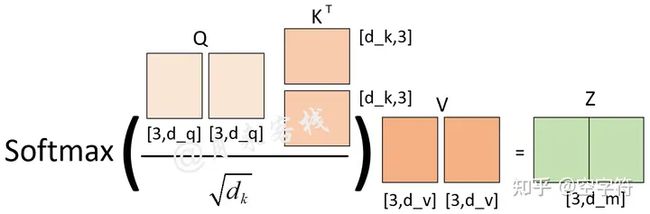
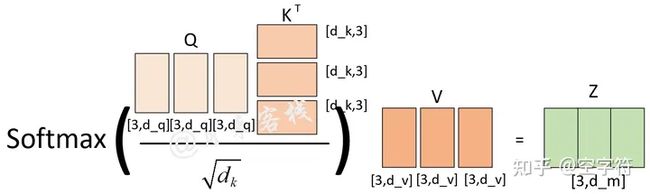

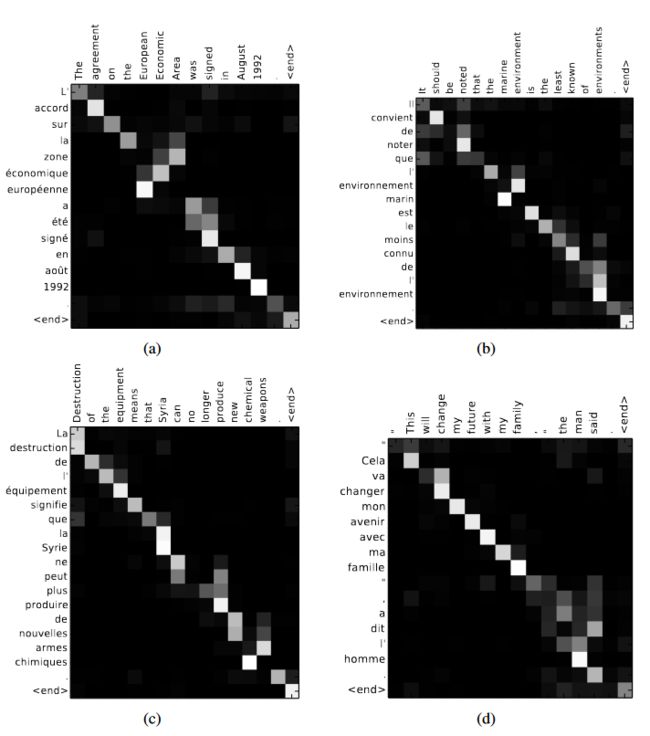
从上图可以看出,如果ℎ=1,那么最终可能得到的就是一个各个位置只集中于自身位置的注意力权重矩阵;如果ℎ=2,那么就还可能得到另外一个注意力权重稍微分配合理的权重矩阵;ℎ=3同理如此。因而多头这一做法也恰好是论文作者提出用于克服模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置的问题。这里再插入一张真实场景下同一层的不同注意力权重矩阵可视化结果图:

同时,当ℎ不一样时,dk的取值也不一样,进而使得对权重矩阵的scale的程度不一样。例如,如果dm=768,那么当ℎ=12时,则dk=64;当ℎ=1时,则dk=768。
所以,当模型的维度dm确定时,一定程度上ℎ越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
3.Encoder层
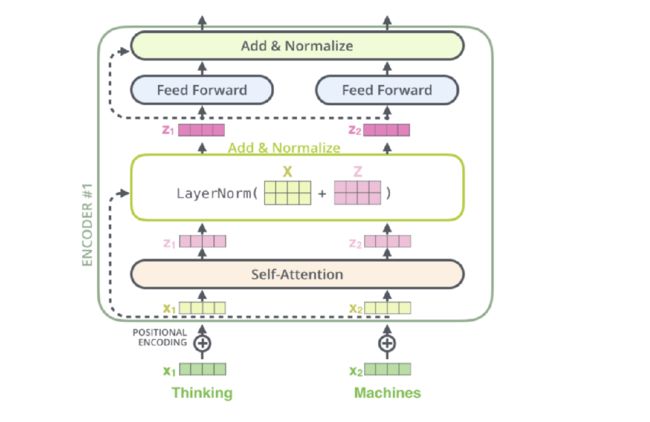
对于Encoder部分来说其内部主要由两部分网络所构成:多头注意力机制和两层前馈神经网络。同时,对于这两部分网络来说,都加入了残差连接,并且在残差连接后还进行了层归一化操作。这样,对于每个部分来说其输出均为LayerNorm(x+Sublayer(x)),并且在都加入了Dropout操作。对于第2部分的两层全连接网络来说,其具体计算过程为:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0, xW1 + b1)W2 + b2 FFN(x)=max(0,xW1+b1)W2+b2
4.Decoder层
对于Decoder部分来说,其整体上与Encoder类似,只是多了一个用于与Encoder输出进行交互的多头注意力机制。
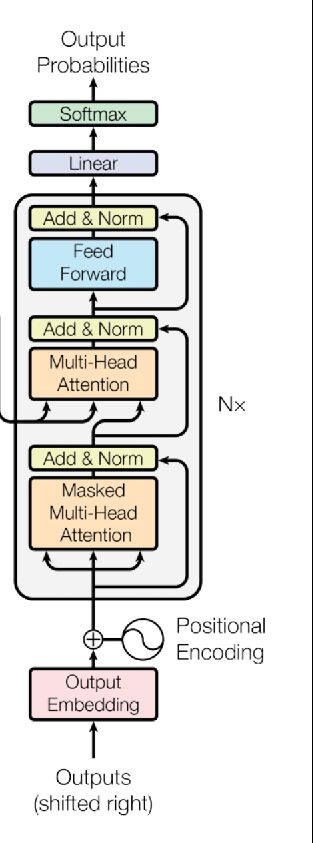
不同于Encoder部分,在Decoder中一共包含有3个部分的网络结构。最上面的和最下面的部分(暂时忽略Mask)与Encoder相同,只是多了中间这个与Encoder输出(Memory)进行交互的部分,作者称之为“Encoder-Decoder attention”。对于这部分的输入,Q来自于下面多头注意力机制的输出,K和V均是Encoder部分的输出(Memory)经过线性变换后得到。
在Decoder对每一个时刻进行解码时,首先需要做的便是通过Q与 K进行交互(query查询),并计算得到注意力权重矩阵;然后再通过注意力权重与V进行计算得到一个权重向量,该权重向量所表示的含义就是在解码时如何将注意力分配到Memory的各个位置上。
Decoder解码预测过程
Decoder训练解码过程
在介绍完预测时Decoder的解码过程后,下面就继续来看在网络在训练过程中是如何进行解码的。在真实预测时解码器需要将上一个时刻的输出作为下一个时刻解码的输入,然后一个时刻一个时刻的进行解码操作。显然,如果训练时也采用同样的方法那将是十分费时的。因此,在训练过程中,解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。这样做的好处,一是通过多样本并行计算能够加快网络的训练速度;二是在训练过程中直接喂入解码器正确的结果而不是上一时刻的预测值(因为训练时上一时刻的预测值可能是错误的)能够更好的训练网络。
例如在用平行预料"我 是 谁"<==>"who am i"对网络进行训练时,编码器的输入便是"我 是 谁",而解码器的输入则是",对应的正确标签则是 who am i""who am i
但是,模型在实际的预测过程中只是将当前时刻之前(包括当前时刻)的所有时刻作为输入来预测下一个时刻,也就是说模型在预测时是看不到当前时刻之后的信息。因此,Transformer中的Decoder通过加入注意力掩码机制来解决了这一问题。
左边依旧是通过Q和K计算得到了注意力权重矩阵(此时还未进行softmax操作),而中间的就是所谓的注意力掩码矩阵,两者在相加之后再乘上矩阵V便得到了整个自注意力机制的输出。
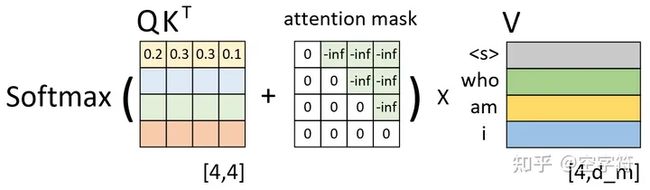
5.残差和LayerNorm
残差
在Transformer中,数据过Attention层和FFN层后,都会经过一个Add & Norm处理。其中,Add为residule block(残差模块),数据在这里进行residule connection(残差连接)。
在transformer的encoder和decoder中,各用到了6层的attention模块,每一个attention模块又和一个FeedForward层(简称FFN)相接。对每一层的attention和FFN,都采用了一次残差连接,即把每一个位置的输入数据和输出数据相加,使得Transformer能够有效训练更深的网络。在残差连接过后,再采取Layer Nomalization的方式。具体的操作过程见下图:

LayerNorm
为什么在NLP任务中(Transformer),使用LayerNorm而不是BatchNorm。
首先,BN不适合RNN这种动态文本模型,有一个原因是因为batch中的长度不一致,导致有的靠后的特征的均值和方差不能估算。
但是这个问题不是大问题,可以在处理数据的适合,使句子的长度相近的在一个batch,所以这不是NLP中不用BN的核心原因。
BN是对每个特征的batch_size上求得均值和方差,就是对每个特征,这些特征都有明确得含义,比如身高、体重等。但是想象以下,如果BN应用到NLP任务,就变成了对每个单词,也就是默认了在同一个位置得单词对应的是同一个特征,比如:“我/期待/全新/AGI”和“今天/天气/真/不错“,使用BN代表着”我“和”今天“是对应同一个维度的特征,才能做BN。
LayNorm做的事针对每一个样本,做特征的缩放。也就是,它认为“我/期待/全新/AGI”这四个词在同一个特征下,基于此做归一化。这样做和BN的区别在于,一句话中的每个单词都可以归到这句话的”语义信息“这个特征中。所以这里不再对应batch_size,而是文本长度。
引申-为什么BN在CNN中可以而在NLP中不行
浅浅理解:BN在NLP中是对词向量进行缩放,词向量是我们学习出来的参数来表示词语语义的参数,不是真实存在的。而图像像素是真实存在的,像素中包含固有的信息。
6.问题解析
Transformer的并行化
Decoder不用多说,没有并行,只能一个一个解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
Encoder:首先,6个大的模块之间是串行的,一个模块的计算结果作为下一个模块的输入,互相之间有依赖关系。对于每个模块,注意力层和前馈神经网络这两个子模块单独看都是可以并行的,不同的单词之间是没有依赖关系的,当然对于注意力层在做attention时会依赖别的时刻的输入。然后注意力层和前馈网络之间时串行的,必须先完成注意力层计算再做前馈网络。
为什么Q和K使用不同的权重矩阵生成,不能使用同一个值进行自身的点乘
简单回答:使用QKV不相同可以保证在不同空间进行投影,增强了表达能力,提高泛化能力。
详细解释:
transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值? - 知乎
Transformer计算attention时候为什么选择点乘而不是加法,在计算复杂度和效果上有什么区别
实验分析,时间复杂度相似;效果上,和dk相关,dk越大,加法效果越显著。
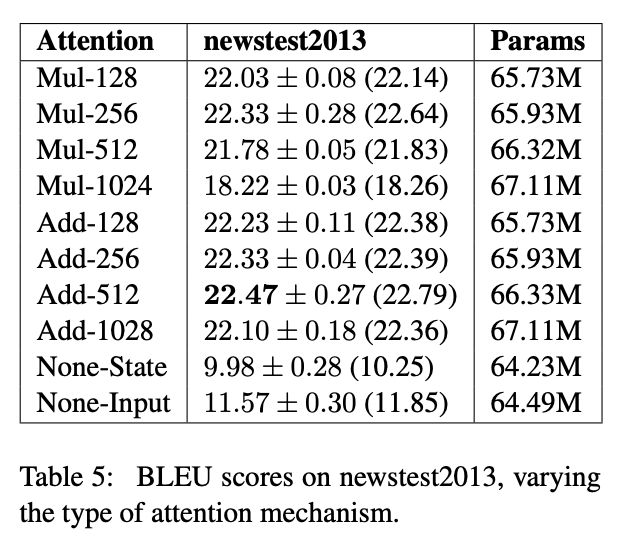
transformer中的attention为什么scaled
根据上一个问题,在dk(即 attention-dim)较小的时候,两者的效果接近。但是随着dk增大,Add 开始显著超越 Mul。作者分析 Mul 性能不佳的原因,认为是极大的点积值将整个 softmax 推向梯度平缓区,使得收敛困难。
这才有了 scaled。所以,Add 是天然地不需要 scaled,Mul 在dk较大的时候必须要做 scaled。个人认为,Add 中的矩阵乘法,和 Mul 中的矩阵乘法不同。前者中只有随机变量 X 和参数矩阵W 相乘,但是后者中包含随机变量 X 和随机变量 X 之间的乘法。
下面附上在知乎看到的代码数值实验就很清楚:
from scipy.special import softmax
import numpy as np
def test_gradient(dim, time_steps=50, scale=1.0):
# Assume components of the query and keys are drawn from N(0, 1) independently
q = np.random.randn(dim)
ks = np.random.randn(time_steps, dim)
x = np.sum(q * ks, axis=1) / scale # x.shape = (time_steps,)
y = softmax(x)
grad = np.diag(y) - np.outer(y, y)
return np.max(np.abs(grad)) # the maximum component of gradients
NUMBER_OF_EXPERIMENTS = 5
# results of 5 random runs without scaling
print([test_gradient(100) for _ in range(NUMBER_OF_EXPERIMENTS)])
print([test_gradient(1000) for _ in range(NUMBER_OF_EXPERIMENTS)])
# results of 5 random runs with scaling
print([test_gradient(100, scale=np.sqrt(100)) for _ in range(NUMBER_OF_EXPERIMENTS)])
print([test_gradient(1000, scale=np.sqrt(1000)) for _ in range(NUMBER_OF_EXPERIMENTS)])
# 不带 scaling 的两组(可以看到 dim=1000 时很容易发生梯度消失):
[1.123056543761436e-06, 0.14117211040878508, 0.24896212285554725, 0.000861296669097178, 0.24717750591081689]
[1.2388028380883043e-09, 3.630249703743676e-18, 1.4210854715202004e-14, 1.1652900866465643e-12, 5.045026175709566e-07]
# 带 scaling 的两组(dim=1000 时梯度流依然稳定):
[0.11292476415310426, 0.08650727907448993, 0.11307320939056421, 0.2039260641245917, 0.11422935801305531]
[0.12367058336991178, 0.15990586501130605, 0.1701746604359328, 0.10761820500367032, 0.07591586878293968]