flink1.15消费kafka之checkpoint 二
前言
上一篇讲解了checkpoint恢复的流程,以及checkpoint恢复时如何从状态中获取topic、partition,开始offset值,本篇主要如何取到offset值进行消费的。
流程
Task运行时,首先调用doRun方法:
public void run() {
try {
doRun();
} finally {
terminationFuture.complete(executionState);
}
}
private void doRun() {
// ----------------------------
// Initial State transition
// ----------------------------
while (true) {
ExecutionState current = this.executionState;
if (current == ExecutionState.CREATED) {
if (transitionState(ExecutionState.CREATED, ExecutionState.DEPLOYING)) {
// success, we can start our work
break;
}
} else if (current == ExecutionState.FAILED) {
// we were immediately failed. tell the TaskManager that we reached our final state
notifyFinalState();
if (metrics != null) {
metrics.close();
}
return;
} else if (current == ExecutionState.CANCELING) {
if (transitionState(ExecutionState.CANCELING, ExecutionState.CANCELED)) {
// we were immediately canceled. tell the TaskManager that we reached our final
// state
notifyFinalState();
if (metrics != null) {
metrics.close();
}
return;
}
} else {
if (metrics != null) {
metrics.close();
}
throw new IllegalStateException(
"Invalid state for beginning of operation of task " + this + '.');
}
}
// all resource acquisitions and registrations from here on
// need to be undone in the end
Map> distributedCacheEntries = new HashMap<>();
TaskInvokable invokable = null;
try {
// ----------------------------
// Task Bootstrap - We periodically
// check for canceling as a shortcut
// ----------------------------
// activate safety net for task thread
LOG.debug("Creating FileSystem stream leak safety net for task {}", this);
FileSystemSafetyNet.initializeSafetyNetForThread();
// first of all, get a user-code classloader
// this may involve downloading the job's JAR files and/or classes
LOG.info("Loading JAR files for task {}.", this);
userCodeClassLoader = createUserCodeClassloader();
final ExecutionConfig executionConfig =
serializedExecutionConfig.deserializeValue(userCodeClassLoader.asClassLoader());
if (executionConfig.getTaskCancellationInterval() >= 0) {
// override task cancellation interval from Flink config if set in ExecutionConfig
taskCancellationInterval = executionConfig.getTaskCancellationInterval();
}
if (executionConfig.getTaskCancellationTimeout() >= 0) {
// override task cancellation timeout from Flink config if set in ExecutionConfig
taskCancellationTimeout = executionConfig.getTaskCancellationTimeout();
}
if (isCanceledOrFailed()) {
throw new CancelTaskException();
}
// ----------------------------------------------------------------
// register the task with the network stack
// this operation may fail if the system does not have enough
// memory to run the necessary data exchanges
// the registration must also strictly be undone
// ----------------------------------------------------------------
LOG.debug("Registering task at network: {}.", this);
setupPartitionsAndGates(consumableNotifyingPartitionWriters, inputGates);
for (ResultPartitionWriter partitionWriter : consumableNotifyingPartitionWriters) {
taskEventDispatcher.registerPartition(partitionWriter.getPartitionId());
}
// next, kick off the background copying of files for the distributed cache
try {
for (Map.Entry entry :
DistributedCache.readFileInfoFromConfig(jobConfiguration)) {
LOG.info("Obtaining local cache file for '{}'.", entry.getKey());
Future cp =
fileCache.createTmpFile(
entry.getKey(), entry.getValue(), jobId, executionId);
distributedCacheEntries.put(entry.getKey(), cp);
}
} catch (Exception e) {
throw new Exception(
String.format(
"Exception while adding files to distributed cache of task %s (%s).",
taskNameWithSubtask, executionId),
e);
}
if (isCanceledOrFailed()) {
throw new CancelTaskException();
}
// ----------------------------------------------------------------
// call the user code initialization methods
// ----------------------------------------------------------------
TaskKvStateRegistry kvStateRegistry =
kvStateService.createKvStateTaskRegistry(jobId, getJobVertexId());
Environment env =
new RuntimeEnvironment(
jobId,
vertexId,
executionId,
executionConfig,
taskInfo,
jobConfiguration,
taskConfiguration,
userCodeClassLoader,
memoryManager,
ioManager,
broadcastVariableManager,
taskStateManager,
aggregateManager,
accumulatorRegistry,
kvStateRegistry,
inputSplitProvider,
distributedCacheEntries,
consumableNotifyingPartitionWriters,
inputGates,
taskEventDispatcher,
checkpointResponder,
operatorCoordinatorEventGateway,
taskManagerConfig,
metrics,
this,
externalResourceInfoProvider);
// Make sure the user code classloader is accessible thread-locally.
// We are setting the correct context class loader before instantiating the invokable
// so that it is available to the invokable during its entire lifetime.
executingThread.setContextClassLoader(userCodeClassLoader.asClassLoader());
// When constructing invokable, separate threads can be constructed and thus should be
// monitored for system exit (in addition to invoking thread itself monitored below).
FlinkSecurityManager.monitorUserSystemExitForCurrentThread();
try {
// now load and instantiate the task's invokable code
invokable =
loadAndInstantiateInvokable(
userCodeClassLoader.asClassLoader(), nameOfInvokableClass, env);
} finally {
FlinkSecurityManager.unmonitorUserSystemExitForCurrentThread();
}
// ----------------------------------------------------------------
// actual task core work
// ----------------------------------------------------------------
// we must make strictly sure that the invokable is accessible to the cancel() call
// by the time we switched to running.
this.invokable = invokable;
restoreAndInvoke(invokable);
// make sure, we enter the catch block if the task leaves the invoke() method due
// to the fact that it has been canceled
if (isCanceledOrFailed()) {
throw new CancelTaskException();
}
// ----------------------------------------------------------------
// finalization of a successful execution
// ----------------------------------------------------------------
// finish the produced partitions. if this fails, we consider the execution failed.
for (ResultPartitionWriter partitionWriter : consumableNotifyingPartitionWriters) {
if (partitionWriter != null) {
partitionWriter.finish();
}
}
// try to mark the task as finished
// if that fails, the task was canceled/failed in the meantime
if (!transitionState(ExecutionState.RUNNING, ExecutionState.FINISHED)) {
throw new CancelTaskException();
}
} catch (Throwable t) {
// ----------------------------------------------------------------
// the execution failed. either the invokable code properly failed, or
// an exception was thrown as a side effect of cancelling
// ----------------------------------------------------------------
t = preProcessException(t);
try {
// transition into our final state. we should be either in DEPLOYING, INITIALIZING,
// RUNNING, CANCELING, or FAILED
// loop for multiple retries during concurrent state changes via calls to cancel()
// or to failExternally()
while (true) {
ExecutionState current = this.executionState;
if (current == ExecutionState.RUNNING
|| current == ExecutionState.INITIALIZING
|| current == ExecutionState.DEPLOYING) {
if (ExceptionUtils.findThrowable(t, CancelTaskException.class)
.isPresent()) {
if (transitionState(current, ExecutionState.CANCELED, t)) {
cancelInvokable(invokable);
break;
}
} else {
if (transitionState(current, ExecutionState.FAILED, t)) {
cancelInvokable(invokable);
break;
}
}
} else if (current == ExecutionState.CANCELING) {
if (transitionState(current, ExecutionState.CANCELED)) {
break;
}
} else if (current == ExecutionState.FAILED) {
// in state failed already, no transition necessary any more
break;
}
// unexpected state, go to failed
else if (transitionState(current, ExecutionState.FAILED, t)) {
LOG.error(
"Unexpected state in task {} ({}) during an exception: {}.",
taskNameWithSubtask,
executionId,
current);
break;
}
// else fall through the loop and
}
} catch (Throwable tt) {
String message =
String.format(
"FATAL - exception in exception handler of task %s (%s).",
taskNameWithSubtask, executionId);
LOG.error(message, tt);
notifyFatalError(message, tt);
}
} finally {
try {
LOG.info("Freeing task resources for {} ({}).", taskNameWithSubtask, executionId);
// clear the reference to the invokable. this helps guard against holding references
// to the invokable and its structures in cases where this Task object is still
// referenced
this.invokable = null;
// free the network resources
releaseResources();
// free memory resources
if (invokable != null) {
memoryManager.releaseAll(invokable);
}
// remove all of the tasks resources
fileCache.releaseJob(jobId, executionId);
// close and de-activate safety net for task thread
LOG.debug("Ensuring all FileSystem streams are closed for task {}", this);
FileSystemSafetyNet.closeSafetyNetAndGuardedResourcesForThread();
notifyFinalState();
} catch (Throwable t) {
// an error in the resource cleanup is fatal
String message =
String.format(
"FATAL - exception in resource cleanup of task %s (%s).",
taskNameWithSubtask, executionId);
LOG.error(message, t);
notifyFatalError(message, t);
}
// un-register the metrics at the end so that the task may already be
// counted as finished when this happens
// errors here will only be logged
try {
metrics.close();
} catch (Throwable t) {
LOG.error(
"Error during metrics de-registration of task {} ({}).",
taskNameWithSubtask,
executionId,
t);
}
}
}
restoreAndInvoke方法中进行恢复操作:
private void restoreAndInvoke(TaskInvokable finalInvokable) throws Exception {
try {
// switch to the INITIALIZING state, if that fails, we have been canceled/failed in the
// meantime
if (!transitionState(ExecutionState.DEPLOYING, ExecutionState.INITIALIZING)) {
throw new CancelTaskException();
}
taskManagerActions.updateTaskExecutionState(
new TaskExecutionState(executionId, ExecutionState.INITIALIZING));
// make sure the user code classloader is accessible thread-locally
executingThread.setContextClassLoader(userCodeClassLoader.asClassLoader());
runWithSystemExitMonitoring(finalInvokable::restore);
if (!transitionState(ExecutionState.INITIALIZING, ExecutionState.RUNNING)) {
throw new CancelTaskException();
}
// notify everyone that we switched to running
taskManagerActions.updateTaskExecutionState(
new TaskExecutionState(executionId, ExecutionState.RUNNING));
runWithSystemExitMonitoring(finalInvokable::invoke);
} catch (Throwable throwable) {
try {
runWithSystemExitMonitoring(() -> finalInvokable.cleanUp(throwable));
} catch (Throwable cleanUpThrowable) {
throwable.addSuppressed(cleanUpThrowable);
}
throw throwable;
}
runWithSystemExitMonitoring(() -> finalInvokable.cleanUp(null));
}
接下来执行StreamTask的restore方法:
public final void restore() throws Exception {
restoreInternal();
}
void restoreInternal() throws Exception {
if (isRunning) {
LOG.debug("Re-restore attempt rejected.");
return;
}
closedOperators = false;
LOG.debug("Initializing {}.", getName());
operatorChain =
getEnvironment().getTaskStateManager().isTaskDeployedAsFinished()
? new FinishedOperatorChain<>(this, recordWriter)
: new RegularOperatorChain<>(this, recordWriter);
mainOperator = operatorChain.getMainOperator();
getEnvironment()
.getTaskStateManager()
.getRestoreCheckpointId()
.ifPresent(restoreId -> latestReportCheckpointId = restoreId);
// task specific initialization
init();
// save the work of reloading state, etc, if the task is already canceled
ensureNotCanceled();
// -------- Invoke --------
LOG.debug("Invoking {}", getName());
// we need to make sure that any triggers scheduled in open() cannot be
// executed before all operators are opened
CompletableFuture allGatesRecoveredFuture = actionExecutor.call(this::restoreGates);
// Run mailbox until all gates will be recovered.
mailboxProcessor.runMailboxLoop();
ensureNotCanceled();
checkState(
allGatesRecoveredFuture.isDone(),
"Mailbox loop interrupted before recovery was finished.");
// we recovered all the gates, we can close the channel IO executor as it is no longer
// needed
channelIOExecutor.shutdown();
isRunning = true;
}
其中获取operatorChain,执行restoreGates:
private CompletableFuture restoreGates() throws Exception {
SequentialChannelStateReader reader =
getEnvironment().getTaskStateManager().getSequentialChannelStateReader();
reader.readOutputData(
getEnvironment().getAllWriters(), !configuration.isGraphContainingLoops());
operatorChain.initializeStateAndOpenOperators(createStreamTaskStateInitializer());
IndexedInputGate[] inputGates = getEnvironment().getAllInputGates();
channelIOExecutor.execute(
() -> {
try {
reader.readInputData(inputGates);
} catch (Exception e) {
asyncExceptionHandler.handleAsyncException(
"Unable to read channel state", e);
}
});
// We wait for all input channel state to recover before we go into RUNNING state, and thus
// start checkpointing. If we implement incremental checkpointing of input channel state
// we must make sure it supports CheckpointType#FULL_CHECKPOINT
List> recoveredFutures = new ArrayList<>(inputGates.length);
for (InputGate inputGate : inputGates) {
recoveredFutures.add(inputGate.getStateConsumedFuture());
inputGate
.getStateConsumedFuture()
.thenRun(
() ->
mainMailboxExecutor.execute(
inputGate::requestPartitions,
"Input gate request partitions"));
}
return CompletableFuture.allOf(recoveredFutures.toArray(new CompletableFuture[0]))
.thenRun(mailboxProcessor::suspend);
}
然后在initializeStateAndOpenOperators中执行各个算子的初始化和open方法,本实例用到2个算子(StreamSink、SourceOperator):
public void initializeStateAndOpenOperators(
StreamTaskStateInitializer streamTaskStateInitializer) throws Exception {
for (StreamOperatorWrapper operatorWrapper : getAllOperators(true)) {
StreamOperator operator = operatorWrapper.getStreamOperator();
operator.initializeState(streamTaskStateInitializer);
operator.open();
}
}
在SourceOperator算子中,首先看operator.initializeState方法(调用AbstractStreamOperator.initializeState -> stateHandler.initializeOperatorState -> streamOperator.initializeState),即为调用SourceOperator.initializeState获取到上篇文章从checkpoint中读取的operator算子的状态,状态值如下(5分区),此处参数rawState值需要进行反序列化,splitSerializer为KafkaPartitionSplitSerializer:
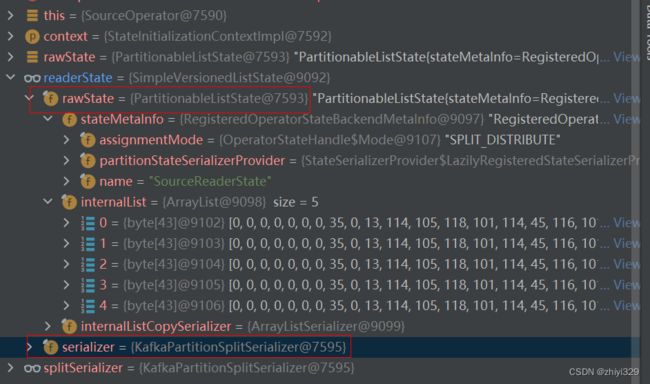
public void initializeState(StateInitializationContext context) throws Exception {
super.initializeState(context);
final ListState rawState =
context.getOperatorStateStore().getListState(SPLITS_STATE_DESC);
readerState = new SimpleVersionedListState<>(rawState, splitSerializer);
}
接下来调用operator.open()方法,在SourceOperator的open中调用CollectionUtil.iterableToList中forEachRemaining -> next()->SimpleVersionedSerialization.readVersionAndDeSerialize->KafkaPartitionSplitSerializer.deserialize方法中将数据进行反序列化,读取offset值,返回splits列表:
public void open() throws Exception {
initReader();
// in the future when we this one is migrated to the "eager initialization" operator
// (StreamOperatorV2), then we should evaluate this during operator construction.
if (emitProgressiveWatermarks) {
eventTimeLogic =
TimestampsAndWatermarks.createProgressiveEventTimeLogic(
watermarkStrategy,
sourceMetricGroup,
getProcessingTimeService(),
getExecutionConfig().getAutoWatermarkInterval());
} else {
eventTimeLogic =
TimestampsAndWatermarks.createNoOpEventTimeLogic(
watermarkStrategy, sourceMetricGroup);
}
// restore the state if necessary.
final List splits = CollectionUtil.iterableToList(readerState.get());
if (!splits.isEmpty()) {
sourceReader.addSplits(splits);
}
// Register the reader to the coordinator.
registerReader();
sourceMetricGroup.idlingStarted();
// Start the reader after registration, sending messages in start is allowed.
sourceReader.start();
eventTimeLogic.startPeriodicWatermarkEmits();
}
public T next() {
final byte[] bytes = rawIterator.next();
try {
return SimpleVersionedSerialization.readVersionAndDeSerialize(serializer, bytes);
} catch (IOException e) {
throw new FlinkRuntimeException("Failed to deserialize value", e);
}
}
public KafkaPartitionSplit deserialize(int version, byte[] serialized) throws IOException {
try (ByteArrayInputStream bais = new ByteArrayInputStream(serialized);
DataInputStream in = new DataInputStream(bais)) {
String topic = in.readUTF();
int partition = in.readInt();
long offset = in.readLong();
long stoppingOffset = in.readLong();
return new KafkaPartitionSplit(
new TopicPartition(topic, partition), offset, stoppingOffset);
}
}
反序列化后的splits值如下:
open()方法中sourceReader.addSplits调用SourceReaderBase的addSplits方法,将offset数据存放到splitStates中(不从checkpoint恢复时,splitStates中state值,如:[Partition: river-test-01-3, StartingOffset: -1, StoppingOffset: -9223372036854775808]。从checkpoint恢复时,splitStates状态值如下,保存checkpoint的offset信息,读取时会获取到此值,每次emitRecord都会更新使当前offset+1,每次快照时都会保存此splitStates中值):
public void addSplits(List splits) {
LOG.info("Adding split(s) to reader: {}", splits);
splits.forEach((s) -> {
SourceReaderBase.SplitContext var10000 = (SourceReaderBase.SplitContext)this.splitStates.put(s.splitId(), new SourceReaderBase.SplitContext(s.splitId(), this.initializedState(s)));
});
this.splitFetcherManager.addSplits(splits);
}

调用KafkaSourceReader的initializedState方法:
protected KafkaPartitionSplitState initializedState(KafkaPartitionSplit split) {
return new KafkaPartitionSplitState(split);
}