论文阅读笔记——Challenges of developing a digital scribe to reduce clinical documentation burden
开发数字抄写器(以减轻临床记录文档的负担)的一系列挑战
Challenges of developing a digital scribe to reduce clinical documentation burden
原文链接:
https://www.nature.com/articles/s41746-019-0190-1
文章目录
-
- 开发数字抄写器(以减轻临床记录文档的负担)的一系列挑战
- Challenges of developing a digital scribe to reduce clinical documentation burden
-
- 简述
-
- 现状:
- 影响:
- 背景:
- 问题:
- 本文内容:
- 详述:
-
- 介绍:
-
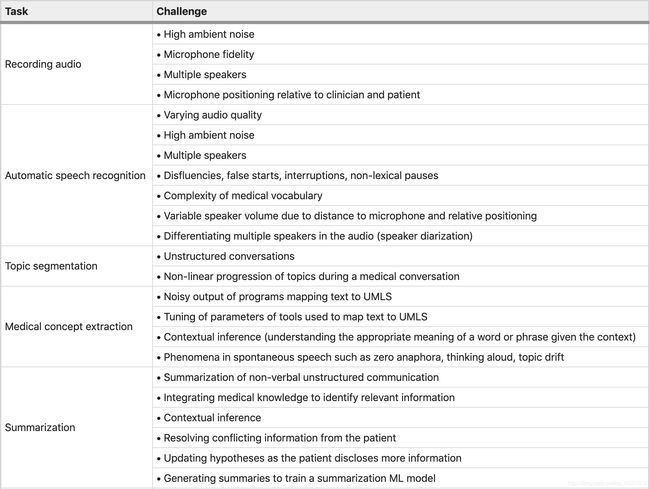
- 1 临床文献有以下几个影响因素:
- 2 Digital scribe数字抄写员 别称:
- 3 理论情况下数字抄写员的一系列优点:
- 4 理想情况下,临床记录将是一个自动化的过程,仅需要人类的最少必要输入。
- 5 要达到上述要求,也就是为了生成临床医生与患者之间的医疗笔记,数字抄写员必须能够:
- 6 数字抄写员pipeline:
- 7 行业背景:
- 挑战:
-
- 1 、 录音和语音识别 AUDIO RECORDING AND SPEECH RECOGNITION
- 2 、 医生与患者的对话的结构化(STRUCTURING CLINICIAN–PATIENT CONVERSATIONS)
- 3 、 临床对话中的信息提取(INFORMATION EXTRACTION IN CLINICAL CONVERSATIONS)
- 4 、 对话总结摘要(CONVERSATION SUMMARIZATION)
- 5 、缺乏临床数据(LACK OF CLINICAL DATA)
- 临床意义讨论
- 总结图:
- 总结表格:
简述
现状:
临床医生(或医学抄写员)将大量时间花在患者遭遇的临床记录上,
影响:
通常会影响护理质量和临床医生满意度,并导致医生精疲力尽。
背景:
人工智能(AI)和机器学习(ML)的进步,使得“用数字抄写员自动化临床文档”变成可能
问题:
临床环境和临床对话的复杂性
本文内容:
在临床环境中开发基于语音的自动化文档相关的主要挑战:
录制高质量音频
使用语音识别将音频转换为转录本(transcripts)
从会话数据中诱导主题结构,
提取医学概念
生成具有临床意义的对话摘要
收集临床数据 以用于AI和ML算法
详述:
介绍:
1 临床文献有以下几个影响因素:
- clinician burnout 临床医生疲惫
- increased cognitive load 增加的认知负担
- information loss 信息丢失
- distractions. 分心
2 Digital scribe数字抄写员 别称:
(自动抄写员)autoscribes, automated scribes,
(虚拟医疗抄写员)virtual medical scribes,
(AI驱动医疗笔记)artificial intelligence (AI) powered medical notes,
(语音识别辅助文档)speech recognition-assisted documentation,
(智能医疗助手)smart medical assistants.
3 理论情况下数字抄写员的一系列优点:
- 使临床医生能够与患者充分互动,保持眼神交流,并不会因为需要手动记录数据(通过使用计算机手动记录遭遇情况)分散注意力;
- 减少临床医生在文档编制过程中花费的时间和精力,还可以提高生产力,减少临床医生的倦怠并改善临床医生与患者的关系,从而带来更高的质量和以患者为中心的护理。
4 理想情况下,临床记录将是一个自动化的过程,仅需要人类的最少必要输入。
数字抄写员是一种自动化的临床记录系统,与人类医疗抄写员所执行的功能一样,
能够捕获临床医生与患者的对话,
然后生成有关相遇的记录。
5 要达到上述要求,也就是为了生成临床医生与患者之间的医疗笔记,数字抄写员必须能够:
- 记录(录音)医生和患者的对话
- 将音频转化为文本
- 从文本中提取重要信息并总结信息
数字抄写员的实现包括一些列语音处理和**自然语言处理(NLP)**模块
6 数字抄写员pipeline:
数字抄写员获取临床医生-患者对话的音频,执行自动语音识别以生成对话记录,从转录本中提取信息,汇总信息,并在与临床医生相关的电子健康记录(EHR)中生成医疗记录-病人的具体情况。
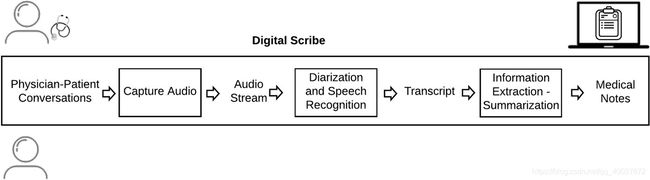
(补充:语音识别,信息提取和汇总依赖于AI和ML模型,这些模型需要大量数据进行训练和评估。)
7 行业背景:
对数字抄写员的需求和兴趣迅速增加,除了对数字抄写员的学术研究以外,越来越多的公司也投入进数字抄写员领域中,包括Microsoft, Google, EMR.AI, Suki, Robin Healthcare, DeepScribe, Tenor.ai, Saykara, Sopris Health, Carevoice, Notable, Kiroku.
最近,人工智能,机器学习(ML),自然语言处理,自然语言理解和自动语音识别(ASR)的进步,为在临床实践中部署有效且可靠的数字抄写员带来了前景。
迄今为止,研究工作集中于解决数字抄写员开发中的基本问题,包括医学对话的ASR,自动填充对医学遭遇(medical encounter)中讨论的症状的评论,从医学对话中提取症状,尽管这些发展前景可观,但仍存在一些挑战,阻碍了在临床环境中实施功能全面的数字抄写员及其评估。
本文将讨论主要挑战。
挑战:
1 、 录音和语音识别 AUDIO RECORDING AND SPEECH RECOGNITION
实现数字抄写员的第一步是录制临床医生-患者对话的音频。高质量的音频可最大程度地减少数字划线器处理流程中的错误。
最近的一项研究发现,在受控环境中,接近理想的声学条件下进行的,发言人坐在麦克风前模拟医疗对话,使用商用ASR引擎进行识别的单词错误率达到35%或更高。
最近的工作表明,使用递归神经网络传感器(a recurrent neural network transducer)可以大大降低医生和患者之间临床对话的音频记录的误差。
在真实临床环境中进行的录制可能会包含对ASR产生负面影响的噪音和其他环境条件。
记录装置的位置也对所捕获的音频的造成强烈影响。临床医生和患者不太可能在咨询期间面对麦克风,因为坐姿和身体检查会影响他们相对于录音设备的位置。反过来,这会影响录制音频的清晰度和音量。
让多个说话者参与对话并在音频中区分它们(说话者二值化)还会增加ASR的复杂度和潜在错误。
即使使用理想的录音设备,会话语音的ASR也更容易出错。自发的会话性语言在语言学上可能是不正确。对话通常会不流利,比如
interleaved false starts(交错的错误开始)、extraneous filler words(多余的填充词)、non-lexical filled pauses(非词汇填充暂停)、repetitions(重复), interruptions(打断), talking over each other(互相交谈
医学对话的统计属性与医学命令的统计属性不同,这意味着经过听写训练的ASR可能在医学对话中表现不佳。
从语音转换为文本后,由于缺少标点和句子边界,口头和书面语言之间的语法差异以及缺乏结构,在语法上正确的句子上表现良好的NLP技术会因会话语音而崩溃。
2 、 医生与患者的对话的结构化(STRUCTURING CLINICIAN–PATIENT CONVERSATIONS)
ASR产生了临床医生-患者对话的笔录,由于对话性质不受限制,因此缺乏清晰的边界和结构。
从一个说话者到另一个说话者的内容可能大不相同,举例如下图:
(医疗对话片段位于左侧,各个主题位于右侧)

一种解决方案是:
识别每个说话者讲话的类别(utterance),从而使得可以从转录本中获取主题块(topic segmentation,然后可以将目标信息提取和汇总应用于所识别的主题。主题可以基于预先确定的类别或传统医学遭遇encounter的组成部分(主要疾病,家族病史,社会历史)。但是,临床遭遇不一定按照其组成的线性顺序排列,这会对总结或者信息提取造成恶劣影响。
主题识别的优点:
在咨询过程中了解当前主题或医疗活动可降低信息提取和汇总的复杂性。
主题识别还可以帮助您识别出出于文档目的可以忽略的信息,从而减少了将误报或无关信息作为生成的医疗记录的一部分的可能性。
3 、 临床对话中的信息提取(INFORMATION EXTRACTION IN CLINICAL CONVERSATIONS)
现有工具或方法:
大规模语义分类法,例如统一医学语言系统(UMLS),可以识别文本中的医学术语。现有的工具,例如MetaMap和cTAKES,提供了将文本映射到UMLS中的概念的编程方法。但是,UMLS是为书面文本而不是为口头医疗对话而设计的。
使用现有工具的问题:
(1)口语与书面语言的差异
(2)外行与专家术语的差异
会导致不准确和单词不匹配。像MetaMap这样的工具也必须调整其参数。
因此:必须采取额外的步骤来识别语义类型和分组,以控制文本映射到医学概念的方式,或制定规则以过滤不相关的术语
临床医生与患者之间的对话以临床医生的紧急需求为指导,以获取有关患者状况的信息。因此,临床医生与患者之间的对话以临床医生的紧急需求为指导,以获取有关患者状况的信息。
由于自发语音中的常见现象,对书面段落的机器理解的研究无法直接转移到口语对话中。此外,对话不是类似命令的结构,这使得执行意图识别(从话语识别用户的意图)和应用NLP技术变得困难。
最后,庞大而复杂的医学词汇和对话的性质使语境推理变得复杂(根据邻近短语或对话片段的主题,理解一个单词或短语的适当含义),这是对话的必要部分。
4 、 对话总结摘要(CONVERSATION SUMMARIZATION)
从临床医生-患者对话中生成医学摘要可以作为有监督的学习任务,使用大量过去的医学对话记录以及与每次对话相关的黄金标准摘要来训练ML算法。
最终目标是训练一个summarization model
输入是临床医生-患者的录音的转录本(语音识别结果),输出是适当的摘要summariy
问题:
获得黄金摘要的成本很高
需要一套用来评估黄金摘要的标准
为了生成有效的医学注释,摘要可能需要利用医学知识并在会诊期间捕获非语言信息。
医学笔记不仅包括医学对话中最重要的要点,而且还可以通过查询,聆听,观察,对患者进行身体检查以及得出结论来反映医生收集的特定信息(其中某些信息可能永远不会通过口头传达)。
要捕获此信息,可能需要对临床医生的工作流程或做法进行一些更改。例如,临床医生在体格检查期间可能需要表达自己的意见。然而,这可能会迫使临床医生表达他们可能不想告诉患者的事情。这种情况下的交互设计需要精细的解决方案。未来的研究还应关注整合医学知识和非语言信息作为ML或AI汇总模型输入的方法。
在临床相遇期间,临床医生通常会更改他们的评估或修改某些观察结果。
这将很难通过自动摘要模型来区分,因为它将需要复杂的自然语言理解。一种可能的解决方案是使临床医生负责编辑和解决所生成摘要中的冲突信息。
5 、缺乏临床数据(LACK OF CLINICAL DATA)
大型公共数据集通过
(1)为研究人员提供建立ML模型所需的规模的数据
(2)促进研究复制和比较研究的基准,帮助推进了ML研究。
由于隐私问题和数据的敏感性质,获得和共享医学数据成为主要障碍。
在某些情况下,政府法规可能会限制在全球的机构和研究团队的数据共享。在其他情况下,数据将被货币化。结果,丰富而准确的临床数据已成为工业界和学术界最有价值的知识产权资产之一。
临床意义讨论
反:手动记录可以使临床医生有效地组织思想,批判性思考,有效地反映和实践医学,从而将其删除会对临床医生的医学实践产生不利影响。当前倡导用AI代替整个文档编制过程的人也倾向于忽略医疗保健社会技术系统的复杂性。在临床环境中对这些系统的评估必须包括对它们如何影响护理质量,患者满意度,临床医生效率,记录时间以及诊所内组织动态的评估。
正:数字抄写员的目标不是形成许多功能异常的AI期货中所描述的替代临床医生,而是形成一种“人与AI的共生关系”,以增强临床医生与患者的经验并改善护理质量。数字抄写员可以很好地改变临床医生与患者之间的交流,将重点重新转移到患者和临床推理上。数字划线器解决方案越无缝,对临床医生与患者接触的支持就越大。任何需要在咨询过程中不断进行输入和监督的数字划线员解决方案,都会(1)使临床医生从患者中分散注意力,并且(2)用数字划线员来代替使用EHR的干扰和干扰。如果数字抄写员的集成以牺牲临床实践的标准化为代价,那么如果它可以释放临床医生的时间并改善临床医生与患者的关系,那么仍然值得这样做。临床接触的某些方面的标准化也可以提高患者对临床接触的理解。
总结图:
总结表格: