安居客数据的爬取并保存到MySQL
今天阿彬爬取的网页是安居客,涉及到异步抓取,先分析首页,再得到各个首页的标签的url,做一个二次请求,最后是到得到的二次请求的详情页获取详细数据。(下面就全是代码)
1、经过首页的分析,可以得到详情页的url,圈起来的是重点。获取各个详情页的url之后,进入详情页对详细的数据进行抓取。
2、爬取数据的代码:
import requests
# 使用xpath方法定位元素
from lxml import etree
import csv
#
f = open('安居客2.csv', mode='a', encoding='utf8', newline='')
csv_write = csv.DictWriter(f, fieldnames=['标题', '地址', '建筑面积', '月租', '性质', '楼层', '类型', '付款方式', '使用率', '物业费',
'房源亮点', '配套设施', '项目优势', '项目图片'])
csv_write.writeheader()
for d in range(1, 3):
url = f'https://zh.sydc.anjuke.com/xzl-zu/p+{d}/' # 请求头
head = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'cookie': 'aQQ_ajkguid=49251b9d-01b8-4a2a-8750-8c8d46a3a061; sessid=ad07f13d-086f-40ff-9044-8347518facce; lps=https%3A%2F%2Fzh.sydc.anjuke.com%2Fxzl-zu%2F%7Cnull; ctid=42; fzq_h=0ef6053df4385c7f4b8d9621d0873223_1657457994428_d41105585c4a47c89785d46bc4ab49c6_2018900023; id58=CocKx2LKzUptyucVm4BwAg==; id58=CrIMp2LKzUtH/xqlmCnNAg==; wmda_uuid=371ceba20e63c73b95cd3be8c29147df; wmda_new_uuid=1; wmda_visited_projects=%3B6289197098934; wmda_session_id_6289197098934=1657457995012-368cc26f-de19-6181; ajk-appVersion=; JSESSIONID=A7A8B1E1E17991242AB9483D21223E8A; fzq_js_anjuke_business_fang_pc=ae985b0c03544ca615cc48ac7b6c5bb5_1657458865784_25; __xsptplus8=8.1.1657457995.1657458866.12%234%7C%7C%7C%7C%7C%23%23VOSWEhAO-5wxS1JfST853m4oWbleBw23%23',
'referer': 'https://zh.sydc.anjuke.com/xzl-zu/'
} # 伪装,防止被封IP
resp = requests.get(url, headers=head).text # 以文本的格式打卡网页
# print(resp)
whh = etree.HTML(resp).xpath('//div[@class="list-item"]/a/@href')
for src in whh: # 对上一行代码所获取到每个标题的连接做一个遍历
# print(src)
data_url = requests.get(src, headers=head).text # 二次请求,就是对新的url重新发起请求
data_link = etree.HTML(data_url)
title = data_link.xpath('//h1[@class="house-title"]/text()')
jzmj = data_link.xpath('//div[@class="detail-wrap"]/div/div[1]/text()')
pohto = data_link.xpath('//div[@id="photos"]/img/@src')
# pictuer = 'https:' + pohto
data = data_link.xpath('//div[@class="basic-info-wrapper"]')
xiangxi_data = data_link.xpath('//div[@id="detaildesc"]/div')
for a in data:
# 因为所获取到的数据是列表,所以[0]是使得到的结果返回列表的第一个元素
dz = a.xpath('./div[15]/span[2]/text()')[0]
yz = a.xpath('./div[3]/span[2]/text()')[0]
xz = a.xpath('./div[2]/span[2]/text()')[0]
lc = a.xpath('./div[8]/span[2]/text()')[0]
lx = a.xpath('./div[6]/span[2]/text()')[0]
fk = a.xpath('./div[5]/span[2]/text()')[0]
syl = a.xpath('./div[10]/span[2]/text()')[0]
wyf = a.xpath('./div[16]/span[2]/text()')
for b in xiangxi_data:
fyld = b.xpath('./div[1]/article/text()')[0]
ptss = b.xpath('./div[2]/article/text()')
xmys = b.xpath('./div[3]/article/text()')
print(title, dz, jzmj, yz, xz, lc, lx, fk, syl, wyf, fyld, ptss, xmys, pohto)
data_dict = {'标题': title, '地址': dz, '建筑面积': jzmj, '月租': yz, '性质': xz, '楼层': lc, '类型': lx,
'付款方式': fk, '使用率': syl, '物业费': wyf, '房源亮点': fyld, '配套设施': ptss, '项目优势': xmys,
'项目图片': pohto}
csv_write.writerow(data_dict)
f.close()3、得到的数据需要做一些简单的处理,代码如下:
import pandas as pd
import numpy as np
df = pd.read_csv(r'D:\努力学python\文章\安居客1.csv')
df
df1 = df['配套设施'].replace('[]',0)
df2 = []
for a in df1:
if a == 0:
df2.append(a)
else:
df2.append(a[2:-2])
df['配套设施'] = df2
df2
# df2 = df['标题']
# for i in df2:
# print(i[2:-2])
df3 = df['标题']
df4 = []
for b in df3:
df4.append(b[2:-2])
df['标题'] = df4
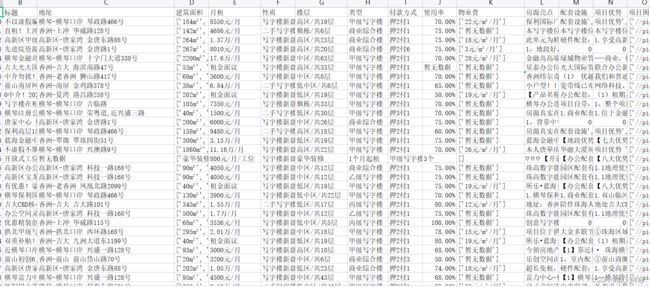
df44、得到的数据如下:
5、将处理后的Excel数据表传送到本地的MySQL数据库中。
import pandas as pd
import numpy as np
df = pd.read_csv('C:/Users/jhwsx/Desktop/安居客2.csv')
from sqlalchemy import create_engine
engine = create_engine("mysql+mysqlconnector://root:[email protected]:3306/安居客",echo=False)
df.to_sql(name='安居客2',con=engine,if_exists="replace")6、到mysql查看数据:“select 字段1,字段2,字段n from 安居客2”: