项目说明文档【自用】【视频共享】
文章目录
-
- 概要
- 整体技术分析
- 工具模块
-
- 文件工具类
-
- 判断文件是否存在 Exists();
- 获取文件大小 Size();
- 读取数据到body中 GetContent(std::string *body);
- 向文件中写入数据 bool SetContent(const std::string &body);
- 针对目录创建目录 bool CreateDiretory();
- 序列化与反序列化工具
-
- 序列化 static bool Serialize(const Json::Value &value, std::string *body)
- 反序列化 static bool UnSerialize(const std::string &body, Json::Value *value)
- 数据管理
-
-
- 初始化MysqlInit();
- 删除MysqlDestory(MYSQL *mysql);
- 执行语句MysqlQuery(MYSQL *mysql, const std::string &sql);
- Table Video
-
- 构造 TableVideo();
- 析构
- 增加视频
- 删除视频
- 全局查找
- 精确查找
- 模糊匹配查找
- 修改视频信息
- 测试用例
-
- 请求与响应
-
- REST
- httplib库
- 业务与网络
-
- 插入 static void Insert(const httplib::Request &req, httplib::Response &rsp)
- 修改 static void Update(const httplib::Request &req, httplib::Response &rsp)
- 删除 static void Delete(const httplib::Request &req, httplib::Response &rsp)
- 单个查询 static void SelectOne(const httplib::Request &req, httplib::Response &rsp)
- 多个查询 static void SelectAll(const httplib::Request &req, httplib::Response &rsp)
- 报文响应设计RunModule()
- 前端细节
- 文档总结
概要
历时三个月终于完工的实践项目,但总感觉时间一久就忘了自己写的代码要干什么。(已经忘了(
特别推出此篇项目说明文档(bushi)
对项目中每一份代码中每一个函数(方法)或者说一些重要逻辑做出梳理解释,更加的融会贯通~

整体技术分析
在视频点播分享系统中,用户使用的直观感受是可以直接在网站中上传视频并播放,并且可以对其进行描述,删除,修改视频名称与描述等等操作。
很明显是关于视频相关内容的增删改。
网站需要获取数据库中表单的内容,传输结构数据少不了JSON序列化,同时也需要搭建tcp,这里采用http-lib自动搭建,使用其提供的方法接口即可。
同时也是是现客户端对服务器内的数据进行一系列操作。
此处首先说明一次不自己搭建相关网络环境的原因
此处首先说明一次不自己搭建相关网络环境的原因
编写套接字实现固然不会耗费太多精力与时间
但 http请求需要注意的细节有很多
请求和响应需要处理的细节问题过于繁杂
稍有不慎就会翻车()
单另拿出其代码量完全可以充当一个新的实践项目
项目整体大体流程如下:
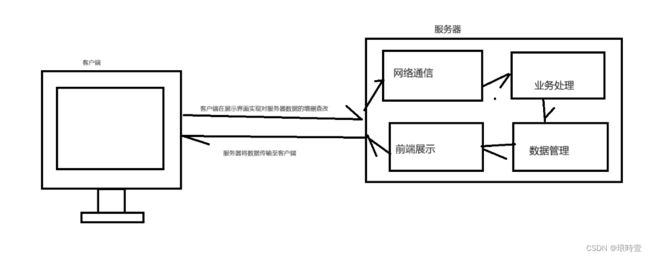
- 网络通信:构建网络通信,实现数据传输。
- 业务处理:处理客户端请求,处理后并响应结果
- 数据管理:客户端上传的信息,通过MySQLAPI进行管理。
- 前端展示:模板代码,实现网页中对数据的增删改查。
工具模块
上传数据文件与使用MySQLAPI离不开文件操作,网络传输自然离不开序列化与反序列化。这些操作是贯穿整个项目的,将其封装起来以便使用。
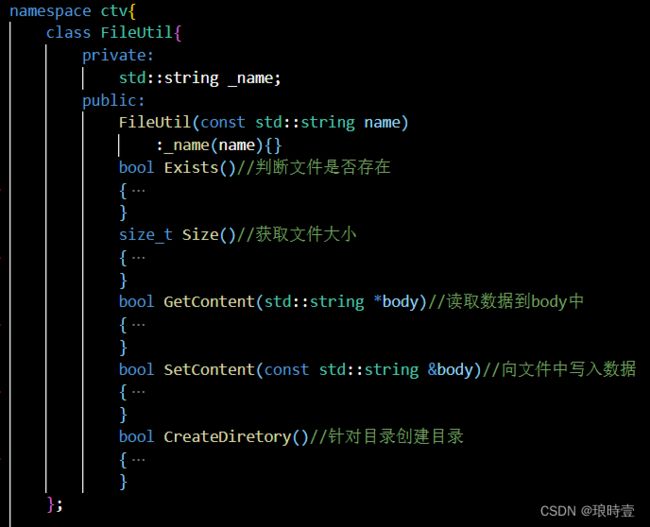
文件工具类
上传数据文件与使用MySQLAPI离不开文件操作,上传的视频数据自然也需要存储在服务端。
实现的功能有:判断文件是否存在、获取文件大小、读取数据到一个字符串中、向文件写入数据、创建目录等。
判断文件是否存在 Exists();
bool Exists()//判断文件是否存在
{
//F_OK用来判断文件是否存在,存在则返回0
int ret = access(_name.c_str(), F_OK);
if(ret != 0)
{
std::cout << "file is not exists\n";
return false;
}
return true;
}
- _name是构造函数时产生的文件对象
- access()函数用来判断用户是否具有访问某个文件的权限(或判断某个文件是否存在).
- 需要包含#include
参数和返回值
int access(const char *pathname,int mode)
参数:
pathname:表示要测试的文件的路径
mode:表示测试的模式可能的值有:
R_OK:是否具有读权限
W_OK:是否具有可写权限
X_OK:是否具有可执行权限
F_OK:文件是否存在
返回值:若测试成功则返回0,否则返回-1
- 使用F_OK函数即可判断文件是否存在,存在返回0,不存在返回1。
获取文件大小 Size();
size_t Size()//获取文件大小
{
if(this->Exists() == false)
{
return 0;
}
struct stat st;
//stat获取文件属性,st_size就是文件大小
int ret = stat(_name.c_str(), &st);
if(ret != 0)
{
std::cout << "get file stat failed!\n";
return 0;
}
return st.st_size;
}
- struct stat 结构体详解
struct stat
{
dev_t st_dev; /* ID of device containing file */文件使用的设备号
ino_t st_ino; /* inode number */ 索引节点号
mode_t st_mode; /* protection */ 文件对应的模式,文件,目录等
nlink_t st_nlink; /* number of hard links */ 文件的硬连接数
uid_t st_uid; /* user ID of owner */ 所有者用户识别号
gid_t st_gid; /* group ID of owner */ 组识别号
dev_t st_rdev; /* device ID (if special file) */ 设备文件的设备号
off_t st_size; /* total size, in bytes */ 以字节为单位的文件容量
blksize_t st_blksize; /* blocksize for file system I/O */ 包含该文件的磁盘块的大小
blkcnt_t st_blocks; /* number of 512B blocks allocated */ 该文件所占的磁盘块
time_t st_atime; /* time of last access */ 最后一次访问该文件的时间
time_t st_mtime; /* time of last modification */ /最后一次修改该文件的时间
time_t st_ctime; /* time of last status change */ 最后一次改变该文件状态的时间
};
- 需要包含的头文件
#include - 函数原型
int stat(const char *path, struct stat *buf)
成功返回0,失败返回-1;
参数:文件路径(名),struct stat 类型的结构体
读取数据到body中 GetContent(std::string *body);
bool GetContent(std::string *body)//读取数据到body中
{
std::ifstream ifs;
ifs.open(_name, std::ios::binary);
if(ifs.is_open() == false)
{
std::cout << "open file failed\n";
return false;
}
size_t flen = this->Size();
body->reserve(flen);
ifs.read(&(*body)[0], flen);
if(ifs.good() == false)
{
std::cout << "read fail content failed!\n";
ifs.close();
return false;
}
ifs.close();
//调试
std::cout << "输出" << std::endl;
return true;
}
设计文件操作,文件操作平时使用场景,这边只能做到即用即查,这里仅对代码内相关操作做简单解释

- 在fstream类中,成员函数open()实现打开文件的操作,从而将数据流和文件进行关联,通过ofstream,ifstream,fstream对象进行对文件的读写操作
- 函数open()
public member function
void open ( const char * filename,
ios_base::openmode mode = ios_base::in | ios_base::out );
void open(const wchar_t *_Filename,
ios_base::openmode mode= ios_base::in | ios_base::out,
int prot = ios_base::_Openprot);
参数: filename 操作文件名
mode 打开文件的方式
prot 打开文件的属性 //基本很少用到
- 打开文件的方式在ios类(所有流式I/O的基类)中定义,有如下几种方式:
ios::in 为输入(读)而打开文件
ios::out 为输出(写)而打开文件
ios::ate 初始位置:文件尾
ios::app 所有输出附加在文件末尾
ios::trunc 如果文件已存在则先删除该文件
ios::binary 二进制方式
这些方式是能够进行组合使用的,以“或”运算(“|”)的方式
- 属性
0 普通文件,打开操作
1 只读文件
2 隐含文件
4 系统文件
- ifstream Input file stream class
- ofstream Output file stream
- fstream Input/output file stream class
查看是否绑定成功 bool is_open() const;
文件流对象与文件绑定,返回 true ,否则 false 。
比如,当尝试以ios_base::in | ios_base::trune模式打开文件时,
这就是不允许的模式组合,导致打开流失败。
is_open()方法用于检测此种故障。
reserve(n);预分配n个存储空间
- 通过read函数将文件中的数据按照一定的长度读取出来并且存放在新的数组中。
istream& read (char* s, streamsize n); //用来暂存内容的数组(必须是char*型),以及流的长度
在stream流类型中,有一个成员函数good().用来判断当前流的状态(读写正常(即符合读取和写入的类型),没有文件末尾)
对于类 读写文件 fstream ifstream ofstream 以及读写字符串流stringstream istringstream ostringstream等类型。都用good()成员函数来判断当前流是否正常。
在没有任何错误的情况下返回true
如果在C++中打开一个文件但不关闭它,会导致以下问题:
-
文件资源泄漏:打开文件时,系统会分配一些资源(例如文件描述符),如果不及时关闭文件,这些资源将一直被占用,并且在一些情况下可能导致系统资源的浪费。
-
对于某些操作系统,同时打开的文件数量是有限的。如果你打开了太多文件而没有关闭它们,将会占用过多的资源,可能导致其他程序无法打开文件或者系统崩溃。
-
数据丢失:如果在打开的文件上执行了写操作,但未关闭该文件,那么在程序崩溃或关闭之前,所做的更改将不会被保存。
为了正确地处理文件操作,应该始终在不再使用文件时关闭它,以释放相关资源并确保数据的完整性。可以使用C++的文件流对象(例如std::ifstream和std::ofstream)的析构函数来自动关闭文件。或者,也可以在操作文件后调用流对象的close()函数手动关闭文件。
- 需要注意的是,打开的文件并不在缓冲区中(内存)
在C++中打开的文件不是直接存储在内存中,而是在文件系统中。文件系统是一种将数据从磁盘存储到内存中的机制。
当你打开一个文件时,文件系统会根据文件路径在磁盘上找到对应的文件,并将其加载到内存中的文件缓冲区中。这样,在进行读取或写入操作时,可以直接在内存中进行。
文件缓冲区是指内存中的一块区域,用于临时存储文件的内容。在进行文件操作时,可以使用文件流对象来读取或写入该缓冲区。
当文件操作完成后,应该关闭文件,这将导致文件系统将缓冲区中的数据写回磁盘,并释放缓冲区所占用的内存。文件系统负责在适当的时候将数据从磁盘加载到缓冲区中,并将更改的内容写回磁盘,这样可以保护数据的完整性和一致性。
所以,可以说打开的文件在内存中的文件缓冲区中进行读写操作,但实际的文件数据仍然存储在磁盘上的文件系统中。
向文件中写入数据 bool SetContent(const std::string &body);
bool SetContent(const std::string &body)//向文件中写入数据
{
std::ofstream ofs;
ofs.open(_name, std::ios::binary);
if(ofs.is_open() == false)
{
std::cout << "open file failed\n";
return false;
}
ofs.write(body.c_str(), body.size());
if(ofs.good() == false)
{
std::cout << "write fail content failed!\n";
ofs.close();
return false;
}
ofs.close();
return true;
}
和上面有好多类似的操作~~(就不写了叭())
- write
std::ostream& write(const char* s, std::streamsize n);
1. `const char* s`:要写入的数据的指针,通常是一个字符数组或C风格的字符串。
2. `std::streamsize n`:要写入的数据的字节数。
-
write函数不会自动添加字符串结束符\0,所以写入的字符串必须有足够的长度,并且要在读取时使用适当的方法来确定结束位置。 -
它是以字节为单位进行写入的,因此要确保写入的数据的长度正确,以避免写入多余或不足的数据
使用ofs.good()函数来检查写入状态,以确保写入操作成功。
针对目录创建目录 bool CreateDiretory();
bool CreateDiretory()//针对目录创建目录
{
if(this->Exists())
{
return true;
}
mkdir(_name.c_str(), 0777);
return true;
}
- 调用
Exists()函数来检查目录是否已存在。 - 如果目录不存在,则调用
mkdir()函数创建一个新的目录,目录名由_name变量指定。第二个参数0777指定了新创建目录的权限。
在Linux系统中,文件和目录的权限是由三组数字表示的,每组数字代表了所有者、所属组和其他用户的权限。
每一位数字代表了一种权限,具体如下:
0:没有权限1:执行权限2:写权限4:读权限
组合不同的数字可以得到不同的权限组合。例如,0777表示所有者、所属组和其他用户都具有读、写和执行权限。
在这个函数中,0777表示创建的目录具有最高的权限,即所有用户都可以读取、写入和执行该目录。
——————文件工具类就是这些。我嘞个豆,虽然只是简单的查阅文档和资料,但好废精力和时间哇()
序列化与反序列化工具
网络传输自然少不了序列化与反序列化啦
-
序列化是将对象的状态转换为可以存储或传输的形式的过程。在序列化过程中,对象的状态被转换为字节流或其他表示形式,以便可以将其保存在文件、数据库中,或者通过网络进行传输。
-
反序列化是将序列化后的数据重新转换为对象的过程。在反序列化过程中,字节流或其他表示形式被还原为对象的状态,使得我们可以从存储设备或网络中读取数据并重新创建对象。
JSON格式的序列化与反序列化是将对象转换为JSON字符串,或者将JSON字符串转换为对象的过程。
序列化:将对象转换为JSON字符串的过程称为序列化。在序列化过程中,对象的属性会被转换为JSON格式的键值对,通常使用双引号括起来。序列化后的JSON字符串可以用于保存到文件或通过网络传输。
反序列化:将JSON字符串转换为对象的过程称为反序列化。在反序列化过程中,JSON字符串会被解析为对应的对象,对象的属性值会从JSON中提取出来进行赋值。
JSON格式的序列化与反序列化具有以下优点:
-
可读性强:JSON使用明确的键值对比较易于阅读和理解。
-
跨平台兼容:JSON是一种通用的数据格式,几乎所有的编程语言都有支持JSON的库或工具。
-
简洁轻量:JSON相对于其他数据格式来说,通常会比较紧凑,因此在存储和传输数据时占用较少的空间。
笔者中对JSON的使用也是即用即查,仅仅了解。(因为版本较多(每个版本都有略微的使用差别)也需要和httplib匹配等等等等

序列化 static bool Serialize(const Json::Value &value, std::string *body)
static bool Serialize(const Json::Value &value, std::string *body)
{
Json::StreamWriterBuilder swb;
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
std::stringstream ss;
int ret = sw->write(value, &ss);
if(ret != 0)
{
std::cout << "Serilaize failed!\n";
return false;
}
*body = ss.str();
return true;
}
- 使用
static关键字表示它是一个静态成员函数。静态成员函数是属于类而不是对象的函数,它可以在没有创建类的实例的情况下被调用。 - 在C++中,静态成员函数不依赖于特定的对象实例,因此没有隐含的
this指针,只能访问静态成员和其他静态函数。 - std::stringstream是C++标准库中的一个类,它提供了一个用于操作字符串的流。可以将其视为输入/输出流,用于从字符串中读取或写入数据。这是一个非常实用的类,可以用于字符串的操作和格式化。
- JSON格式的键值对如下
{"name": "John", "age": 25, "city": "New York"},写入的时候也是一块一块,所以使用了stringstream。 - 调用sw->write(value, &ss)将Json::Value对象value序列化到std::stringstream对象ss中,并将返回值保存在ret中。
这里使用了unique_ptr,简单解释一下。(智能指针还是拿出来吧,写清楚要大功夫)
用于对动态对象进行自动内存管理。
它比原始指针更好,因为它在超出作用域或重置时自动删除所拥有的对象。
unique_ptr是唯一的,意味着同一时间只能有一个unique_ptr拥有特定的对象。
当所有权被转移时,原始的unique_ptr变为空,并且不再拥有对象。
这可以避免两个不同的unique_ptr尝试删除相同对象的问题。
反序列化 static bool UnSerialize(const std::string &body, Json::Value *value)
static bool UnSerialize(const std::string &body, Json::Value *value)
{
Json::CharReaderBuilder crb;
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
std::string err;
bool ret = cr->parse(body.c_str(), body.c_str() + body.size(), value, &err);
if(ret == false)
{
std::cout << "UnSerialize failed!\n";
return false;
}
return true;
}
cr->parse() 是 Jsoncpp 库中用于将 JSON 字符串解析为 Json::Value 对象的方法。它接受以下参数:
const char* begin:指向要解析的 JSON 字符串的起始位置的指针。const char* end:指向要解析的 JSON 字符串的结束位置的指针。Json::Value* root:指向要存储解析结果的Json::Value对象指针。std::string* errs:指向用于存储解析错误信息的std::string对象指针。
数据管理
视频文件存放在服务器,视频封面图片与描述内容存放在数据库,视频文件较大存放在数据库(MySQL不大的吧)
- 创建表单
drop database if exists aod_system;
create database if not exists aod_system;
use aod_system;
create table if not exists tb_video(
id int primary key auto_increment comment '视频ID',
name varchar(32) comment '名称',
info text comment '描述',
video varchar(256) comment '视频文件url,加上静态资源根目录就是实际存储路径',
image varchar(256) comment '封面图片文件url,加上静态资源根目录就是实际存储路径'
);
这里对ID进行了自增主键的设置,新增视频是ID自增,通过ID来定位视频。
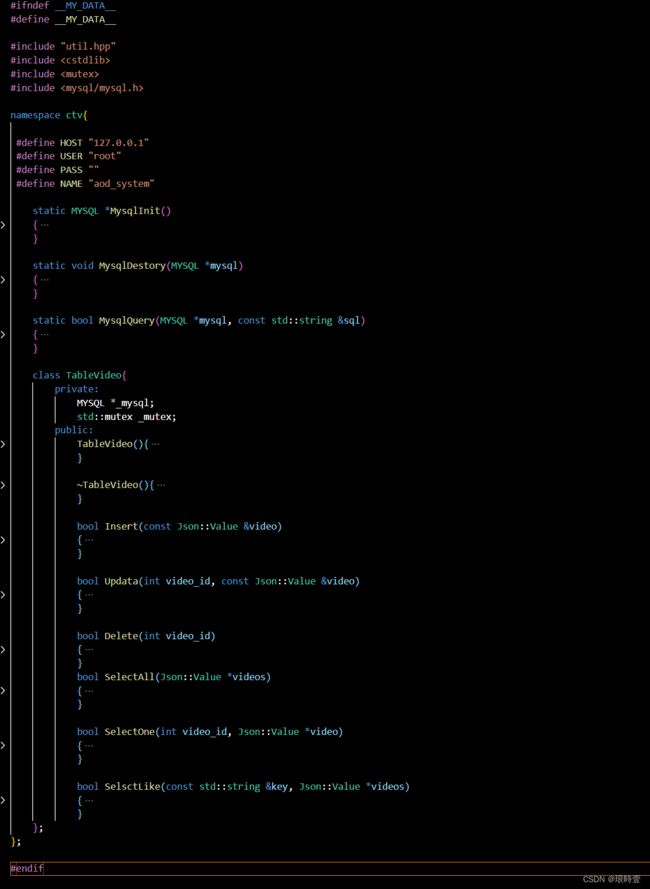
- MySQL服务器端是一个独立运行的数据库服务器,可以在操作系统上作为一个进程或服务运行。它负责接受来自客户端的连接请求,并处理和执行SQL语句。
- 在客户端中使用MySQL提供的命令行或者图形界面工具,输入服务器的IP地址、端口号、用户名和密码等信息,与MySQL服务器建立连接。
- 127.0.0.1 是Linux下本地环回,可以找到MySQL服务器。
MySQLAPI也是即查即用()
初始化MysqlInit();
static MYSQL *MysqlInit()
{
MYSQL *mysql = mysql_init(NULL);
if(mysql == NULL)
{
std::cout << "init mysql failed!\n";
return NULL;
}
if(mysql_real_connect(mysql, HOST, USER, PASS, NAME, 0, NULL, 0) == NULL)
{
std::cout << "connect server failed!\n";
mysql_close(mysql);
return NULL;
}
mysql_set_character_set(mysql, "utf8");
return mysql;
}
- 使用
mysql_real_connect函数连接到 MySQL 服务器。该函数的参数依次为:MYSQL*结构体指针,服务器主机名HOST,用户名USER,密码PASS,要连接的数据库名NAME,端口号0,UNIX socket 文件名为NULL,连接标志为0
MYSQL结构体中的一些重要成员:
-
MYSQL *sock:一个指向MySQL服务器连接所使用的套接字的指针。
-
char *host:一个指向MySQL服务器主机名或IP地址的指针。
-
unsigned int port:MySQL服务器的端口号。
-
char *user:连接MySQL服务器所使用的用户名。
-
char *passwd:连接MySQL服务器所使用的密码。
-
char *db:连接MySQL服务器后要选择的数据库名。
-
char *unix_socket:一个指向用于连接本地UNIX套接字文件的路径的指针。
-
unsigned long client_flag:客户端标志,用于设置连接的一些选项。
-
my_bool autocommit:表示连接是否自动提交事务的标志。
-
my_bool reconnect:表示连接是否自动重新连接的标志。
此外,MYSQL结构体还包含了一些错误信息、结果集、服务器版本等与连接相关的信息。这些成员变量提供了对MySQL连接的控制和访问。
删除MysqlDestory(MYSQL *mysql);
static void MysqlDestory(MYSQL *mysql)
{
if(mysql != NULL)
{
mysql_close(mysql);
}
return;
}
执行语句MysqlQuery(MYSQL *mysql, const std::string &sql);
static bool MysqlQuery(MYSQL *mysql, const std::string &sql)
{
int ret = mysql_query(mysql, sql.c_str());
if(ret != 0)
{
std::cout << sql << std::endl;
std::cout << mysql_error(mysql) << std::endl;
return false;
}
return true;
}
- 调用
mysql_query函数执行SQL语句,并将返回值存储在ret变量中。若执行成功,mysql_query函数返回0,否则返回非零值。 - 检查
ret的值,如果不为0表示查询执行失败。在查询失败的情况下,将打印出执行的SQL语句和MySQL错误信息,并返回false表示执行失败。 - 如果查询执行成功,返回
true表示执行成功。
sql在后续的主要作用是通过sprintf生成SQL语句。
在使用数据库操作方法时,使用了互斥锁保证线程安全。(线程和进程也拿出去了)
线程安全指的是在多线程环境下,对于共享的数据结构或代码段的操作能够保证多个线程同时执行时,不会出现意外的结果或数据不一致的情况。具体来说,线程安全的代码在多线程并发执行时能够正确地完成任务,而不会导致数据损坏或不一致。
MYSQL *_mysql;
std::mutex _mutex;
Table Video
构造 TableVideo();
TableVideo(){
_mysql = MysqlInit();
if(_mysql == NULL)
{
exit(-1);
}
}
就是调用了初始化。
析构
~TableVideo(){
MysqlDestory(_mysql);
}
增加视频
bool Insert(const Json::Value &video)
{
//id name info video image
std::string sql;
sql.resize(4096 + video["info"].asString().size());//简介很长
//需要对每一个参数进行大量的校验
#define INSERT_VIDEO "insert tb_video values(null, '%s', '%s', '%s', '%s');"
sprintf(&sql[0], INSERT_VIDEO, video["name"].asCString(),
video["info"].asCString(),
video["video"].asCString(),
video["image"].asCString());
return MysqlQuery(_mysql, sql);
}
- 视频名称不长,视频ID不长,图片与视频路径也不长,4096足矣,但简介多长呢,不知道,看用户喜欢,所以简介长度是sql句柄长度的关键。
- 函数将接受到的Json::Value数据插入到数据库中。
- 注意,此时的视频与图片都是路径,是服务端的路径,凭借此路径在服务器端获取相关数据。
- &sql[0]表示对std::string对象的底层字符数组的指针,因此在这里sprintf将格式化后的内容直接写入到了这个字符数组中,从而改变了sql字符串的内容。
删除视频
bool Delete(int video_id)
{
#define DELETE_VIDEO "delete from tb_video where id = %d;"
char sql[1024] = {0};
sprintf(sql, DELETE_VIDEO, video_id);
return MysqlQuery(_mysql, sql);
}
- 在关系型数据库中,每条记录通常都会有一个唯一标识符或主键,这个标识符对应于数据库表中的ID字段。当执行删除操作时,可以使用这个唯一标识符来指定要删除的记录,因为每个记录的ID是唯一的。所以,在给定的Delete函数中,通过传入的video_id参数,可以构建一个SQL语句来精确地删除具有该特定ID的记录。
全局查找
bool SelectAll(Json::Value *videos)
{
#define SELECTALL_VIDEO "select * from tb_video;"
_mutex.lock();
bool ret = MysqlQuery(_mysql, SELECTALL_VIDEO);
if(ret == false)
{
_mutex.unlock();
return false;
}
MYSQL_RES *res = mysql_store_result(_mysql);
if(res == NULL)
{
std::cout << "mysql store failed!\n";
_mutex.unlock();
return false;
}
_mutex.unlock();//end
int num_rows = mysql_num_rows(res);
for(int i = 0; i < num_rows; i++)
{
MYSQL_ROW row = mysql_fetch_row(res);//获取字段
Json::Value video;
video["id"] = atoi(row[0]);
video["name"] = row[1];
video["info"] = row[2];
video["video"] = row[3];
video["image"] = row[4];
videos->append(video);
}
mysql_free_result(res);
return true;
}
- 涉及到数据库查询和结果处理,而且很可能会被多个并发线程同时调用。加锁的目的是确保在执行查询和处理结果期间不会有其他线程干扰,以维护线程安全性。
- mysql_store_result的作用是将查询操作返回的所有数据从服务器取回到客户端,并以结果集的形式存储在程序中的一个结构中,以供后续处理和读取。
在使用 mysql_store_result 函数之前,需要首先通过 mysql_query 或者类似的函数向MySQL服务器发送SQL查询语句。然后,如果这个查询返回了结果(比如SELECT语句),那么就可以调用 mysql_store_result 来获取对应的结果集。
一旦获得了结果集,我们就可以使用MySQL提供的其他API函数来处理和读取每行数据。通常情况下,我们会使用 mysql_fetch_row 函数来逐行获取结果集中的数据,并进行进一步的处理和解析。 - 顾名思义,mysql_num_rows就是获取结果集有多少行,方便后续的 mysql_fetch_row逐行读取。
- 通过循环遍历结果集,将每一行的数据提取出来,并存储到名为videos的Json::Value对象中。
- 不能忘了释放结果集。
精确查找
bool SelectOne(int video_id, Json::Value *video)
{
#define SELECTONE_VIDEO "select * from tb_video where id = %d;"
char sql[1024] = {0};
sprintf(sql, SELECTONE_VIDEO, video_id);
_mutex.lock();
bool ret = MysqlQuery(_mysql, sql);
if(ret == false)
{
_mutex.unlock();
return false;
}
MYSQL_RES *res = mysql_store_result(_mysql);
if(res == NULL)
{
std::cout << "mysql store failed!\n";
_mutex.unlock();
return false;
}
_mutex.unlock();//end
int num_rows = mysql_num_rows(res);
if(num_rows != 1)
{
std::cout << "get row failed!\n";
mysql_free_result(res);
_mutex.unlock();
return false;
}
MYSQL_ROW row = mysql_fetch_row(res);//获取字段
(*video)["id"] = video_id;
(*video)["name"] = row[1];
(*video)["info"] = row[2];
(*video)["video"] = row[3];
(*video)["image"] = row[4];
mysql_free_result(res);
return true;
}
- 同上,通过主键精确查找一条视频信息,后序无需遍历直接写入video即可。
模糊匹配查找
bool SelsctLike(const std::string &key, Json::Value *videos)
{
#define SELECTLIKE_VIDEO "select * from tb_video where name like '%%%s%%';"
char sql[1024] = {0};
sprintf(sql, SELECTLIKE_VIDEO, key.c_str());
_mutex.lock();
bool ret = MysqlQuery(_mysql, sql);
if(ret == false)
{
_mutex.unlock();
return false;
}
MYSQL_RES *res = mysql_store_result(_mysql);
if(res == NULL)
{
std::cout << "mysql store failed!\n";
_mutex.unlock();
return false;
}
_mutex.unlock();//end
int num_rows = mysql_num_rows(res);
for(int i = 0; i < num_rows; i++)
{
MYSQL_ROW row = mysql_fetch_row(res);//获取字段
Json::Value video;
video["id"] = atoi(row[0]);
video["name"] = row[1];
video["info"] = row[2];
video["video"] = row[3];
video["image"] = row[4];
videos->append(video);
}
mysql_free_result(res);
return true;
}
- select * from tb_video where name like ‘%%%s%%’;在sql语句中应该为select * from tb_video where name like ‘%s%’;,但是在字符串中,sprintf将可以传给%s后,只剩下%,需要转义字符来保证语法正确,至于网上说的什么保证安全防止恶意冲击(hhhhhhhhhh,)
修改视频信息
bool Updata(int video_id, const Json::Value &video)
{
std::string sql;
sql.resize(4096 + video["info"].asString().size());
#define UPDATE_VIDEO "update tb_video set name = '%s', info = '%s' where id = '%d';"
sprintf(&sql[0], UPDATE_VIDEO, video["name"].asCString(),
video["info"].asCString(),
video_id);
return MysqlQuery(_mysql, sql);
}
- 很简单就是执行了MySQL修改语句。
测试用例
本来不打算写的,但一想万一有朋友认真看嘞,贴一下吧
void FileTest()//文件测设工具
{
ctv::FileUtil("./www").CreateDiretory();//创建文件
ctv::FileUtil("./www/index.html").SetContent(" ");//设置内容
std::string body;
ctv::FileUtil("./www/index.html").GetContent(&body);//将内容写入body中
std::cout << body.c_str() << std::endl;//打印需谨慎
//std::cout << "嘿嘿" << std::endl;
std::cout << ctv::FileUtil("./www/index.html").Size() << std::endl;//字符串大小
}
void JsonTest()
{
Json::Value val;
val["姓名"] = "校长";
val["年龄"] = 18;
val["成绩"].append(77.1);
val["成绩"].append(88.1);
val["成绩"].append(99.1);
std::string body;
ctv::JsonUtil::Serialize(val, &body);
std::cout << body << std::endl;
Json::Value stu;
ctv ::JsonUtil::UnSerialize(body, &stu);
std::cout << stu["姓名"].asString() << std::endl;
std::cout << stu["年龄"].asString() << std::endl;
for(auto &a : stu["成绩"])
{
std::cout << a.asFloat() << std::endl;
}
}
void DataTest()
{
ctv::TableVideo tb_video;
Json::Value video;
// video["name"] = "轻音少女";
// video["info"] = "yyds-----on";
// video["video"] = "/video/K-ON-.mp4";
// video["image"] = "/image/K-ON-.jpg";
//tb_video.Insert(video);
//tb_video.Updata(2,video);
//tb_video.SelectAll(&video);
//tb_video.SelectOne(1, &video);
//tb_video.SelsctLike("轻音", &video);
tb_video.Delete(2);
std::string body;
ctv::JsonUtil::Serialize(video, &body);
std::cout << body << std::endl;
}
工作量大的时候一定要写一写测一测,不然都不知道错哪了(哭)
请求与响应
这一块就是笔者写项目时遇到的知识栈以外的部分,没有代码,是项目需要的一部分知识拓展。
视频数据已经可以上传至数据库,数据库中视频是按路径存储的,怎么拿出来呢?
- 服务端提供的功能包括:新增视频、删除视频、修改视频、查询所有视频、查询单个视频、模糊匹配查询。
- 要让每一个功能对应到网页上的不同接口上。
- 接口感性认识来说,就是规定好长什么样的是什么(类似报头),一种特定的格式,什么样是查询,什么样式插入。
其实不重要,只是了解一下后续使用httplib库进行通信时,请求与响应部分,为什么那样写。
REST
REST(Representational State Transfer)是一种用于设计和构建网络应用程序的架构风格。它是一种轻量级、灵活且可扩展的方式,用于创建分布式系统和Web服务。REST 的设计原则可以帮助开发者构建具有良好可维护性、可伸缩性和性能的应用程序。
以下是 REST 的一些主要特点和原则:
资源(Resources):REST 将应用程序中的数据和功能抽象为资源。每个资源都有一个唯一的标识符(通常是URL),可以用来访问和操作该资源。
HTTP 方法(HTTP Methods):REST 基于HTTP协议,使用不同的HTTP方法来执行不同的操作。常用的HTTP方法包括GET(获取资源)、POST(创建资源)、PUT(更新资源)和DELETE(删除资源)等。
状态无关(Stateless):REST 是状态无关的,每个请求都包含了足够的信息以便服务器理解请求的意图,因此服务器不需要存储客户端的状态信息。
无会话(Sessionless):REST 不需要维护客户端会话状态,每个请求都应该包含足够的信息来处理请求。
统一接口(Uniform Interface):REST 的接口应该是统一的,这意味着它应该具有一致的资源标识符(URI)、HTTP方法、媒体类型等。
表示(Representation):资源的表示形式可以是不同的媒体类型,如XML、JSON、HTML等。客户端和服务器之间通过这些表示来交换数据。
自描述性(Self-descriptive):每个资源的表示应该包含足够的信息来描述资源的内容以及如何处理它。
分层系统(Layered System):REST 架构支持分层系统,允许在不影响客户端的情况下对服务器进行扩展、负载均衡和缓存等操作。
RESTful Web服务是一种符合REST原则的Web服务,通过HTTP协议提供资源的访问和操作。它通常使用HTTP动词来执行各种操作,并使用标准的HTTP状态码来表示操作的结果。RESTful API已经成为许多Web应用程序和移动应用程序的常见标准,因为它们易于理解和使用。
以上是百度百科,看也看不太懂,直接上例子。
在REST风格中定义了:
- GET方法:表示查询
- POST方法:表示新增
- PUT方法:表示修改
- DELETE方法:表示删除
- 资源正文数据采用Json、XML数据格式## 业务处理与网络通信
请求:(所有)
GET /video HTTP/1.1
Connection: keep-alive
......
响应:
HTTP/1.1 200 OK
Content-Length: xxx
Content-Type: application/json
......
请求:(关键字)
GET /video?search="电影1" HTTP/1.1
Connection: keep-alive
......
响应:
HTTP/1.1 200 OK
Content-Length: xxx
Content-Type: application/json
......
注意看 ?search=

是不是类似的。
请求://video/1中的1就是ID,这就是精确查找的格式(大体)
GET /video/1 HTTP/1.1
Connection: keep-alive
......
响应:
HTTP/1.1 200 OK
Content-Length: xxx
Content-Type: application/json
......
请求:(删除)
DELETE /video/1 HTTP/1.1
Connection: keep-alive
......
响应:
HTTP/1.1 200 OK
......
PUT /video/1 HTTP/1.1(修改)
Connection: keep-alive
......
响应:
HTTP/1.1 200 OK
......
上传需要注意,上传时视频文件与封面图片文件都是二进制格式,不适合rest,这里使用http。
请求:(上传)
PSOT /video HTTP/1.1
Content-Type: video/form-data; boundary="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
Content-Length: xxx
......
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name="name"
name(视频的名称)
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name="info"
info(视频的描述)
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name="video"; filename="video.mp4"
Content-Type: text/plain
video视频数据
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name="image"; filename="image.jpg"
Content-Type: text/plain
image封面图片数据
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name="submit"
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
响应:
HTTP/1.1 303 See Other
Location: "/"
httplib库
httplib 是一个基于 C++11 的简单、易用的 HTTP 服务器和客户端库。它提供了处理 Web 请求和响应的功能,支持路由、Cookie、SSL 加密等特性,使得开发者能央够方便地构建和处理 HTTP 服务端和客户端。
以下是 httplib 库的一些主要特性:
- 轻量级和易用性:httplib 设计简洁,使用方便,适合快速搭建简单的 HTTP 服务端或客户端。
- 支持多种操作系统:httplib 可以在多种操作系统上运行,包括 Windows、Linux 等。
- HTTP 服务器:可以创建和运行基于 httplib 的 HTTP 服务器,支持路由、中间件等功能,使得处理 HTTP 请求变得更加灵活。
- HTTP 客户端:可以使用 httplib 创建和发送 HTTP 请求,并处理服务器返回的响应,支持 GET、POST、PUT、DELETE 等常见的 HTTP 方法。
- 支持 SSL/TLS 加密:httplib 支持通过 SSL/TLS 加密协议进行安全的 HTTP 通信。
- 文件上传支持:提供对 multipart/form-data 类型数据的处理,方便处理文件上传相关的功能。
- 由于其简洁的设计和易用的特点,httplib 在开发人员之间广受欢迎,特别适合用于快速原型开发、小规模项目的搭建以及教学和学习等场景。
目前只需理解为,帮我们写好了网络传输socket(tcp),以及请求与响应报文的方法化。
业务与网络
接收客户端的请求,然后根据请求信息,明确客户端用户的意图进行业务处理,并返回相应的处理结果给客户端。网络部分使用了httplib,所以网络部分只有方法,主要是业务的处理。(如果说把网络部分作为项目的一个优化方向,同时也是作为不算新的新人的提高能力的一直方式,只是企业上,大量的开源代码上这种造轮子的场景并不多见,作为一个项目还是合群一点比较好)(个人目前暂时觉得)
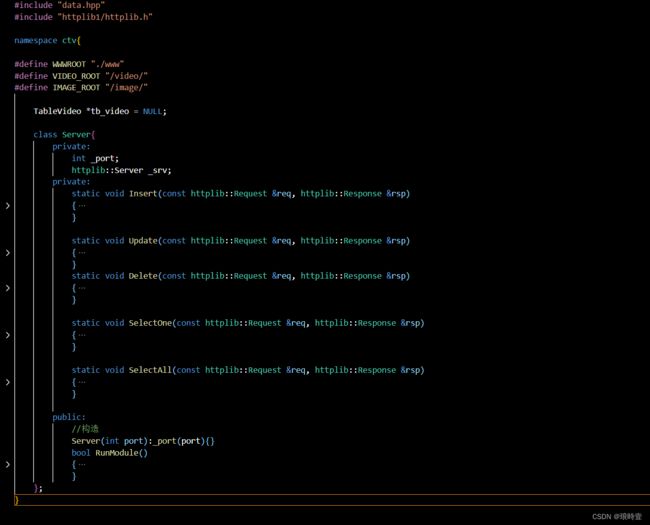
定义了一些常量,如 WWWROOT、VIDEO_ROOT 和 IMAGE_ROOT,用于指定服务器的根目录以及视频和图片的存储路径。
静态成员函数:类中定义了一系列静态成员函数,每个函数对应一个 HTTP 请求处理操作。这些函数包括:
-
Insert:处理 POST 请求,用于上传视频和相关信息。
-
Update:处理 PUT 请求,用于更新视频信息。
-
Delete:处理 DELETE 请求,用于删除视频和相关信息。
-
SelectOne:处理 GET 请求,用于获取单个视频的信息。
-
SelectAll:处理 GET 请求,用于获取所有视频的信息。
-
int _port;:这是一个私有成员变量,表示服务器的端口号。
-
httplib::Server _srv;:这是一个私有成员变量,表示使用 httplib 库创建的 HTTP 服务器对象。该对象被命名为 _srv,用于处理HTTP请求和响应。
插入 static void Insert(const httplib::Request &req, httplib::Response &rsp)
static void Insert(const httplib::Request &req, httplib::Response &rsp)
{
if(req.has_file("name") == false||
req.has_file("info") == false||
req.has_file("video") == false||
req.has_file("image") == false){
rsp.status = 400;
rsp.body = R"({"result":false, "reason":"上传格式出错"})";
rsp.set_header("Content-Type", "application/json");
return;
}
httplib::MultipartFormData name = req.get_file_value("name");
httplib::MultipartFormData info = req.get_file_value("info");
httplib::MultipartFormData video = req.get_file_value("video");
httplib::MultipartFormData image = req.get_file_value("image");
std::string video_name = name.content;
std::string video_info = info.content;
std::string root = WWWROOT;
std::string video_path = root + VIDEO_ROOT + video.name + video.filename;
std::string image_path = root + IMAGE_ROOT + video.name + image.filename;
if(FileUtil(video_path).SetContent(video.content) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"视频文件存储失败"})";
rsp.set_header("Content-Type", "application/json");
return;
}
if(FileUtil(image_path).SetContent(image.content) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"图片文件存储失败"})";
rsp.set_header("Content-Type", "application/json");
return;
}
//保存到数据库
Json::Value Video_json;
Video_json["name"] = video_name;
Video_json["info"] = video_info;
Video_json["video"] = VIDEO_ROOT + video.name + video.filename;
Video_json["image"] = IMAGE_ROOT + video.name + image.filename;
if(tb_video->Insert(Video_json) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"数据库新增数据失败"})";
rsp.set_header("Content-Type", "application/json");
return;
}
rsp.set_redirect("/index.html", 303);
return;
}
这段代码是一个静态成员函数 Insert。它接收一个 httplib::Request 类型的请求对象 req 和一个 httplib::Response 类型的响应对象 rsp。该函数用于处理客户端上传的文件以及将文件信息保存到数据库中。
首先,它通过检查请求中是否包含名为 “name”、“info”、“video” 和 “image” 的文件来确保上传的格式正确。如果其中任何一个文件不存在,则设置响应状态码为 400,返回一个包含错误原因的 JSON 响应,并设置响应头的 Content-Type 为 application/json,并结束函数执行。
接着,它使用 req.get_file_value 方法获取并解析每个文件的内容和其他相关信息,然后将视频名称、信息提取出来。
随后,它拼接存储文件的路径,并使用 FileUtil 对象将视频和图片文件内容写入对应的路径。如果文件写入失败,会设置响应状态码为 500,返回相应的错误信息,并设定响应头的 Content-Type 为 application/json,并结束函数执行。
然后,它创建一个 Json::Value 对象,将视频的名称、信息、路径等信息存储到其中,并调用 tb_video->Insert 方法将该 Json 对象中的数据插入数据库中。如果插入失败,会设置响应状态码为 500,返回相应的错误信息,并设定响应头的 Content-Type 为 application/json,并结束函数执行。
最后,如果一切操作顺利,会将响应状态码设置为 303(表示重定向),并将用户重定向到 “/index.html” 页面。
整体上,这段代码实现了处理文件上传、文件存储、数据库插入以及响应设置等功能。
-
httplib::MultipartFormData 对象通常包含以下属性和方法:
-
content:表示文件的内容,可以是二进制数据或文本数据。
-
filename:表示上传的文件名。
-
name:表示表单字段的名称。
-
其他可能的方法或属性用于访问和处理表单字段数据。
-
req.has_file 是 httplib 库中 httplib::Request 对象的一个方法,用于检查请求中是否包含指定名称的文件字段。
-
rsp.set_header(“Content-Type”, “application/json”); 这行代码用于设置 HTTP 响应头中的 Content-Type 属性为 “application/json”。在 HTTP 协议中,Content-Type 属性用于指示响应体的数据类型。通过将 Content-Type 设置为 “application/json”,服务器告知客户端返回的响应数据是 JSON 格式的内容。这样客户端在接收到响应时就能够正确解析响应体的数据类型,并进行相应的处理。
-
SetContent还记得吗,向文件中写入数据。
-
rsp.set_redirect 是 httplib 库中 httplib::Response 对象的一个方法,用于设置 HTTP 重定向响应。在代码中使用 rsp.set_redirect(“/index.html”, 303); 这个方法将响应状态码设置为 303,并将客户端重定向到 “/index.html” 页面。HTTP 状态码 303 表示 “See Other”,用于指示客户端应当使用 GET 方法重定向到另一个地址获取资源。在这种情况下,浏览器或客户端会自动发起对新地址的 GET 请求,以获取所需的资源。
修改 static void Update(const httplib::Request &req, httplib::Response &rsp)
static void Update(const httplib::Request &req, httplib::Response &rsp)
{
//获取id
int video_id = std::stoi(req.matches[1]);
Json::Value video;
if(JsonUtil::UnSerialize(req.body, &video) == false)
{
rsp.status = 400;
rsp.body = R"({"result":false, "reason":"视频解析错误"})";
rsp.set_header("Content-Type", "application/json");
return;
}
if(tb_video->Updata(video_id, video) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"数据库修改数据失败"})";
rsp.set_header("Content-Type", "application/json");
return;
}
return;
}
- req.matches[1] 用于获取从请求 URL 中匹配到的第一个参数值。
- 将请求到的报文反序列化到video中,再由video充当句柄用于修改。
删除 static void Delete(const httplib::Request &req, httplib::Response &rsp)
static void Delete(const httplib::Request &req, httplib::Response &rsp)
{
//获取视频id
int video_id = std::stoi(req.matches[1]);
//删除视频文件
Json::Value video;
if(tb_video->SelectOne(video_id, &video) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"要删除的视频不存在哦宝宝~~"})";
rsp.set_header("Content-Type", "application/json");
return;
}
std::string root = WWWROOT;
std::string video_path = root + video["video"].asString();
std::string image_path = root + video["image"].asString();
remove(video_path.c_str());
remove(image_path.c_str());
//删除数据库
if(tb_video->Delete(video_id) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"删除数据库信息失败了哦宝宝~~"})";
rsp.set_header("Content-Type", "application/json");
return;
}
}
-
拼接存储视频和图片文件的路径,并使用 remove 函数将这些文件从系统中删除。
-
调用 tb_video->Delete 方法删除数据库中指定 id 的视频信息。如果删除失败,设置响应状态码为 500,返回相应的错误信息,并设置响应头的 Content-Type 为 application/json,并结束函数执行。
单个查询 static void SelectOne(const httplib::Request &req, httplib::Response &rsp)
static void SelectOne(const httplib::Request &req, httplib::Response &rsp)
{
//获取视频id
int video_id = stoi(req.matches[1]);
//指定查询信息
Json::Value video;
if(tb_video->SelectOne(video_id, &video) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"对不起数据库出问题了~~"})";
rsp.set_header("Content-Type", "application/json");
return;
}
//响应正文
JsonUtil::Serialize(video, &rsp.body);
rsp.set_header("Content-Type", "application/json");
return;
}
从请求 URL 中获取视频的 id(假设 URL 匹配了一个参数)。然后,使用 tb_video->SelectOne 方法来查询数据库中指定 id 的视频信息。如果查询失败,则设置响应状态码为 500,返回一个包含错误原因的 JSON 响应,并设置响应头的 Content-Type 为 application/json,然后结束函数执行。
如果查询成功,将查询结果 video 序列化为 JSON 格式,并将其作为响应正文。然后设置响应头的 Content-Type 为 application/json。
返回响应。
多个查询 static void SelectAll(const httplib::Request &req, httplib::Response &rsp)
static void SelectAll(const httplib::Request &req, httplib::Response &rsp)
{
//查询所有
bool select_flag = true;
std::string search_key;
if(req.has_param("search") == true)
{
select_flag = false;//模糊匹配
search_key = req.get_param_value("search");
}
Json::Value videos;
if(select_flag == true)
{
if(tb_video->SelectAll(&videos) == false)
{
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"查询失败,系统错误~~"})";
rsp.set_header("Content-Type", "application/json");
return;
}
}
else
{
if(tb_video->SelsctLike(search_key, &videos) == false)
{
std:: cout << "11" << std::endl;
rsp.status = 500;
rsp.body = R"({"result":false, "reason":"查询失败,系统错误(~~"})";
rsp.set_header("Content-Type", "application/json");
return;
}
}
//序列化响应客户端
JsonUtil::Serialize(videos, &rsp.body);
rsp.set_header("Content-Type", "application/json");
return;
}
还是看上文有没有那个“?”,有就是模糊匹配,没有就是查询所有
- req.has_param检查请求中是否包含名为 “search” 的参数,如果存在则将 select_flag 置为 false,并获取参数值作为模糊匹配的搜索关键字。
- videos用于存储查询结果
报文响应设计RunModule()
Server(int port):_port(port){}
bool RunModule()
{
//初始化数据管理,创建指定目录
tb_video = new TableVideo();
FileUtil(WWWROOT).CreateDiretory();
std::string root = WWWROOT;
std::string video_real_path = root + VIDEO_ROOT;
FileUtil(video_real_path).CreateDiretory();
std::string image_real_path = root + IMAGE_ROOT;
FileUtil(image_real_path).CreateDiretory();
//搭建http
//设置静态资源根目录
_srv.set_mount_point("/", WWWROOT);
//设置对应关系
_srv.Post("/video", Insert);
_srv.Delete("/video/(\\d+)", Delete);
_srv.Put("/video/(\\d+)", Update);
_srv.Get("/video/(\\d+)", SelectOne);
_srv.Get("/video", SelectAll);
//启动服务器
_srv.listen("0.0.0.0", _port);
return true;
}
-
通过 new TableVideo() 创建了一个 TableVideo 类型的对象 tb_video 来管理视频数据。接着,使用 FileUtil(WWWROOT).CreateDiretory() 创建了一个指定目录,随后依次创建了视频文件和图片文件的存储目录。
-
通过 _srv.set_mount_point(“/”, WWWROOT) 设置了静态资源根目录,并为不同的 HTTP 请求方法设置了对应的处理函数:
-
POST 方法对应路由 “/video”,调用 Insert 函数来处理视频信息的插入;
-
DELETE 方法对应路由 “/video/(\d+)”,调用 Delete 函数来处理指定 id 的视频信息的删除;
-
PUT 方法对应路由 “/video/(\d+)”,调用 Update 函数来处理指定 id 的视频信息的更新;
-
GET 方法对应路由 “/video/(\d+)”,调用 SelectOne 函数来处理获取指定 id 的视频信息;
-
GET 方法对应路由 “/video”,调用 SelectAll 函数来处理获取所有视频信息。
-
调用 _srv.listen(“0.0.0.0”, _port) 启动服务器,开始监听指定端口的请求。
服务运行代码
void ServerTest()
{
ctv::Server server(9090);
server.RunModule();
}
int main()
{
// FileTest();
//JsonTest();
//DataTest();
ServerTest();
return 0;
}
前端细节
前端部分自我能力,主要是套用网络上的模板。
留下自己能用的部分后实现了几大功能。
展示页面视频随着用户上传自动排列,通过vue.ajax实现一些位置的动态变化。
div>
<script src="js/jquery-1.12.1.min.js">script>
<script src="js/bootstrap.min.js">script>
<script src="js/lity.js">script>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js">script>
<script>
$(".nav .dropdown").hover(function () {
$(this).find(".dropdown-toggle").dropdown("toggle");
});
script>
<script>
Vue.config.devtools = true;
let app = new Vue({
el: '#myapp',
data: {
author: 'raylanch',
videos: [],
},
methods: {
get_allvideos: function () {
$.ajax({
url: "/video",
type: "get",
context: this,
success: function (result, status, xhr) {
this.videos = result;
}
})
}
}
});
app.get_allvideos();
<script>
Vue.config.devtools = true;
let app = new Vue({
el: '#myapp',
data: {
author: 'raylanch',
video: {}
},
methods: {
get_param: function(name) {
return decodeURIComponent((new RegExp('[?|&]' + name + '=' + '([^&;]+?)(&|#|;|$)').exec(location.href) || [, ""])[1].replace(/\+/g, '%20')) || null
},
get_video: function() {
var id = this.get_param("id");
$.ajax({
url: "/video/" + id,
type: "get",
context: this,
success: function (result, status, xhr) {
this.video = result;
}
})
},
updata_video: function(){
$.ajax({
url: "/video/" + this.video.id,
type: "put",
data: JSON.stringify(this.video),
context: this,
success: function (result, status, xhr) {
alert("修改成功")
window.location.reload();
}
})
},
delete_video: function(){
$.ajax({
url: "/video/" + this.video.id,
type: "delete",
context: this,
success: function (result, status, xhr) {
alert("删除成功")
window.location.href = "/index.html";
}
})
}
}
});
app.get_video();
script>
- data 属性中包含了一个名为 author 的字符串变量和一个名为 video 的空对象。
- methods 属性中包含了以下几个方法:
- get_param: 这个方法用于从当前 URL 中获取指定名称的参数值。
- get_video: 通过发起一个 AJAX GET 请求,获取指定 id 的视频信息,并将结果赋值给 this.video。
- updata_video: 通过发起一个 AJAX PUT 请求,更新当前视频信息,并在请求成功时刷新页面。
- delete_video: 通过发起一个 AJAX DELETE 请求,删除当前视频信息,并在请求成功时跳转至首页。
*调用了 app.get_video() 方法来获取并展示指定id的视频信息。
这块真不知道怎么说,写完就忘了
文档总结
工程确实需要文档,自己刚刚写完没两天的项目,自己写文档的时候有好多已经忘了是什么鬼了(),
终于算是写完了,侧重点还是在逻辑与内容上,一些使用性强的内容就弱化了。
