深入理解Python生成器和yield
深入理解Python生成器和yield
我在《Python性能优化指南–让你的Python代码快x3倍的秘诀》中有提到,在处理大文件或大数据集时用生成器可以提高性能。很多朋友会问:“为什么用生成器就能提升性能呢?”。今天,我就带大家深入看一下Python的生成器模型和yield语句。看完本文,你将彻底明白什么是生成器以及如何用好生成器。
 -
-
文章目录
-
- 什么是生成器
- 理解生成器
-
- 生成器的迭代性
- yield的作用
- 生成器推导式
- 生成器的性能
- 生成器的高级用法
-
- send()
- throw()
- close()
- 总结
什么是生成器
根据PEP 255的定义,生成器是一类特殊的函数,它会返回一个延迟迭代器(lazy iterator)。延迟迭代器跟列表很像,都能循环遍历;但与列表不同的是,延迟迭代器不会将内容放到内存中。这就使得生成器在处理流数据和超大数据集的时候非常有用。
比如你有一个超大的数据集,其大小比机器的物理内存还要大,现在我们想统计这个数据集有多少样本(行数)。我们通常的思路是将这个csv文件以列表的形式读取到内存,然后逐行遍历累计行数(或者用len()方法获得列表的长度)。代码思路如下:
def csv_reader(file_name):
# 打开文件
file = open(file_name)
# 读取文件,并以换行符为分隔符将文件内容拆分到数组
result = file.read().split("\n")
return result
csv_gen = csv_reader("very_large_dataset.csv")
row_count = 0
for row in csv_gen:
row_count += 1
print(f"Row count is {row_count}")
上面的代码思路没问题,但是忽略了一个可能的事实——当文件超大时,内存可能无法装下如此大的数据,此时file.read()会报MemoryError
Traceback (most recent call last):
File "ex1_naive.py", line 22, in
main()
File "ex1_naive.py", line 13, in main
csv_gen = csv_reader("file.txt")
File "ex1_naive.py", line 6, in csv_reader
result = file.read().split("\n")
MemoryError
除了内存可能爆掉,上面的代码还有一个严重问题——那就是速度很慢。这是因为内存压力太大,操作系统使用虚拟内存存储和交换数据,导致整部电脑运行速度缓慢,甚至卡死不动。
处理大数集的正确做法是使用生成器。请看下面正确的代码示例:
def csv_reader(file_name):
for row in open(file_name, "r"):
yield row
因为open()会返回一个生成器对象,我们可以迭代整个生成器对象,然后yield每一行。这里yield将csv_reader()变成了一个生成器函数。其结果是csv_reader()不再返回每一行数据,而是返回一个迭代器对象,供后面延迟迭代。
这里我们还可以用生成器推导式(类似列表推导式)让代码更加简明,更加Pythonic:
csv_gen = (row for row in open(file_name))
这里如果看不懂也没关系,后面我会详细讲解yield语句。这里你只要知道:
- 用
yield返回的是生成器对象 - 用
return返回的是数据
理解生成器
上一节我们通过一个例子带大家宏观地看了一下生成器,教大家创建生成器的2种主要方法:生成器函数和生成器推导式,你可能已经隐约能了解到生成器是如何工作的。本节将带大家深入理解生成器的工作原理。
生成器函数看上去跟不同函数一样,主要区别在于生成器函数用yield替代了return。例如下面的代码:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
上面的代码会生成一个_无限序列_。除了yield部分,其他都跟常规函数一样。yield语句表示这里将值发送给其调用者,但与return不同的是,这里不会退出函数。
这里你可能会问,如果遍历这个生成器会发生什么?我们可以试一下:
for i in infinite_sequence():
print(i)
⚠注意:实际开发中我们不需要自己实现无限序列生成器,Python的
itertools模块提供了一个非常高效的无限序列生成器——itertools.count()。import itertools
for i in itertools.count():
print(i)
上面的代码会一直循环下去,输出 [ 0 → + ∞ ) [0 \rightarrow +\infin) [0→+∞),直到你手动结束程序。为什么会这样?这里给大家深入讲解一下生成器的迭代性。
生成器的迭代性
生成器是可迭代的,因为生成器实现了_迭代协议_。
迭代协议即__next__方法。任何实现了__next__方法的对象都是_可迭代的_。可迭代对象可以在for循环或其他迭代工具中遍历。每次遍历都会触发__next__方法前进到下一结果,达到末尾时会触发StopIteration,捕获到StopIteration遍历就结束。
我们可以用__next__方法手动遍历可迭代对象。上面的代码
for i in infinite_sequence():
print(i)
可以改写成:
while True:
i = gen.__next__()
print(i)
ℹ提示:
__next__是内部协议,在实际开发中不建议直接调用。Python中内置了next()方法,接收一个可迭代对象为参数,代替直接调用__next__方法。next(iter_obj)相当于iter_obj.__next__()。
yield的作用
生成器是有状态的。简单来说,这个状态是由yield来维持的,yield的主要工作是用类似返回语句的方式控制生成器函数的流程。
还以无限序列生成器为例,每次next()方法被调用时(无论是显式调用还是for语句中的隐式调用),生成器函数会执行到yield语句就暂停下来,并返回yield的值给生成器的调用者。此时生成器函数的状态会被暂存下来,这里的所说的状态既包括生成器的内部变量,也包括指令指针、内部栈和异常处理。
当再一次调用next()方法时,生成器会恢复运行,上一次yield的值会+1,然后重新执行到yield语句,生成器再一次暂停并返回yield的值给调用者,同时暂存当前的状态。由于每一次执行next()生成器都会yield一个值,不会触发StopIteration,所以会一直迭代下去。
整体运行流程可以用下面的流程图来完整描述:

生成器推导式
跟列表推导式一样,生成器推导式可以让你用最少的代码快速创建生成器。除了代码简洁外,生成器推导式还有另一个优势:生成器推导式无需在迭代之前在内存中创建和保存整个生成器对象。换句话说,使用生成器推导式内存开销会更小。举了例子大家就明白了,请看下面的代码:
nums_squared_lc = [num**2 for num in range(5)]
nums_squared_gc = (num**2 for num in range(5))
上面两行代码非常像,都是生成5以内自然数的平方,但却有着本质区别。第一行是列表推导式,执行后nums_squared_lc的数据类型是_列表_。而第二行是生成器推导式,执行后nums_squared_gc的数据类型是_生成器对象_。我们可以输出一下看一下二者的区别:

从输出结果可以清楚的看到,nums_squared_lc是个列表,所以print()将整个列表的值输出出来。而nums_squared_gc 是生成器对象(generator object),且这个生成器对象还是通过生成器推导式创建的()。如果生成器对象是通过生成器函数创建的,那么这的输出会显示生成器函数名,如:
生成器的性能
本文开头以及《Python性能优化指南》都提到,**在处理大文件或大数据集时,生成器的效率会更高。**本节我们就详细看一下生成器的性能。
生成器最大的作用是优化内存,这在处理超大文件时非常有用。我们可以比较一下相同功能的列表和生成器的内存占用。
import sys
nums_squared_lc = [i ** 2 for i in range(10000)]
sys.getsizeof(nums_squared_lc)
nums_squared_gc = (i ** 2 for i in range(10000))
print(sys.getsizeof(nums_squared_gc))

从输出可以看到,列表推导式生成的列表大小85176,而生成器推导式生成的生成器大小只有104。列表的内存占用是生成器的800倍数!
列表内存占用比生成器大的原因很好理解,因为列表将所有的数据都装入了内存,而生成器只是一个生成器对象,每次需要时会返回一个数据。内存上生成器有巨大的优势,我们接着看一下二者速度上的差别。
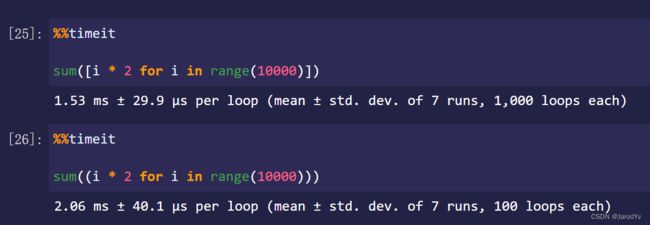
从输出上看,列表平均用时1.53ms,生成器平均用时2.06ms,列表比生成器还要快25%。不是说生成器能提高性能吗?为什么这里生成器的速度还不如列表?
这是因为我们的数据还是太少。当数据量不大时,内存压力不大,此时列表的速度比生成器要快,因为正如前面介绍的,生成器要暂存状态,这会产生额外的开销,所以速度会比列表慢一些。
而当数据量很大的时候,即便内存没有被塞满,内存的压力也会很大。因为还有很多其他程序在运行,也需要内存,此时操作系统一般会使用虚拟内存(Windows)或交换空间(Linux)。在内存紧张时,操作系统会将部分内存数据部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。虚拟内存的性能相比内存来说低很多,这就是为什么内存不够时电脑会变得非常慢。因此当处理大文件或大数据集时,是内存拖累了列表的性能,而生成器就不会有这个问题。这就是为什么在处理大数据大文件时用生成器性能会更好的原因。
这里我们可以总结一个原则:
- 当数据量小的时候,列表的速度比生成器快;(因为列表数据都在内存中,且内存无压力)
- 当数据量大的时候,生成器的速度比列表快。(因为列表将数据都加载到内存中,内存压力大,会启用虚拟内存,拖累了运行速度,而生成器不会给内存带来压力,性能反而高)
生成器的高级用法
上面介绍的是生成器的常规用法,除了yield,生成器还有一些高级用法,主要涉及下面3个方法:
- send()
- throw()
- close()
send()
send()方法的作用是恢复生成器运行,并向生成器发送一个值_value_,这个_value_将作为生成器的当前值,send()方法会返回生成器的下一个值,无值时会返回StopIteration。
我们来看个例子:
def accumulator():
total = 0
value = None
while True:
# value接收sent发送的数据,并返回total
value = yield total
if value is None:
break
total += value
generator = accumulator()
generator.send(None)
# Out: 0
generator.send(1)
# Out: 1
generator.send(2)
# Out: 3
generator.send(10)
# Out: 13
这里最难理解的是这一句value = yield total。这一句要分2部分看来看:首先是yield total,生成器返回值total;然后是value = yield,它接收send传入的值并赋给value。因此generator.send(None)执行时,执行到yield total会返回0,此时程序处于暂停状态。当执行generator.send(1)时,生成器恢复运行,执行value = yield,将传入的1赋给value,接着向下运行total += value,然后又执行到yield total,此时total的值为1,因此返回1,程序再一次进入暂停状态。同理执行generator.send(2)时,生成器恢复运行,先将2赋给value,然后value加到total上,然后返回value…依次类推。整个过程值的变化参加下表:
语句
上一次yield值
value
本次yield值
generator.send(None)
–
–
0
generator.send(1)
0
1
1
generator.send(2)
1
2
3
generator.send(10)
3
10
13
这里要注意的是,当用send()启动生成器时,必须传None,否则就会报错

因为此时没有生成器表达式来接收这个值(生成器执行到yield total就暂停了)。所以**send(None)等同于next()**。
throw()
.throw()方法可以让我们在生成器中抛出异常。比如我们将上面的例子稍微改造一下:
t = 1
while True:
if t > 10:
generator.throw(ValueError("超过范围10"))
t = generator.send(t)
print(t)
输出结果如下:
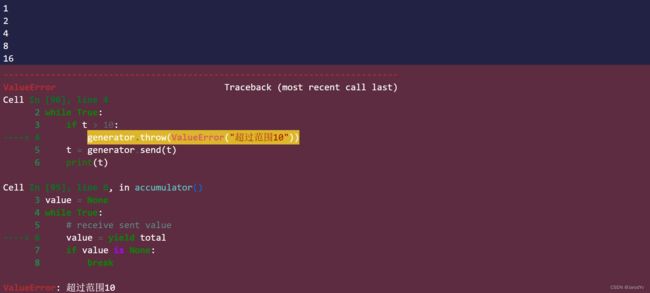
当需要抛出异常时throw()方法就非常好用。一旦抛出异常生成器也会跟着失效。此后再使用都会报StopIteration。想要再次使用,需要重新初始化并启动生成器。
close()
上面介绍的throw()抛出异常后会关闭生成器。如果不需要抛出异常,那么关闭生成器更优雅的方式是使用close()方法。我们用close()更新一下上一节的代码:
t = 1
while True:
if t > 10:
generator.close()
t = generator.send(t)
print(t)
上面的代码执行后,最终会抛出StopIteration。

这样的好处是StopIteration可以终止迭代。而throw()需要我们在外层通过try...except捕获抛出的异常,并做相应处理。二者各有其适用的场景,具体看开发中的需要。
总结
本文带大家深入地学习了生成器和yield语句。生成器在处理大文件大数据集时非常有用,它占用内存少,不会拖慢机器性能,从而能够更快的处理数据。
我们还学习了生成器的高级用法,尤其是send()方法,它可以向生成器中传递数据,利用这个功能可以实现协程(coroutine)。协程在很多场景下非常有用,比如构造数据流,后面我会专门写一篇教程介绍Python的协程。