Python爬虫之requests+验证码破解+scrapy框架基础
requests是Python自带的一个第三方库(针对解决爬虫问题)使得收集数据,更加简单。
一个类型和六个属性:
我们知道使用urllib的三步法;
请求对象定制、模拟浏览器向服务器发送请求、获取响应数据
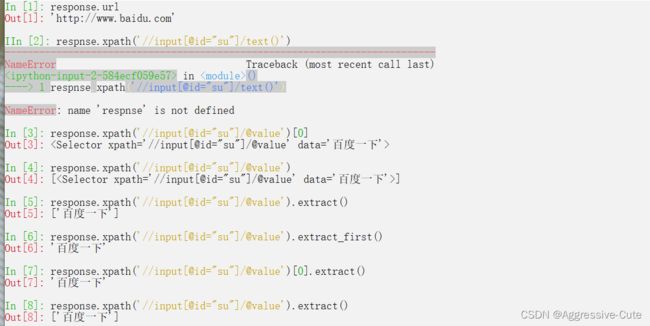
这里的response的类型是"HTTPResponse"



get请求(带有参数的情况):直接传入数据,不需要进行编码。

post请求,表单数据也是不需要编码的,直接传入即可。

想到百度翻译:其实我们可以写个程序来查询单词的意思ACTION!!!


比较简单,利用循环+百度翻译服务器提供的数据 返回到本地进行查询。
验证码破解:
主要难点:
隐藏域;
验证码;
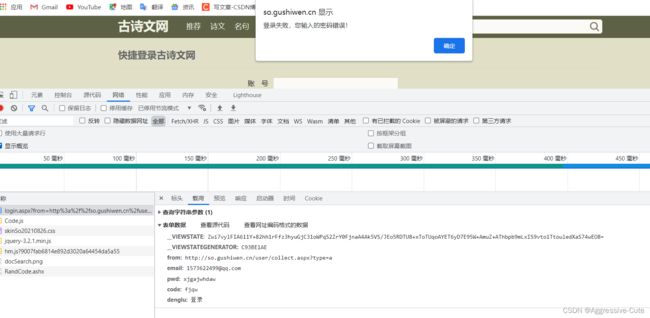

可以看到这个网站的请求方式采用post请求、表单数据中 两个__的反爬手段是不断地变化
那么该怎么解决呢?
可以把这一页的网页源码拿到 通过xpath或者bs4解析拿到 对应的value 就成功了。
解决代码:
bs4解析手法:
注意:select返回列表数据[0] 如果想获取该标签对应的数据 需要.attrs.get('属性名')
接下来就是处理验证码的问题了:
我们找到这个验证码的src(图片路径)将图片下载下来 定义变量输入传入 验证登录即可。

抓取登录接口:

但是这样做是不能拿到登录的页面的,坑点来了:
第一次请求获得图片验证码
第二次请求获取网页
两次的请求不一致 !,需要使用requests里的session 来确立两次请求实同一个请求。

这样才能解决验证码问题:
session可以将两次请求一致!!!可以理解为加载同一个网页,相同的请求。
怎么请求一致的? 先使用session 保存图片 再将登录使用的requests换成session
这样就可以解决请求一致的问题了! session使得两次请求一致 共享的作用
session步骤:
session=requests.session()
response=session.get(图片路径)
content=response.content 拿到二进制文件进行下载到本地 注意写入方法是(wb)
访问登录页面:
session.post(...)
爬虫之scrapy框架:
scrapy是什么?他是一个为了爬取网站数据,提取结构性数据(如:ul下有li)而编写的应用框架,可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装scrapy的方法(有一定的难度,有仔细解读):
- pip install scrapy
- 如果1报错,可能是因为没有twisted这个库,scrapy依赖twisted这个库进行运作。解决方法:
https://www.lfd.uci.edu/~gohlke/pathonlibs/#twisted 下载对应电脑的版本 (cp是python的版本) (amd是你操作系统的版本) 下载安装好twisted后再次使用1的指令。 - 报错提示:更新pip指令 解决方案:终端输入:python -m pip install --upgrade pip
- 报错提示:win32 解决方案:pip install win32
- 直接下载anaconda 仔细想想自己做过什么坏事,无药可救!!!
anaconda使用步骤:
双击打开anaconda
点击environments
点击 not istalled
输入scrapy,然后点击应用apply,并且切换环境,在python解释器卡槽选择anaconda环境。
Scrapy使用流程:
- 创建爬虫项目
- 创建爬虫文件
- 运行爬出文件
对应指令:
1、scrapy startproject 爬虫项目名字
2、cd 爬虫项目名字\爬虫项目名字\spiders(进入spiders文件 在其下面创建爬虫文件)
创建爬虫文件指令:scrapy genspider 爬虫名字 需要爬取数据的网页
例如: scrapy genspider baidu www.baidi.com 注意:不需要写http协议 会自动生成!!!
3、在爬虫文件中写好了代码(解析好了) 终端使用命令获得需要爬取的数据
运行爬虫文件: scrapy crawl 爬虫文件名
认识一下爬虫核心文件:
spiders目录下对应创建的爬虫文件

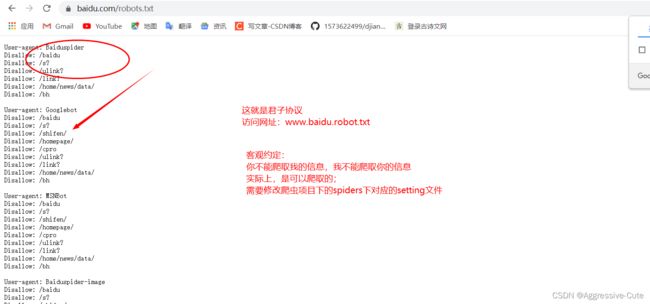
约定俗成的君子协议 在setting.py文件里设置(robot.txt)
案例:
![]()


scrapy项目各个组成部分解读:
我放在github上了,大家可以看看
本地上传github服务器:

本地传文件到github服务器 使用指令 git push 将本地文件发送到服务器存储。

注意:上传的时候能会连接错误,大多是因为当前网络不稳定造成 ,多提交几次就好了!!!
先做一个案例:爬取58tc二手房价的信息,并且保存到本地excel文件:
操作流程:
创建项目
创建爬虫文件
运行爬虫文件,收获数据
chrome浏览器访问58tc进入网站 爬取想要数据 例如:爬取重庆市渝中区二手房数据

将爬取的数据保存到本地 后期我们可以利用管道下载 连接数据库,写sql 保存数据到数据库。

scrapy运行流程:
创建爬虫项目
找到爬取的网站url,创建爬虫文件 写xpath解析
拿到网页源码数据,开始爬取需要的数据。
导入表格,爬虫完成。
注意:
运行爬虫文件:scrapy crawl 爬虫文件名
应该在spiders文件夹内执行
scrapy组成介绍:
(1)引擎
自动运行、会自动组织所有的请求对象、分发给下载器
(2)下载器
从引擎处获取到请求对象后,请求数据
(3)spiders 这个类定义了如何爬取某个网站,包括爬取的动作、分析网页
(4)调度器
自动调度
(5)管道
最终处理数据的管道(下载数据)、会预留给我们处理数据
item pipeline组件应用:
清理html数据
验证爬取的数据
查重
将爬取的结果保存到数据库中
scrapy的工作原理:

过程:
- 引擎向spiders要url
- 引擎将爬取的url给调度器
- 调度器将url生成的请求对象放入指定的队列里
- 从队列中出队一个请求
- 引擎将请求交给下载器进行处理
- 下载器向互联网发送请求获取数据,这一步可能拿不到数据
- 下载器将数据(或者url)发送给引擎
- 引擎将数据给spiders(response)
- spiders通过xpath解析数据,得到数据or url(会继续获取数据)
- spiders将数据或者 url给引擎
- 引擎判断是数据还是url if 数据:传给管道;else:url:重新执行上面操作。
简单流程:
spiders->引擎->调度器->引擎->下载器->互联网->下载器->引擎->spiders-{判断十数据还是url
数据就执行:spiders->引擎->管道
url就执行:重复执行。。。
scrapy shell介绍:
针对复杂爬虫业务,我们可以使用scrapy shell
感谢你的阅读,下篇爬虫文章将会陆续发布,我们下期再见。