Python实现员工管理系统(Django页面版 ) 翻页封装
翻页处理在上一篇博客有进行详细的讲述,在本篇博客只会教大家如何封装代码。
Python实现员工管理系统(Django页面版 ) 五-CSDN博客
在上一小节中我们实现了条件筛选和翻页处理,我们可以从前面写的一些组件可以发现,翻页处理可以运用到每一个组件的列表展示操作中,因此如果我们将翻页操作进行一个封装,那我们是不是就不用重写代码了,这会让我们的代码看上去更加具有可拓展性且不会出现大量的代码冗余。
深拷贝处理:
在上一小节中不知道大家有没有发现,其实上一小节的代码并没有做的完善,里面会出现一个“bug”。
例如在我们进行条件筛选的时候,我想要查询等级为二级的所有数据。
![]()
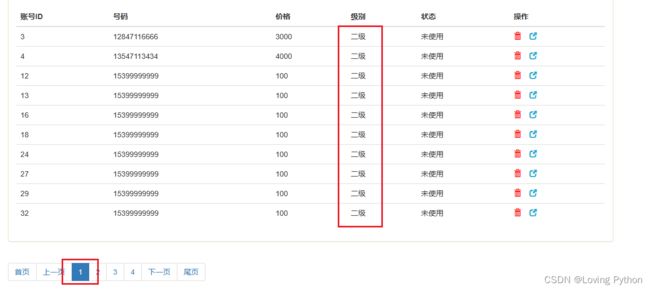
它会正常给我们返回所有级别为二级的所有数据,现在我想要在这个的前提下查找二级数据的第二页数据我们看看会发生什么。
![]()
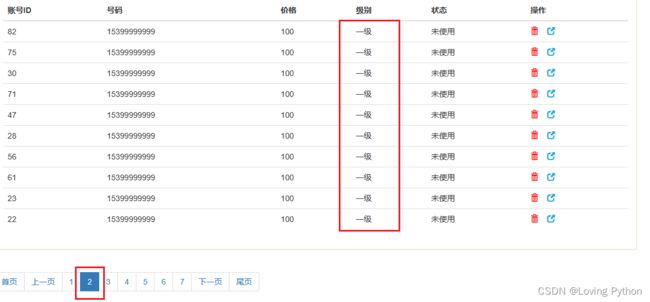 我们可以发现在我们进行点击第二页时,它只会给我们返回所有数据的条件下的第二页数据,而不是给我们返回等级为二级的数据的第二页,我们当然希望它能一起给我们返回,我们可以观察上的url地址,我们在点击不同的查询条件时它会给我们返回的参数不同,那如果我们能够让条件查询的query参数和翻页处理的page参数能够同时出现在url上,那我们这个问题是不是就解决了。
我们可以发现在我们进行点击第二页时,它只会给我们返回所有数据的条件下的第二页数据,而不是给我们返回等级为二级的数据的第二页,我们当然希望它能一起给我们返回,我们可以观察上的url地址,我们在点击不同的查询条件时它会给我们返回的参数不同,那如果我们能够让条件查询的query参数和翻页处理的page参数能够同时出现在url上,那我们这个问题是不是就解决了。
在这里我们就可以采用深拷贝来解决这个问题,我们首先获取当前的页面请求,然后将它做一个深拷贝,然后让它与当前页面的page参数进行一个整合,是不是就解决了我们这个问题。
我们在pretty_list中加入下面的代码,然后重新从页面中发起请求。
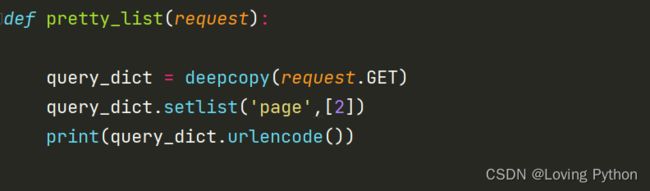
我们可以发现当我们选择条件为二级的时候,它会为我们拼接page这个参数,且值为2。那么这个问题是不是就被成功解决了。
![]()
封装翻页处理:
首先我们在project_manage中新创建一个包名为utils用于存放我们的翻页模块,然后我们在包中新建一个模块名为 pagination ,我们在这个模块中新建一个类名Pagination 为用于存放我们模块代码,接下来我们对代码进行一个编写。
确认需要传递的参数
由于我们是想要更多的组件都能复用这个模块,那么我们就得确认我们模块需要传递的参数,不能对某个组件进行单独处理。
- request 请求参数:我们首先需要有用户发送过来的请求,因为用户发送过来的请求中有我们需要的url参数及参数值,而后续我们进行深拷贝的时候也需要对这个请求进行拷贝。
- queryset 数据参数:我们需要获取到用户当前需要查看的数据有哪些,这样我们才能知道当前数据可以分多少页。
- page_size 当前页面数据数量参数:这是一个可选参数,我们默认设置为10条数据,我们也可以通过传参进行一个修改。
- page_param 需要进行深拷贝的参数名:这是一个可选参数,默认参数名为page,如果我们后续名字更改,我们也可以通过更改这个page直接更换,也不用每条代码都进行检查。
- plus 基准参数:这是一个可选参数,我们在上一小节中有说过,当我们需要展示7个页码进行页面展示的时候,我们就可以将基准设置为3,它会给我们展示当前页面的前三条数据和后三条数据。
class Pagination(object):
def __init__(self,request,queryset,page_size=10,page_param='page',plus=3):
"""
:param request: 请求
:param queryset: 数据表查询结果
:param page_size: 当前一页展示的数据
:param page_param: 翻页的参数名
:param plus: 当前页左右的li数量
"""
self.page_param = page_param
# 没有值则取1
page = request.GET.get(page_param,'1')
# 防止用户数据错误数据类型,数字判断
if page.isdecimal():
page = int(page)
else:
page = 1
self.page = page
self.start = (page - 1) * page_size
self.end = page * page_size
# 统计数据表当中有多少条数据
self.page_queryset = queryset[self.start:self.end]
total_count = queryset.count()
total_page_count,div = divmod(total_count,page_size)
if div:
total_page_count += 1
self.total_page_count = total_page_count
self.plus = plus
# 分页+筛选/搜索
get_query_dict = deepcopy(request.GET)
self.query_dict = get_query_dict其中基本上都是我们在上一小节中已经说过的代码了,增加了一个深拷贝需要注意。
然后我们就需要构造一个自定义函数用于返回我们最后的页码处理的html代码。
pagination.py
def page_html(self):
# 如果当前数据表的总页数小于7
if self.total_page_count < 2 * self.plus + 1:
start_page = 1
end_page = self.total_page_count
else:
if self.page <= self.plus:
start_page = 1
end_page = 2 * self.plus + 1
else:
if (self.page + self.plus) > self.total_page_count:
start_page = self.total_page_count - 2 * self.plus
end_page = self.total_page_count
else:
start_page = self.page - self.plus
end_page = self.page + self.plus
# 页码列表
page_str_list = []
# 首页
self.query_dict.setlist(self.page_param,[1])
page_str_list.append(f'首页 ')
# 上一页
if self.page > 1:
self.query_dict.setlist(self.page_param, [self.page - 1])
page_str_list.append(f'上一页 ')
else:
self.query_dict.setlist(self.page_param, [1])
page_str_list.append(f'上一页 ')
# 当前7页
for page_num in range(start_page, end_page + 1):
if page_num == self.page:
self.query_dict.setlist(self.page_param, [page_num])
page_ele = f'{page_num} '
else:
self.query_dict.setlist(self.page_param, [page_num])
page_ele = f'{page_num} '
page_str_list.append(page_ele)
# 下一页
if self.page < self.total_page_count:
self.query_dict.setlist(self.page_param, [self.page+1])
page_str_list.append(f'下一页 ')
else:
self.query_dict.setlist(self.page_param, [self.total_page_count])
page_str_list.append(f'下一页 ')
# 尾页
self.query_dict.setlist(self.page_param, [self.total_page_count])
page_str_list.append(f'尾页 ')
serch_string = """
"""
page_str_list.append(serch_string)
from django.utils.safestring import mark_safe
page_string = mark_safe(''.join(page_str_list))
return page_string很多的代码逻辑在上一小节已经说过了,在这里就不在重复,其中需要注意的就是对于每一个li标签我们进行了修改,我们需要传入更新后的参数进去。
pretty.py
# -------------------------账号管理----------------------------------------------
def pretty_list(request):
# 搜索
dict_data = {}
value = request.GET.get("query")
if value:
dict_data["mobile__contains"] = value
# 筛选
level = request.GET.get("level")
if level:
dict_data["level__contains"] = level
# 翻页
queryset = models.PrettyNum.objects.filter(**dict_data).order_by("level")
page_object = Pagination(request, queryset)
obj_list = models.PrettyNum.level_choice
# data_pretty_list页面当中展示的数据
# page_string 分页操作
return render(request, "pretty_list.html",
{"data_pretty_list": page_object.page_queryset, "page_string": page_object.page_html(),
"obj_list": obj_list})这样我们对于翻页代码的封装就完成了。下面我们开始对于其他组件进行一个修改,同样将这个翻页处理赋予进去。
user.py
def user_list(request):
data_list = models.UserInfo.objects.all()
obj_page = Pagination(request,data_list)
return render(request, 'user_list.html', {'data_list': obj_page.page_queryset,'page_string':obj_page.page_html()},)user_list.html

 这样我们的封装翻页处理就完成了,后续我们添加翻页操作的时候,只需要将这个模块导出即可。
这样我们的封装翻页处理就完成了,后续我们添加翻页操作的时候,只需要将这个模块导出即可。