详解大火的自动驾驶数据闭环与工程化问题
作者 | 萧猛 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/555838623?utm_id=0
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
本文只做学术分享,如有侵权,联系删文
1前言
关于自动驾驶的软件架构,我之前有几篇文章《智能驾驶域控制器的软件架构及实现》(上,下),《中间件与SOA》(上,中,下)。
这篇文章的重点不在于具体的软件架构,而在于软件架构的工程化落地。因为再好的架构,也需要变成真正可以稳定运行的产品才能体现其价值。而自动驾驶相关的软件系统关联了非常多的技术领域,每个技术领域有专门的知识体系,需要专门的人才,需要解决特定的问题。而完整的自动驾驶系统是需要所有相关的技术一起协同工作的,任何一个领域在技术或工程上的短板,都将影响整个系统的可用性、可靠性、安全性。
同时在研发组织上,也需要让不同领域的技术团队能够独立的开发、独立测试验证,最后还能集成在一起。那么如何拆得开、拆得好,还能整合起来,就是工程落地过程中至关重要的顶层设计问题。
第1章叙述闭环的抽象概念以及研发闭环的界定。阐述如何依据最小变量原理来拆解研发闭环,使得复杂系统的研发及集成过程可控。
第2章叙述产品概念上的闭环思路。自动驾驶作为跨多个技术领域的复杂产品,很难一步到位解决所有问题。本章从产品角度出发,提出纵横交叉的产品演进路线,使得自动驾驶系统工程化道路上的每一步的难度降低,也让整个系统能在早期就开始逐步集成,提高整体工程化成功的可能性。
第3章是本文的重点。目的是阐述数据驱动闭环的基本原理以及方法论。
这一章中,我们先给出数据概念模型及其分析,重点阐明语义层级的概念。然后我假设一个AEB 的技术方案,作为我们讨论的功能范围的锚定点。基于概念模型,分析这个技术方案涉及算法的语义层级分解。
我们再给出智能驾驶系统集成的一般原理,分别阐述“算法串接、执行平台、数据规模”三个集成纬度的各自概念和相互组合关系。并将这个一般原理应用到 AEB 方案的系统集成上,给出一个参考的 AEB 功能的系统集成路径。这个集成路径上涉及了大量的工具链,我们重点分析了其中的仿真测试工具链,并对不同的仿真和测试的手段做了对比,分析其各自的用途和侧重点。至此,用于数据驱动闭环的技术基本设施叙述完毕。在此基础上,我们论述了如何基于这些技术设施,利用大量数据从算法开发和测试验证两个方面驱动AEB产品完成工程化落地。虽然 AEB 功能实际对量产开发并不需要把所有上述过方法论严格实施。但是这个方法论是迈向更高阶功能的基础。我们以 Level 2.5 和 Level 4 为例阐明该方法论的进一步应用。
最后,我们分析了什么是自动驾驶的核心技术:“算法能力”和“工程化能力”缺一不可。目前自动驾驶技术在实际应用中在这两方面都遇到了很大程度的困难,于是采取了很多手段规避这些困难,从而衍生出各种弱化版本的自动驾驶场景。本章对这些场景在算法能力和工程化难度两个纬度做了分析和比较。一方面可以了解产业图景背后的技术原因,一方面也可以直观的理解建立工程化能力的难度及重要性。
本文为个人产品与研发经验的总结,不代表任何企业或组织的观点,仅仅分享出来供行业同仁参考。受个人水平与视野限制,文中难免有疏漏谬误之处,欢迎业内同仁指正,共同探讨。
2本文的读者
本文的目标读者为从事自动驾驶系统研发的相关人员,包括产品经理、系统工程师、架构师 、算法工程师、软件工程师、数据工程师、测试经理、项目经理等角色。本文的重点不在自动驾驶的算法,而在于如何实现工程化落地。对于自动驾驶领域的投资人,本文也有参考意义,方便投资人理解和评估自动驾驶企业的落地能力。
为了让更多人能理解工程化的方法论,本文尽量避免采用过于专业的术语,用到的术语也会在首次出现时定义它在本文中的含义,以避免歧义而影响理解。本文也不会叙述具体算法的细节原理和实现方式,因此对于行业内的大部分人,投入一定的专注力,应该都可以理解本文的主旨。
3版权声明
本文作者为萧猛。本文的电子版本允许任何不以盈利为目的的使用、复制和再分发。要求在分发过程中保留此版权声明的全文。否则视为对本文著作权的侵犯,将会承担相应的法律责任。以盈利为目的的使用请与本人联系。
4感谢
本文写作过程中曾与很多业内人士进行沟通交流。感谢东风技术中心数字化部林斯团总工,多次讨论中给了我很多启发与帮助;感谢真点科技 CTO 袁宏先生在 NRTK 定位算法方面的解惑以及关于自动驾驶路权方面的指导。也感谢许多领导和同事在本文写作过程中给予的帮助和支持。
5第1章 闭环概念及研发闭环
我们每天都在跟闭环打交道,你的手指点击手机屏幕,手机系统将你选择的内容显示出来给你,这是一个交互闭环,在你使用手机的过程中,这个闭环会持续进行。算法分析你在某些短视频的停留时间,推断你的兴趣,就推送你可能喜欢的短视频,形成一个闭环。这个闭环持续运转,最终算法就会对你的兴趣点抓的死死的。
其实我们在产品设计、营销、研发等所有环节都会经常提到闭环。
产品设计研发、发布给用户、收集反馈进一步改进设计,形成闭环。
举行营销活动、发布广告、收集广告效果数据并分析,根据数据改进营销方式和广告设计、优选广告投放渠道,也形成了闭环。
深度学习算法训练过程中每一次梯度下降的迭代、损失函数计算偏离、反向传播后计算下一次梯度下降也是一个闭环。
敏捷开发中每一次两周的迭代,是一次 PDCA(plan-do-check-adjust)的闭环,每一次 PI (Program Increment) 包含了多次迭代,PI本身是一个更大范围的 PDCA闭环。
闭环概念广泛存在,我们来梳理其一般化的概念,来更好的理解和应用。
1.1 闭环的抽象概念
学术上,严谨的“闭环”概念是在控制论中出现的。较为抽象的定义是:当我们要准确控制一个系统的行为时,我们根据系统的输出来校正对它的输入,以达到较为准确的控制精度。因为系统的输出会导入到输入端的计算,形成一个不断往复的循环,称之为闭环(Closed Loop)。
 图 1控制系统
图 1控制系统
通俗的例子,我们要把鼠标移到屏幕中的某一个目标位置,我们手在移动鼠标的过程中,眼睛观察当前位置与目标位置,大脑计算两者之间的偏差,控制手中鼠标指针移动的方向和速度。移动过程的前一段会快一些,到目标位置附近再做精细调节。眼睛观察到到的新的鼠标偏离会导入到大脑中用来计算手部移动的距离。不断循环这个闭环过程,只到鼠标到达目标位置。看起来很简单,但却是一个非常通用的过程。自动驾驶的车辆控制算法、远程导弹的制导都是类似的过程。
我们从这些例子中抽象出组成闭环的几个关键概念:闭环标的、偏离定义、反馈回路。
闭环标的
每一个“闭环”都有其“标的”。“标的”可以理解为这个闭环说需要达成的目标。也就是这个闭环的作用所在。比如“控制车辆按照规划的轨迹行使”,“正确识别图像中的人”。
对与一个测试闭环,具体要测试的目标物就是这个闭环的标的。
对于一个研发过程的闭环,研发的目标就是闭环的标的。
偏离定义
每一个闭环都有一个从输入到输出的正向路径,输出结果与期望达到的结果直接有一个偏离,这个偏离需要能够被明确的定义。闭环多次迭代的目的就是要缩小这个偏离。
 图 2 闭环的属性
图 2 闭环的属性
反馈回路
反馈回路是根据正向路径的输出来修正输入的机制。
概念的抽象
熟悉控制理论和深度学习算法的人对这些概念会非常熟悉,比如在深度学习算法里关于这这些概念会被称作“损失函数”、“反向传播”之类的术语。本文的目的不是讲述具体的算法原理,而是自动驾驶系统研发的工程化。这个工程化的过程是由一系列闭环组成的。
这些闭环有的是某一个具体技术研发的过程,有的是测试的方式,有的是具体某个算法执行时的原理。但只要是某个特定过程形成了一个闭环,就都可以归纳出上述抽象概念,也能演绎出抽象概念在具体上下文语境中的具体体现。
1.2 研发闭环
如前文所述,“闭环”是一个很通用的概念,可以出现在很多领域,尤其在自动驾驶系统的研发和运行过程中处处可见。为了更准确的描述本文的话题,我们先澄清容易误解的概念。这里先区分“研发闭环”(Develop Closed Loop)与“运行时闭环”(Runtime Closed Loop)。
1.2.1 研发闭环与运行时闭环
我们用一个具体的例子来说明。
自动驾驶功能中比较基础的功能是“车道居中”,即在有车道线的情况下,保持车辆沿车道中心线行使。这个功能的关键技术是两项:车道线识别的视觉感知算法和横向车辆控制算法。
 图 3 车道保持功能示意
图 3 车道保持功能示意
其“运行时闭环”就是:车辆行使过程中,摄像头采集前方道路图像,识别出车道线并转换成合适的坐标系,估算当前车辆在车道中的位置,控制算法接收车道线信息、车辆位置信息、车辆自身的速度、方向等信息,控制方向盘的角度或扭矩。整个闭环周而复始的运转,保持车辆居中。
这个运行时闭环的标的是“保持车辆居中”,闭环的偏离定义为车辆方向与车道中线方向的偏离,反馈回路是根据偏离计算出的横向控制指令再控制车辆状态发生变化。
而“研发闭环”是开发这个“运行时闭环”的研发、测试和集成过程。我们可以为上述运行时闭环设计两个独立的研发闭环,一个用于开发和测试感知算法,从视觉图像中计算车道线,并根据通过其它手段获(如仿真系统)得的车道线真值验证计算是否正确,这个研发闭环反复迭代,持续改进算法;另一个研发闭环之间获取车道线的真值,只是开发和测试横向控制算法。这两个研发闭环可以独立进行,最后集成在一起。
原型系统 vs 量产开发
如果只是要做一个原型系统,其实并不复杂。可以使用一个200万像素的前视摄像头(内置ISP)并做好相机内外参的标定,一台工控机(x86带 GPU), 一台带线控的车辆。车道线识别的卷积神经网络有很多论文和开源算法可供参考,单纯的横向控制做到 Demo 级别也相对比较容易。
但是如果是需要一个能安装到上万台车辆上的量产系统,事情就不那么简单了,可以想到的难点至少有:
摄像头的ISP性能在不同环境下都能输出较好的画质
车道线识别算法的准确度,尤其是在车道线不清晰、雨雪天气下
车道线识别算法对车道弯曲程度的识别是否准确
横向控制算法在不同车速情况下的稳定性
横向控制算法在不同弯道情况下的稳定性
从获取图像到控制指令被执行的延迟是否足够小,并且足够稳定
当整套系统移植到车载嵌入式平台后还有其它的工程难题:
要选择合适的能够执行深度学习算法的嵌入式处理器
深度学习的算法模型转换到目标嵌入式处理器,会不会缺失算子,会不会有精度损失,会不会执行延迟过长
深度学习算法要对特定的嵌入式平台做优化,是否需要减支,能否定点化,如何充分利用内存带宽,如何提高 Cache 命中率等等
支持视觉算法运行的软件架构如何设计,不同模块之间如何通讯
视觉算法运行的OS往往是个软实时系统,车辆控制算法往往运行在OS硬实时系统上,视觉算法极端情况下丢帧,控制算法如何容错
ECU 跟整车系统的电源管理、网络管理系统、诊断系统的对接
ECU 的更新升级,包括调试模式、工厂模式、OTA模式等等
这还没有算上硬件设计和测试的复杂性,硬件上还要考虑散热、抗震、电磁兼容性、耐久性等一系列问题。所以实现一套能量产的系统远比开发一个原型系统要复杂得多。开发原型系统只需要几个主要的工程师把算法跑通,就可以控制车辆在道路上进行演示。但这距离工程化量产还差得很远。
原型系统可以暂时忽略上述各种难点问题,在一个非常理想的工况上直接展示核心功能。原型系统的研发可以只使用一个大的涵盖所有环节的研发闭环,内置 ISP的摄像头,工控机上运行视觉算法可控制算法,最理想的道路环境,直接在车上进行调试。
研发闭环的拆解
但是对于工程化的量产开发,不可能把上述所有难点都在一个研发闭环内解决。而且不同的难点之间跨越的技术领域差距非常大。都是深度学习算法相关,但是用英伟达的GPU做算法训练跟在特定嵌入式平台做算法移植和优化,几乎是两个完全不同的专业。
所以在研发时需要把上述各自技术难点拆分在不同的研发闭环中进行。让每一项关键技术点能分别在一个研发闭环中进行独立的开发和优化。每个研发闭环的标的关注于尽可能少的技术点。
每个研发闭环独立演进、测试。最后集成在一起,构成完整的系统。一旦在整个系统运行中出现的问题,要能回溯到该问题所在的独立闭环中去复现、解决、再测试。然后再进行集成后的验证。这就是工程化。
工程化是对复杂系统按照合理逻辑进行分解,分解到合适规模的团队能够进行规范化分析、设计和研发,最后还能集成为完整系统的过程。最后体现出来,其重要特征是过程可重复、结果可预期、问题可追溯,流程自动化。
这边文章重点在是研发过程的工程化,所以是以研发闭环为基点进行讨论,每个研发闭环的标的往往是整体自动驾驶运行时闭环的某一个环节。还有可能某一个研发闭环,在运行时可能是开环 (Open Loop) 。
1.2.2 最少变量原理
你可能看到过这么一个故事: 在一个大工厂,有一台大机器,突然有一天出了问题,停工不能生产了,请了好多修理工都未能修好,老板最后找到了最有名的机械师,他这边敲敲,那边敲敲,最后确定了一个位置,选准了一个角度,敲了一锤子,机器正常运转起来。然后开价“要一万元”。理由是:“抡一锤子只值一元,但在那里敲,什么角度,用多大力就值9999元,这就是技术的价值。”
且不论故事的真假,这个故事说明了一个现象,人们遇到问题的时候,希望能有一个技术牛人一锤子下去就解决问题,哪怕要为此付出一定代价。
我也遇到过很多次,自动驾驶的研发团队的二十多个人围着一辆车,不同技术部门、不同工种的人轮番上去,你试试、我试试,就是解决不了问题。团队的Leader 肯定也跟前文故事中的老板一样,希望能有这么一个牛人,上去就能指出来问题在哪里,应该如何整改。
但是故事之所以是故事,正因为它只是一个美好的愿望。
相比与这个故事,我更青睐另一个事实。A、B两地的电话线路断了,维修人员先到A、B的中点C,检测AC和BC是否能通电话。如果AC通畅而BC不通,则继续到BC的中点完成类似的检测。我们清楚的知道,无论AB距离多长,这个方法都能让我们以对数函数的形式快速收敛到故障点附近。
第二个故事完美的符合了工程化的特征:过程可重复、结果可预期、问题可追溯。我们知道一定能在某个有限时间内发现问题并解决问题。很多时候发现问题比解决问题难得多。而第一个故事更多是看运气了,能否有这么一个牛人、这个牛人能花多长时间解决问题,这次解决了,下一次能否解决,完全都是不可预期的。
事实上,当一个闭环系统中的可变因素超过达到两个及以上的时候,你就很难确定是哪个可变因素导致的问题。
当我们分析一个可变量时,我们应该尽可能隔离其它可变量的影响。所以拆解研发闭环时,我们希望每一个小闭环针对的只是整体问题域的一个单一可变量。就像故事二中,我们测试AC段时,不会受到BC段的影响。这往往就要求我们能够对其他可变量进行准确的控制甚至隔离,体现在具体应用中就是提供其它可变量的数据模拟(Mock)。自动驾驶研发中往往把这个称为各种形式的在环仿真。
1.2.3 研发闭环之间的组成关系
一般我们对自动驾驶数据闭环的理解就是:驾驶专业采集车或者通过量产车辆采集数据,用来改进各种算法、发现并解决驾驶场景中出现的各种问题,改进自动驾驶系统,形成自动驾驶能力的闭环迭代。
这个理解本身并没有问题,但是这么复杂的系统,如果没有一个合适的层级分解,直接就整个复杂系统的进行讨论,那就是在讨论一个玄学问题,而不是一个工程问题。
一个大的研发闭环是由一系列相互关联的小闭环组成特定。有的是层级关系,大闭环内有小闭环,
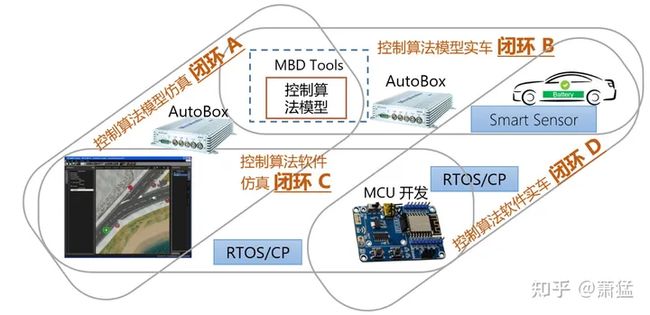 图 4 车辆控制算法开发闭环演进
图 4 车辆控制算法开发闭环演进
不同小闭环之间还有相互衔接的形式。我们来看具体的例子。
上图演示了车辆控制算法开发时4个可能的闭环(A,B,C,D)。
一般车辆控制算法做原型开发时会直接使用“闭环B”,在这个闭环中,控制算法是使用Model Based Development 模式开发,常用的是使用MATLAB+Simulink构建算法模型,模型生成的C代码会编译运行在一个快速原型设备(如:dSpace AutoBox),快速原型设备与车辆总线相连,通过车辆线控系统控制车辆运行。
旁注:关于Model Based Development
这是一种低代码的开发方式。MATLAB 是数学分析软件,基本上对数学计算有密集需求的专业(如应用数学、自动控制等),从大学开始就是使用MATLAB内置的简便的脚本语言进行数学计算和显示。Simulink 作为 MATLAB的插件存在,提供可视化的编程环境。内置了各种现成的函数实现,使用者只需要将这些模块可视化的装配起来就可以实现自己的算法思想。基本上控制算法工程师从学校学习到实际工作都是这样进行的。这样他们可以专注于将控制理论应用到实际场景,而不必花太多时间在 C 语言编程上。大多数精通C语言的车载嵌入式工程师,解决的是怎么跟操作系统、跟车辆控制器硬件打交道,对控制理论并不熟悉。毕竟每个领域都不简单,不是每个人都有足够的精力掌握跨领域的知识。使用 MATLAB + Simulink ,就可以把控制算法工程师的建立的可视化算法(控制模型)自动转换成高质量的 C代码。这样就弥补了两个领域的鸿沟,让两个领域的专家可以专注自己擅长的工作。Simulink 的可视化开发,本质上跟儿童编程语言 Scratch 的工作模式没啥区别,只不过提供了更专业的函数库和更丰富灵活的表达方式。如果有好事者,完全也可以为 Scratch 编写一个C代码生成器。
旁注:关于快速原型设备
使用 MATLAB + Simulink 编写的可视化模型最终是要转换为 C 代码再编译执行的。因为自动控制系统往往都是运行在嵌入式实时计算平台,所以这些 C 代码需要运行在一个 RTOS 系统上,通过各种现场总线与其它设备进行交互,这是嵌入式开发的领域,这就又要求学自动控制的学生也要精通嵌入式开发,精通两个领域难度就大了,毕竟时间只有这么多。快速原型设备就是想解决这个问题。这个设备内置了自定义的标准嵌入式硬件,以及配套的实时操作系统。同时提供将 C 代码编译并运行在这个设备上的工具链。设备定型后,其输入输出能力也就确定了。既然控制算法工程师是使用 Simulink 进行工作,那这个设备的开发商也就很贴心的将对设备输入输出进行控制的能力,设计成在Simulink 上可以进行拖拽布局的模块。控制算法工程师就在Simulink 上使用这些模块与自己的算法部分进行对接。这样只需要全程在 Simulink 上工作就能够完成实际的控制动作了。而从模型转换为 C代码,编译、部署到这个标准嵌入式硬件的过程都由设备的开放商提供的工具自动完成。模型开发者不需要关心,只需要专注自己控制领域的技术就行。量产的嵌入式设备是一般为特定项目专门设计,功能够用、性能满足的情况下,成本越低越好,更不可能去开发配套的 Simulink 模块。而快速原型设备可以堆砌很多接口,提供高性能的硬件,方便的开发工具链,目的是适用于尽可能广泛的项目,当然价格也贵。不过只需要小批量用于开发,成本就不是重要因素,方便才是最重要的。有了这样的设备就解决了开发前期的问题,节省时间,让控制算法工程师可以不依赖其他工程师的工作而快速投入前期的原型开发,所以叫快速原型设备。
但是“闭环B”是需要实际的车辆的,当车辆未就绪或者资源不够时,我们可以先采用“闭环A”,这个闭环中我们使用软件仿真工具代替车辆,仿真软件可以配置模拟车辆(ego car)的动力学参数,给出ego car 周围环境的真值出道路环境的真值。这样控制算法开发人员可以脱离车辆,先在桌面进行开发,而且感知结果使用的是真值,相当于减少了可变量。
“闭环C”与“闭环A”的差别在于去掉了快速原型设备,使用一块MCU开发板来运行控制算法模型生成的 C 代码。这可以用来验证控制算法模型转换成 C 代码后是否正确。这个MCU应该就是我们量产时打算使用的芯片,但是量产硬件的开发还需要时间,我们可以使用厂家提供的开发板来快速搭建试验环境。可能导致不正确的原因至少有:
Simulink模型转换成 C 代码时有错误,可能需要对模型进行调整
MCU性能比快速原型设备差,出现之前(闭环A)没有发现的问题
模型生成的 C 语言代码在往 RTOS 集成时出现的 Bug. 这是将来在量产开发中会出现的问题,可以提前在这个阶段发现。
“闭环D”与 “闭环C”相比,用实车替换了仿真,相当于增加了真实的车辆动力学因素进闭环。
下表这四个闭环各自的标的,同时列出每个闭环的可变量与不可变量(真值)。
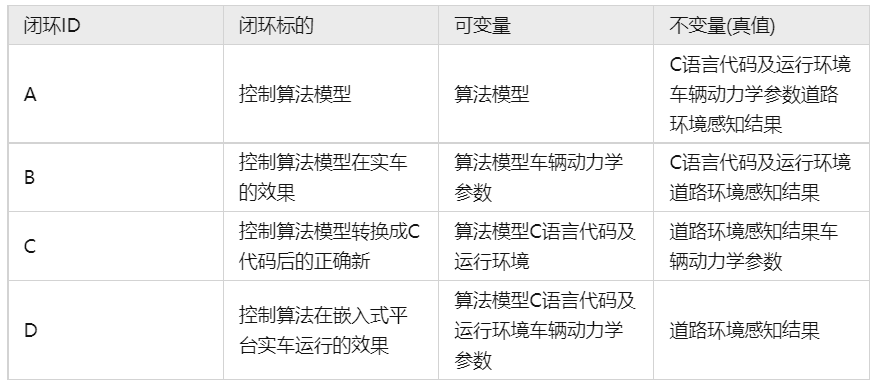
表格 1 控制算法各闭环的比较
我们可以看到, A 到 B 、A 到 C 两个过程,是分别增加一个不同的可变量(我们假设Smart Senor 给出的感知结果是可信赖的)。这两个可变量又一起出现在 D 中。
然而 闭环 D 还远不是终点,这4个关联到闭环主要是测试车辆控制算法。Smart Sensor 还需要替换成自研的感知算法,MCU开发板还要替换成量产的硬件。所以这四个关联闭环还只是更大范围闭环的一部份,需要被集成在更高一个层级的闭环中。
通过这个例子,我们可以看到一个研发闭环的几个特征。
研发闭环的独立性
每个研发闭环应该是可以独立运转的。能否独立运转也是我们在设计一个研发闭环时必须考虑的边界条件。在独立运转的前提下来我们尽量给闭环赋予最少的可变量,这样就可以专注于测试这个可变量本身的正确性。
然而为了形成闭环,某些数据或过程又是必需的。比如上面例子中的闭环A,我们需要要有一个模拟车以及车周围的环境信息。解决方法就是提供模拟数据。简单的模拟数据可以自己编造,这也是软件测试过程中的常用方法。自动驾驶系统的模拟数据比较复杂,往往需要通过仿真工具来实现。
所以,仿真工具的目的是为了给独立运转的闭环提供模拟数据(Mock Data)。不同目的的闭环,对仿真工具提供的模拟数据的要求是不一样的。比如上面的闭环A,只关心车辆动力学模型是否准确,以及车周围环境的真值数据,置于渲染的是否美观逼真,对这个闭环意义不大。
研发闭环的衔接与演进
我们在一个研发闭环中放入最少的可变量,是为了在测试这个可变量的时候隔离其它可变量的影响。但是我们的最终目标是要将所有的可变量集成到一个最大的闭环并能正常工作。
这个增加可变量的过程是逐步累积的,最好一次增加一个,每增加一个可变量,就形成一个新的闭环,正如上文例子中 “A演进到B”、“A演进到C”以及“B+C = D”的过程。这个逐步做加法的过程,相当闭环之间的衔接或者是原始闭环的演进。闭环演进的步子越小,就越容易发现问题出现在哪一步。
这个做加法的顺序反过来做减法,就恰恰是我们在出现故障时定位问题的方法。
我们能不能跳过ABC,直接到 D ,当然也是可以做到的。但是问题在于这么多可变量在一起集成,没有任何的前置验证,最终闭环D能正确运转的可能性很低。体现出来就是项目延期,不知道什么时候能完成。而且出了故障,没有测试环境可以用于隔离某个可变量进行诊断。
ABC三个闭环的存在,实际上也为闭环D提供了故障检测的技术手段。用数学的说法,ABC三个闭环的成功概率是闭环D成功的先验概率,有了这个先验概率,根据概率论的贝叶斯定律,我们是可以算出闭环D的成功概率的。
没有ABC闭环,闭环D的成功完全是靠运气了。还是那句话,我们需要的是工程上的确定性,不到万不得已不需要牛人力挽狂澜。我们要的是让一群普通人一开始就走在堂堂皇皇的王者之道上,而不是寄希望于某个多智近妖的人在混乱中“受任于败军之际,奉命于危难之间”,工程化不指望奇迹!
研发闭环的层级
研发闭环不仅有顺序的演进,还是有层级的。最大的一层闭环就是本节开头说的:驾驶专业采集车或者通过量产车辆采集数据,用来改进各种算法、发现并解决驾驶场景中出现的各种问题,改进自动驾驶系统,形成自动驾驶能力的闭环迭代。这个大闭环是由内层的多级子闭环组成的。
自动驾驶技术在工程上涉及很多完全不同的专业技术,感知算法与控制算法是完全不同的技术方向,感知算法中不同传感器的算法原理也完全不同,前融合与后融合的技术路线也是差异巨大。还有操作系统、中间件跟前面这些算法也没什么关系。
这些不同领域的技术完全可以在各自独立的闭环中进行开发和验证,最后一起装配成最大的闭环。根据各自技术领域的特点,各子闭环内部还能继续嵌套更小的闭环。单独一层的闭环甚至可以衍生出独立的产品,可以自己研发,也可以采购成熟的现有产品。
对闭环的层级分解实质上是划定出了组成完整自动驾驶系统各个子产品的可能边界。这个子产品边界的划分,可以让不同的团队并行的独立完成自己的开发活动,也可以通过采购成熟产品来加快整个系统的研发与建设。
1.3 测试与仿真的闭环
每个或大或小的独立研发闭环,也要为这个闭环主要的研发内容提供工程上可行的测试方法与测试环境。自动驾驶系统的软硬件又往往是异构平台,功能集成难度大,测试方式也比一般软件测试复杂,对测试工具的依赖也更多,会用到各种在环仿真系统。
图 5 表示出各种级别的测试已经仿真的范围和演进关系。我们从测试与仿真的层级、工具、执行者几个角度进行讨论。
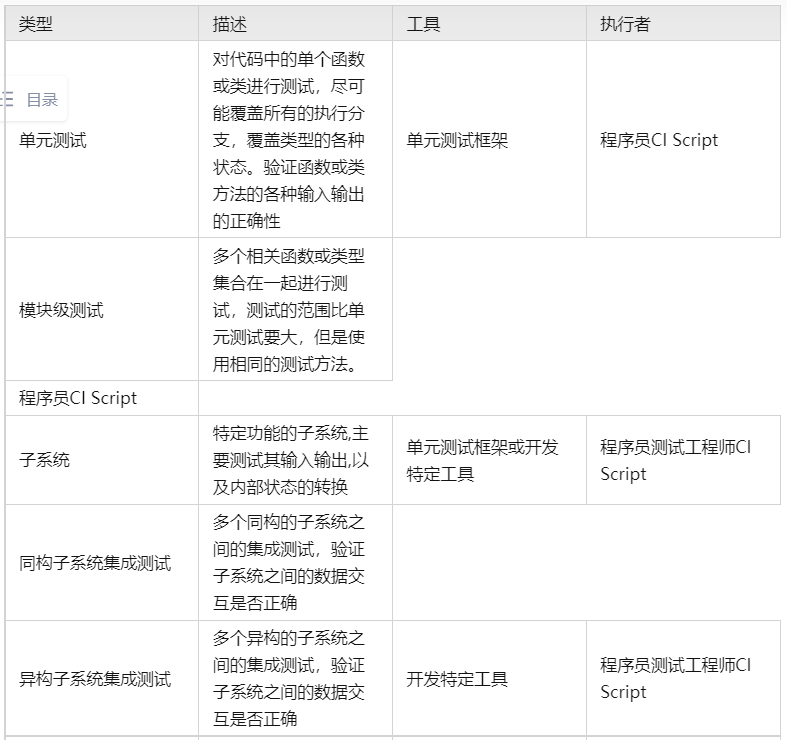
单元测试与模块测试
单元测试主要是指函数级别的测试。理论上要求每一个独立函数、或者类型的成员函数都应该有对应的单元测试代码。单元测试的重要性,怎么说都不为过。单元测试中,我们要考核代码覆盖率和分支覆盖率,要求都达到100%。也就是每一行代码,每一个可能分支都被单元测试程序执行过。
单元测试还对软件架构的合理性有重要作用,这个很少被人提及。原因就是它可以考验软件架构在函数粒度上的可测性。
不是能够为每一个函数都写出有效的测试代码的,一个函数输入的参数组合可能有几万种,就不可能全被覆盖,一个函数的执行依赖函数外部的状态(比如全局变量),同样的输入,因为外部状态可能有不同的结果,单元测试也不好写(了解一下什么是纯函数)。一个函数干了太多事情,比如有两千行,单元测试基本就没法做了。
所以当能为所有函数写出单元测试代码时,就已经强迫目标代码在函数级别设计上做了优化:函数功能尽量单一,尽量写成纯函数,一个函数代码别太长等等。
可以看一个反面例子“丰田事件 1万多全局变量建了个超大bug基地”。
函数级别的单元测试关注点是检查函数在不同输入的情况下,其输出的正确性。而且这个函数最好内部不保存状态(纯函数)。这个测试范围再大一些,多个函数(或多个代码文件)一起协同工作,在多次关联调用之间需要保存状态,一般而言,我喜欢把这个范围称为功能模块。可以把模块理解为更大粒度的函数。模块有其对外公开的调用接口,已经可被观察到的对外相应,在内部有多个不公开的子模块或函数,有内部保存的状态。
从程序语言上看,一个模块相当于 Python 的模块,Rust 的模块,Java 的 package , C++ 的一个多个类的集和,C 语言关联度比较高的一个或多个代码文件。
对模块的测试关注点是不同输入情况下,模块的响应是否正确,模块的内部状态是否正确。
单元测试和模块测试一般都可以使用特定的单元测试框架来编写,例如 gtest 用来写 C++ 的单元测试,Rust 内置有单元测试机制。同时还有各种代码检查工具来验证代码是否符合编码规范,检查代码的圈复杂度,分析潜在的代码错误。
单元测试和模块测试的编写者就是开发该功能模块的程序员本身或其小组成员。一般来说程序员每次代码提交前,关联模块的单元测试和模块测试代码都应该能执行通过。每一处代码修改,与其关联到所有模块的单元测试代码都要被重新执行。
单元测试和模块测试的模拟数据一般就写在测试代码中,看测试框架的能力,也可以从外部加载测试数据。
单元测试和模块测试很重要,不幸的是,在研发中还是经常会出现没有单元测试的情况。原因很简单,项目太紧,没时间。没有单元测试不影响代码运行,只是某些情况没有被测试而已,这样的代码合并到整个系统中,就是潜在的风险。
子系统
模块往上是子系统。一个子系统表示能够完成某个方面的功能体系,比如完成了“视频采集子系统”“车辆的识别子系统”,“泊车路径规划子系统”,“用户交互子系统”等等。存在形式可能是Linux内核中的一个驱动,应用层上的一个独立的进程或一个 SOA 服务,MCU RTOS 上一个或多个关联到 TASK,CP AUTOSAR 上的一个 SWC 等等。
与模块测试一样的是,子系统一般会有内部状态,需要检查在响应外部输入过程中,内部状态的正确性。
一个子系统应该能够单独被测试,就是它能独立的在一个测试闭环中运行并被校验。然后再做加法,即把更多的系统一个一个的逐步加入进测试闭环中,最后形成整个系统。
子系统测试跟模块测试的差别在于模块测试的访问接口一般都是 API 级别,也就是模块的 API 函数会直接被测试框架进行调用。而子系统的接口往往是与其它子系统的之间的交互,可能是通过各种网络(Can, FlexRay,以太网等等),也可以是通过共享内存、信号量等进程间通讯机制。
这决定了子系统的测试不太能跟模块测试采用同样的工具。子系统的测试不光要提供模拟数据,还要有能把模拟数据送入子系统的方法,以及检测子系统响应结果的方法。
子系统的测试一般要采购一些专用工具,同时要开发一些工具。采购的工具往往有总线模拟类(如 CanOE)。还有整体的自动化测试框架,如 ECUTest 。也有开源的替代品,如Robot Framework。自己开发的工具需要能将采购的工具连接起来,或者为特定的设备或子系统接口开发驱动。
“发布订阅”设计模式对子系统测试有重要意义。因为“发布订阅”模式解耦了消息的生产者和消费者,所以我们测试一个子系统时,就可以比较方便的模拟出该子系统需要对数据发送给它,同时也可以通过接收该子系统发出的消息来校验其行为或内部状态是否正确。
无论是自动驾驶常用中间件ROS/ROS2、百度 Cyber RT、DDS,还有SOA的基础协议SOME/IP都是支持发布订阅模式的。
同构与异构
自动驾驶系统是一个异构系统。硬件上有高实时性的MCU和高性能多功能的 SoC芯片。MCU上运行RTOS系统,SoC 上有 Linux 或 QNX 也可以运行RTOS系统。SoC上有通用CPU,有用于渲染的GPU,有用于数学计算的 DSP 和深度学习的NPU,其中每个部分的软件实现方式也是不一样的。
单元测试、模块测试甚至基于CPU的子系统都可以在x86的开发设备上进行测试。但是如果子系统涉及到嵌入式平台的专用设备,其真实效果,尤其是性能表现只能到目标嵌入式平台进行测试。一般我们称之为处理器在环(Processor in Loop)。
所以整个测试闭环以及测试工具系统,需要考虑对嵌入式平台的支持。
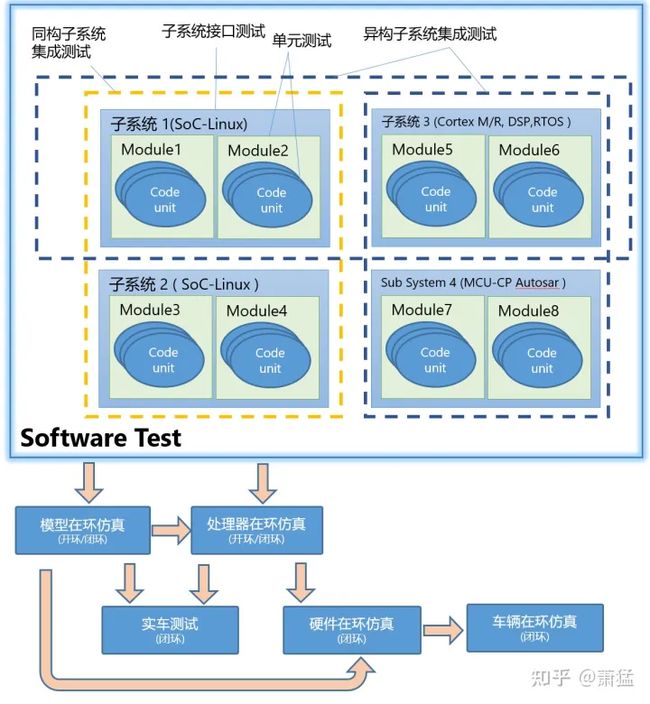 图 5 测试与仿真的类型
图 5 测试与仿真的类型
X in Loop
除了异构子系统集成测试比较特殊之外,前面讲的测试概念其实跟一般软件测试没太大区别。自动驾驶系统测试中比较特殊是各种形式的在环测试。
1.2.3节中的闭环A是典型模型在环(MiL, Model in Loop), 闭环C是属于软件在环(SiL,Software in Loop),将模型生成了软件代码进行执行。
重点是Simulink 模型直接运行在快速原型设备里,仿真软件直接给出传感器的真值数据。也就是说就是仿真软件渲染了场景动画,也是给人看的,实际的真值直接发送给模型作为输入,当然真值数据怎么从仿真软件到模型需要工程师写代码来集成。
前文异构子系统集成测试就是一种处理器在环测试(PiL,Processor in Loop)。异构子系统的集成是可以将多个子系统逐步集成进来的。如果把视觉算法也运行在目标嵌入式平台处理器上,视觉数据从仿真软件中提取出来通过网络发送到嵌入式平台,那就是 PiL 和 MiL 的混合模式。这时候仿真软件渲染的图像是有用的,运行在嵌入式平台的视觉算法根据图像识别出目标发送给Simulink模型。比纯粹的 MiL ,这一部集成了更多内容进仿真闭环中。
标准的硬件在环(HiL,Hardware in Loop) 是要用正式量产的ECU硬件,而且数据与 ECU 硬件交互的方式都应该与实际在车上是一样。虽然车辆周围的环境是通过仿真模拟出来的,但从ECU本身的视角,几乎是分不出自己是在仿真测试环境还是在真实车上。这样整个测试的环境就与真实车辆更接近了了。
在PiL测试中,如果需要使用原始的图像数据,一般图像数据是通过对视频文件的回放,并通过网络发送到目标嵌入式平台(ECU),而 HiL 则是直接通过物理设备将仿真出来的图像转成原始图像格式注入到 ECU 的视频采集端口,只是通过仿真跳过了传感器模数转换和ISP 处理的过程。这样ECU的采集模块也备集成到测试闭环中了。当然,完成这个视频数据从仿真软件到ECU视频端口,需要专门的硬件设备,这就是HiL台架的作用了。
车辆在环仿真(ViL, Vehicle in Loop) 实际上跟 HiL 很接近,但是全套HiL设备要能小型化后装到车上,控制算法的执行不是基于仿真软件的动力学模型,而是实际物理车辆的控制系统。仿真软件把模拟的场景注入到ECU,相当于物理汽车认为自己在某个道路场景中驾驶,ViL 跟HiL 的差别在于使用了真实的车辆控制系统。
表格 2 列出了各种测试和仿真的定义和说明。

表格 2 各种测试与仿真类型的比较
6第2章 产品级闭环
上一章讲的是研发闭环,偏重与研发与测试仿真的协同。这一章我们从产品的角度来讨论。
自动驾驶系统是复杂度非常高的系统,从产品角度看,它复杂到没有一个传统意义上的产品经理能把待开发的系统准确定义清楚。我遇到过有的公司想招自动驾驶产品经理,招了两年,产品部门走马灯似的换人,也不知道自己到底想要什么样的人。还有的JD上对产品经理的要求几乎是十项全能,像极了上海人民广场大妈手上的征婚条件,既要又要。
为什么自动驾驶领域的产品这么难定义?因为他不是一个单一产品,它是一个高度复合的产品,本身就是由一系列软硬件子产品组合而成,同时它又被装配到了“车辆”这个更复杂的产品中。然后这个车辆会在无限可能的交通场景中行驶。也就是说自动驾驶产品是多重复杂性的叠加,至少包括内部组成的复杂性,装配环境的复杂性,以及使用场景的复杂性。
在分析这种产品时,我们要把它分解成多个、多级子产品,对逐个子产品进行分析,然后分析各子产品如何构成完整的系统。每个子产品有其特定的关注点、技术领域,有其自己独立的演进方向,在整个系统中,某个子产品可能有多个可替代的选项。
在我另一篇文章《智能驾驶域控制器的软件架构及实现》(下) 中,我画了两张与产品分解相关的图。“图 6 软件架构鸟瞰图”讲述的是自动驾驶域控制器内部的软件构成,三个维度的分析和每一层的作用请看原文。这篇文章据此来分析内部子产品的分解。“图 7 四级产品架构”在图 6的基础上,向外延伸到自动驾驶工具链体系,向内以与自动驾驶的相关性再做了三级的层次化分解。本文中我们会更关注其中的工具链体系。
 图 6 软件架构鸟瞰图
图 6 软件架构鸟瞰图 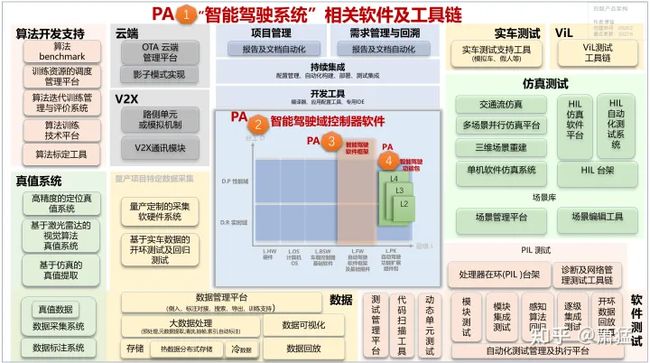 图 7 四级产品架构
图 7 四级产品架构
2.1 各层产品的独特性
图 6 中横向“层级”这个维度,每一层的每一个域(性能域或实时域)都有其独特性,要解决的问题、涉及的技术领域、需要的专业技能、开发与测试的方式,差别非常大。
“产品”的概念
我们需要对“产品”的概念有一个定义。一般我们理解的“产品”是从终端用户角度去看到,比如一个咖啡机、一个手机、一台车,软件产品比如浏览器,音乐播放器、微信APP 等等。
我们把产品的概念抽象一下,如图 8所示,“产品”具有一系列“特性”,并提供“交互接口”给它的“用户”。
我们把“车”当成一个产品,它的特性就是“百公里加速时间、语音控制大屏、代客泊车功能、自动变道功能”等等,它提供了“方向盘、仪表盘、刹车、油门”等交互接口给任何具有驾驶能力的用户。
我们把“嵌入式Linux”作为一个产品,它的特性就是“启动时间、进程调度、内存管理和各种外设的支持能力、信息安全、通讯能力”等等,它提供符合POSIX 标准的API,还通过定制的内核驱动提供新设备的API访问接口,Linux 应用开发者可以基于这些API实现自己想要的应用功能。
这两个例子涉及的领域差距非常大,但它们都是产品。
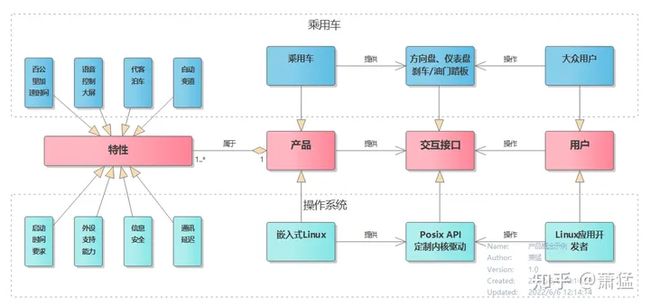 图 8 产品概念示例
图 8 产品概念示例
如图 9所示,产品的交互接口、特性、特定的技术领域都是产品的内涵,它决定了产品的能力以及对外的交互方式。但产品还有其外延概念。
 图 9 产品概念的内涵与外延
图 9 产品概念的内涵与外延
产品的外延至少包括了其市场定位、适用场合等,同时一个产品还需要有一定的独立性。所谓独立性是指它的设计、研发和销售是可以独立与其它产品进行的。比如说,我们可以独立的销售一张桌子,但是我们没办法只卖一支桌子腿。
产品的内涵与外延也是密切相关的,比如产品的独立性就与其对外的交互接口密切相关。
产品的独立性
自动驾驶系统内部的子产品构成这么复杂,引申出来其内部各子产品的独立性非常重要。各子产品相对独立就可以分到不同团队进行开发,某些子产品就可以直接从市场上采购成熟的产品,就可以使用不同供应商的产品进行替代。
汽车OEM的供应链管理最喜欢的事情就是同一个零部件有多家供应商。避免单一供应商无法供货时生产停滞,还可以在价格是有较好的谈判地位。
上汽说要掌握自己的“灵魂”,本质上也是这个产品独立性的问题。因为自动驾驶系统虽然需要域控制器硬件各种传感器硬件,但本质上任然是一个软件密集型的产品。其内部各组成部分(软件子产品)的切分就不如原先的硬件零部件那么清晰。以科技公司为主的供应商就会更倾向于软硬一体的解决方案,或者至少是在软件上提供整体的解决方案。而汽车OEM则希望软件硬件能分开,同时在软件组成上最好也能分拆成独立的子产品,这样就能在供应链上能保持更好的控制权。
产品内涵中的“特定技术领域”也能反映产品独立性的特征。图6中各层产品的技术领域差别非常大,相关研发人员的专业技能也相差很大,开发与测试的方法也有很大的差异。比如为嵌入式系统定制开发Linux的工程师技能与视觉算法的工程师差异非常大;能熟练在Linux上开发应用的工程师很少能熟练的编写 Linux 驱动;同样是算法工程师,从算法设计、算法实现、参数调优、嵌入式移植和优化,也需要很多不同技能的工程师来实现。所以这些不同的产品时需要不同技能背景的团队来各自独立的设计和开发。
当我们找一个设计用户级产品的产品经理来定义一个操作系统级的产品时,他是无法胜任的。我们让一个对操作系统非常有经验的专家去定义自动驾驶的具体功能及场景,他也需要补充很多知识,意味着要花更多时间。
2.2 纵横交叉的产品演进路线
子产品的独立性,让图6中的各层产品可以独立演进,可以交错组合成完整的客户交付产品。
横向分层产品的演进路线
图 10 中显示了每一层可能的产品演进方向。比如在“计算平台”,研发初期可以使用 x86 工控机或 Xavier 套件这样立即可得的设备开发必须的软件功能,当确定目标 SoC 平台后,可以使用该平台的原厂开发板,等基于目标平台的量产专用计算平台硬件开发完成后,再将软件系统切换过去。
对应的操作系统层,前期开发直接用 Ubuntu, 为了让开发人员环境一致,可以再用个 Docker;到了目标平台,就要用 Yocto 定制化一个适合的 Linux 系统,这也是目前大多数平台采用的方式。随着自动驾驶SoC 芯片性能越来越强,核心数越来越多,相应的虚拟化技术和容器技术也会被使用,相应的研究和开发可以先开始做,然后用于将来的产品。
 图 10 横向分层产品演进路线
图 10 横向分层产品演进路线
中间件这一层,一般习惯于先基于 ROS或 ROS2开发原型系统,再转向可以用于量产的中间件,如 Adaptive AUTOSAR 或百度 CyberRT 等。
纵向产品组合路径
图 10中的每一层从左到右是单层的某个产品的演进路线。但是任何单独一层的产品是无法构成完整的自动驾驶系统的。我们不可能等到某一层的产品成熟了再去做整体的集成。相反,我们希望全系统集成的时间越早越好。
图 11 演示了多种可能的全系统集成路线,从上自下的每一条贯穿路线,都是一个可能的产品集成组合。
路径 ① 和 ② 正好对应与1.2.3节的“闭环 A”和“闭环 B”。
路径 ③ 是一个研发前期的原型系统仿真,中间件、操作系统、计算平台都是使用现成的产品,重点放在相关算法的研发。自动驾驶创业企业早期用于融资的多半就是这样的系统。
路径 ④ ⑥ 是一个典型的硬件在环仿真系统,从硬件到操作系统、中间件都已经是使用产品化的解决方案。
路径 ⑤ ⑧ ⑨ 都是量产交付的产品,因为最终的目标产品不一样,所以各层使用的子产品也不同。路径 ⑦ 是车辆在环仿真系统。
根据需要,还可以设计出各种不同的集成路径,每一条路径实际是也行程了一个独立的产品研发闭环。我们一般从最简单的路径开始,逐渐增加可变量,达到量产交付的最终产品形态。
 图 11 纵向产品组合路径
图 11 纵向产品组合路径
产品规划的闭环思路
横向的分层是由各层产品的相对独立性决定的,纵向组合是构成完整系统的必然要求。一般来说,企业在做产品规划时会更关注最终形态产品,而对中间各层的子产品的规划重视不够,毕竟最终产品是要做商业交付的。
这样就会在事到临头发现没有合适的中间子产品,或者子产品功能不满足交付要求,需要重新选型并适配,或者还需要较多的研发时间以致延误项目进度。所以企业的在产品规划时,要充分重视个层子产品的规划,要用横向和纵向两个视角进行综合考虑。
横向视角代表这个子产品自身的发展,要遵从由该产品技术特性决定的客观规律,不能主观上拔苗助长;要跟随技术的发展趋势保持先进性;要有合适的产品经理和架构师,建设合适的团队;要能建立能独立的开发测试闭环,使得该子产品的研发过程不依赖其它子产品,可以独立迭代。
纵向视角会影响子产品演进过程中各步骤的功能规划和优先级设定。每一条纵向路径虽然其目的不同(有的是测试闭环,有的是最终交付闭环),都是一个完整的全流程闭环。纵向路径对中间子产品的要求首先是能保证这个纵向路径闭环能够运转。因此子产品的横向发展步骤要与多个纵向路径的需求进行匹配协同。也就意味着我们在规划某个子产品的路线图时,要同步要把纵向集成的因素考虑进去。
如果某个子产品不成熟,或者还没能达到量产要求,为了纵向路径能走通,我们要寻求前期的替代品。虽然这个阶段的子产品不能用于量产,但是它很好的支持了其上层产品的开发。于此同时,抓紧进行该层子产品的开发来了来了,为下一步替代临时方案做准备。
横纵两个方向的拆解和组合,是为了能让每一层的子产品都能有独立进行设计和开发,这样也就让所有层的都能够并行进行开发,然后再通过纵向的路径逐步集成。所以设计良好的产品规划,包括子产品规划,能够让整个工程化落地的过程少走弯路。
7第3章 数据驱动的闭环
随着高阶自动驾驶逐步进入现实,数据闭环的概念越来越受到重视,很多自动驾驶研发公司和 OEM 都想建立自己的数据闭环体系。但是究竟要达到一个什么样的状态才叫数据闭环,数据闭环如何设计、如何实施又往往很难有一个明确的说法。
这里有一个关键点概念很容易被人忽视,“产品规划的闭环、研发和测试的闭环才是自动驾驶研发工程化的内在需求,而数据是驱动这个闭环运转的技术要素”。
前面两章讨论了研发测试的闭环与产品规划的闭环,核心思想是尽量从小的闭环开始,逐步叠加到完整的系统闭环,以从简单的到复杂逐步递进的方式构建大型系统,这是工程化的方式。这是从产品和研发的视角看待闭环系统。然而不管是大的闭环还是小的闭环,都是需要通过数据对其进行驱动,小闭环叠加成大闭环的过程,也是多样化的数据逐步进入系统并协同驱动大系统工作的过程,所以本章从数据的视角来讨论闭环系统。数据闭环的正确说法应该是数据驱动的闭环,
直接讨论整体的数据闭环很难说清楚,我们依然从小闭环开始讨论如何进行数据驱动。不同类型的闭环,由于其闭环标的不同,其中流转的数据也有非常大的不同。要分析清楚一个数据驱动的闭环,需要搞清楚以下问题:
数据闭环语境下的数据到底是什么(数据的概念)
在闭环中需要什么数据,数据的作用是什么
数据如何生产
数据在使用前如何被加工
感知类数据,如何获取真值(Ground Truth)
数据如何在闭环中流转,需要哪些工具来支持数据的流转
这一章先分析基础的“数据概念模型”,然后再通过几个典型的案例来分析其数据如何驱动闭环的执行。
3.1 数据概念模型
既然讨论数据驱动的闭环,那我们先把“数据”的概念搞清楚。本文说讲的“数据”是指与自动驾驶系统的研发与运行相关的信息元素,图 12展示了数据的抽象概念模型。理解了这个概念模型,就能更容易理解数据是如何被生产、加工和使用的。
此图的符号语义是基于 UML 类图,基本的符号语义请参照我在《中间件与 SOA》3.1.1节中的简单描述。图中淡蓝色框内的是数据概念模型,外围是具体的数据类别和关联的工具平台。
我们可以从很多方面去描述一个数据的属性,对于自动驾驶系统中的数据,我们可以关注分类、语义层级、生产方式、使用方式(图中从“数据”引出去的四个概念)。从另一个角度看,这几个关注点描述了数据“是什么,从哪来,到哪去”三个问题。
关于分类,数据可以有很多种不同的分类方式,比如按照跟自车的关系,分为自车数据或环境数据;按数据的物理采样方式分为图像数据、雷达信号等等,采用什么分类方式并没有固定的标准,是根据实际对数据利用的上下文来选择。
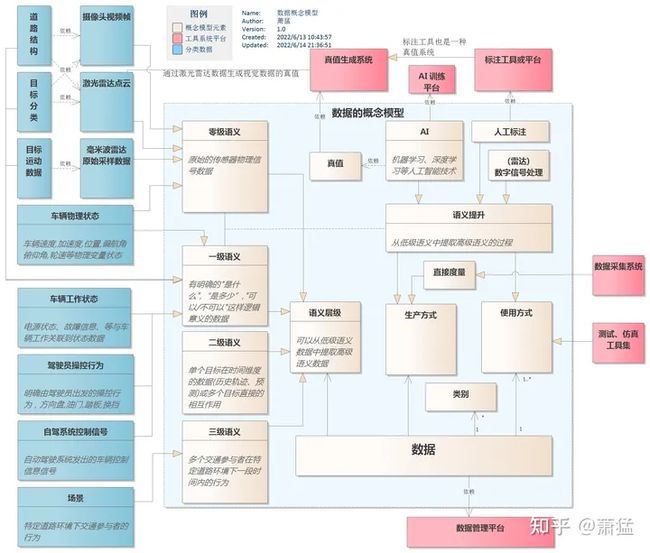 图 12 数据的概念模型
图 12 数据的概念模型
图中淡蓝色框内的是数据概念模型,外围左侧列举了一些具体的数据形式,其它红色是关联的工具平台。左侧具体的数据形式只画出了语义层级,但是每种数据都会有概念模型中语义提升、生产方式、使用方式等概念的具体体现。图中限于布局不容易表示,后文中都会详细说明。
这里我们先重点说明“语义层级”概念,它对于自动驾驶系统的数据是非常核心的属性,很多数据处理动作实际上就是在提升数据的语义层级。
语义层级
“语义”是我们从某个信息媒介中所提取的高阶信息含义。比如一张报纸,其物理层面是纸张上分布着油墨,人读报纸,能从油墨的分布中其中的的含义,这就是语义提取。NLP(自然语言理解)可以认为是计算机自动从文字中提取语义。
语义是有层级的,语义层级并没有标准化的定义,本文根据实践经验给出自己的定义。
“零级语义”就是没有语义的原始物理信号。如摄像头的原始像素点集合,激光雷达的点云,雷达收到的电磁信号经过采样之后的原始数据。
“一级语义”级是根据原始物理信号计算出来的属性特征,有明确的“是什么、有多少、可以/不可以”等含义。比如带计量单位或物理量纲的速度、距离、位置等;车辆、行人、车道线等目标分类;交通标志的限行、限速、禁止掉头,可行驶区域分割等。
“二级语义”是在一级语义上的进一步加工,有一下几种可能情况
两个2级语义的组合,如车在某个车道,两个传感器的后融合。
时空两个维度同时具备,如历史轨迹,目标跟踪。
“三级语义” 对目标意图的识别与判断,如当前行为意图,行为预测,轨迹预测
“四级语义”多个交通参与者在特定道路环境下一段时间内的行为
举例来说,摄像头输出的一帧图像,如下图:
 图 13 非法掉头的示例场景
图 13 非法掉头的示例场景
图像本身实质上是 YUV 或 RGB 格式保存的一段二进制数据,记录里每一个像素点的光学采样值。这是没有任何语义信息的,是零级语义。
通过人眼识别或者 AI 算法识别,我们从这一帧图像中提取出一辆乘用车、车道双黄线、还有“禁止掉头”的交通标志,这是几个独立的一级语义,互相之间没有关联起来。
根据车辆和车道线的相对位置,我们可以车辆压线,这是两个一级语义的组合。可以认为是二级语义。继续叠加双黄线的交通规则信息,可以认为车辆已经非法压线了;再叠加禁止掉头的语义,可以认为这是非法掉头。
假如对向车道有一辆车正在向图上的白车行驶过来,我们能测出其速度。那我们还能作出预测,这两辆车可能会相撞。这已经不是多个独立的一级语义叠加了,而是多个目标可能的关联分析,这可以认为是三级语义了。
图 12中并没有画三级之上的高层语义,本文也不打算去定义更高层的语义,第三级语义的定义也值得商榷。因为语义分层的目的体现在工程上是给不同算法的能力划定边界,分层的方式也确定的各层算法独立进行闭环测试的闭环分解方法。比如,我可以单独为某个零级提升到一级语义的算法设计测试闭环,同时还可以直接提供一级的真值给另一个算法,它负责提取出二级语义。所以你完全可以根据你的算法集和的规划去定义自己的语义分级规则。语义分层是为了可以进行工程化的闭环测试。
语义提升
前面例子中从低级语义逐步提取到高级语义的过程就是语义提升。(图 12中零级语义和一级语义中有一根线连接到“语义提升”,这在UML语义中表示关联类,就是说“语义提升”是跟两个高低语义层级相关)。人眼在看图 13 时这个语义提升的过程是瞬间完成,人也不会意识到会有这个逐级提升的过程。但是在计算机来执行语义提升的时候,确实不同的类型的数据,不同层级的提升方法都有很大的差别。
图 12中画出来三种语义提升的方式,人工智能(AI) ,人工标注,数字信号处理,还可以有更多的语义提升方式。这三个是比较具有典型性,数字信号处理主要是在对雷达原始数据的处理上,已经发展了很多年,图像和激光雷达点云采用深度学习等人工智能技术成为了主流。“人工标注”实际上就是一种语义提升的方式,它一样可以用在不同的语义层级之间。
“语义提升”对于低级语义来说是数据的使用方式,对于高级语义来说,是数据的生产方式。最直接的数据生产方式就是“数据采集”,直接采集原始数据。
真值系统
目前感知层面的深度学习主要是以监督学习为主,监督学习就需要数据的真值来进行训练。不同类型的数据,不同类型的算法训练,其真值形式也有很大差别。产生真值的系统称为“真值系统”。我们在设计生产用于 AI 训练数据的同时,也必须设计获取其真值系统。
真值系统至少有三种:
人工标注
用更高精度的测量工具的结果作为低精度工具的真值
仿真软件直接输出真值
第1种就是靠人力去标注,比如百度就建设有上万人的标注基地,为很多自动驾驶公司提供标注服务。第2种,比如我们可以用激光雷达算法输出的结果作为视觉算法的真值,前提是激光雷达算法的精度足够。仿真软件的真值是可以直接输出的,这在我们设计测试闭环的时候非常有用,可以让我们在算法成熟之前就建立起算法或其它软件模块的测试闭环。
为数据生产服务的工具平台
各级语义数据的生产,算法的开发,离不开一系列的工具平台的支持。清楚了数据的抽象概念模型,也就能更清楚的理解工具平台的作用。相关的工具平台如图 12所示:
数据采集系统要支持各种传感器数据车身数据的实施采集,支持每天10T 级别的数据采集量,还要保证各种数据的时钟同步。
数据标注需要标注工具与平台,提供各种类型的数据标注功能、支持标注质检,支持成千上万人分布式工作、对任务和人员进行调度管理。
要为各种不同类型的数据,提供符合算法要求的真值系统。
AI 训练平台要能支持成百上千的计算卡进行分布式训练。
测试仿真平台要能利用各种语义层级的数据形成多样化的测试闭环。
需要一个统一的数据管理平台对数据从导入、存储、清洗、加工、筛选、利用进行全生命周期的管理。
这些相关的工具平台也会在后文的合适章节单独进行论述。
3.2 假设的系统方案
AEB (Autonomous Emergency Braking)是典型的 L1功能,就是自动紧急制动,避免撞上前方的车辆、行人或其他障碍物,或者至少降低速度后,减少撞击之后的伤害。当然这只是非常简单的描述,详细的功能描述可以写出500页出来,这里不多说。
我们假设一个能支持 AEB 功能的系统方案,包含简明的软硬件架构,这个方案有最足够的传感器和足够的计算能力,不过我们只关注 AEB 一个功能。但尽可能穷举出所有可以细分的工程环节,包含各独立子产品开发、分步集成、仿真测试、量产后根据回传数据持续迭代等。
这个系统方案不会出现在任何企业的实际产品中,因为方案的硬件配置只实现一个 AEB 功能从成本来说太不划算,过于细分的工程环节只用于开发一个功能太过奢侈。
这个案例的意义在于可以提供一个方法论模板,让我们先不陷入复杂的自动驾驶功能里,而是从开发单一功能的视角分析工程化过程,让功能尽量简单,以凸显工程化的脉络。在后续叠加更多的自驾功能时,其实就是在这个模板的各个环节横向增加内容,而工程化的原理还是一样的。
我们假设的AEB 功能的系统方案,关键硬件组成:
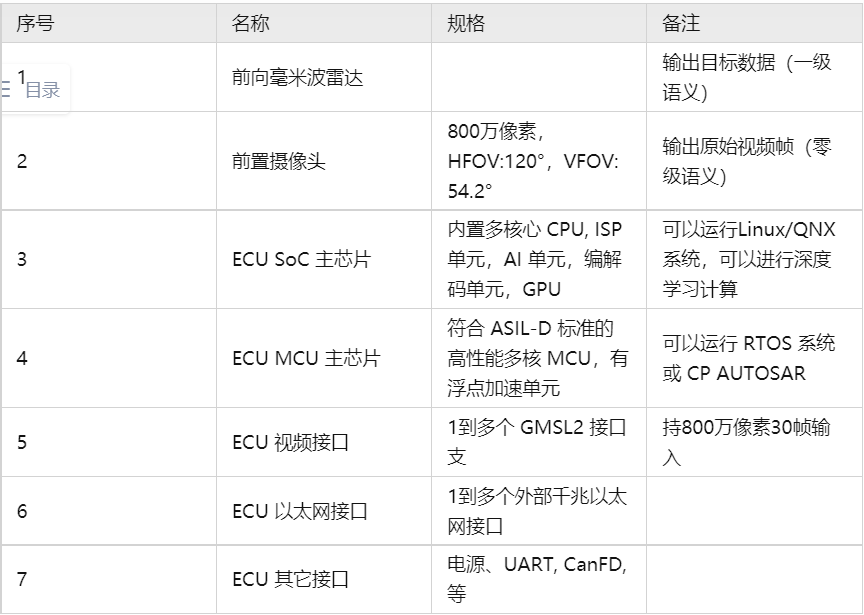
旁注:部分使用 Smart Sensor简化 HiL 实现
方案中雷达使用 Smart Senor ,直接输出检测到的目标列表。此案例先关注在视觉算法上。实际产品可以直接把雷达信号处理运行在ECU中的 MCU 上,MCU 要负责对雷达回波的物理信号进行采样。但这样在对ECU进行 HiL 测试时要模拟雷达回波,难度很大。此案例雷达用Smart Sensor 以简化后面的说明。
smart sensor 在这里指的是直接输出感知结果的器件。比如mobile eye 的摄像头,芯片算法镜头都集成在一个设备里,通过can 输出。毫米波雷达也很多是这样供货,雷达器件里面集成了芯片算法,can输出目标列表信息。L2的开发很多就是这样选传感器,还可以把ACC这些功能直接运行在雷达的CPU某个核心上。这些都算smart sensor.
L2.5往上会逐步倾向于把这些算法的执行放在集中的域控制器上。传感器就只做物理信号捕捉,就不那么smart了
然后我们还有专业采集车,专业采集车上安装一个64线的激光雷达,输出点云(零级语义)。
3.3 各层级数据语义的独立研发闭环
图 14 算法的语义层级划分,这张图中把 AEB 功能可能涉及到的各种算法按照语义层级进行划分。这是一个工程化视角,并不是一个算法实现原理的视角。这里所谓工程化视角,是指可以比较方便的把每个算法单独开发,单独测试。
比如雷达目标和摄像头目标都是一级语义数据,我们需要这两个一级语义数据做的融合算法。可以直接在仿真软件上做传感器模拟,基于仿真软件输出的一级语义进行开发。这样我们可以在雷达算法和摄像头算法都不具备的情况下,先进行融合算法的开发。
好的仿真软件,可以提供各级语义的模拟数据,可以在模拟数据上加噪音,同时还能直接提供真值。这些可以满足各层算法的前期开发需要。
所以各种算法的独立开发再逐步集成的过程,是沿着语义层级的边界进行的。下面我们梳理一下图 14中各层级的算法。每个算法我们会关注其要达到的目的、语义层级、以及数据来源、和真值数据产生的方式。这篇文章不会关注具体算法的实现原理。
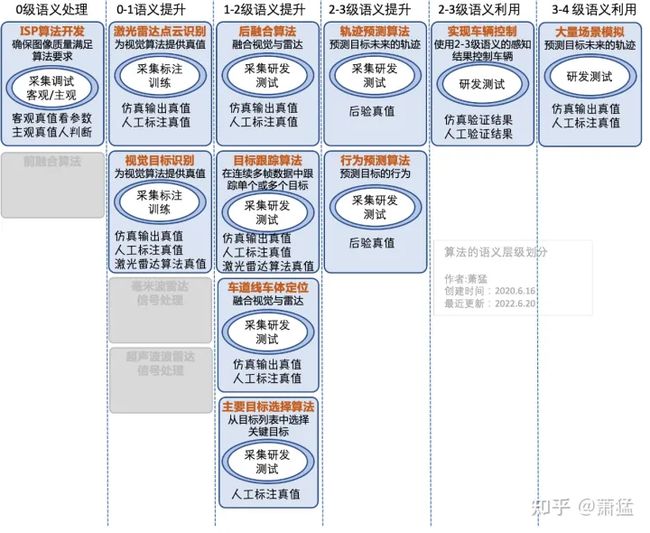 图 14 算法的语义层级划分
图 14 算法的语义层级划分
3.3.1 “0级语义处理”独立开发闭环
ISP 算法独立开发闭环
最典型的0级语义处理是 ISP(图像信号处理)算法。摄像头传感器输出的图像质量会受到环境的明暗程度、相机的对焦、曝光时长等很多方面的影响。视觉算法的效果重度依赖摄像头获取的图像质量。尤其现在自动驾驶系统安装量越来越多的摄像头,ISP算法的重要性就很突出了。
ISP 算法一般由专用芯片来执行(或者 ISP 硬件模块集成在某个SoC)中,算法根据情况还会对镜头或 Sensor进行反馈控制。常见的 ISP算法至少包含“格式转换、3A(自动白平衡,自动对焦,自动曝光)、噪点消除、宽动态(WDR)、白平衡调整、颜色校正、锐度调整”等。
旁注:关于ISP 算法能力
有三类厂商非常看中 ISP 算法能力。一类是摄像头厂商,为了便于销售往往把 ISP 芯片集成在摄像头内部,调试好图像效果后整体出售,这样客户也方便。另一类是视觉算法开发厂商,因为算法严重依赖 ISP 效果,所以他们会非常看中 ISP 的效果,要么与摄像头厂商深度合作,要么自己参与研发。第三类是用于自动驾驶的SoC 芯片厂商。因为自动驾驶系统需要很多摄像头,如果把摄像头中的 ISP 芯片放在 SoC 内部,可以大大降低摄像头的成本。SoC 芯片厂商为了让芯片有竞争力,也会开发 ISP算法。具体项目中,ISP 的能力具体由谁来提供是一个重要的待决策事项。

摄像头的畸变矫正算法、传感器的前融合算法也都属于0级语义的处理,理论上都可以采取类似的处理方式,但是具体算法还是有各自的差别。
3.3.2 “0->1语义提升”独立开发闭环
激光雷达算法独立开发闭环
激光雷达可以生成3D点云,线数越多,点云越稠密。相对摄像头和毫米波雷达,更能精确的测量物体在3D空间中的位置和形状。所以基于点云可以做一系列的感知算法,包括目标检测、分类、跟踪、语义分割、SLAM 定位等等。
本 AEB案例的系统方案主要使用视觉方案,不使用激光雷达,但是一个良好的激光雷达算法可以协助进行视觉数据的自动化标注,也就是将激光雷达算法的输出作视觉算法训练使用的真值。所以本例的专业采集车配备激光雷达。
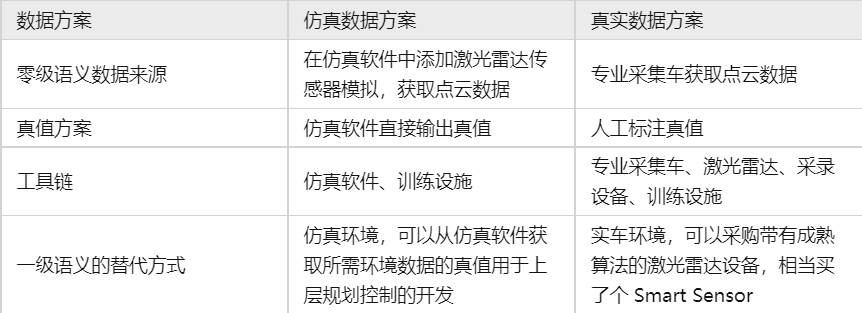
旁注:关于仿真软件的传感器模拟
交通场景仿真软件是可以知道整个场景的真值信息的,包括场景中的建筑物、道路、各种车辆、行人等交通参与者,其位置、速度、行为都是仿真软件都是知道其绝对真值的。我们看到的逼真的3D视觉效果就是根据真值渲染出来的。相当于仿真软件具备了完全的上帝视角。我们要模拟一个真实车辆上的摄像头,就需要在仿真软件的自车对应位置设置一个同样参数的摄像头。参数包括安装的位置、摄像头的像素、FOV,畸变效果等等。仿真软件还要在其全知全能的上帝视角中,过滤出该摄像头“应该”能看到的局部场景信息并输出。输出可以有0级语义或1级语义。对应摄像头,0级语义就是符合摄像头参数允许范围内“看”到的局部图像。仿真软件要根据真值渲染出这个局部图像输出。输出1级语义就是从全场景真值中过滤出这个局部的真值。其他传感器的模拟也是类似原理。只是不同传感器的0级语义模拟时,要根据局部真值转换成该传感器对应的信息形式。所以仿真软件中一个模拟的传感器本质上是整个场景信息的一个过滤器。
视觉算法独立开发闭环
对本例的 AEB 功能来说,视觉算法主要做的工作是目标识别与分类、目标跟踪、视觉测速、车道线识别等等。下表列出了四种不同的数据来源方式来完成视觉算法开发。

这四个方案都可以支持视觉算法独立的进行开发和训练。但从左到右,是从原型系统到真正量产可用的过程。数据量越来越大,需要的资源也越来越多,成本也越来越高。体现了一个单体算法开发从起步到真正实用的过程。
旁注:关于联合标注
数据采集的时候如果同时采集激光雷达数据和视觉数据,只要两个传感器数据的时间戳能够做好同步,并标定好相机和雷达之间的位置关系参数,那么标注激光雷达数据的同时是可以连带视觉图像数据一起标注的,称为联合标注。如图 15所示是联合标注工具。我们可以看到在激光雷达点云上标注的车辆,同时在左后相机上也被标注出来。因为点云是3D 空间,所以可以在三视图上对标注框做更精细的调节,转换到视觉图像上,就是一个贴合非常好3D Bounding Box。这样我们为激光雷达数据标注真值数据时,可以同步标注图像数据的真值。
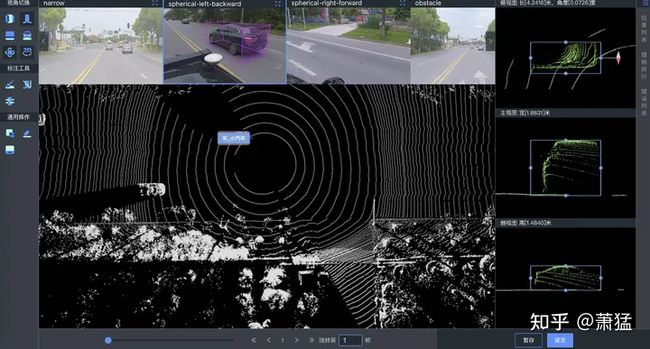 图 15 激光雷达与视觉的联合标注(图片由百度标注团队提供)
图 15 激光雷达与视觉的联合标注(图片由百度标注团队提供)
3.3.3 “1-2级的语义提升”独立开发闭环
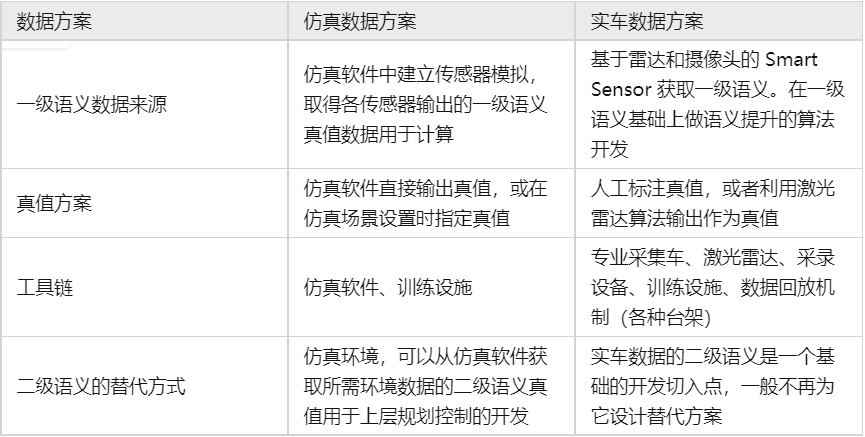
此AEB案例中,1级到2级到语义提升算法可以包括:
后融合算法:根据毫米波雷达输出的目标和视觉算法输出的目标。
目标跟踪算法:在连续多帧数据中跟踪单个或多个目标
基于车道线的车体定位:判断车辆与车道的关系
主要目标选择算法:从多个目标中筛选当前最重要的关键目标
这些算法的数据方案基本类似,如下表:
3.3.4 “2->3 级语义提升”独立开发闭环
轨迹预测与行为预测的独立开发闭环
AEB 功能对于选定的主要目标,要判断其危险性,需要做“轨迹预测”和“行为预测”。我们认为这是2级到3级到语义提升。
旁注:关于“轨迹预测”和“行为预测”
“轨迹预测”和“行为预测”在 AEB 中并不是必须的,目前实际量产的 AEB 功能,多数并没有做,或者并没有明确的有这两个模块。一般在 AEB 功能的“危险程度评估”阶段,会对主要目标的速度和方向做一些判断,并不会去做较长时间(比如5秒以上)的轨迹预测。因为 AEB 功能如果需要被触发,从触发到执行的时间非常短,从预警(声音)到舒适性制动再到紧急制动的过程一般会在0.5-3秒内完成。从保守的安全性考虑,决策时不考虑目标未来的轨迹和行为,会减少漏报的可能性。如果能在足够的数据支持下增加“轨迹预测”和“行为预测”理论上可以减少误报率(幽灵刹车)。所以这两个算法的开发应该作为 AEB 功能持续改进时的切入点,而不是一开始的重点。Level 4 以上高阶自动驾驶中“轨迹预测”和“行为预测”的重要性就非常大了。

3.3.5 “2和3级语义利用”的独立开发闭环
对于本例的 AEB 功能来说,“2和3级感知语义的利用”就是基于它们执行车辆的控制的行为“舒适性制动”和“紧急制动”。
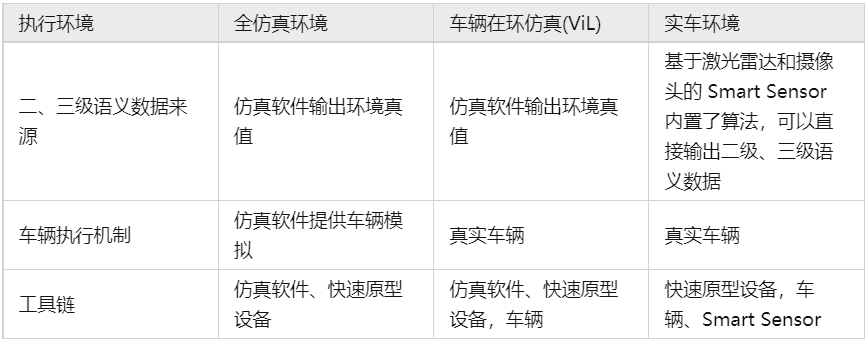
这正好是“图 4 车辆控制算法开发闭环演进”说阐述的内容。
3.3.6 独立闭环与执行环境
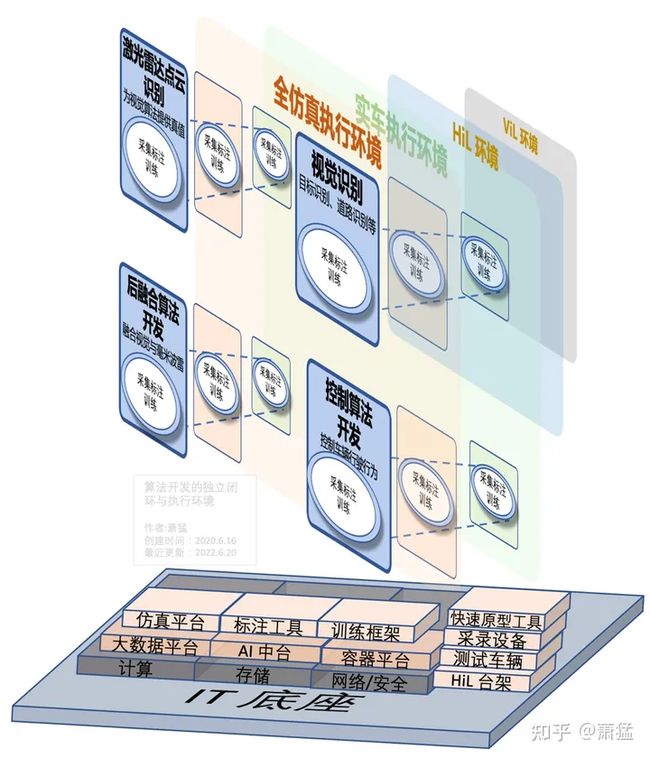 图 16算法开发的独立闭环与执行环境
图 16算法开发的独立闭环与执行环境
通过上面的分析,我们可以发现一个特点,各层以及层级之间语义提升的算法可以独立开发,但是可以在不同的执行环境中开发,从便捷的仿真环境,逐步到更贴近真实场景的实车环境。
仿真环境数据和真值获取方便,便于建立初始研发闭环。实车环境跟真实量产的执行环境最为接近。
如图 16所示,几个不同语义层级的算法都可以独立进行开发(对低级语义的数据需求使用替代性方案),同时还可以在不同的执行环境中运行,包括纯软仿真环境、HiL台架、 ViL 仿真、实车环境等等。如前文所述,每种环境的数据来源、真值方案各有不同。完成从原型开发逐步向量产质量的过渡。
各种环境都需要一定的 IT 底座进行支持,越接近量产,数据规模越大,IT 底座的资源也越多。同时需要一系列的工具链支持,包括仿真软件、台架系统、采集系统等等。
83.4 智能驾驶系统集成的一般原理
各算法模块能够独立进行开发和测试了,那么下一步就是如何进行集成。
3.4.1 集成的三个维度
可以从三个纬度去考虑集成过程,为了能小粒度的准确的表述集成的演进路线,我再把每个纬度分层三段,如图 17:
算法串接(单体算法 局部闭环 全程闭环)
执行平台(原型平台、工程平台、量产平台)
数据规模(少量数据、大量数据、海量数据)
 图 17 三个纬度看待系统的集成
图 17 三个纬度看待系统的集成
本文会出现“执行平台”和“执行环境”两个概念,这里做一下定义。“执行平台”是自动驾驶算法和软件的运行平台,包括硬件平台(MCU + SoC)、操作系统、中间件等。“执行环境”是执行平台及其所运行的外在环境,外在环境包括传感器、车辆以及交通场景。外在环境主要有实车道路环境与仿真环境两类,也有实车+仿真道路的模式(ViL)。
3.4.2 算法串接
“算法串接”很容易理解,图 14中列出的多个算法可以连接在一起。比如,我们在仿真环境开发毫米波雷达与视觉的融合算法,两个一级语义的数据都可以由仿真软件给出,那么这个研发闭环就是“融合算法在仿真环境下的单体闭环”,实现的是1->2级语义的提升。
如果把视觉算法加入这个闭环,也就是让仿真软件输出渲染图片,用训练好的深度学习模型进行推理,计算得到车道信息和目标列表,再跟雷达目标进行融合,这样就把0->1, 1->2 两级语义提升连接在了一起。但还没有完成全部 AEB 的流程,所以只是“局部闭环”。
局部闭环是一个逐步叠加的过程,一个个算法模块或功能单元逐步被纳入到执行平台中,直到把图 14中的所有算法连接在一起,形成仿真环境下的从感知到控制执行的全流程,称为“全程闭环”。
3.4.3 执行平台
如果系统都集成是在仿真环境下执行的。整个过程完全没有使用任何将来会安装在车上的元器件。那么这执行平台只是一个“原型平台”。对应与图 16中的“全仿真执行环境”平面层。
“原型平台”不光可以基于仿真建立,在实车环境也可以。我们可以用两个 Smart Sensor(内置算法直接输出目标信息摄像头和雷达器件)提供一级语义来开发融合算法,这是单体闭环。如果去掉视觉 Smart Sensor,换上我们自己选用或开发的“摄像头+ISP+视觉算法”提供视觉目标,这就到了局部闭环。我们再加上控制算法,使用快速原型设备控制真实车辆,就可以形成全程闭环。(参见1.2.3中的闭环 B)如果视觉算法运行在 x86 工控机上,那这个执行平台也没有任何用于量产的元器件。
我们接着对上面的执行平台进行改造。我们去掉快速原型设备,如果我们自己的设备(ECU/域控制器/计算平台/智能大脑等等目前流行的各种叫法) 还未就绪,那么可以使用 已选定的MCU 的开发板运行实时域程序,用选定的 AI 芯片的开发板运行视觉算法(参见1.2.3中的闭环 D),这时候,整个执平台中就有了我们用于量产的元器件,我们认为它是一个初步的“工程平台”。
工程平台也是一个逐步累积的过程,比如我们用自己的计算平台设备的样件替换掉了前面两个开发板,这就往前跟进一步了。最终我们的执行平台就是正式量产的计算平台设备,成为“量产平台”。
各执行平台都可以基于仿真来运行(参见1.2.3中的闭环 C),量产平台一样可以基于仿真来运行,一般意义上的HiL 测试就是这种模式。ViL 测试既可以基于原型平台,也可以基于量产平台。
3.4.4 数据规模
说到数据闭环,数据规模是大家最关心的事情。因为无论是采集、存储、脱敏,还是数据的清洗、筛选、标注、训练,一旦上了规模,都是大把大把真金白银的投入。假如我们准备了100量专业采集车,配备全套传感器,全国采集了上千万公里的数据(这投入已经是10亿人民币量级了),然后发现某个数据没有时间戳~~~~ 芭比Q 了
这里我把数据规模分为“少量数据、大量数据、海量数据”,这里不必纠结于字眼,多少本来就是相对的概念。名称只是一个代号,重要的是数据规模划分的逻辑。
少量数据
图 17中把“算法串接、执行平台”的各自三段画在“少量数据”的平面上,也是为了表示“少量数据”的重要性。这个重要性就是“基于少量数据快速建立起‘单体算法、局部闭环、全程闭环’分别在‘原型环境和工程环境’的执行能力”。
我们可以通过仿真软件,提取数据建立基于仿真的算法串接闭环,包括算法串接的三个阶段。我们也可以用简化版本的采集车,先采集少量数据做算法验证,采集车也需要迭代到一个完整版本。即便有完整版本的采集车,也可以只是先采集少量初始数据,到底是多少,看你项目需要达到的目的,几万公里不多,几千公里不少。
但这些数据的目的是为了“建立原型环境和工程环境的执行能力”,这些能力体现在至少以下方面:
算法串接的各种局部组合到全程闭环都能在原型环境和工程环境运行起来(只关注能否运行,不关注准确性)
工程环境的各种形态可运行能力经过了实际数据的检验
工程环境的各种形态能对不同的算法串接组合做自动化测试
工程环境执行中产生的日志数据可以进行回放,便于分析问题
为采集到的数据建立了标准的处理流程,基于各种数据处理工具(数据脱敏、清洗、筛选、标注、训练),建立了数据生产并推动算法提升的能力
建立了可弹性扩展的 IT 基础设施,弹性体现在算力、存储等方面,也就是 IT 基础架构具备,可以随时扩容
简单来说,就是“用少量数据建数据处理能力,为大量数据驱动做准备”。
大量数据
数据处理能力建立并得到验证,就可以投入大量资金去提升数据规模。这个时候只要资金够,就可以投入几百台采集车,获取上亿里程的数据。用数据去驱动各种算法快速成熟可用。所以少量数据的时候关注点是算法可执行,大量数据阶段关注的是算法的正确性和执行性能。这个阶段完成,整个系统具备了量产装车的可行性。
海量数据
但是就算有几百台采集车,司机驾驶行为的多样性依然不够;上亿里程,也不能覆盖所有的长尾场景。这时候就需要通过量产车辆在合适的时机触发数据采集,回传数据到数据处理平台。
假设有10万量产车具备数据回传到能力,只要设置了合适的采集触发规则,我们就可以针对特定的兴趣点(感兴趣的环境、自车行为、交通场景等)获取海量数据。这个海量不仅仅体现在数据容量上,更体现在数据多样性上,10万不同的司机,遍布在几乎所有可能的道路环境,发生任何事情都不奇怪。
一般来说,我们会把通过大量数据验证的软硬件系统部署到量产车上,但是以“影子模式”运行。也就是全部的传感器都开启、所有涉及的的计算都正常执行,但是到控制车辆的最后一步放弃执行,改为触发数据回传。
这样通过海量数据挖掘出长尾场景,这些场景的数据经过加工后,可以在合适的工程环境中回放,分析、复现问题并验证修复的结果。改进后的软件 OTA 到量产车辆,再重复这样的循环。经过一段时间的迭代,长尾场景的数量收敛到一定程度,相同触发条件下的数据回传量也会减少,那么在合适的时机,就可以在量产车上关闭影子模式,真正启用功能的执行。
综上所述,数据规模三个阶段的作用,总结来说就是以下三点:
用少量数据尽快建立起“单体算法、局部闭环、全程闭环”分别在“原型环境和工程环境”的执行能力,并能进行自动化回归测试。
基于专业采集获取的大量数据,驱动上述执行能力组合,快速迭代,达到量产装车的基本要求,保证影子模式能够执行
利用量产环境回传海量数据,并进行分析处理,提取长尾场景,补充训练、测试并改进系统,最终实现在量产车上启用功能。
3.5 AEB 功能的系统集成路径
上一节是一般意义的系统集成原理。现在我们回到我们的样例AEB 功能开发,看如何进行整体的系统集成。我们先基于少量数据,在“算法串接”和“执行平台”两个维度上进行集成。
图 18显示了整个集成的过程。为了能在一页图上能放得下,我们还省略了一些更细节的步骤,不过图上显示的部分已经足够说明整体的集成思路了。
因为整幅图比较复杂,自定义了一套符号体系来表达,说明如下:
图上的实体符号有三类,“算法闭环”、“执行平台”和“工具集”。算法闭环的三个几段用三种颜色做了区分。每个算法闭环下有其依托的执行平台。整幅图从上到下分了三个区域以区分“原型环境、工程环境、量产环境”。工具集分为“仿真工具集”和“实车工具集”,以不同颜色区分,布局在图上两侧。
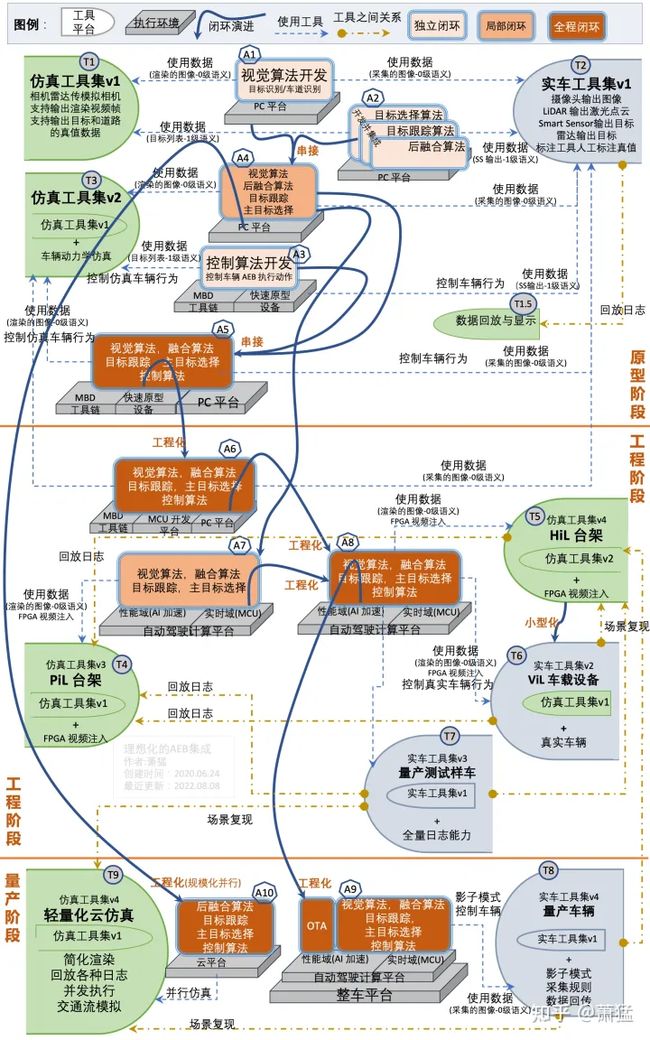 图18 理想化的 AEB 集成(虽然图很复杂,但仍只是实际集成过程的简化表示)
图18 理想化的 AEB 集成(虽然图很复杂,但仍只是实际集成过程的简化表示)
图上的连接线三类,一类表示算法闭环的串接关系,一类表示执行环境如何使用工具集,一类表示工具集之间的关系。连线附近有关于其意义的文字说明。可以参见图例来识别符号含义。为了便于后文说明,算法闭环和工具集上有数字角标,用于在后文陈述中对其引用。
整张图主要有三条线索,“算法串接”和“执行平台演进”两条线索本身就是我们前面说的集成过的两个维度。另一条线索是 “工具集的变化”主要体现了集成过程中不同阶段的测试环境和测试方法。这三条线索是交叉行进的,虽然图上的布局尽量体现了从上到下从原型开发到量产的过程,但依然在中间会出现很多交叉的过程,这也是感觉复杂的原因。我们理解集成过程时,也要顺着这三条线索去分析。我们从上到下,依次来说明(后续内容建议阅读时打开另一个页面,显式图 18,随时对照)。
原型开发阶段
原型阶段的 A1 (视觉算法) A2(后融合、目标跟踪、主目标选择)和 A3(控制算法)三者之间是可以完全独立进行开发的。A1使用的是0级语义数据,A2使用的是1级语义数据,A3使用的是1级和2级语义数据。A1和 A2都可以在 T1、T2这两个工具集下进行闭环测试,T1、T2分别提供了仿真和实车的测试环境,提供算法需要的0级语义或1级语义。A1、A2、A3是典型的以语义分层为边界做的划分,使得各层算法可以独立、并行的进行开发和测试。
A1和A2串接起来成为 A4,直接实现从0级语义到2级语义的提升。A3、A4串接起来形成 A5。A5就已经是从感知到控制的全程闭环了。
A1~A5的执行平台虽然都算原型平台,但是也是有差别的。A1,A2,A4可以直接在 PC 上进行开发,开发环境的建立成本会低很多。A3和 A5涉及到对车辆的控制,一般都需要 MBD (Model Based Development) 工具链和快速原型设备支持(参见1.2.3)。
A1~A5都可以在仿真测试环境或实车测试环境运行。同样的功能和执行平台能在两个不同的测试环境,一方面可以利用仿真降低研发成本提高效率,一方面方便建立自动化测试体系。
大多数自动驾驶系统的开发都是从原型阶段开始的,原型阶段的最终形态一般就是在在改装好的车辆后备箱安装一大堆设备,以x86工控机作为计算平台,驱动车辆演示一些自动驾驶功能。多数公司前期融资时就是这样的状态,但实际上这仅仅只是一个漂亮的 Demo,距离工程化的量产,还差的非常非常远。
工程化阶段
工程化阶段的核心目标,直观来说,就是把原型阶段车辆后备箱里的那一大堆设备都扔掉。这要求硬件上要用能耗比高的计算平台替换掉工控机,要求具有高 AI 运算能力、高实时性,还要能满足车载设备抗振、耐高低温、电磁兼容等要求。软件上从操作系统到中间件到自动驾驶软件架构,也有非常多的技术难点需要克服。同时,软硬件还要能满足汽车功能安全要求。所以工程化落地能否合理有序的推进,同时辅以一系列测试手段保证产品的质量,是自动驾驶技术能否落地的关键环节之一。
图 18演示的工程化阶段的步骤仍然被高度简化了,但可以用来阐述一般性原理。具体到实际项目要做专门的工程化路径设计。
A5到 A6的工程化动作是把快速原型设备替换为量产的 MCU 平台来执行实时域的计算。相当于1.2.3节中的 闭环 B 演进到闭环 D。A5和 A6的仿真测试环境和实车测试环境是一样的。这也是符合最少变量原理,每次演进步骤尽可能做最小的改变。
A4到 A7的工程化步骤是讲 PC 平台替换为车载计算平台,这其实是一个很大的工程化动作。内部还可以进一步拆分层更小的步骤,比如 A1,A2包含的4个算法可以单独向 A7的执行环境移植,图上没有做这更细粒度的拆分。
A4和 A7都不是全程闭环,因为没有对接车辆控制算法。A7的测试环境可以有很多种,技术人员从芯片的开发板开始,逐步迭代自己的硬件平台和基础软件,最终形成相对完整的计算平台。密集开发阶段,可能每个开发人员桌面都会有一个样件,专注调试自己负责对模块。
图 18画的 A7与T4形成的测试环境是比较接近开环测试(不包含车辆控制)能达到的最大测试跨度。T4是PiL(处理器在环)测试台架,主要测试软件和算法在目标嵌入式平台上的行为。PiL 比 HiL 简单,可以包含仿真软件,也可以不包含仿真软件,这样成本很低,就可以在 PiL 台架上同时支持多路目标设备,方便进行并行执行多个用例的自动化测试。
A6和A7 集成在一起就成为A8,A8在目标计算平台上运行完整的感知到控制的闭环。A8可以在 HiL 台架(T5)上进行测试,也可以将 HiL 台架小型化后再车上进行ViL 测试(T6),也可以直接实车测试(T7)。ViL 和实车测试录制的日志数据,应该可以在 HiL 和 PiL 台架上进行回放,用于分析和定位问题。
量产阶段
A8进一步工程化到量产装车的正式产品 A9。A9与A8相比,增加的比较重要的特性在几方面:
A9要支持一定的 OTA 能力,方便更新软件 A9要与车辆环境深度集成并进行严格测试,比如电源管理、网络管理等。而 A8只需要关心自动驾驶相关的功能、 A9需要能支持影子模式与数据回传。A10的产品形态并不是安装在车上,但是也把它放在了量产阶段,因为这就是它这种运行模式的最终形态。A10直接从A4进化而来,执行平台从PC换成了云平台。A10所依赖的执行环境 T9为轻量化的云仿真平台。它不需要做0级语义的支持,这意味着不会做视觉的渲染输出,会大大降低单个仿真实例对计算资源的需求。一般来说,T9的渲染只需将1级及以上语义信息以线框图的形式呈现出来。比如我们经常能看到 Apollo 开发平台仿真的渲染画面。
 图 19 图 19 场景渲染的线框图形式(图片来源于 Apollo 官网)
图 19 图 19 场景渲染的线框图形式(图片来源于 Apollo 官网)
图 19 场景渲染的线框图形式(图片来源于Apollo 官网)
T9的重要作用在于对场景的复现与测试,也就是在三级及以上语义基础上,验证对车辆行为的规划与控制。比如我们再 A9回传到数据中发现了一个“鬼探头”的场景,就可以在 T9仿真环境中设计复现这个场景,并将它加入到每日例行的回归测试中。
T9的另一个重要作用是并行仿真,后文详述。
3.6 仿真及测试工具链分析
可以看到,图 18中包含了很多仿真和测试的工具链,这些工具链的存在对完成整个系统的工程化有非常重要的作用,以下简要列出来仿真及测试工具链在“工程化、高效率、一致性、可测性、精确性、可靠性”等方面的作用:
实现工程化的分阶段测试。研发不同阶段提供的测试环境 T1~T9 ,也为出现问题时提供回溯分析的平台。
提高效率,节省研发资源。能在仿真上做的开发和测试就尽量在仿真上先做,至少先把算法或功能的流程通路先跑通,省得在实车测试出现这方面问题,就能节省实车测试时间。
验证不同环境下的一致性。对于能同时在仿真环境和实车环境执行的研发阶段,如 A1~A6,A8 ,保证执行平台一致,仅需关注测试环境的不同。就可以在仿真环境中提早发现问题。也可以把实车环境的问题在仿真环境进行复现。
通过仿真系统模拟部分必须的数据,使得局部或全程系统达到可测性,尤其某些危险场景实车测试很难进行,就只能进行仿真测试。
软件系统的可靠性是需要持续不断的回归测试来支持的。理论上只要有代码(或AI模型)的更新,都应该执行回归测试。每次变更之后都要将之前的测试用例都重新测试一遍。必须要建立自动化测试机制才能高效率高频次的执行测试动作。大多数自动化测试只能在仿真环境进行。仿真是解决自动化测试的关键武器。
不同算法都必然有精确性的要求,这需要测试机制能够对算法的精确性提供测试和度量的方式。
分析和设计测试环境时,可以从以上几方面进行考虑。图 18中T1到T9的测试环境都会体现上面几个特性的组合。但T1~T9也不能完全涵盖全部可能的测试环境,需要根据产品和项目的需求设计合适的测试环境。
同时从T1到T9各自的用途和侧重点有不同,产生的数据和对数据的利用方式也有不同。我们也可以从数据的语义层级出发对测试环境进行分析。
下面我们对几个重点的仿真和测试环境从“工程化、高效率、一致性、可测性、精确性、可靠性”以及与数据的关系方面进行一些分析。
3.6.1 纯软件仿真
图 18中T1和 T3是纯软件仿真。A1+T1 使用的是0级语义的图像数据,A2+T1 使用的是1级语义,不需要图像数据。这两个组合首先解决的首要问题是提高效率。尤其在开发前期,车辆环境还不具备的时候就可以进行开发。一台车辆从采购到改装至少两个月,还要找专业的有工程车测试资质的测试员来开,多个团队等着排队用车,会消耗很多时间在等待上。
要让 T1具备对 A1和 A2 的可测性,要求 T1的仿真软件具备“传感器模拟”能力和良好的“真值输出接口”。
传感器模拟
我们先区分两个仿真中的两个概念“地图”和“场景”。“地图”代表一个交通环境中的静态部分,包括道路结构(含桥梁隧道)、交通标志、静态障碍物等等。“场景”表示“地图”加上一段时间内交通参与者的行为,交通参与者包含自车(EGO Car)、其它车辆、行人信号灯状态变换等等。简单说,“地图”是静态的,“场景”是动态的。这两个词的意思或许在其它地方与这个定义有差别,但在本文,就是表示这个意思。
那么当一个仿真软件加载并运行一个场景时,它是有一个上帝视角,知道场景中所有事物(包括地图中的静态物体和场景中的所有参与者)的状态的。传感器模拟实质上是给这个全知全能的上帝视角增加一个过滤器。比如一个前置摄像头,给定了横向和纵向的视场角后,它就过滤掉这个视场角之外的环境信息,只把视场角内的环境数据输出出来。这就是传感器模在环境语义上的本质含义。
对于类似于 A1和 A2的开发需求,要看重仿真软件的传感器模拟能力。包括能够支持的传感器类型,每种传感器能够模拟的物理参数范围,执行性能上要能同时设置大量传感器而没有明显的延迟等等。
上帝视角的场景信息至少是一级语义,所以传感器模拟输出一级语义是非常自然的,反而输出0级语义(图像或点云或雷达信号),反而要经过额外的数据处理或渲染。
关于仿真软件的渲染效果
人们很容易关注仿真软件的3D 实时渲染效果,毕竟这是很容易被直接看到的,高逼真度类似游戏的场景渲染,确实很震撼。但从语义层级来讲,这是零级语义,仅仅在需要使用图像数据的闭环测试中需要,比如 HiL 测试。
对于直接利用一级及以上语义进行开发的闭环(如 A2和 A3),是不会利用渲染图景,对渲染效果自然也就没有要求,反而往往会更关注仿真软件的传感器模拟能力,真值的结构定义、输出API形式。要对车辆进行控制的研发闭环,会关注仿真软件中自车的动力学模拟能力是否足够逼真。
支持三级语义(涉及自车之外的其他交通参与者的研发闭环),更希望仿真软件能够提供除自车之外,对其它交通参与者行为的控制能力,包括AI 控制或提供编程控制的接口。
一级及以上语义的研发闭环,对渲染的要求只要能让人看清语义含义就行,可以简单到只需要使用线框图显示就足够了,这样不需要高性能的渲染设备,还可以直接在浏览器中高性能的展现,也方便在渲染画面中附注各种方便开发人员进行分析的信息。
高逼真度的3D 实时渲染效果需要高性能显卡支持,研发人员在桌面端或许有需求。当不适合用于成百上千场景的并行仿真,并行仿真中本来也没人去看渲染的结果,并行仿真只需要记录日志数据,如果有需要(比如分析仿真中发现到的错误),只要能将日志数据以线框图的形式回放分析就可以了。
真值的定义和输出接口
仿真软件自身拥有的上帝视角,有场景中所有事物的真值数据。但是这个真值的数据结构如何定义,真值数据如何输出并不是一个容易的设计。
真值数据结构体现了描述复杂的交通环境的能力,我们也把这个交通环境的数据表达形式成为“环境模型”。开放仿真接口(Open Simulation Interface)定义了一套环境模型表达的数据结构,使用 proto buffer 的格式定义,可以从 GitHub上获取 。
图 20 是分析 OSI 定义中所有文件的依赖关系而绘制出来的依赖图,A --->B表示 A 依赖于 B。可以看到,所有代表传感器检测到的环境信息的数据文件是依赖于代表真值的数据文件的。这也从侧面说明了,仿真软件输出的模拟传感器检测到的环境数据,是根据真值推算出来的(把传感器当过滤器,输出部分环境真值数据,根据必要还可以加噪声)。
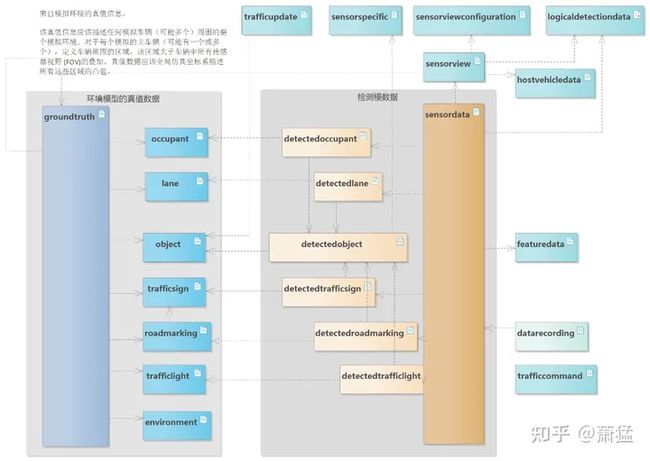 图 20 开放仿真文件依赖分析 (A --->B ,代表 A 依赖于 B)
图 20 开放仿真文件依赖分析 (A --->B ,代表 A 依赖于 B)
代表上帝视角的真值数据本身也非常复杂,毕竟要描述“整个世界”.
 图 21 开放仿真接口的真值定义
图 21 开放仿真接口的真值定义
图 21 是开放仿真接口的真值定义(根据 OSI 定义文件逆向生成,高清图请单独索取),包括车道、车道边界、静态物体、动态物体、交通标志、地面标志等等。
OSI 的定义出来的比较晚,大多数仿真软件还没有支持,所以各仿真软件都有各自的真值和模拟传感器输出的数据格式。所以为 A1和A2类似的开发阶段,需要考场仿真软件真值的表达能力。还有真值和模拟传感器的数据的方式也会影响开发的难易程度,值得关注。
动力学仿真
图 18中A3、A5(原型阶段的全程闭环)和 A6(工程化阶段的第一个全程闭环)都使用了T3作为仿真环境。T3主要是在 T1的基础上增加了车辆动力学模拟。一般自动驾驶仿真软件都会提供一定的车辆动力学模拟能力,预置一些典型车型的动力学基本参数。用户也可以根据已知的参数来在仿真系统上创建新的动力学参数车型。
T3首先解决的需求也是提高效率和可测性。让车辆未就绪时能支持控制算法的开发。T3跟 T5(HiL 台架测试环境)是有很大差别的。T3主要靠软件解决问题,尽量不涉及昂贵的硬件。T3对准确性的要求低,但同时也要求成本低。软件仿真的优势就是可以同时开启很多实例,让不同组别的人可以同时工作。甚至每个开发人员都可以在桌面启动一个仿真测试的开发闭环。测试组也可以同时进行测试闭环的开发,自动化测试的搭建。所以要求单授权的采购成本低才能采购较多的授权。
而T5 HiL 台架测试会追求高精度,不仅仅动力学模型参数准确、实际执行效果也跟要适配的车辆高度一致,动力学模型也要放在高性能的实时机上执行,支撑的软件也会非常昂贵。这样的系统一般来说不可能会采购很多实例。
纯软件仿真工具的选择原则
纯仿真软件(T1和 T3)的重点在提高效率和提供可测性,并尽可能降低成本以采购尽量多的授权。同时在准确性上的要求应有所让步。
0级语义的精确性不是 T1的目标。满足 T1要求的仿真系统,需要有较好的渲染效果,但是不用追逐过于逼真的渲染效果,因为再逼真的效果,也是计算机生成的,跟物理摄像头拍摄还是有很大出入,尤其在人眼看不到的细节上,人眼看不到的内容,也许对算法上敏感的。而为获取逼真渲染效果的投入与其产出并不成正比。
动力学模型的准确性也不是 T3的核心目标,T3需要的是低成本下的动力学模型支持。只要测试闭环能建立起来,实际对动力学效果到 T2(实车上)进行测试。
所以在选择仿真软件时,尤其要注意以下几点:
警惕对渲染效果的过度宣传,确认你是否需要并值得为其付费
这个阶段不要过度追求高精度的动力学模型
根据自己需要的语义层级、传感器类型谨慎选择仿真软件的功能模块
总之就是要在满足核心目标(提高效率和实现可测性)的前提下,尽可能降低成本而采购足够多的授权。一个所有功能齐备、渲染精美、动力学模型高精度的仿真软件,单个授权上百万了,抵得上一辆豪车了,如果不能买多个授权,开发团队和测试团队不能同时使用,也就谈不上效率了,还不如多配几台车算了。
同时为了能基于不同层级的语义做各层算法的并行开发,要特别关注仿真软件对不同层级语义的定义能力、真值的定义能力、数据格式规范、以及 API是否便利。
3.6.2 处理器在环仿真
1.3节已经提到 PiL(处理器在环),也就是图 18中的 T4。
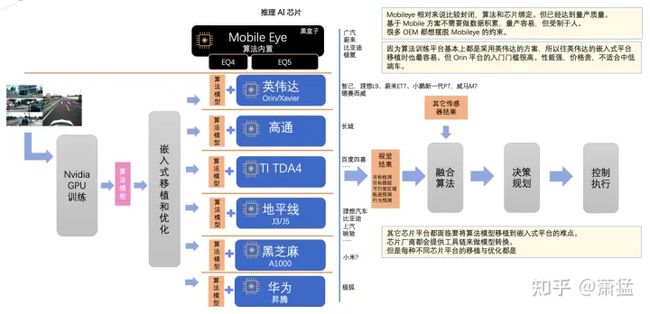 图 22 各 AI芯片平台
图 22 各 AI芯片平台
PiL 测试首要解决的问题是一致性。原型阶段的所有软件都没有在我们的最终目标硬件上运行。更直接到说法,原型阶段大多数都是在 x86平台上开发,在车上也是用 x86工控机,工控机上安装Nvidia的显卡来运行深度学习算法。但是在量产阶段,我们需要所有软件运行在车载专用计算平台,CPU 以 Arm 为主,AI 模块各芯片有自己的专用设计。
图 22列出来目前比较知名的一些 AI 芯片平台。可以看到,虽然大家在训练阶段都使用Nvidia的 GPU 或计算卡,但是在推理阶段, 训练得到的AI模型在向不同的嵌入式平台移植时都需要做一下模型的转换、嵌入式的优化工作。需要保证移植和优化完成后,算法的执行结果仍然和最初训练出来的一样。
除了感知类的 AI 算法外,控制算法原型阶段在快速原型设备上运行,工程阶段要在高实时 MCU 上运行,也需要保证一致性。嵌入式系统的基础软件环境与工控机也不同,也需要验证软件在运行环境变更后,其行为是否一致。
日常开发可以用计算平台样件,为了方便做自动化测试,一般通过 PiL 台架来执行。PiL 台架上包括电源、电压范围、软件的更新都可以通过程序进行控制。方便自动化测试用例的部署和执行。以太网、Can总线、LVDS 线束等也可以设计层可以通过程序控制其中断与连接,这样可以模拟故障的注入。
PiL 台架可以支持视频注入到嵌入式平台的摄像头数据捕获接口(一般是 LVDS 接口),这样可以把嵌入式平台的视频捕获模块也纳入到测试回路中,这是 T1、T3 仿真测试环境无法实现的,T1、T3的渲染数据只能通过以太网发送,是测试不到视频捕获模块的。如果 PiL 台架不包含仿真软件,还可以直接回放视频文件作为视频源,这样也可以将实车路采的视频数据在 PiL 台架上进行回放。
3.6.3 硬件在环仿真
具体的硬件在环测试的原理和设计很多文章有论述,这里不做详细说明,只对其与其他测试手段的区别进行说明。
在 PiL基本上解决了一致性的前提下,HiL 主要目标是可靠性和可测性,同时兼具精确性。能够达到这几点,是由设计HiL 测试的几个基本原则决定的:
待测设备的所有外部接口数据交换方式要尽可能跟实车一样
完成从感知到控制执行的全程闭环
测试场景通过仿真来实现
全系统能够程序控制自动化
对于第1点,我们想达到的效果是让待测设备貌似不知道自己当前是在车上还是在测试台架上。因为所以的外部接口的数据交换都是跟车上一样。比如在摄像头数据输入上,也需要通过视频注入的方式,让视频捕捉设备以跟车上同样的方式获取图像数据(0级语义模拟)。也可能某些传感器的0级语义模拟非常困难,很难做到很精确,或者成本太高(比如雷达回波),那么部分传感器数据使用1级语义。但总的来说,是倾向于全部使用原始的0级语义数据。
这样就将待测设备的全部软硬件都纳入到了测试闭环中,相对于其它跳过某些环节的测试手段而言,这是最完整的测试闭环(上文第2点),这是能验证系统可靠性的一个基本前提。同时与自动化测试相配合,可以在测试频次、测试时间上提高数量级,对可靠性验证有很大帮助。
虽然是全程闭环,但是交通场景是仿真的,这也就意味着一些危险的场景能够以较低的成本被进行测试,达到较好的可测性。
因为感知到0级语义(图像、点云等)是仿真出来的,经过训练的感知算法对这些数据会有非常好的效果。这可以推导出两个结论:
HiL 测试中感知算法对仿真场景非常准确,能给后续的决策规划提供较好的依据
HIL 测试实际上测试不了实际感知算法的精确性(但能助力形成全程闭环过程)
在这两个前提下,如果我们提高车辆动力学模型的精确性,就能非常好的测试控制算法的精确性。因此 HiL 测试的仿真软件要求能够具有非常精确的设置和调整动力学模型的能力,同时使用高性能的实时机(硬件和操作系统都是以高实时为目标进行设计)来执行动力学模型,保证其执行机制跟实车环境高度一致。这也是 HiL 测试系统价格昂贵的重要原因之一。
这与4.5.1中对动力学模型的要求是不一样的。4.5.1的纯软件仿真是以效率为主,要求低成本获取足够多的软件授权提高前期的开发效率,可以牺牲部分动力学模型的精确性。本节的 HiL 测试确是要以控制算法的精确性为主要目标之一,以高成本实现一个测试台架。
ViL 测试(图 18的 T6)可以看成是 HiL测试的小型化,整套测试环境(仿真软件、传感器注入能力)都被安装到车上。去掉 HiL 测试中运行动力学模型的实时机,替换为真实的汽车执行机制。这样就在 HiL 基础上,对控制执行的测试直接使用真实的实车设备,进一步提高了测试的精确性。因为依旧使用仿真场景,所以仍然具有跟 HiL一样的可测性,但是一定程度上牺牲了自动化测试能力。
3.6.4 影子模式与云化并行仿真
前面我们用软仿真快速构建初步的研发闭环,在利用 PiL 测试环境逐步从原型阶段向工程化阶段转换。HiL 测试实现了工程化阶段最完整的仿真闭环,ViL测试得到更精确车辆控制效果。我们也可以通过实车(T7)来复现某个单个场景(使用假人、模型车等道具)。到这一步,对单个场景的工程化能力建设到了极致。我们可以在这一系列工程化阶段中把算法、软件迭代得越来越好,但还有一个关键点问题:场景覆盖度不够。
这体现在两方面:
如何发现大量的长尾场景
如何对大量场景进行回归测试
第1点难在“如何发现未知的问题”,第2点是“如何提高测试效率”的问题。T1~T8都是针对少量场景的测试,是无法应对段时间内执行成千上万测试场景的需求的。
为了解决这两个问题,衍生出对应的解决方案,分别是影子模式和并行仿真。
量产车的影子模式
图 18的 T8是量产车,如果把刚刚开发完成对 AEB 功能部署到量产车,会出现两类大问题,漏报和误报。
漏报就是应该紧急刹车的时候没有刹车,会影响行车安全,造成重大的人身伤亡事故。但是如果为了减少漏报,将相关触发条件的阈值放得较为宽松,就会出现大量的误报,就是俗称的“幽灵刹车”,严重影响驾驶体验。
影子模式就是用来解决这个问题。其基本原理很简单,当我们的 AEB 功能实际装车后,会让所有相关的传感器、算法逻辑、AEB 功能的触发都正常运行。但是在功能触发后,应该实际执行紧急刹车动作的时候,停止执行。同时把触发时间点前后一段时间的传感器数据、自车的状态数据、驾驶员的驾驶行为数据等信息,加密脱敏后回传到云端进行分析。这里有几个关键点:
触发数据记录规则的设定与更新
数据记录与回传能力
软件 OTA 能力
设定数据触发的规则是为了找到尽可能多的漏报和误报的场景。所有影子模式下功能被触发的场景,一般都应该记录下来。这里会有大量的误报场景。甚至可以在初期将相关阈值调低一些,以获取较多的触发场景进行分析。然后调整规则,让误报逐步减少。但减少误报可能会增加漏报。
漏报的触发规则可以是检测到车辆撞击、驾驶员紧急刹车,所以漏报后的数据回传是一个亡羊补牢的过程,每一个漏报可能是一个悲伤的故事。
触发规则的设计是为了找到对算法改进有用的数据。所以往往会针对算法的能力弱点进行设计。比如根据不同传感器获取了不一致的结果时,一定有一个是有问题的,这可以是一个触发规则。或者算法对隧道的效果较差,也设定进入隧道前开始触发数据记录(根据定位数据触发)。也就是说触发规则的定义应该可以非常灵活。
在车载终端执行触发规则时,可以选用合适的规则引擎工具,具体规则可以由算法专家根据需要编写,再下发到车端。
数据记录和回传到能力也是影子模式的关键。量产车与专业采集车不一样,受限于存储与计算资源,并不能记录太长时间的数据。一般来讲软件设计时会在内存中时刻更新一个时间窗口内的数据,包括传感器数据(0级语义的原始数据和各级语义提升后的数据),规划决策的关键数据、软件运行中的关键日志信息、车辆总线数据等。数据记录被触发时,才会把内存中的数据写入持久化存储。如果遇到严重事故,数据落盘可能会失败。这些数据来源与不同的模块,如何统一记录需要做好设计。数据回传通道一般会利用智能座舱域的对外网络通讯能力。所以数据记录和回传能力是要在车辆开发阶段就进行专门设计的。
根据回传数据修正的算法和软件需要能更新到车辆上,所以车辆必须要有 OTA 能力,至少对相关的自动驾驶软件部分具有 OTA 能力。
另外数据记录触发规则的 OTA 和整个自动驾驶软件的 OTA 是两回事。前者简单很多,是为了更好的采集数据而调整采集规则,应该与软件的 OTA 分开处理。
从影子模式和正常功能启用模式并不是非此即彼的,可以有中间状态。比如某些非常确定的场景可以实际执行控车动作,而其他场景保持影子模式执行。逐步迭代更新到完全功能启用模式。
这里说句题外话,量产车从影子模式切换到完全功能启用的过程时间是不一定的,可能几个月,也可能一两年。但是这个切换的过程大多数情况下用户是不太清楚的。所以从负责任的角度看,车辆销售时应该避免夸大自动驾驶功能,尤其像 AEB 这种与人身安全密切相关的功能,避免给用户过高的预期,而降低了驾驶的警惕性,尤其是在车型量产前期。但为了新车型销售,往往会把自动驾驶功能作为宣传卖点,这里就有利益冲突。总之,在现阶段,用户驾驶时不要过度依赖自动驾驶功能,还是要专注驾驶、警惕危险,保证自身的安全。
基于云的并行仿真
基于云的并行仿真解决的是对大量场景高效率的全覆盖测试的问题。要准确理解这句话,我们只需回答以下几个问题:
大量场景从哪来,是个什么量级
为什么其他仿真形式不能满足大量场景的测试要求
基于云的并行仿真测试重点是什么,哪些能力不在它的测试覆盖范围内。
如前文所述,本文对场景的定义是“在特定的静态道路交通环境下(地图),多个交通参与者在一段时间内的行为及相互影响”。
设想如下场景。
场景:1:“一辆车顺畅的通过一个空无一人的路口”。
场景2:“一辆车通过路口时,前方车辆遇到红灯停下,本车也停下。绿灯后跟随前车通过路口”。这至少有两个交通参与者,红绿灯的状态变化也是场景的一部分。
场景3“车辆行进时突然有侧方来车,避让不及相撞”。
这些交通参与者的行为可以有无穷无尽的组合,还可以发生在不同的地图上。原型阶段和工程化阶段开发时我们只需针对少量典型场景进行开发和测试,重点是验证感知的准确性,控制执行的准确性。但在工程阶段后期和量产阶段,我们需要找到足够多的有可能会使得功能失效的场景。影子模式就是用来发现这些场景的重要手段。
如果把上述场景称为“基准场景”,根据关注的自动驾驶功能的复杂度,我们可以设计出成百上千,乃至更多的基准场景,当然我们需要尽量选择对现实交通有代表意义到场景。每个基准场景可以有多个参数。必如上面的场景3,我们至少可以设计几个参数,自车的初始速度,初始时刻位置,感知系统发现另一辆车的时间,另一辆车也可以有初始位置,和初始速度,这就是5个参数。交通参与者越多,参数也会越多。假设每个参数有5个可选值,那就是25个参数组合就是一个可被测试的场景,这里称为“特化场景”。如果有1000个基准场景,每个有25个特化场景,这就有2.5万个特化场景。这个数字就非常大了。
HiL测试能否对这些特化场景进行测试?答案是肯定的,而且可以做到非常精确。假设我们有一个完全自动化的HiL测试台架,5分钟完成一个特化场景的测试,一刻不停的进行测试,要完成2.5万特化场景的测试要将近三个月。就算有足够的预算可以多添置几个HiL台架,也是无法应对指数增长的特化场景数量的。所以不能指望HiL完成海量场景的测试。
要短时间内完成海量场景的测试,一方面要大大提高并行能力,一方面要降低单个场景测试的资源需求。首先降低资源需求的方式是仿真过程中不对零级语义数据做模拟,也就是不做视觉渲染,不做点云生成等,直接使用一级(含)之上的语义。其次是简化车辆动力学模拟。HiL测试是包含了基于真实车辆动力学模型的控制算法的。我们给线控系统下指令希望车辆加速度降低到多少,这是由运行在实时机上的动力学模型根据真实的车辆发动机参数模拟执行最后达到的。但在云仿真中,我们要求车辆加速度到某个数值,它就自然到了,怎么到的不用关心,上帝之手帮你搞定,这就是一个非常简化的动力学模型。
这样单个场景的仿真需要的资源大大降低,也就有了大量低成本复制测试闭环,达到并发测试的目的。但也意味着我们不会测试感知算法,不会测试控制算法,实际上测试的是各种规划和决策算法。
轻量化后的测试闭环非常适合部署在云平台上,不测试时不需要占用太多计算资源。需要测试时临时开启大量资源并行执行,测试完成后释放资源。
3.6.5 各种测试方式的对比
图18的 T1~T9是各种不同的测试环境,我们不能指望一种测试环境可以达到所有的测试目的,而是要在不同的研发阶段,在测试条件和成本等诸多因素的约束下,使用恰当的测试方式达到特定的目的。
下表总结了各种测试环境的关注重点。
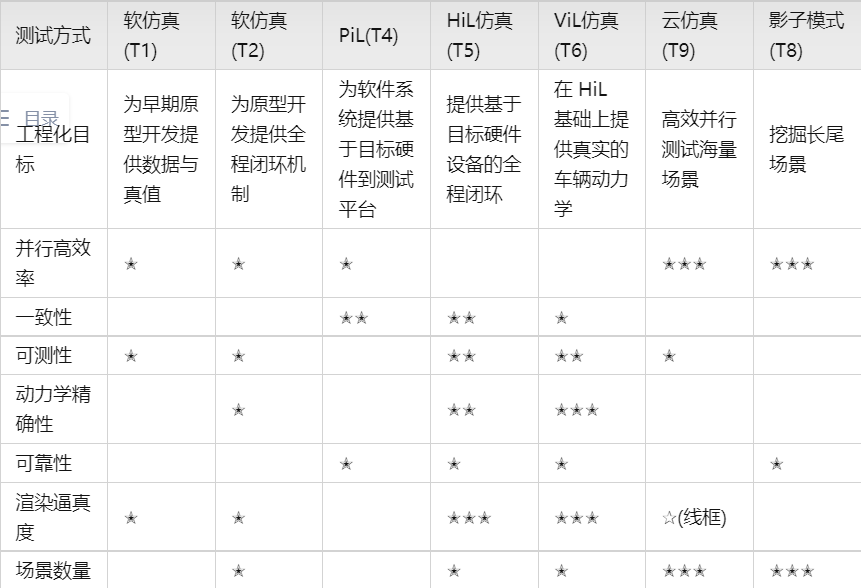
我们可以看到,软仿真阶段重点是让研发和测试团队能够尽快的建立基本的开发和测试闭环,对硬件设备的依赖尽可能少。T2因为是全程闭环,所以比 T1增加了对渲染和动力学模型的要求,但是对精确度要求不高。
PiL 测试重点解决一致性,可以通过在测试台台上部署多个设备,提供自动化测试的并行度。然后HiL 和 ViL继续增加精确性上的测试能力,但是因为较高的设备成本,一般只有少量的整套测试设备,测试成本较高。
到这一步已经可以完成对单个场景的高精度测试。然后通过云仿真建立大量场景并发测试的能力,通过影子模式采集数据挖掘基准场景,基准场景参数化后生成的海量场景通过云仿真进行高效率并发测试。测试中发现的重点场景可以再进行 HiL或 ViL 的高精度测试。
这样多种测试环境的组合使用,就构建了全方位的工程化测试能力。如果所有测试环境都完成了自动化测试能力的构建,并在各个测试阶段进行回归测试,就能很好的保证算法和软件的质量,这也是提高工程化能力的重要手段。
3.7 数据如何驱动
3.4.4阐述数据规模时提到,少量数据的作用是“快建立起‘单体算法、局部闭环、全程闭环’分别在‘原型环境和工程环境’的执行能力”。对应到图18,也就是原型阶段和工程阶段A1~A8、T1~T7的内容。这部分执行能力建立起来后,工程阶段的数据驱动才具备了前提条件。
工程阶段的数据驱动体现在两个方面:
采集的数据经过处理后(清洗、筛选、标注、检索)用于算法的开发,先在原型系统中进行验证,工程化环境具备后,也可以在工程化环境中进行验证。
具备了逐级递进的工程化仿真及测试环境后,可以利用第N级仿真环境作为第N+1测试环境的日志数据回放平台。回溯分析N+1级测试的问题,并在第 N 级仿真环境中建立可以进行自动化回归测试的测试用例。
下面分别说明。
获取对算法改进有效的数据
第1条很容易理解,尤其对于感知算法,目前普遍使用监督学习方式,根据采集的数据和真值进行训练,数据越多越好。需要针对不同的传感器、不同的算法类型选择合适的数据和获取真值的方式。这里的难点是对如何对数据进行管理,其核心就是通过一系列技术手段找到对算法改进有效的数据。
对于监督学习而言,典型问题领域使用哪种神经网络结构已经被业界研究的差不多了。在算法设计上的革命性改进很多年才有一两次。多数算法都是根据已有的论文实现,算法效果的优劣实际上比拼的是数据。
无论是哪种算法前期数据的有效性是最明显的。当算法效果提升到一定程度之后,就需要找到对算法改进有效的数据。因为只有这些数据才是具有“驱动性”的数据。
而要找到这些数据,一靠数据规模,足够多的数据找到有用的数据几率就会越大;二要依靠数据挖掘的手段。为了达到更好的挖掘效果,要从数据采集开始,到后续数据处理的各个环节,为后续能更好的进行数据挖掘做准备。这就是数据管理平台的作用。
数据回溯分析
数据驱动的第2层含义就是基于测试数据的回溯分析。图18中我们画了好几条标注为“回放日志”或“场景复现”的连接线。比如 T5 HiL台架的测试、T6 ViL 测试和T7量产车的测试,其测试执行时采集到的日志数据,我们都可以在 T4 PiL台架上进行日志回放执行。
假设我们在T7样车上进行 AEB 功能测试,测试场景是过马路时检测到行人紧急制动。在测试场使用假人和真实车辆进行测试。当某个参数组合(车辆的速度,行人出现的时机)下,10次测试会出现1次测试失败,车辆撞倒了假人,造成一定伤害。
我们可以通过在 PiL 台架或者专用的日志可视化工具中(如:ROS的 rviz 工具,图18中的 T1.5)中回放日志,分析错误所在。感知算法的各个环节、软件代码等都有可能出现错误。无论错误在哪,假如我们发现并修复了错误,那么怎么进行验证。
最直接的办法就是在到测试场上执行同样车测试场景。这里就有两个问题:
频繁的在测试场进行实车测试,成本高昂,效率非常低。
没法保证每次实车测试的执行环境完全一样。
就算不考虑测试成本的问题,第2条也让确认 Bug已经被修复非常困难。而且Bug的发生率是10次偶发1次。修复后就是测试100次都正确也不能认为 Bug 已经解决,因为可能这100次测试都没有达到 Bug 的触发条件。
这种情况下,至少有两种解决方案。
将出现错误的那次测试的实车数据在 PiL 台架上进行回放执行。这个执行与纯观看日志数据的结果不一样,PiL 上的回放执行是可以直接将录制日志中的视频图像数据直接注入的计算平台的视频捕捉接口,各算法和软件尽可能的运行只到错误出现的那个时间点。在这个时间点,验证bug 修复前后同的执行结果。这个数据回放是开环的,如果 bug 修复成功,该时间点后的日志时间就无意义了。
另一种方法就是在 HiL 台架上复现出错误的场景。同样的场景使用bug修正前和修正后的不同版本软件进行测试,比较执行结果。这个测试时闭环的。
工程阶段,专业采集车可以运行数百万公里并采集数据。我们可以分析提取大量的片段数据,每个应该触发或者不应该触发某个动作的执行。可以把这些片段数据在 PiL 台架上进行测试,验证与我们的期望是否一致。
到量产阶段,影子模式根据设定的规则回传大量不同场景的日志数据。但是量产车与专业采集车相相比,采集到的日志数据种类和数量都会少很多,一般达不到能在 PiL台架进行回放的条件。跟多的是分析场景,在 HiL/ViL 上进行高精度场景复现,验证代码在这些仿真场景下的行为。或者在轻量化的云仿真平台进行复现、修复、再验证。
3.8 高阶功能的闭环拓展
前文用 AEB 来举例子,只是为了在尽量单一的功能下,突出工程化的方法论。下面我们尝试将这个工程化的分析方法应用到更多的功能开发,以两个例子作为说明。
3.8.1 Level 2.5自动车道变更功能
自动驾驶的功能分级里有一个 Level 2.5 的说法。大意就是 Level3达不到,但功能又明显超过了 Lever 2 的范围,还有称为 Level 2.9 的,含义不言而喻。当然也有人认为 L1~L5这种自动驾驶能力的分级方式本身就不对。
##### 3.8.1.1 L2.5是一个核心技术能力的临界点
不过从工程化的角度看,L2.5 的功能点是一个核心技术能力的临界点,非常关键的临界点。L2.5的典型功能就是“自动变道”,可以分为“人触发自动变道”和“完全自动变道”。为什么说它是核心技术能力的临界点?至少有两个原因:
首先,从算法角度看,从这个功能开始要做路径规划了。之前 L1、L2的功能只需要在某个时机对车辆运动实施横向或纵向的影响就行。但是变道不行,规划到控制的设计方式跟 L2有很大不同,难度也增大很多,倒逼对感知能力的要求也高了很多。
第二,从工程化角度看,自动变道的可能场景更多了(当然,这个对算法的要求高了很多)。L2的ACC、AEB、TJA 等功能, 每个功能基准场景20个左右就能覆盖到绝大多数现实情况了。但是变道的场景就复杂多了,涉及多个车道,道路结构有多种可能,多个车道都可能有车,交通参与者变多,组合形式多样。枚举出200个以上意思的基准场景是完全可以做到的。更多的场景意味着要更多的数据、更严格的测试,这都是工程化的难度。
之所以还有个“人触发变道”功能,说白了就是功能太难做不出来,先做个简单的。人来判断变道的触发时机,这样就排除了大量场景,相应对感知算法到要求也被降低了。整体从算法到工程化的难度都降低了。
#### 3.8.1.2 工程化与数据驱动
我们使用本章的方法论,来看看“完全自动变道”功能进行工程化开发的方法。并与前文 AEB 的工程化方法相对照。
首先我们要分析出来涉及的各种算法,按照语义层级进行分割。按语义层级分割我们可以很方便的分析出哪些算法可以同时一起开发,高层级的算法可以使用仿真软件输出的低级语义。可以分析出算法需要的数据和真值,可以先通过仿真软件获取某些算法的数据集和真值。
图14中的所有算法基本上都会继续使用。为了换道,侧方的摄像头和毫米波雷达(一般是角雷达)是必须的,要观察后方来车,也需要后向的摄像头,以及后雷达。增加的算法至少有:
侧方和后方都需要有对应的视觉算法,完成目标识别、分类、跟踪等
基于前后摄像头、前后雷达、侧方摄像头和角雷达进行360度目标融合
车辆的行为预测和轨迹预测不再是可选的,而是必须的。
要根据其他车辆的当前轨迹和预测轨迹来规划自车的形行驶路径
控制车辆按照规划的路径行驶
原型阶段的扩展
我们对照图18来分析在“完全自动变道”功能下的扩展。
首先对A1进行扩展,原来的 A1主要是前置摄像头的视觉算法(目标检测和分类、目标跟踪、车道线识别、还有基于视觉的测速等等),现在要新增后向摄像头、侧方摄像头的视觉算法,也要涵盖前视视觉算法的内容,但是摄像头安装角度不一样,看到的数据风格还是有差别,需要补充这些角度的数据进行训练。不过T1和 T2环境一样可以为这部分开发进行服务。
A2是基于1级语义开发的算法。新功能下同样可以找出需要基于1级语义开发的算法,比如“选择对变道动作有影响的目标”,“360度目标融合”等等。
A3在 AEB 的例子中是直接使用1级语义的数据完成控制算法的开发。这个控制算法里面其实隐含了好几级算法步骤。先要根据两车的距离和相对速度计算出对本车的速度规划(一段时间内的速度变化),然后算出对应的加速度变化,再转成对刹车和油门踏板的控制执行。因为这几个阶段经常都是同时在一个算法模块里完成,所以常常放在一起称为控制算法。但在“完全自动变道”的案例中,A3应该会被拆解成明确的两个算法步骤“轨迹规划”(也有叫“路径规划”的)和“轨迹执行”,也有可能在具体算法设计时做更精细的拆解。但这两个步骤都同 AEB 例子的 A3一样,利用1级语义进行开发和测试,可以在 T2和 T3环境进行测试验证。
A4代表的是几个算法的局部串接,相对 AEB 案例,“完全自动变道”的案例的单体算法更多,在这一步可以设计更多的串接组合,但串接的基本原理和测试环境仍然是一致的。
A5是原型阶段的最终形态,经过前面的逐级开发和串联,到这一步从感知到控制执行全部闭环(运行时闭环)连接在一起。AEB 案例和完全自动变道案例只是功能复杂度不同,在开发过程中所属阶段和测试环境也是一致的。
两个案例在工程化阶段的分析与上文原型阶段的分析类似,这里不再赘叙。
场景的挖掘
相较于 AEB 案例,完全自动变道功能因为传感器更多,涉及的场景更复杂,相应数据规模也会大很多。传感器配置齐全专业采集车能提供丰富的感知数据用于训练。从这些数据中我们也能挖掘出自动变道的场景。
专业采集车采集数据的过程中,驾驶员也会存在变道的情况。编写相应的检索算法分析采集到的数据(例如:提取40公里以上速度时驾驶员拨转向杆,过段时间又拨正的场景,再进一步分析)。这些数据里至少提供了三个算法的真值:
变道的时机
变道的轨迹规划
变道的控制执行
这些数据可以作为工程化阶段开发的数据来源,人工或自动的方式提取场景信息。因为专业采集是各种传感器数据非常完备,我们甚至可以通过在 PiL 台架上回放数据,来验证我们判断变道时机的算法是否正确。数据回放时可以回放1级语义的数据,也可以回放0级语义的数据来把更多算法纳入到测试执行中。
同理,在配置了足够传感器的量产车辆上,我们可以为“完全自动变道”功能设置影子模式执行。可以在用户拨转向杆时,触发数据记录(包括拨杆前一段时间的数据),到用户拨正时结束。也可以在我们的算法认为应该触发转向时开始记录(这时候用户没有主动执行变道动作),但是不执行变道动作。这两种触发方式,前者可能是我们判断变道的时机过于保守,后者可能是过于激进。这些数据回传后都可以用于我们进行场景分析,调整算法的规则或阈值,发现感知算法的问题点等等。
较多数量的基准场景参数化后产生的庞大的特化场景,就需要轻量的云仿真来进行测试验证。这些设施我们在前面的 AEB 案例中已经就绪。
可以看到,虽然“完全自动变道”功能比 AEB 案例复杂很多,但是整个工程化的原理和工具是通用的。只是在横向纬度进行扩充,变得更“胖”了。如果我们在 AEB 开发中就建立好了这一整套工程化设施,就能为新的功能开发带来便利,在架构一致的前提下在量的维度进行扩充。
3.8.2 Level 4的工程化
有了前面 AEB 和完全自动变道两个例子,我们再来看Level 4 自动驾驶的工程化之路也就会比较清晰了。
Level 4 自动驾驶在原型阶段,对应与图18的A1、A2的部分(0->1级语义提升和基于1级语义的算法,1->2级语义提升)依然存在。但是涉及的传感器更多,对应与这个阶段的算法也会更多,这需要算法专家根据具体的传感器配置和整体的算法架构去规划。不过这个步骤对应的测试环境依然可以是图中的 T1、T2。
对应与 A3的部分,与完全自动变道功能一样,也要拆分为“规划”与“执行”两个部分。但是规划部分的复杂度会远远超过自动变道功能中的实现。因为场景的空间范围、时间跨度、交通参与者的类型和数量都有很大的扩充。如何对这个阶段的“规划”与“执行”进行定义、设计和实现,是 Level 4自动驾驶的一个关键技术难点。但是其测试环境依然可以基于T2、T3来进行。(我在另一篇文章《智能驾驶域控制器的软件架构及实现(下)》的4.3节,叙述了一个多级规划与执行的机制,可以参考,有助于理解这一部分的复杂度)。
在工程化阶段的实现机制依然跟前面两个例子一样,但是单体算法和局部闭环的数量会多很多,需要逐个设计其测试方式。测试环境依然是 T4~T7。
但是在量产阶段,Level4自动驾驶跟之前的例子就会有很大不同。
一方面L4的影子模式是不能简单的在量产车上部署的。因为量产的 Level4车辆没有驾驶员,所以算法必须执行所有的控车任务,不能像之前例子一样,只触发数据记录,不具体控车。也就是说出了事故之后的“漏报”数据可以记录并回传,但是没法用影子模式解决“误报”问题。解决的办法就是在量产之前有很长一段时间,使用人类安全员坐在驾驶位上,随时准备“接管”车辆。“接管”动作本身就是一个数据记录的触发器。
另一方面,云端的并行仿真变得极为重要,不可替代。前面 AEB 和自动变道的例子中,云端并行仿真如果没有,基本上也能完成开发,只是测试不充分。但是在 Level4中却是必不可少的。同时功能上不仅仅是简单的复现预设的场景,还要能让场景中除了自车之外的交通参与者也具备一定智能,这样才能主动生成无限的场景组合。才能以低成本的方式通过仿真积累数十亿公里的驾驶里程,发掘更多的长尾场景。
这两个方面都在我们图18的量产阶段中都有定义,但是规模大小又上了一个数量级。我们可以看到 Level 4 自动驾驶的工程化原理依然是与之前示例一样的,但是数据规模比 L2和 L2.5功能的工程化有了数量级上的提升。
正因为这个阶段是 Level4自动驾驶工程化的必经路径,所以当我们看到路上带安全员的Level4的车辆在运行时,并不意味着其 Level4驾驶能力就很好了,也可能只是刚刚开始。这个阶段的开发投入巨大,也需要很长时间点积累,对数据驱动闭环的IT 基础设施和工具链都有很高的要求。
3.9 升维还是降维
自动驾驶领域人们常讨论的一个问题是“升维还是降维?”。也就是说是从Level1、Level2开始逐步升级到 Level4以上的自动驾驶能力;还是反过来,先具备 Level4的技术能力,然后消减功能和硬件配置,以较低成本向下实现功能量产。
这一节我们从工程化的角度对此问题进行分析。
3.9.1 自动驾驶的核心技术
自动驾驶的核心技术是什么,我的总结是两个,算法能力和工程化能力。
算法能力涵盖了各种传感器感知算法、融合算法、定位算法、规划算法以及控制执行算法等。感知算法又与相应的传感器技术密切相关。考核算法能力的基本目标就是能完整原型阶段的完整运行时闭环,也就是图 18中的 A5。这个阶段验证了预期功能在原型系统上的可行性。
工程化能力决定了预期功能是否可以从原型车走向大规模量产。搭建一个自动驾驶原型车和大规模量产的工程难度完全不在一个数量级。原型车我们可以不计成本(毕竟数量少),用高配的硬件设备,对可靠性要求也不高,反正随时出问题可以随时去解决。原型车也不用管AEC-Q100等规范要求,天气冷的地方别去,天热了拉一个空调排风口到后备箱就行。但是量产车辆要控制成本,一辆车的寿命是10多年,对零部件长生命周期的可靠性的要求非常高,否则车辆召回会带来重大的经济损失。在中国销售的车辆,必须能适应南北气候的不同,东北零下30度的气温,大多数原型车都会趴下。
3.9.2 工程化能力的体现
自动驾驶的工程化的能力至少可以现在以下几个方面:
硬件系统的工程化
软件工程化
测试工程化
数据工程化
与车辆工程的集成
如果进行更专业的仔细分析,还能有更多。同时还需要一系列用来满足这些工程化能力的工具链体系。
硬件系统的工程化的体现最典型的就是一系列汽车零部件的质量标准,抗振的标准、电磁兼容性标准、散热的标准等等,我们常说的 AEC-Q100标准是对集成电路的,包含了对芯片的七个大类别共45项各种类型的测试。现在自动驾驶的计算平台已经妥妥地是一台高性能计算机了,板级的精密度已经接近智能手机了,实际对设计和工艺的复杂度比手机还高。这样一个设备要在车上颠簸10年以上,还要保证高可靠性,这在汽车行业也是从来没有过的事情。
相比硬件工程化还有很多硬性标准可以度量,软件的工程化更难度量。软件不比硬件,有时候质量差一些,功能一样能正常运转,只是问题被掩盖的更深。而软件的工程化,从需求管理和跟踪、概要设计和详细设计到编码实现和测试,是需要一系列的文档体系去管控研发过程的。常用的度量软件工程化的手段如 ISO9000标准、CMMI 能力成熟度认证、功能安全过程认证,也是在检查这些文档。
自动驾驶和智能座舱之外车载软件,功能复杂度和整体的代码量其实要低两个数量级,还有可能完全按照规范要求完成全部文档化跟踪。但是自动驾驶相关软件如果严格文档化,导致的研发周期拖长几乎是不可接受的。直接结果就是有人写文档就没人编码了。这也导致了软件的工程化建设更为困难。
所以自动驾驶的软件工程化要在质量和效率之间做平衡。这个平衡不是说牺牲质量换效率,而是说对于这些创新技术的研发,要在研发初期重效率,然后逐步提高对质量的管控能力,而不是一开始就要质量标准卡着软件研发无法寸进。这也是考验每一个自动驾驶软件研发团队进行工程化量产开发的难点。
关于测试的工程化,前文图 18基本上都是讲这方面,不再赘述。
数据工程化较少被提及,算法研究时一般都是基于处理得非常规整的数据进行。但是现实中我们用专业采集车采集的数据规模庞大,充斥着大量无效、重复的数据。要找到对我们算法改进有用的数据并非易事。我们会在后续文章中对此进行讨论、
3.9.3 影响工程化难度的因素
哪些因素会影响自动驾驶工程化的难度呢。
速度快慢
车速一旦慢下来,实时性要求就会被降低,很多软硬件的要求就会被降低了。工程化难度就会下降。比如自动清洁车5-10km 的时速,那对感知算法的帧率要求可以降低到每秒15帧(每帧行进距离不到20厘米)。软件也不用基于高实时的操作系统和中间件,用 ROS就完全可以满足。
载人与否
如果不载人,很多为了功能安全的设计就可以大大简化。行驶也不需要考虑人的舒适性,控制算法开发也可以得到简化。典型的如清洁车、洒水车、无人矿车、无人农用车、无人卡车等。
成本高低
如果量产车能承受较高的成本,自动驾驶系统的工程化难度也能降低。比如一辆无人重卡售价可能到上百万,那么10万元一套的自动驾驶系统就是可以接受的。但是15万左右的乘用车,可能就需要把成本压缩到2万以内甚至更低,还要达到工程化就难了。
应用场景
应用场景应该是对工程化难度影响最大的。前文谈到,从 Level2.5功能开始,场景的复杂度大大增加,到 Level4,会有无数的长尾场景需要被发掘和适配,所以对数据驱动有着非常现实的要求。
我们也可以换一个思路,如果不能挖掘出所有的长尾场景,那就把这些场景消灭掉。所以我们看到封闭园区的 L4低速摆渡车、城市固定路线的大巴车、封闭园区内固定线路的矿车、港口的无人卡车、封闭农场的农用车等等。这些场景通过“封闭园区”、“固定线路”的方式圈定了可能出现的交通场景的范围,以此来降低工程化过程的难度。
3.9.4 升维 vs 降维
核心算法的难度和工程化难度是实现自动驾驶的关键难点。图23将常见的自动驾驶产品(或应用场景)在这两个纬度上进行了一个分布,便于比较。这只是一个粗略的示意图,两个轴也没有精确到比例尺含义,仅仅是相对位置提供一点参考意义。
我们可以看到,Robotaxi是在两个纬度上都是最难的。在原型阶段实现各种算法能力已经很不容易了,要到大规模量产应用还要克服很多工程化的难题。正因为这样,以 Robotaxi 为目标的开发团队,要么做到原型阶段就很难继续,要么在努力工程化的过程中,通过自主研发或整合其它工具,构建了最完善的自动驾驶研发工具链体系。
很多企业为了能尽快具备量产能力,也会选择先专注于工程化难度较低的应用场景。比如无人矿车、封闭园区的无人巴士等。
已经有L4研发能力的企业,希望能把L4研发过程中建立的技术能力用来进行 L2.5~L3级别的开发,实现“降维打击”。
 图 23 两个纬度的自动驾驶产品分布
图 23 两个纬度的自动驾驶产品分布
老牌的 Tier1企业,因为具备了比较丰富的 L1/L2的工程化经验,往往会选择以 L2研发能力为出发点向右上方攀登,与降维对应,一般称为“升维”。究竟谁更能成功呢,众说纷纭。
其实从本文重点突出的工程化角度来看,“升维”和“降维”之争很容易就能分辨清楚。
对于具备了 L1/L2工程化量产能力的企业来说,如果在开发过程中并没有建立起本文所说的数据驱动的工程化体系(图18所描述的全套环境和工具链),那么它在走向高阶自动驾驶的过程中将面临两个纬度的挑战,之前工程化能力在新的挑战中有作用但作用有限。典型的,就是之前基于黑盒子芯片加感知算法来实现 L2功能的团队。反之如果在 L2的研发中建立了完善的基于数据驱动的工程化工具链,那么就是需要重点突破算法能力,工程化能力是在“量”上进行扩充,难度相对较小。
对于具备了 L4开发能力的团队,如果仅仅是搭建了几台原型车,能在有限区域中做一些演示。没有完善的工程化能力和工具链,即便做L2/L3 量产开发,也没有明显的优势。反之如果在 L4的开发中,建立了完整的数据驱动的工具链并且采集了大量的数据。那么在转而开发低阶自动驾驶功能时,一方面算法难度会降低,一方面可以从已经采集的数据中挖掘有用的数据,工程化的工具链体系也是现成的,这样才具有“降维打击”的能力。反而是要在成本控制上做更多的努力。
所以不是简单的“升维”和“降维”,要看具体的两方面技术能力的储备。
3.9.5 自动驾驶的路权
有些地方开始有无人的有轨电车(上海张江线,成都璧山云巴),这些场景逐渐可以被无人驾驶的大巴来实现。这里面其实隐含了一个路权的问题。从有轨车辆中我们比较容易观察到路权的作用。
高铁作为有轨车辆独占了路权,城市的有轨电车是跟其它车辆共享路权,但是有轨电车有优先权。乘用车的 Level4特别是 Robotaxi 之所以会产生大量的长尾场景,就是因为自动驾驶车辆在和人类驾驶的车辆在平等地共享路权,某些情况下甚至是在争抢路权。虽然有交通规则存在,但是这个规则过于宽泛。比如交通规则只会规定两个车道直接是否可以变道。但是什么情况下变道却是人独立做出判断,每个人的驾驶习惯都可能不同。所以人的行为的太多可能性导致了场景的复杂度。
从路权的角度看,那就把自动驾驶车辆的路权和人类驾驶车辆的路权分开就好了。封闭园区就是自动驾驶车辆独占了路权、固定线路是没有铺设物理轨道的“有轨”,实质是提高了该路线自动驾驶车辆的路权优先级。如果在这些自动驾驶车辆具备路权优势的道路上部署路侧的传感器和 AI 能力,给车辆提供环境信息,一方面能减少车辆的成本,另一方面车跟路就能协同工作。场景的复杂度进一步降低,意味着工程化难度也被降低。
所以,从工程化落地的现实角度看,自动驾驶的发展很大程度上将会是自动驾驶车辆对人类驾驶车辆在路权上的挤出,先有部分道路只允许自动驾驶车辆运行,最后发展到把人类驾驶的车辆彻底赶出去。就像汽车赶走了马车一样。
在当前火热的自动驾驶发展过程中,工程化能力确实不如核心算法那么耀眼夺目,但它确实是自动驾驶技术真正走进人们生活的关键难点。负责工程化的大量工程师们可能没有算法科学家、算法专家那样崇高的头衔和漂亮的履历,但他们确实是在一点点的克服各种工程难题,让自动驾驶技术早日走进现实。好比在新冠疫情中,特效药和疫苗代表核心算法,隔离管控、流调等管理手段代表工程化,两者都要做好、互相配合才能得到最完美的结果。
9全文结语
本文先论述了自动驾驶的研发闭环和产品闭环,在此基础上继续论述了数据驱动闭环的基本原理以及自动驾驶工程化的方法论。
我们知道,自动驾驶是一个庞大的产业链,从第2章的图11中的各层子产品角度看,每个子产品方向背后就可能有很多不同的公司在开发。同样,图18中的各种工程化工具链也有各种供应商。
有的企业可能擅长原型阶段的算法研究,但是在工程化落地方面缺少资金、数据和经验;有的企业可能对 Level2方面有很好的工程化经验,但是对 Level2.5 及以上的技术缺少算法积累。汽车 OEM 有资金上的优势和理论上最好的数据采集通道(量产车),但是在如何构建整套IT 系统并利用数据上缺少经验;以算法起步的企业有较好的算法研究能力却缺少足够多数据来源。所以产业链上下游的紧密合作才能有利于自动驾驶系统真正的走向工程化落地。
目前自动驾驶行业内都非常强调“自研”或者“全栈自研”。排除掉宣传因素来看,一个企业完成所有的技术栈和工具链是不现实的,或许只有极少数企业能够覆盖到大多数的技术栈。一方面技术积累和团队培养的时间周期会很长,会在竞争中失去先机;另一方面整个行业的人才资源也不足以支持这么多企业去完成“全栈自研”。
所以,从 Tier2,Tier1到 OEM,每个企业都应该找到适合自己的“自研”之路。芯片企业最熟悉自己芯片的 AI 能力,可以开发基础的算法以及算法模型转换到工具链;擅长硬件设计的企业可以使用合适的芯片做出计算平台并集成好操作系统,以硬件 Tier1 的身份向多家 OEM 提供硬件计算平台或域控制器。软件 Tier1开发完整的功能适配不同的硬件平台,同硬件 Tier1 合作向 OEM 完成功能交付。OEM 可以把自主研发的重点放在工程化能力的建设上(图18中的工程化阶段和量产阶段),这部分需要大量的投资以建立数据驱动的能力,而数据通道本来就是 OEM 的固有优势。OEM 另外要重视的是数据如何能够被充分的利用,自己使用的同时开放给算法企业和软件 Tier1使用。而这些也可以通过多方计算、联邦学习之类的技术实现,将会在后续文章中介绍。
10预告
根据本文的论述,我们可以看到其中涉及了非常庞大规模的数据,10PB 级别也是刚刚起步;涉及大量人工智能算法的训练;涉及多层次各种目的的仿真测试;需要全面的自动化的 DevOps 系统进行高效率研发和测试。这些都要求有一个坚实的 IT 基础设施来支持。本文的姊妹篇《数据闭环的 IT 基础设施》仍在写作中,将重点对此进行论述。敬请期待!
PDF 版本请点赞后从此链接下载 。当然,不点赞也能下 :)
链接:https://pan.baidu.com/s/1igDy6PG51Fv6ety2ReNMQA?pwd=3oz4
提取码:3oz4
图21 高清版本:
链接:https://pan.baidu.com/s/1Y_wvfTLyHjEFTJO_eJ687Q?pwd=i54c
提取码:i54c
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码免费学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、Occupancy、多传感器融合、大模型、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)
