ELK 分离式日志
目录
一.ELK组件
ElasticSearch:
Kiabana:
Logstash:
可以添加的其它组件:
ELK 的工作原理:
二.部署ELK
节点都设置Java环境:
每台都可以部署 Elasticsearch 软件:
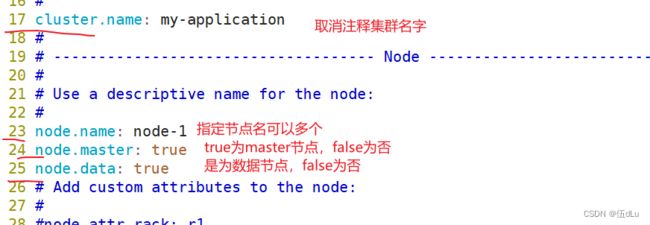
修改elasticsearch主配置文件:
性能调优参数:
修改内核参数文件:
访问页面查看节点信息及状态:
每台安装 Elasticsearch-head 插件:
安装 phantomjs:
安装 Elasticsearch-head 数据可视化工具(安装一个节点):
安装依赖包:
修改 Elasticsearch 主配置文件(10,20,30节点):
启动 elasticsearch-head 服务:
访问页面:
插入索引:
通过命令插入一个测试索引,索引为 index-demo,类型为 test:
浏览器访问 http://192.168.80.10:9100/ 查看索引信息:
ELK Logstash 部署(在 web 节点上操作):
安装logstash:
测试 Logstash:
使用 Logstash 将信息写入 Elasticsearch 中:
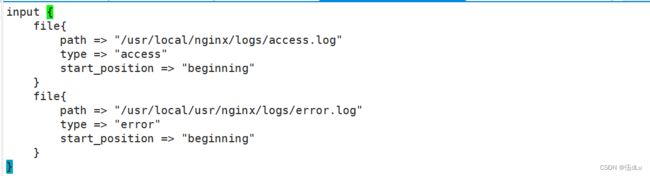
修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中:
创建目录:
切换到目录:
添加文件内容:
ELK Kiabana 部署(30节点上操作):
安装 Kiabana:
设置 Kibana 的主配置文件:
创建日志:
验证 Kibana:
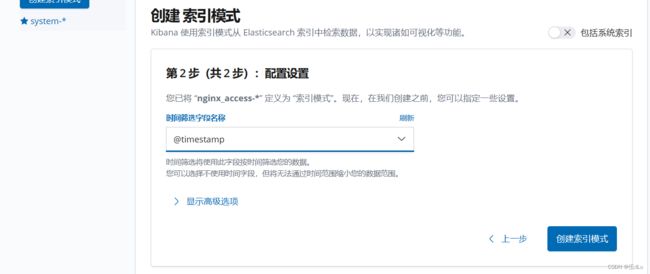
创建索引:
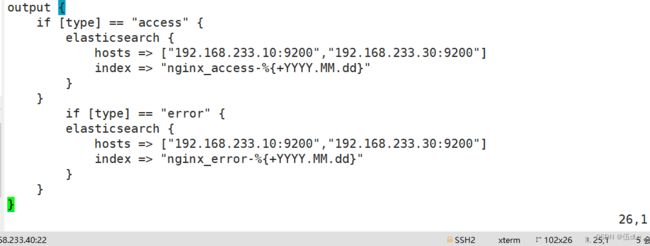
将nginx服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示:
到kibana目录下添加文件内容:
一.ELK组件
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。
ElasticSearch:
是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
Kiabana:
Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
Logstash:
作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
可以添加的其它组件:
Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进行解析,或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。
filebeat 结合 logstash 带来好处:
1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
4)使用条件数据流逻辑组成更复杂的处理管道
缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
ELK 的工作原理:
Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
Elasticsearch 对格式化后的数据进行索引和存储。
Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理。
二.部署ELK
先准备三台服务器,192.168.233.(10..30),其中30为web网页服务器,
节点都设置Java环境:
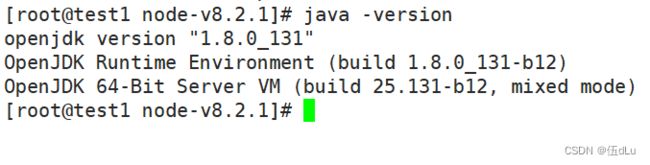
如果没有安装则下载:yum -y install java。
每台都可以部署 Elasticsearch 软件:


修改elasticsearch主配置文件:
![]()



查看信息:
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
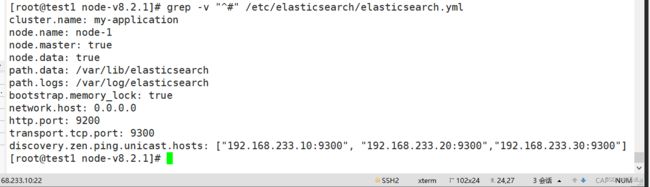
其他节点:

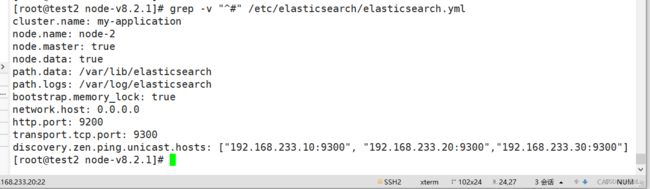

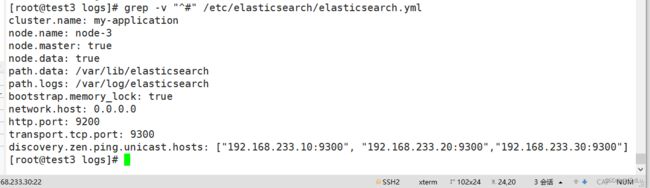
性能调优参数:

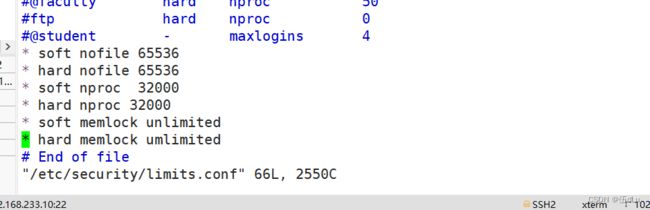

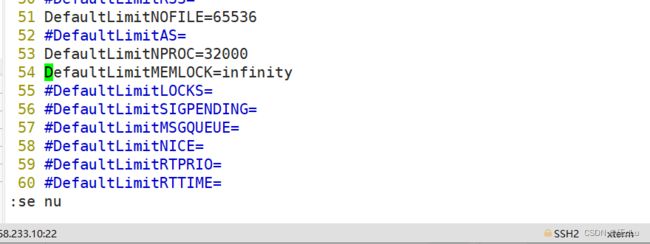 需重启生效:
需重启生效:

修改内核参数文件:




启动elasticsearch是否成功开启:



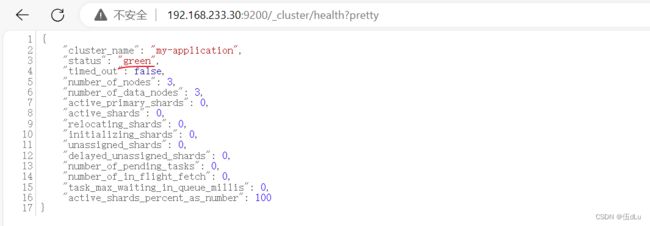
访问页面查看节点信息及状态:
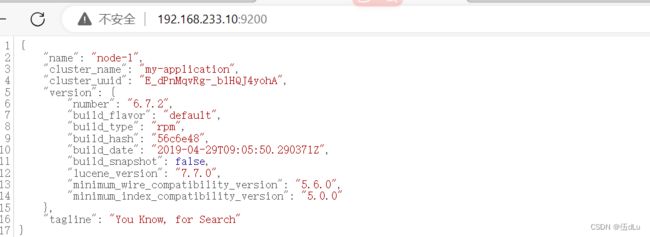
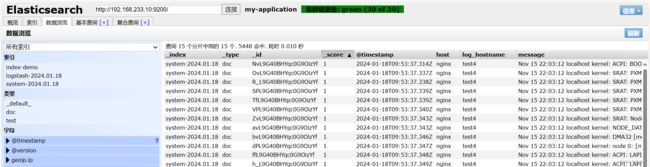
状态,查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行:
http://192.168.233.10:9200/_cluster/health?pretty

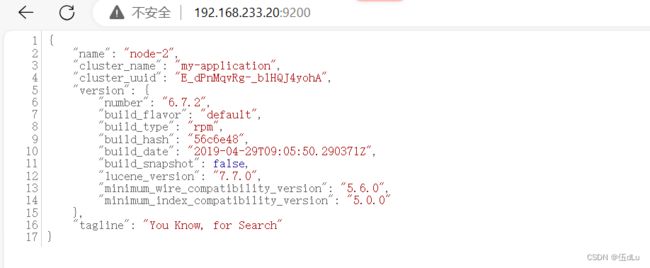
状态:


状态:
每台安装 Elasticsearch-head 插件:
上传软件包 node-v8.2.1.tar.gz 到/opt,并解压:


编译安装:


安装 phantomjs:
上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到/opt,并解压:
![]()

将命令复制到环境变量下:

安装 Elasticsearch-head 数据可视化工具(安装一个节点):
上传软件包 elasticsearch-head-master.zip 到/opt:

unzip elasticsearch-head-master.zip

安装依赖包:

修改 Elasticsearch 主配置文件(10,20,30节点):
http.cors.enabled: true
http.cors.allow-origin: "*"
10节点:
![]()
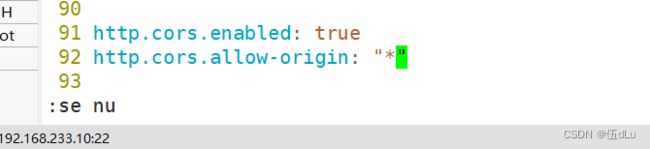

20节点:

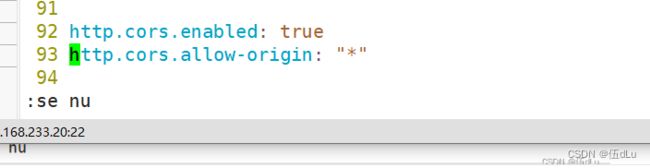

30节点:


重启:

启动 elasticsearch-head 服务:
必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
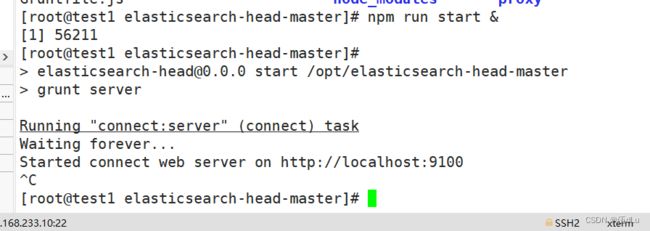

访问页面:

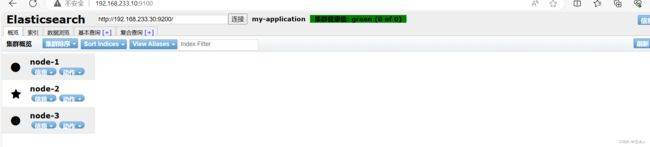
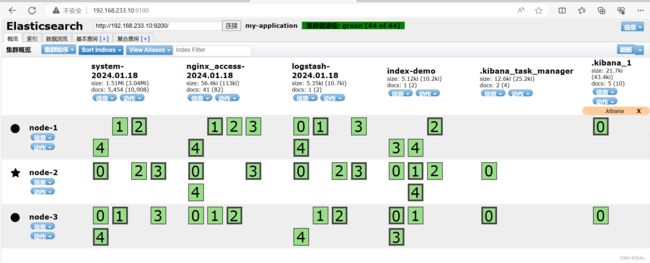
通过 Elasticsearch-head 查看 Elasticsearch 信息:看到群集健康值为 green 绿色,代表群集很健康。

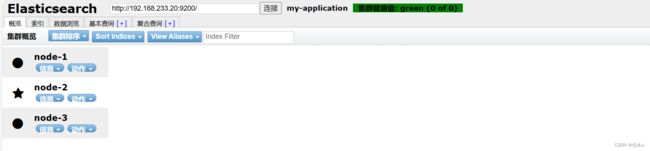
插入索引:
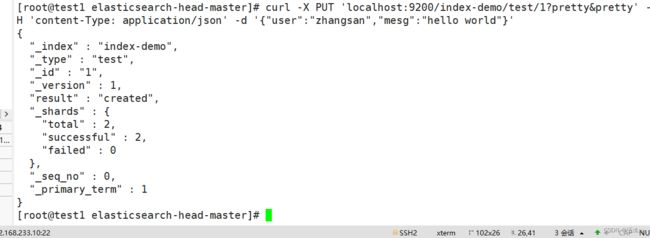
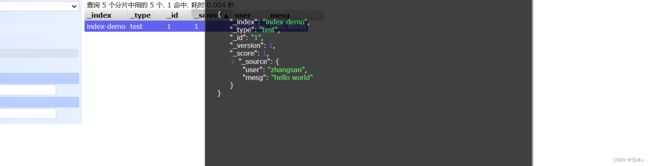
通过命令插入一个测试索引,索引为 index-demo,类型为 test:
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
浏览器访问 http://192.168.80.10:9100/ 查看索引信息:
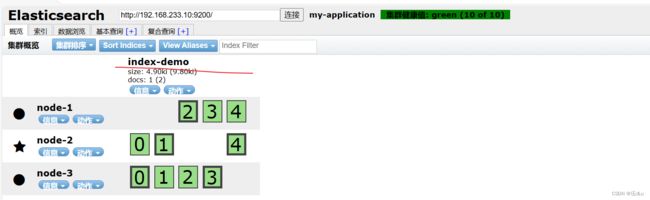
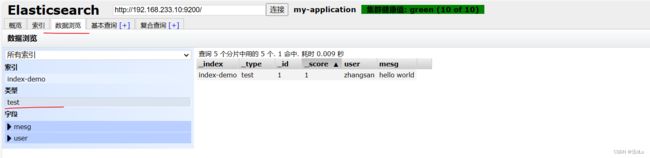
可以看见索引默认被分片5个,并且有一个副本。点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息:
ELK Logstash 部署(在 web 节点上操作):
Logstash 一般部署在需要监控其日志的服务器:
开启40节点安装nginx,并启动:

更改主机名:
hostnamectl set-hostname nginx

添加页面测试页面:





安装logstash:
上传软件包 logstash-6.7.2.rpm 到/opt目录下:
编译:
rpm -ivh logstash-6.7.2.rpm

让logstash能够补全:
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/

设置自启:

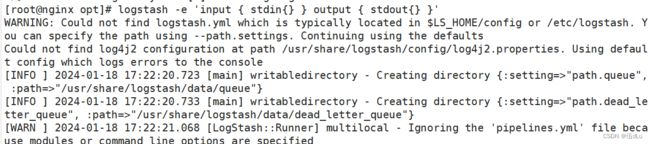
测试 Logstash:
logstash -e 'input { stdin{} } output { stdout{} }'

键盘输入内容:

使用 Logstash 将信息写入 Elasticsearch 中:
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.233.10:9200"] } }'
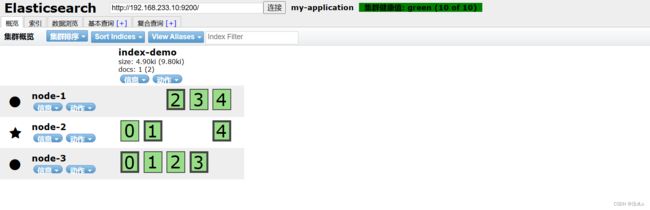
看下10节点的数据:
在40节点上输入内容:

再看下10节点 :


修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中:

chmod +r /var/log/messages

cd /etc/logstash

创建目录:
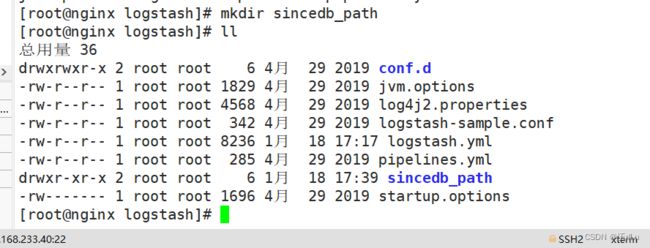
创建日志文件:
touch log_progress
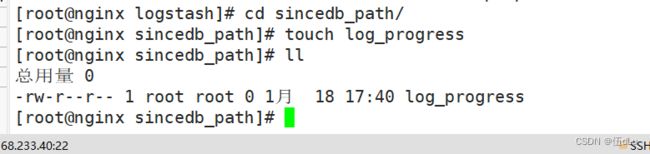
授用户权限:
chown logstash:logstash /etc/logstash/sincedb_path/log_progress

切换到目录:
cd /etc/logstash/conf.d/

关闭logstash服务:

添加文件内容:
vim system.conf



logstash -f system.conf


查看下esWeb页面:

ELK Kiabana 部署(30节点上操作):
安装 Kiabana:
上传软件包 kibana-6.7.2-x86_64.rpm 到/opt目录

rpm -ivh kibana-6.7.2-x86_64.rpm

设置 Kibana 的主配置文件:
vim /etc/kibana/kibana.yml






创建日志:
touch /var/log/kibana.log

授权:
chown kibana:kibana /var/log/kibana.log

开启服务:
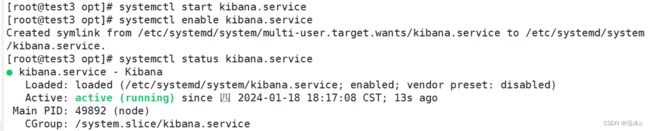

验证 Kibana:
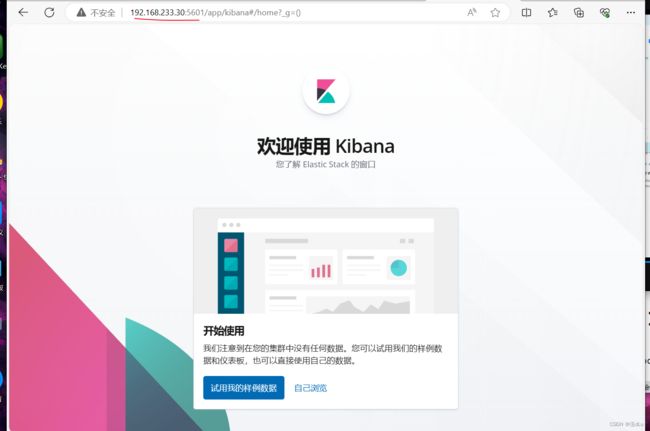
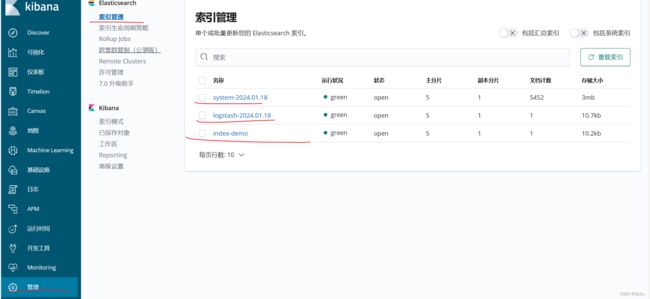
可以管理索引:


创建索引:
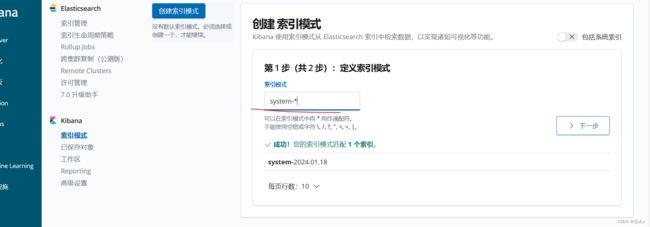

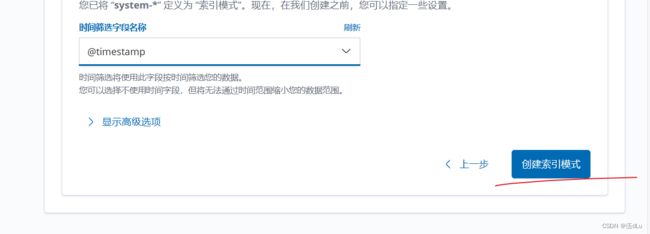
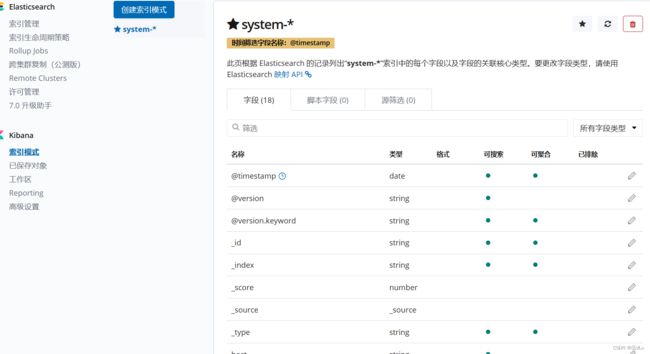

将nginx服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示:

到kibana目录下添加文件内容:


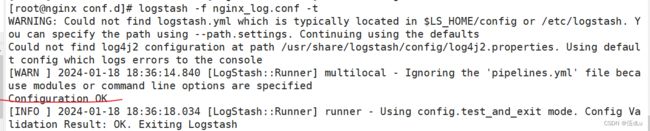

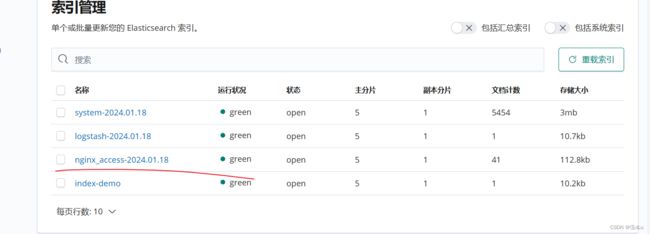

创建成功日志: