Hadoop RPC Server基于Reactor模式和Java NIO 的架构和原理
文章目录
- 前言
- Java NIO简介
- Reactor设计模式详解
-
- 1.Reactor设计模式概览
- 2.RPC总服务启动
- 3.Listener
- 4.Reader
- 5.Handler
- 6.Responder
- 结束
前言
Hadoop RPC远程过程调用的高性能和高并发性是Hadoop高性能、高并发性的根本保证。尤其是作为Master/Slave结构的Hadoop设计,比如HDFS NameNode 或者 Yarn ResourceManager这种master类型的节点,它们以RPC Server的身份,需要并发处理大量的RPC Client请求,比如,Yarn的ResourceManager,需要处理来自NodeManager、ApplicationMaster的基于各种协议的RPC请求,这些请求并发、随机且请求量巨大,ResourceManager必须做到高并发和稳定性。那么,ResourceManager基于怎样的设计,才达到了这样的需求呢?
Hadoop的RPC服务端的核心实现是ipc.Server, 这是一个抽象类 ,但是已经实现了RPC Server的所有运行角色,唯一抽象方法是call(),用来进行最后的请求处理,显然,实际的处理需要交付给具体的ipc.Server的实现类进行处理,各个请求处理方式不同。
ipc.Server基于Reactor设计模式,是RPC Server高效的根本原因。
Java NIO简介
Java NIO(New I/O,即新的I/O)是Java在1.4版本中引入的一组处理非阻塞I/O操作的API。与传统的Java I/O(即Java IO或Java Classic I/O)相比,Java NIO提供了更为灵活和高效的I/O操作方式。
以下是Java NIO的一些关键概念和特点:
-
通道(Channel): 通道是Java NIO中新引入的抽象,代表着一个连接到实体如文件或套接字的开放连接。与传统的Java IO不同,通道可以同时进行读和写操作,支持非阻塞I/O。
-
缓冲区(Buffer): 缓冲区是一个对象,用于在通道和应用程序之间传输数据。所有数据都是通过缓冲区进行读写的。缓冲区提供了一种更灵活的方式来处理数据,支持直接(Direct)和非直接(Non-Direct)两种类型。
-
选择器(Selector): 选择器是Java NIO的一个重要组件,用于实现非阻塞I/O。一个选择器可以同时监控多个通道的I/O事件,例如可读、可写等。通过选择器,一个线程可以有效地管理多个通道,提高系统的可伸缩性。
-
非阻塞I/O(Non-blocking I/O): 与传统的阻塞I/O不同,Java NIO提供了非阻塞I/O的支持。在非阻塞模式下,一个线程可以处理多个通道,不需要等待I/O操作完成。这使得程序能够更有效地利用系统资源。
-
通道之间的传输(Channel-to-Channel Transfer): Java NIO支持直接在通道之间进行数据传输,而不需要通过中间缓冲区。这可以提高数据传输的效率。
Java NIO主要用于构建高性能的网络应用程序,例如服务器和客户端。它提供了一种更为灵活、可扩展和高效的I/O编程方式,适用于处理大量连接的情境。
所以,必须清楚,非阻塞IO(Non-Block IO)只是Java NIO的一种工作方式。我们可以基于NIO实现阻塞和非阻塞两种不同的工作模式:
阻塞模式的Java NIO代码如下:
public class BlockingSocketChannelExample {
public static void main(String[] args) {
try {
// 创建 SocketChannel,并连接到服务器
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("localhost", 8080));
// 发送数据
String message = "Hello, Blocking SocketChannel!";
ByteBuffer buffer = ByteBuffer.wrap(message.getBytes());
socketChannel.write(buffer);
// 接收数据
ByteBuffer receiveBuffer = ByteBuffer.allocate(1024);
int bytesRead = socketChannel.read(receiveBuffer);
if (bytesRead > 0) {
receiveBuffer.flip();
byte[] data = new byte[bytesRead];
receiveBuffer.get(data);
System.out.println("Received data: " + new String(data));
}
// 关闭 SocketChannel
socketChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
非阻塞模式下的Java NIO如下所示:
public class NonBlockingSocketChannelExample {
public static void main(String[] args) {
try {
// 创建 SocketChannel,并连接到服务器
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false); // 设置为非阻塞模式
socketChannel.connect(new InetSocketAddress("localhost", 8080));
// 创建 Selector,并注册 SocketChannel 到 Selector 上,关注 Connect 事件
Selector selector = Selector.open();
socketChannel.register(selector, SelectionKey.OP_CONNECT);
// 循环等待就绪事件
while (true) {
if (selector.select() > 0) {
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isConnectable()) {
// 完成连接
SocketChannel channel = (SocketChannel) key.channel();
if (channel.finishConnect()) {
System.out.println("Connected to server: " + channel.getRemoteAddress());
// 关注可写事件
channel.register(selector, SelectionKey.OP_WRITE);
}
} else if (key.isWritable()) {
// 可写事件,发送数据
SocketChannel channel = (SocketChannel) key.channel();
String message = "Hello, Non-blocking SocketChannel!";
ByteBuffer buffer = ByteBuffer.wrap(message.getBytes());
channel.write(buffer);
// 关注可读事件
channel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 可读事件,接收数据
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer receiveBuffer = ByteBuffer.allocate(1024);
int bytesRead = channel.read(receiveBuffer);
if (bytesRead > 0) {
receiveBuffer.flip();
byte[] data = new byte[bytesRead];
receiveBuffer.get(data);
System.out.println("Received data: " + new String(data));
}
// 关注可写事件
channel.register(selector, SelectionKey.OP_WRITE);
}
keyIterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
在阻塞模式下,SocketChannel 的 write 和 read 方法是阻塞的,会一直等待数据的发送和接收。
在非阻塞模式下,通过设置 configureBlocking(false) 将 SocketChannel 设置为非阻塞模式。在非阻塞模式下,connect() 方法也是非阻塞的,可能在连接未完成时返回。因此,在非阻塞模式下,我们需要使用 Selector 进行事件的轮询。在示例中,我们关注 OP_CONNECT 事件,一旦连接完成,我们发送数据,并在可读事件时接收数据。整个过程是异步的,不会阻塞线程。
Reactor设计模式详解
1.Reactor设计模式概览
先来看看标准Reactor设计模式的构成:
Reactor模式的基本组成:
- Reactor:I/O事件的派发者
- Acceptor:接收来自Client的连接,建立与Client对应的Handler,并向Reactor注册Handler
- Handler:与Client进行通信的通信实体,按照一定的过程实现业务处理。Handler内部往往会有更进一步的层次划分,用来抽象reader、decode、compute、encode、send等过程。由于业务处理流程可能会被分散的I/O过程打破,所以Handler需要有适当的机制保存上下文,并在下一次I/O 到来的时候恢复上下文。
- Reader/Sender:为了加速数据处理,Reactor设计模式会构建一个存放数据处理线程的线程池。数据读出以后,立即扔给线程池即可。因此, Handler中的读和写两个事件被单独分离出来, 由对应的Reader和Sender进行单独处理。
这是Reactor模式的通用角色,在ipc.Server中的Reactor模式的具体实现与之非常相近:
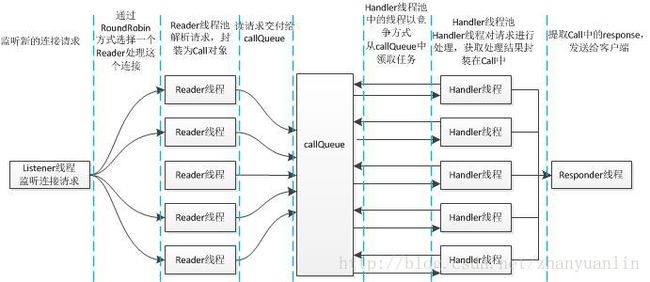
- Listener线程:单线程,负责创建服务器监听,即负责处理SelectionKey.OP_ACCEPT事件,一旦对应事件发生,就调用doAccept()方法对事件进行处理,处理方法其实只是将对应的channel封装成Connection,Reader.getReader()负责选出一个Reader线程,然后把这个新的请求交付给这个Reader对象(添加到这个对象的pendingConnections队列)。getReader()选择Reader线程的方式为简单轮询。
- Reader线程:多线程,由Listener线程创建并管理,通过doRunLoop()方法,反复从自己的pendingConnections 中取出连接通道,注册到自己的readSelector,处理SelectionKey.OP_READ事件,一旦对应事件发生,则调用doRead()进行处理。doRead()的实际工作,是从请求头中提取诸如callId、retry、rpcKind,生成对应的Call对象,放入callQueue中,callQueue 队列将由Handler进行处理。
- Call对象:封装了RPC请求的信息,包括callId、retryCount、rpcKink(RPC.rpcKind)、clientId、connection信息。Reader线程创建了Call对象,封装了请求信息,交付给下面的Handler线程。此后,信息在Reator的不同角色之间的传递都封装在了Call对象中,包括请求、响应。
- Handler线程:Handler的总体职责是取出Call对象中的用户请求,对请求进行处理并拿到response,然后将response封装在Call中,交付给Responder进行响应。
- Responder线程:单线程,内部有一个Selector对象,负责监听writeSelector上的SelectionKey.OP_WRITE,将response通过对应的连接返回给客户端。后面我会详细介绍到,并不是所有的写都是Responder进行的,有一部分是Handler直接进行的:Handler在将响应交付给Responder之前,会检查当前连接上的响应是否只有当前一个,如果是,就会尝试在自己的当前线程中直接把响应发送出去,如果发现响应很多,或者这个响应无法完全发送给远程客户端,才会将剩余任务交付给Responder进行。
为了更好了解各个不同角色的分工,我们从源代码入手,来分析各个角色都干了什么。
2.RPC总服务启动
我在多篇博客中都提到了Hadoop的服务化设计思想,即把某些功能模块抽象为服务,进而抽象出init()、start()、stop()等方法,同时,某个服务还有多个子服务,某个服务启动的标记,是所有子服务启动完毕。ipc.Server也被抽象为服务,通过start()方法启动服务,即启动Responder子服务、Listener子服务和Handler子服务:
/** Starts the service. Must be called before any calls will be handled. */
public synchronized void start() {
//Responder、Listener和Handler都是线程,start就是调用Thread.start()启动线程
responder.start();
listener.start();
handlers = new Handler[handlerCount];
for (int i = 0; i < handlerCount; i++) {
handlers[i] = new Handler(i);
handlers[i].start();
}
}
3.Listener
Listener直接定义为ipc.Server的内部类,因为这个类只会被ipc.Server所使用到。
public Listener() throws IOException {
address = new InetSocketAddress(bindAddress, port);
// Create a new server socket and set to non blocking mode
acceptChannel = ServerSocketChannel.open();
acceptChannel.configureBlocking(false);
// Bind the server socket to the local host and port
//将channel绑定到固定到ip和端口号
bind(acceptChannel.socket(), address, backlogLength, conf, portRangeConfig);
port = acceptChannel.socket().getLocalPort(); //Could be an ephemeral port
// create a selector;
selector= Selector.open();
readers = new Reader[readThreads];
for (int i = 0; i < readThreads; i++) {
Reader reader = new Reader(
"Socket Reader #" + (i + 1) + " for port " + port);
readers[i] = reader;
reader.start();
}
// Register accepts on the server socket with the selector.
//在当前这个server socket上的selector注册accept事件
acceptChannel.register(selector, SelectionKey.OP_ACCEPT);
this.setName("IPC Server listener on " + port);
this.setDaemon(true);
}
从代码里面可以看到,Hadoop RPC的网络通信基于java NIO构建。NIO的显著特性,就是用有限的或者很少的线程,实现大量的网络请求的同时处理,网络请求处理的效率很高。
Listener的构造方法主要负责RPC客户端的建立连接请求 ,创建请求通道,让selector在这个channel上 注册SelectionKey.OP_ACCEPT事件,也就是建立连接请求都会被Listener线程处理。Listener是一个Thread , run()方法为:
public void run() {
LOG.info(Thread.currentThread().getName() + ": starting");
SERVER.set(Server.this);
connectionManager.startIdleScan();
while (running) {
SelectionKey key = null;
try {
getSelector().select();
Iterator<SelectionKey> iter = getSelector().selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
try {
if (key.isValid()) {
if (key.isAcceptable()) //一个新的socket连接请求是否被接受
doAccept(key);//执行ACCEPT对应的处理逻辑
}
} catch (IOException e) {
//.....
}
key = null;
}
} catch (OutOfMemoryError e) {
//......
} catch (Exception e) {
closeCurrentConnection(key, e);
}
}
LOG.info("Stopping " + Thread.currentThread().getName());
//....
//关闭连接操作
}
}
循环监听这个通道上的OP_ACCEPT事件,如果是建立连接请求(SelectionKey.isAcceptable()),就交付给doAccept()`进行处理:
/**
* 执行接受新的socket的连接请求的逻辑
*/
void doAccept(SelectionKey key) throws InterruptedException, IOException, OutOfMemoryError {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel channel;
while ((channel = server.accept()) != null) {
//非关键代码 略
Reader reader = getReader(); //采用轮询方式在众多的reader中取出一个reader进行处理
Connection c = connectionManager.register(channel);
// If the connectionManager can't take it, close the connection.
if (c == null) {
if (channel.isOpen()) {
IOUtils.cleanup(null, channel);
}
continue;
}
//将这个封装了对应的SocketChannel的Connection对象attatch到当前这个SelectionKey对象上
//这样,如果这个SelectionKey对象对应的Channel有读写事件,就可以从这个SelectionKey上取出
//Connection,获取到这个Channel的相关信息
key.attach(c); // so closeCurrentConnection can get the object
//将当前的connection添加给reader的connection队列,reader将会依次从队列中取出连接进行处理
reader.addConnection(c);
}
}
doAccept()方法,从自己管理的多个Reader中通过Round Robin方式获取一个Reader来处理,通过reader.addConnection(c)将这个Connection对象添加到Reader对象所维护的一个连接队列pendingConnections中,Listener此次任务即可结束。
请注意区分这里注册到Selector的SocketChannel和刚刚注册到Selector的ServerSocketChannel。整个服务器端只需要一个ServerSocketChannel,一个 ServerSocketChannel 不对应一个具体的和某个客户端的连接。相反,ServerSocketChannel 是用于监听传入的连接请求的通道,它并不处理实际的数据传输或连接。当一个客户端尝试连接到服务器时,ServerSocketChannel 会接受这个连接请求并返回一个新的 SocketChannel,该 SocketChannel 代表与客户端的实际连接,因此接下来就需要将这个SocketChannel注册到Selector上,并关注OP_READ事件,这个操作是在Reader中做的。
此后,这个channel上的读与写任务将一直固定由这个分派给自己的Reader直接负责,而不会被其它Reader线程处理。注意,Connection是对NIO SocketChannel的封装,它们一一对应。
4.Reader
Reader是Listener的内部类,在Listener的构造函数中可以看到:
readers = new Reader[readThreads];//readThreads个Reader进行处理
for (int i = 0; i < readThreads; i++) {
Reader reader = new Reader(
"Socket Reader #" + (i + 1) + " for port " + port);
readers[i] = reader;
reader.start();
}
从Reader构造函数可以看到,一个Reader对象对应了NIO中的一个Selector。显然,由于Java NIO中一个Selector可以负责监听多个SocketChannel,因此客户端的连接数量并不受到Selector的数量的限制。这就是Java NIO中通过Selector实现非阻塞(Non-Blocking,注意, Non-Blocking只是Java NIO(New IO)的一种工作方式)的重要体现,一个Reader对应一个Selector,但是一个Selector上却负责处理多个客户端的请求。
Listener会创建一个Reader 线程的数组。上面已经说过,收到ACCEPT请求以后,其实是通过Round-Robin选出一个Reader进行处理。来看Reader 的处理方式:
private synchronized void doRunLoop() {
while (running) {
SelectionKey key = null;
try {
// consume as many connections as currently queued to avoid
// unbridled acceptance of connections that starves the select
int size = pendingConnections.size();
for (int i=size; i>0; i--) {
Connection conn = pendingConnections.take();
conn.channel.register(readSelector, SelectionKey.OP_READ, conn);//向Selector注册对应的SocketChannel(注意上文讲到的ServerSocketChannel和SocketChannel的区别,SocketChannel与一个实际的客户端连接对应)并关注OP_READ
}
readSelector.select();
Iterator<SelectionKey> iter = readSelector.selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
if (key.isValid()) {
if (key.isReadable()) {
doRead(key);
}
}
key = null;
}
} catch (InterruptedException e) {
//....
}
}
}
从pendingConnections中取出Listener交付给自己的连接请求,从请求中取出通道,将自己的readSelector注册到通道上,并监听SelectionKey.OP_READ。这样,Reader就可以开始处理该通道上的SelectionKey.OP_READ事件,即客户端已经可以通过这个RPC连接,向服务器端发送消息。Reader.doRead()方法负责处理消息:
void doRead(SelectionKey key) throws InterruptedException {
int count = 0;
Connection c = (Connection)key.attachment();
//.....
try {
count = c.readAndProcess();
} catch (InterruptedException ieo) {
//.....
}
//....
}
/**
* 处理当前的连接请求
*/
public int readAndProcess()
throws WrappedRpcServerException, IOException, InterruptedException {
while (true) {
int count = -1;
if (dataLengthBuffer.remaining() > 0) {
count = channelRead(channel, dataLengthBuffer);
/**
* 正常情况下dataLengthBuffer.reamaining()应该刚好为0,也就是读取到的刚好是四个字节的head RpcConstant.HEADER()
* 如果count < 0 || dataLengthBuffer.remaining() > 0,则已经出现异常,直接返回
*/
if (count < 0 || dataLengthBuffer.remaining() > 0)
return count;
}
if (!connectionHeaderRead) { //如果还没有读到连接的header信息,第一次进入循环,肯定是false
//Every connection is expected to send the header.
if (connectionHeaderBuf == null) {
connectionHeaderBuf = ByteBuffer.allocate(3);//分配空闲ByteBuffer
}
count = channelRead(channel, connectionHeaderBuf);//从channel中读取Header信息到connectionHeaderBuf
if (count < 0 || connectionHeaderBuf.remaining() > 0) {
return count;//如果ByteBuffer还有剩余,说明读取出现了异常情况,退出
}
int version = connectionHeaderBuf.get(0);//第一个字节,版本信息
// TODO we should add handler for service class later
this.setServiceClass(connectionHeaderBuf.get(1));//第二个字节,serviceClass
dataLengthBuffer.flip();//准备开始读取dataLengthBuffer中的信息
//检测用户错误地往这个ipd地址上发送了一个get请求
if (HTTP_GET_BYTES.equals(dataLengthBuffer)) {
setupHttpRequestOnIpcPortResponse();
return -1;
}
//一个合法的RPC请求的请求头应该是hrpc四个字节,VERSION= 9
if (!RpcConstants.HEADER.equals(dataLengthBuffer)
|| version != CURRENT_VERSION) {
//请求不合法,返回异常,代码略
}
// this may switch us into SIMPLE
//获取授权类型,none或者SALS
authProtocol = initializeAuthContext(connectionHeaderBuf.get(2));
dataLengthBuffer.clear(); //clear方法并不清除数据,而是将position 设置为0,capacity和limit都设置为capacity
connectionHeaderBuf = null;
connectionHeaderRead = true;
continue;//如果当前读取到的是header,则继续while循环,读取到的应该是数据长度字段
}
//开始读取数据长度字段
if (data == null) {
dataLengthBuffer.flip();
dataLength = dataLengthBuffer.getInt();
checkDataLength(dataLength);
//根据数据长度初始化data,用来装载数据本身
data = ByteBuffer.allocate(dataLength);
}
//读取数据到data中
count = channelRead(channel, data);
//由于data是按照消息头中的数据长度描述值创建的大小,因此当data.remaining() == 0,则已经读取完了所有的数据,可以开始进行处理了
if (data.remaining() == 0) {
dataLengthBuffer.clear();
data.flip();
boolean isHeaderRead = connectionContextRead;
processOneRpc(data.array());//开始解析RPC请求,将请求交付给具体的处理器类
data = null;
if (!isHeaderRead) {
continue;
}
}
return count;
}
}
readAndProcess()方法负责对RPC请求头进行提取、分析、校验和处理,这里,我们做一下详细分析,有助于我们理解基于protobuf协议的RPC的一些运行机制。
RPC消息头字段的含义如下:
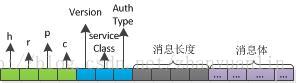
注意,这里将header分为两个:
- RPC Header:RPC协议本身的头信息,与具体业务无关。RPC的消息体中的数据对RPC Header来说就是一堆二进制,如同TCP头不需要关心TCP消息体中携带了什么消息一样;
- 业务 Header:业务本身的头信息。假如我们使用的是基于Protobuf协议的RPC,那么,RPC消息的消息体就包含具体的业务头信息和基于protobuf协议的消息体。
下面我来解释一下RPC消息的第0-10个字节,这10个字节存放的是RPC Header。从第11个字节开始,就是RPC消息体,包含了具体的业务头信息以及业务消息体。
0-3字节:存放固定字符hrpc,作为RPC的标记
/**
- The first four bytes of Hadoop RPC connections
*/
public static final ByteBuffer HEADER = ByteBuffer.wrap(“hrpc”.getBytes
(Charsets.UTF_8));
第4字节:版本信息,RPC Server将版本信息hard code在代码中: public static final byte CURRENT_VERSION = 9;,任何RPC请求都会比较这个版本信息与CURRENT_VERSION是否一致,如果不一致,则返回版本不一致的响应信息
第5字节:整数,作为这个连接的serviceClass,但是我在hadoop代码中没有找到对serviceClass的使用,应该是出于版本迭代等原因,现在已经没有任何作用。
第6字节:authType,授权类型,略过
第7-10字节:数据长度字段,读取到该字段的值以后,会创建该长度的ByteBuffer以接收RPC消息体
第11字段以后:RPC消息体
了解了RPC消息头的基本结构,我们一起来看代码中是如何对RPC消息头进行提取、解析、校验的。基本步骤如下:
-
提取消息流的前四个字节,
count = channelRead(channel, dataLengthBuffer)是第一次读取,看this.dataLengthBuffer = ByteBuffer.allocate(4)知道它是一个4字节数组,这4个字节是RPC标记字符hrpc; -
读取3个字节的HEADER信息,分别记录了版本信息、本次连接的serviceClass和授权类型信息;
-
判断协议版本合法性以及头四个字节的合法性,包括前四个字节是否是规定的
hrpc以及版本号是否与服务端一致; -
继续获取4个字节的信息,这四个字节的信息是一个整数,代表了本次消息的消息体的长度。从代码中可以看到,读取消息长度信息以后,会对消息长度信息进行校验,如果校验成功,则创建一个长度为
dataLength的ByteArray data,用来存放消息体。 -
读取RPC消息体,放入
ByteArray data中 -
通过
processOneRpc(data.array());,对RPC消息体进行解析,如果是基于protobuf协议的RPC,那么这个RPC消息体就包括protobuf的消息头和protobuf的消息体。
private void processOneRpc(byte[] buf)
throws IOException, WrappedRpcServerException, InterruptedException {
int callId = -1;
int retry = RpcConstants.INVALID_RETRY_COUNT;
try {
final DataInputStream dis =
new DataInputStream(new ByteArrayInputStream(buf));
//对protobuf的数据进行解码操作,protobuf客户端在发送前的encode与接收端接收后的decod是一正一反的过程
final RpcRequestHeaderProto header =
decodeProtobufFromStream(RpcRequestHeaderProto.newBuilder(), dis);
callId = header.getCallId();//获取callId,其实是本次交互的序列号信息,对本次请求的response中会携带序列号,以便客户端分辨对响应进行识别
retry = header.getRetryCount();//获取重试次数字段,发送响应的时候,如果发生错误,会根据该字段进行有限次重试
//检查业务头信息
checkRpcHeaders(header);
//callId<0意味着连接、认证尚未正确完成,因此需要进行连接有关的操作
if (callId < 0) { // callIds typically used during connection setup
processRpcOutOfBandRequest(header, dis);
} else if (!connectionContextRead) {
throw new WrappedRpcServerException(
RpcErrorCodeProto.FATAL_INVALID_RPC_HEADER,
"Connection context not established");
} else {
processRpcRequest(header, dis);//校验正常,开始处理RPC请求
}
} catch (WrappedRpcServerException wrse) { // inform client of error
//发生异常,立刻响应error ,代码略
}
}
processOneRpc()的参数byte[] buf是RPC消息体,如果是基于目前最流行的protbuf协议的RPC,那么这个消息体就是经过protobuf协议序列化(encode)的消息。因此,processOneRpc()会对这个消息通过decodeProtobufFromStream()进行decode操作,解析出protobuf头信息,放入RpcRequestHeaderProto header中。
decode完毕以后,会通过checkRpcHeaders()对protobuf消息头中的头信息进行校验,主要是校验RPC_OPERATION和RPC_KIND是否合法。RPC_OPERATION目前只支持RpcRequestHeaderProto.OperationProto.RPC_FINAL_PACKET,否则认为非法。
当基于protobuf协议的RPC消息体被成功地decode,同时,decode出来的消息中的头信息经过了校验,则开始调用processRpcRequest(RpcRequestHeaderProto header,DataInputStream dis)对消息进行处理,它的核心任务,是对数据进行解析,封装成Call对象,放到callQueue中。Handler线程将从callQueue中取出请求,并进行处理和响应:
private void processRpcRequest(RpcRequestHeaderProto header,
DataInputStream dis) throws WrappedRpcServerException,
InterruptedException {
//获取RPC类型,目前主要有两种RPC类型有WritableRPC 和ProtobufRPC
//老版本的Hadoop使用WritableRPC,新版本的Hadoop开始使用基于Protobuf协议的RPC,即ProtobufRPC
//以ProtobufRpcEngine为例,对应的WrapperClass是ProtobufRpcEngine.RpcRequestWrapper
//提取并实例化wrapper class,用来解析请求中的具体字段
Class rpcRequestClass =
getRpcRequestWrapper(header.getRpcKind());
if (rpcRequestClass == null) {
//无法从header中解析出对应的RPCRequestClass,抛出异常
}
Writable rpcRequest;
try { //Read the rpc request
//可以将rpcRequestClass理解为当前基于具体某个序列化协议的解释器,解释器负责解释
//和解析请求内容,封装为rpcRequest对象
rpcRequest = ReflectionUtils.newInstance(rpcRequestClass, conf);
rpcRequest.readFields(dis);
} catch (Throwable t) { // includes runtime exception from newInstance
//数据解析发生异常,则抛出异常
}
//略
//根据请求中提取的callId、重试次数、当前的连接、RPC类型、发起请求的客户端ID等,创建对应的Call对象
Call call = new Call(header.getCallId(), header.getRetryCount(),
rpcRequest, this, ProtoUtil.convert(header.getRpcKind()),
header.getClientId().toByteArray(), traceSpan);
//将Call对象放入callQueue中,Handler线程将负责从callQueue中逐一取出请求并处理
callQueue.put(call); // queue the call; maybe blocked here
incRpcCount(); // Increment the rpc count
}
这里注意区分Call对象和Connection对象的关系:Connection是对一个SocketChannel的封装,即代表了一个连接。一个Call是这个Connection之上的一次请求,可见,Connection和Call是一对多的关系,如下图:

5.Handler
上文提到,在ipc.Server.start()方法中,创建了一个Handler数组并将这些Handler一一进行启动。其实是调用Handler作为一个线程的Thread.start()方法,因此我们来看Handler线程的 run()方法:
public void run() {
SERVER.set(Server.this);
ByteArrayOutputStream buf =
new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE);
while (running) {
try {
//从callQueue中取出Call对象,Call对象封装了请求的所有信息,包括连接对象、序列号等等信息
final Call call = callQueue.take(); // pop the queue; maybe blocked here
//判断这个请求对应是SocketChannel是否是open状态,如果不是,可能客户端已经断开连接,没有响应的必要
if (!call.connection.channel.isOpen()) {
LOG.info(Thread.currentThread().getName() + ": skipped " + call);
continue;
}
//略
CurCall.set(call);
try {
//call方法是一个抽象方法,实际运行的时候会调用具体实现类的call
value = call(call.rpcKind, call.connection.protocolName,
call.rpcRequest, call.timestamp);
} catch (Throwable e) {
//发生异常,根据异常的类型,设置异常的详细信息、返回码等等
}
//服务端调用结束,即服务端已经完成了客户端请求的相关操作,开始对响应进行设置,将响应发送给客户端
CurCall.set(null);
synchronized (call.connection.responseQueue) {
//将error信息封装在call对象中,responder线程将会处理这个Call对象,向客户端返回响应
setupResponse(buf, call, returnStatus, detailedErr,
value, errorClass, error);
//将封装了Error信息或者成功调用的信息的Call对象交付给Responder线程进行处理
responder.doRespond(call);
}
} catch (InterruptedException e) {
//异常信息
} finally {
//略
}
LOG.debug(Thread.currentThread().getName() + ": exiting");
}
}
从代码中可以看到,Handler线程其实是一个事件分发器,一个用来连接Reader和Responder的缓存器:Reader线程根据接收到的RPC请求封装成Call对象,放入callQueue中。Handler线程池中的Handler各自以竞争的方式,不断从callQueue中取出Call对象,调用 call(call.rpcKind, call.connection.protocolName, call.rpcRequest, call.timestamp);进行处理。这里的call()方法是ipc.Server这个抽象类中的唯一抽象方法。
这里可以聊一下为什么ipc.Server是一个抽象方法,以及为什么只有call()方法一个抽象方法:ipc.Server设计为抽象类,是因为Hadoop的设计者不希望任何人修改ipc.Server关于Reactor设计模式的架构和设计,即Hadoop的设计者认为基于Reactor设计模式的架构已经没有修改的必要了,因此,关于Reactor模式的设计,直接在ipc.Server进行了实现。但是,进程间通信的方式有很多种,RPC(Remote Process Call,远程过程调用)只是ipc(Inter-Process Communication,进程间通信)的一种实现方式而已,因此,call()方法声明为抽象方法,让具体的某种ipc实现类具体实现对某个请求的处理。我们来看Hadoop中ipc.Server的RPC实现类RPC.Server对call()方法的实现:
```
public Writable call(RPC.RpcKind rpcKind, String protocol,
Writable rpcRequest, long receiveTime) throws Exception {
return getRpcInvoker(rpcKind).call(this, protocol, rpcRequest,
receiveTime);
}
```
RPC.Server.call()会根据rpc类型,提取出对应的RpcInvoker,实际调用Invoker.call()方法进行处理。在我的两篇拙文《Hadoop 基于protobuf 的RPC的客户端实现原理》和《Hadoop 基于protobuf 的RPC的服务器端实现原理》中详细介绍了不同的RPC Engine通过注册的方式向ipc.Server注册自己,因此RPC.Server就有了rpcKind和RpcInvoker的对应关系,这个注册过程不再详述。我们同样以ProtobufRpcEngine为例,ProtobufRpcEngine启动的时候会向RPC.Server注册自己的ProtobufRpcEngine.Invoker ,即声称自己能够处理protobuf这种rpcKind的请求。因此RPC.Server收到了,就可以根据请求中携带的rpcKind,取出ProtobufRpcEngine.Invoker进行处理,即调用ProtobufRpcEngine.Invoker.call()方法。
Handler调用完call()方法,将返回结果value经过处理放回到Call对象中,然后调用responder.doResponse(call)进行响应操作。下面讲解Responder线程的时候会详细讲到,Responder通过调用responder.doResponse(call)试图在这个Connection上只有当前一个response的情况下,直接将response返回给客户端而不麻烦Responder,如果不止当前一个响应,或者自己一次性无法将当前的response全部发送给远程客户端,才会交给Responder继续进行。
6.Responder
Responder线程负责返回处理Selector上处于writable状态的SelectionKey,然后执行写操作,这个我们跟踪Responder.run()的代码可以很清楚地看到,与Reader类似,这里不做详述。我们详细
抛开写操作的具体细节,我们知道,要想一个Selector可以监控一个channel是否是writable,这个channel必须得预先将自己注册到Selector,这是在Handler.run()里面通过调用Responder.processResponse()进行的:
private boolean processResponse(LinkedList responseQueue,
boolean inHandler) throws IOException {
try {
synchronized (responseQueue) {
//先进先出,因此从respondeQueue中取出第一个Call对象进行处理
call = responseQueue.removeFirst();//
SocketChannel channel = call.connection.channel;
//将call.rpcResponse中的数据写入到channel中
int numBytes = channelWrite(channel, call.rpcResponse);
if (!call.rpcResponse.hasRemaining()) {//数据已经写入完毕
//数据已经写完,进行一个buffer的清理工作
} else {
//如果数据没有完成写操作,则把Call对象重新放进responseQueue中的第一个,下次会进行发送剩余数据
call.connection.responseQueue.addFirst(call);
//如果是inHandler,说明这个方法是Handler直接调用的,这时候数据没有发送完毕,需要将channel注册到writeSelector, 这样Responder.doRunLoop()中就可以检测到这个writeSelector上的writable的SocketChannel,然后把剩余数据发送给客户端
if (inHandler) {
// Wakeup the thread blocked on select, only then can the call
// to channel.register() complete.
writeSelector.wakeup();
//将channel注册到writeSelector,同时将这个Call对象attach到这个SelectionKey对象,这样Responder线程就可以通过select方法检测到channel上的写事件,同时从Call中提取需要写的数据以及SocketChannel,进而进行写操作
channel.register(writeSelector, SelectionKey.OP_WRITE, call);
}
}
error = false; // everything went off well
}
}
return done;
}
从上面的代码可以看到,processResponse()负责对某一个Connection的多个响应中取出第一个(遵循先进先出规则),然后把这个响应通过这个SocketChannel返回给客户端。同时,我们看到,processResponse()的第二个参数inHandler,这个参数标记着这个processResponse()的调用者是否是Handler,因为从Handler.run()方法中可以看到,Handler线程在封装好了响应结果Call对象以后,会试图直接通过调用doRespond()进行响应:
void doRespond(Call call) throws IOException {
synchronized (call.connection.responseQueue) {
call.connection.responseQueue.addLast(call);//将这个Call对象添加到对应的connection的responseQueue中
if (call.connection.responseQueue.size() == 1) {//如果目前与这个客户端的连接的相应队列中只有一条数据,则直接处理
//对这个connection的responseQueue进行处理,之所以设置第二个参数为true,是为了
//在Handler中调用doRespond方法的时候,由于是Handler,所以必定是一个新的请求过来,必须重新将channel注册到在Responder.writerSelector上,以便下次响应
processResponse(call.connection.responseQueue, true);
}
}
}
Handler通过doRespond()方法将Call对象添加到当前这个Connection的responseQueue中,同时判断responseQueue是不是只有当前一个response,如果是,则Handler会在自身线程中直接调用Responder.processResponse(call.connection.responseQueue, true);直接响应,不必麻烦Responder线程。第二个参数inHandler=true,用来标记这个processResponse()方法是被Handler直接调用的,而不是在Responder线程里的调用。这样,如果响应数据只是一部分返回给了客户端,那么Handler会将这个socketChannel注册到Responder.writeSelector并监听SelectionKey.OP_WRITE,这样,Responder在对这个writeSelector进行轮询的时候,会发现当前socketChannel是writable,并负责将Handler没有发送完成的剩余数据响应给客户端。而如果Handler直接把数据全部发完,就不用劳烦Responder了。
结束
以上就是Hadoop基于Reactor模式设计的ipc Server,无论是HDFS NameNode,还是Yarn ResourceManager,都是基于ipc.Server的实现类RPC.Server进行的实现。通过NIO的高效处理方式,NameNode和ResourceManager虽然是整个系统的核心,却不会成为整个系统的瓶颈。一些耗时的IO操作,都交给具体的业务处理器进行处理,处理的过程中RPC.Server会继续接收其它的RPC请求而不会block掉。当这些耗时的IO操作完成,只需要将结果交付给RPC.Server,RPC.Server将请求返回给用用户。